背景・目的
MLOpsについて、理解を深めるために整理する。
内容
概要
MLOpsに登場する用語
- ML = Machine Learning (機械学習)
- CI = Continuous Integration (継続的インテグレーション)
- CD = Continuous Delivery (継続的デリバリー)
- CT = Continuous Training (継続的トレーニング)
- MLOps = Machine Learning Operations
- 探索的データ分析(EDA)
- ホールドアウトテストセット
MLOpsとは?
- Wikipediaによると、以下が定義されている。
MLOps とは、機械学習またはディープラーニングのライフサイクルを管理するための、データサイエンティスト、エンジニア、保守運用担当者のコラボレーションおよびコミュニケーションに関する実践手法。機械学習 Machine Learning (ML) と、ソフトウェア分野での継続的な開発手法である DevOps とを組み合わせた造語である。
- 対象は、「機械学習」、「ディープラーニング」。
- ライフサイクルを管理。
- コラボレーション、コミュニケーションに関する実践的な手法を指す。
ソフトウェア開発ライフサイクル全体におけるワークロードの管理は、従来からDevOpsの概念があった。機械学習プロジェクトにDevOpsを適用した場合、モデルトレーニング等を含むのCI/CDのプロセス管理やデータサイエンティストとデータエンジニアの職種の役割分担など多数の機械学習特有の課題を考慮する必要が生まれた。その結果DevOpsをベースに機械学習プロジェクトに合理化された手法がMLOpsとして概念化された。
- DevOpsを元に機械学習プロジェクトに合理化された手法として、MLOpsが概念化された。
主に実験的な機械学習モデルを本番システムに組み込むプロセス[1]として用いられる。機械学習モデルは、隔離された実験システムでテスト・開発され、アルゴリズムを起動する準備ができたら、データサイエンティスト、保守運用担当者、機械学習エンジニアの間で MLOps を実践し、アルゴリズムを本番システムに移行する[2]。MLOps は、DevOps や DataOps のアプローチと同様に、自動化を進めて本番モデルの品質を向上させるとともに、ビジネスや規制の要件にも焦点を当てている。MLOps は、一連のベストプラクティスとしてスタートしたが、機械学習のライフサイクル管理のための独立したアプローチへと徐々に進化している。 MLOps は、モデルの生成(ソフトウェア開発ライフサイクル、継続的インテグレーション/継続的デリバリー)、編成、デプロイメントの統合から、健全性、診断、ガバナンス、ビジネス指標に至るまで、ライフサイクル全体に適用される。
-
登場するロールは、データサイエンティスト、保守運用担当、機械学習エンジニア。
-
機械学習モデルの流れは、以下の通り。
- 隔離された実験システム(テスト環境?)でテスト、開発
- アルゴリズムを本番に移行する。
-
MLOpsにより、自動化を進め本番モデルの品質を向上させる。ビジネスや規制の要件にも焦点を当てている。
各社のMLOpsの定義
- Microsoft、Google、AmazonでMLOpsをそれぞれ定義しているので整理した。
| 定義 | 価値 | |
|---|---|---|
| Microsoft | ワークフローの効率を向上させる DevOps の原則と実践に基づいている。 たとえば、継続的インテグレーション、配信、デプロイが対象。 | 左記の原則を機械学習プロセスに適用している。 ・モデルのより迅速な実験と開発 ・実稼働環境へのモデルのより迅速なデプロイ ・品質保証 |
| ML システム開発(Dev)と ML システム オペレーション(Ops)の統合を目的とする ML エンジニアリングの文化と手法。 | 統合、テスト、リリース、デプロイ、インフラストラクチャ管理など、ML システム構築のすべてのステップで自動化とモニタリングを推進可能。 | |
| Amazon | 機械学習ワークロードにDevOps プラクティスを適用することに基づいて構築された方法論を指す。 ML ワークロードをリリース管理、CI/CD、および運用に統合する規律を指す。 |
機械学習開発ライフサイクル (MLDC) 全体にわたるモデルの提供を合理化することに重点を置いている。 |
- DevOpsに基づいており、MLのシステム開発(Dev)と運用(Ops)を統合する。
- 統合することで、プロセスが合理化、自動化され迅速にMLのライフサイクルを回せることが価値と考えられる。
MLOps: 機械学習における継続的デリバリーと自動化のパイプライン
ここからは、Googleのドキュメントを元を読み解き、理解を深める。
はじめに
効果的な ML を適用するための要素
- 以下の通り。
- 大規模なデータセット
- 低価格のオンデマンド コンピューティング リソース
- さまざまなクラウド プラットフォームでの ML 専用のアクセラレータ
- さまざまな ML 研究分野(コンピュータ ビジョン、自然言語理解、Recommendations AI システムなど)における急速な進歩
MLOpsの効果
- MLOps を実践することで、以下のMLシステム構築すべてのステップで自動化とモニタリングを推進できる。
- 統合
- テスト
- リリース
- デプロイ
- インフラストラクチャ管理、
実際のMLの課題
- ML モデルを構築することではなく、統合された ML システムを構築し、本番環境で継続的に運用すること。
- (データ サイエンティストは、ユースケースに関連するトレーニング データがあれば、オフラインのホールドアウト データセットの予測性能で ML モデルを実装してトレーニングが可能。)
- MLシステムの中で、MLコードはごく一部である。必要となる周辺要素は膨大で複雑。
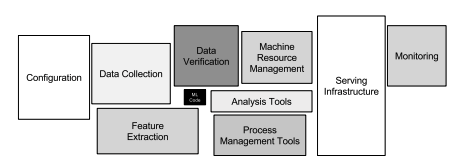
※ Hidden Technical Debt in Machine Learning Systemsから抜粋。

※ MLOps: 機械学習における継続的デリバリーと自動化のパイプラインから抜粋。
- 上記は、構成、自動化、データ収集、データ検証、テストとデバッグ、リソース管理、モデル解析、プロセス管理とメタデータ管理、サービス インフラストラクチャ、モニタリングから構成されている。
- これらの複雑なシステムを開発して運用するために、DevOpsの原則をMLシステム(MLOps)に適用する。
DevOps と MLOps
- DevOpsは、大規模なソフトウェアシステムの開発と運用における一般的な手法。この手法で、以下の効果が期待できる。
- 開発サイクルの短縮
- 開発の迅速化
- 信頼性の高いリリース
- そのためには、CIとCDのコンセプトを導入する。
- MLシステムはソフトウェアのため、DevOps同様の手法を適用して、大規模MLシステムを確実にビルドして運用可能。
MLシステムが他のシステムと異なる点
| 相違点 | 解説 | 注意点 |
|---|---|---|
| チームのスキル | MLプロジェクトチームに参加するメンバーのロール ※以下のロールのメンバが参加しているのが特徴。 ・データサイエンティスト ・ML研究者 |
本番環境クラスのサービスをビルドできる経験豊富なエンジニアではない場合がある。 |
| 開発 | 実験的性質 さまざまな機能、アルゴリズム、モデリング技術、パラメータ構成を試して、問題に最適な方法をできるだけ早く見つける必要がある。 |
何が機能し、何が機能しなかったかを追跡して、コードの再利用性を最大化しながら再現性を維持することが課題になる。 |
| テスト | テストの複雑さ その他のソフトウェア システムのテストよりも複雑。 |
一般的な単体テストと統合テストに加えて、データ検証、トレーニングされたモデル品質評価、モデル検証が必要になる。 |
| デプロイ | デプロイの複雑さ ML システムでは、マルチステップ パイプラインをデプロイして、デプロイモデルを自動的に再トレーニングする必要がある。 |
このパイプラインにより複雑さが増し、データ サイエンティストによるデプロイの前に手動で行われる手順を自動化して、新しいモデルのトレーニングと検証をする必要がある。 |
| 本番環境 | パフォーマンスの低下 最適化されていないコーディングだけでなく、絶えず変化するデータ プロファイルのためにパフォーマンスが低下する可能性がある。 従来のソフトウェア システムよりも多くの方法でモデルが劣化する可能性があるため、このような性能低下を考慮する必要がある。 |
データの概要統計を追跡し、モデルのオンライン パフォーマンスをモニタリングして、値が想定と異なる場合に通知を送信またはロールバックする必要がある。 |
| CI | スコープ コードとコンポーネントのテストと検証だけでなく、データ、データスキーマ、モデルのテストと検証も行う。 |
- |
| CD | 対象 単一のソフトウェア パッケージやサービスについではなく、別のサービス(モデル予測サービス)を自動的にデプロイするシステム(ML トレーニング パイプライン)を指す。 |
- |
| CT | MLシステム固有の概念。 自動的にモデルを再トレーニングして提供します。 |
- |
ML のデータ サイエンスの手順
- MLプロジェクトの手順は以下のステップで進める。
- ビジネスユースケースの定義
- 成功基準を確立
- ML モデルを本番環境に提供するプロセス(以下は、手動でも自動パイプラインでも可能)
- データ抽出
- MLタスクの様々なデータソースから関連データを選択して統合する。
- データ分析
- 探索的データ分析(EDA)を実行し、MLモデルのビルドに使用できるデータを理解する。このプロセスは以下の通り。
- モデルで想定されるデータスキーマと特性を理解する。
- モデルに必要なデータ準備と特徴量エンジニアを特定する。
- 探索的データ分析(EDA)を実行し、MLモデルのビルドに使用できるデータを理解する。このプロセスは以下の通り。
- データの準備
- MLタスク用にデータを準備する。ここでは以下を実施する。
- データクリーニング
- データをトレーニング
- 検証
- テストセットに分割
- ターゲットタスクを解決するモデルにデータ変換と特徴量エンジニアリングを適用する
- MLタスク用にデータを準備する。ここでは以下を実施する。
- モデルのトレーニング
- データサイエンティストは、準備したデータで異なるアルゴリズムを実装し、様々なMLモデルをトレーニングする。
- モデルの評価
- モデルはホールドアウトテストセットにより品質が評価される。
- モデルの検証
- モデルがデプロイに適していること
- 予測性能が特定のベースラインより優れていることを確認する。
- モデルの提供
- 検証済みのモデルがターゲット環境にデプロイされ、予測サービスが提供される。このデプロイは次のいずれかになる。
- オンライン予測を提供する REST API を使用したマイクロサービス。
- エッジまたはモバイル デバイスへの組み込みモデル。
- バッチ予測システムの一部。
- 検証済みのモデルがターゲット環境にデプロイされ、予測サービスが提供される。このデプロイは次のいずれかになる。
- モデルのモニタリング
- モデルの予測性能をモニタリングし、ML プロセスで新しいイテレーションを必要に応じて呼び出す。
- データ抽出
- 上記の手順の自動化レベルによって、MLプロセスの成熟度が決まる。
MLOps の成熟度
- 自動化を伴わない最も一般的なレベルからMLとCI/CDのパイプラインの自動化まで3つのレベルのMLOpsについて整理する。
| 成熟度 | プロセス | 概要 | ワークフロー(※1) | 特徴 | 課題 | 対策 |
|---|---|---|---|---|---|---|
| 0 | 手動プロセス | ML モデルのビルドとデプロイのプロセスは完全に手動 |  |
・手動、スクリプト主導、インタラクティブなプロセス ・ML とオペレーションの分離 ・頻度の低いリリースのイテレーション ・CI/CDなし ・デプロイは予測サービスを意味する。※2 ・アクティブなパフォーマンス モニタリングは行わない |
MLをユースケースに適用しようとしている多くの企業において一般的。 ・モデルは、実際にデプロイされるとしばしば失敗する。 ・モデルは、環境のダイナミクスの変化や環境を記述するデータの変更への適応に失敗する。(※3) |
CI/CDとCT向けのMLOps手法が役立つ。 MLトレーニングパイプラインをデプロイすると、CTを有効にし、CI/CDシステムを設定して、MLパイプラインの新しい実装を迅速にテスト、ビルド、デプロイ可能になる。 本番環境でモデルの精度を維持するには、次の操作を行う必要がある。 ・本番環境でモデルの品質を積極的にモニタリングする ・本番環境モデルを頻繁に再トレーニングする ・新しい実装を継続的にテストして、モデルを生成する |
| 1 | MLパイプラインの自動化 | MLパイプラインを自動化することにより、モデルの継続的トレーニングを実行すること |  |
モデル予測サービスの継続的デリバリーを実現できる。新しいデータを使用して本番環境においてモデルを再トレーニングするプロセスを自動化するには、自動化されたデータとモデル検証の手順、およびパイプライントリガーとメタデータ管理をパイプラインに導入する必要がある。 ・迅速なテスト ・本番環境でのモデルのCT ・テストと運用の対称性 ・コンポーネントとパイプライン用のモジュール化されたコード ・モデルの継続的デリバリー ・パイプラインのデプロイ |
パイプラインの新しい実装が頻繁にはデプロイされず、少数のパイプラインのみを管理している場合、通常、パイプラインとそのコンポーネントを手動でテストする。また、新しいパイプライン実装を手動でデプロイする。また、パイプラインのテスト済ソースコードを IT チームに提出し、ターゲット環境へのデプロイも行う。 | 本番環境で多数のMLパイプラインを管理する場合は、MLパイプラインのビルド、テスト、デプロイを自動化するCI/CD設定が必要になる。 |
| 2 | CI/CDパイプラインの自動化 | 自動MLパイプラインの設定と自動CI/CDルーチンの特性を備えたCI/CDを使用したMLパイプライン |
 以下のコンポーネントが含まれる。 ・ソース管理 ・サービスのテストとビルド ・デプロイサービス ・モデルレジストリ ・Feature Store ・MLメタデータストア ・MLパイプラインオーケストレーター |
 パイプラインは、次のステージで構成される。 ・開発とテスト ・パイプラインの継続的インテグレーション ・パイプライン継続的デリバリー ・自動トリガー ・モデルの継続的デリバリー ・モニタリング |
- | - |
※1. MLOps: 機械学習における継続的デリバリーと自動化のパイプラインから抜粋。
※2. この意味がわからないので後ほど調べる。
※3. Why Machine Learning Models Crash And Burn In Production
参考