背景・目的
AWS Glue Data Catalog now supports generating column-level statisticsにあるように、Glueカタログでカラムレベルの統計情報がサポートされたようです。
これにより、AthenaやRedshift Spectrum等のCBOと統合されるようになりましたので、試してみたいと思います。
まとめ
- Redshift SpectrumやAthenaなどの分析サービスで利用ができます。
- 下記のファイルフォーマットが対象です。
- Parquet
- ORC
- JSON
- ION
- CSV
- XML
- 対象の統計項目は下記になります。
- 最小値
- 最大値
- Null 値の合計
- 個別の値の合計
- 値の平均長
- true 値の合計出現数
- 考慮事項は下記のとおりです。
- サンプリングを使用すると、不正確な統計情報が作られる。
- 異なるバージョンの統計を保存しない。
- テーブル毎に一度に1つの統計生成タスクのみ実行する。
- 下記の統計の生成をサポートしていません。
- Lake Formationのセルベースのアクセス制御を備えたテーブル
- トランザクションデータレイク
- Delta Lake
- Iceberg
- Hudi
- フェデレーション内のテーブル
- Hiveメタストア
- Redshift データシェアリング
- ネストされたカラム、配列、構造体
- 別のアカウントから共有されたテーブル
- 2023/11/19時点で下記のリージョンでのみ利用可能です。
- 米国東部 (バージニア北部)
- 米国東部 (オハイオ)
- 米国西部 (オレゴン)
- 欧州 (アイルランド)
- アジアパシフィック (東京、大阪)
概要
まずは、どのようなものか、Working with column statisticsを元に整理してみます。
下記のファイルフォーマットで列レベルの統計を計算できるようです。
- Parquet
- ORC
- JSON
- ION
- CSV
- XML
下記の統計を生成します。
- 最小値
- 最大値
- Null 値の合計
- 個別の値の合計
- 値の平均長
- true 値の合計出現数等
Redshift SpectrumやAthenaなどの分析サービスで、上記の列統計を使用してクエリの実行計画を生成し、パフォーマンスを向上させる最適なプランが選択できるようになります。
考慮事項と制限事項
Considerations and limitationsをもとに整理しています。
- 考慮事項
- サンプリングを使用すると、不正確な統計情報が作られる。
- 異なるバージョンの統計を保存しない。
- テーブル毎に一度に1つの統計生成タスクのみ実行する。
- 下記の統計の生成をサポートしていない。
- Lake Formationのセルベースのアクセス制御を備えたテーブル
- トランザクションデータレイク
- Delta Lake
- Iceberg
- Hudi
- フェデレーション内のテーブル
- Hiveメタストア
- Redshift データシェアリング
- ネストされたカラム、配列、構造体
- 別のアカウントから共有されたテーブル
実践
前提
IAMロールの設定
列統計の生成、更新を行うためには、IAMロールの作成が必要です。
-
IAMロールの画面で、ロールの作成をクリックします。
-
下記を入力し、「次へ」をクリックします。
- AWSのサービス
- ユースケース:Glue
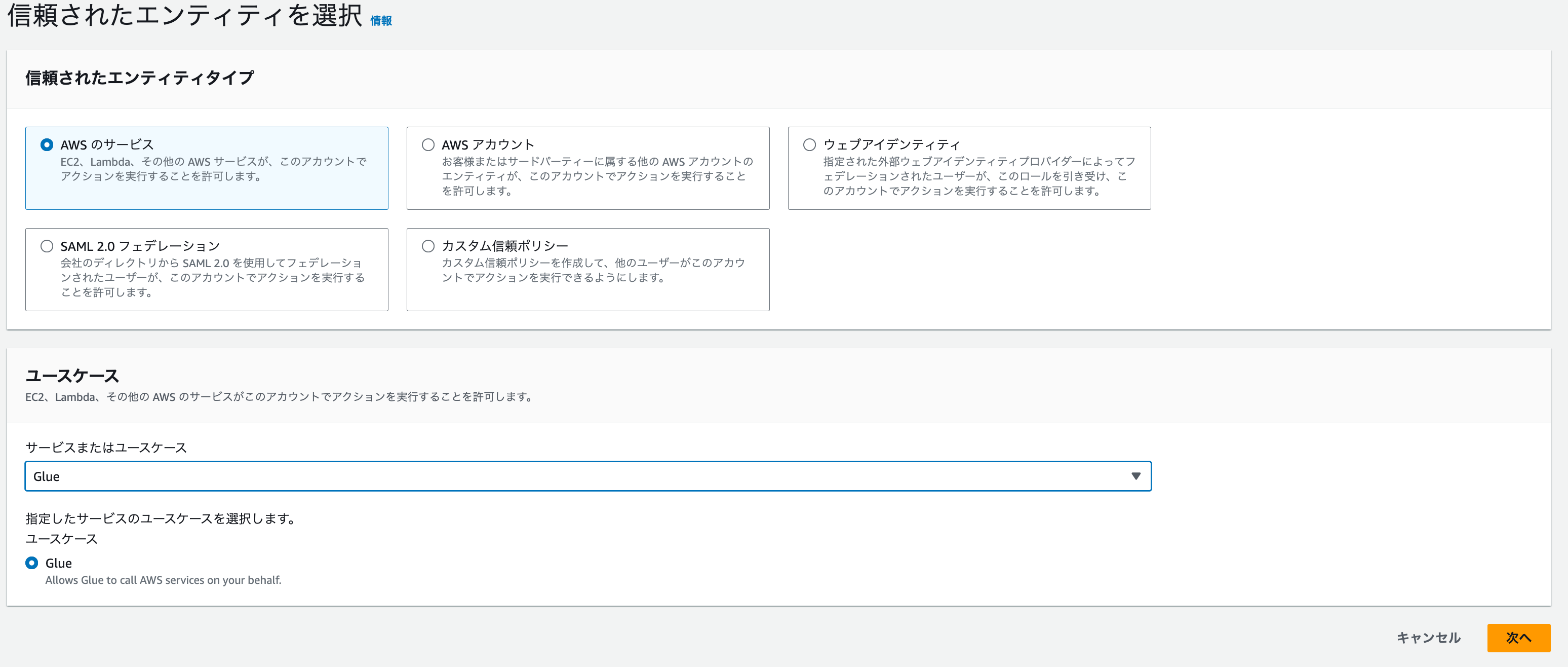
-
ポリシーの追加で、AWS管理の「AWSGlueServiceRole」を選択し、「作成」をクリックします。
-
作成したロールにインラインポリシーを追加します。下記のJSONを貼り付けて、作成します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "S3BucketAccess", "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetObject" ], "Resource": [ "arn:aws:s3:::<bucket>/*", "arn:aws:s3:::<bucket>" ] } ] }
データの準備
ファイルアップロード
-
Redshiftのドキュメントに添付されているサンプルのデータセットtickitdb.zipをダウンロードします。
-
いくつかのファイルのうち、最も大きいサイズのlisting_pipe.txtを使用します。
$ total 57072 -rw-rw-r--@ 1 XXXX YYY 445838 10 16 2019 allevents_pipe.txt -rw-rw-r--@ 1 XXXX YYY 5893626 10 16 2019 allusers_pipe.txt -rw-rw-r--@ 1 XXXX YYY 465 10 16 2019 category_pipe.txt -rw-rw-r--@ 1 XXXX YYY 14534 10 16 2019 date2008_pipe.txt -rw-rw-r--@ 1 XXXX YYY 11585036 10 16 2019 listings_pipe.txt -rw-rw-r--@ 1 XXXX YYY 11260097 10 16 2019 sales_tab.txt -rw-rw-r--@ 1 XXXX YYY 7988 10 16 2019 venue_pipe.txt $ -
S3にアップロードします。
データベースとテーブルの作成
-
GlueのData Catalogを開きます。
-
データベース名を「tickitdb」とし、データベースを作成します。
-
テーブル名を「listing」とし、「Next」をクリックします。
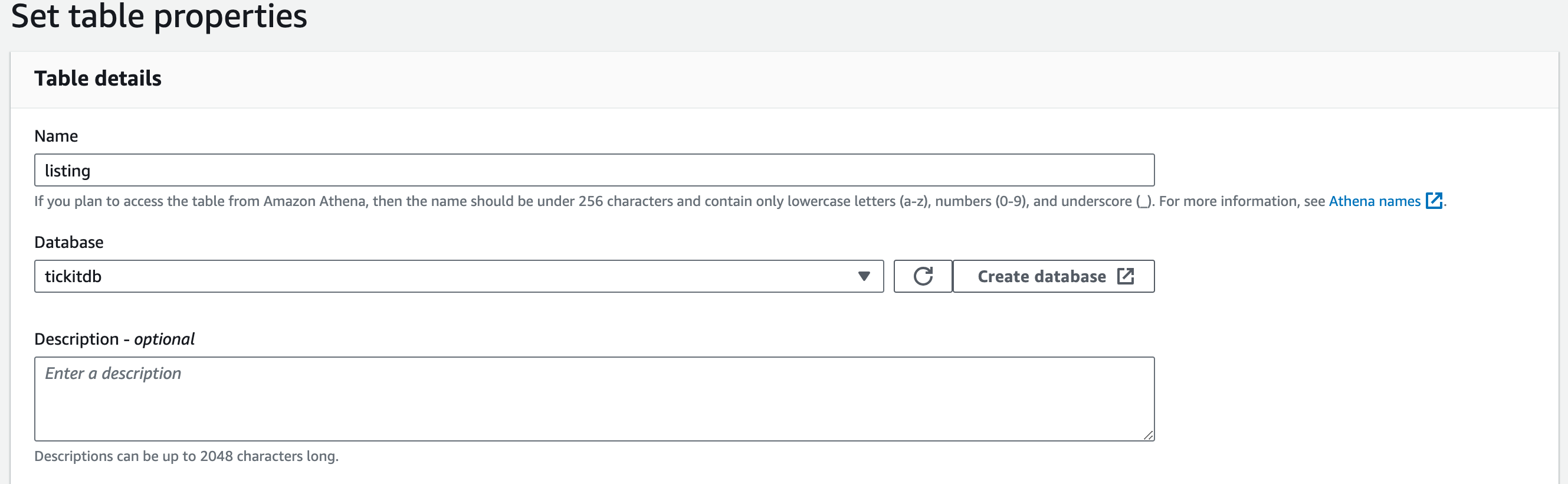
-
スキーマを設定し、「Next」をクリックします。
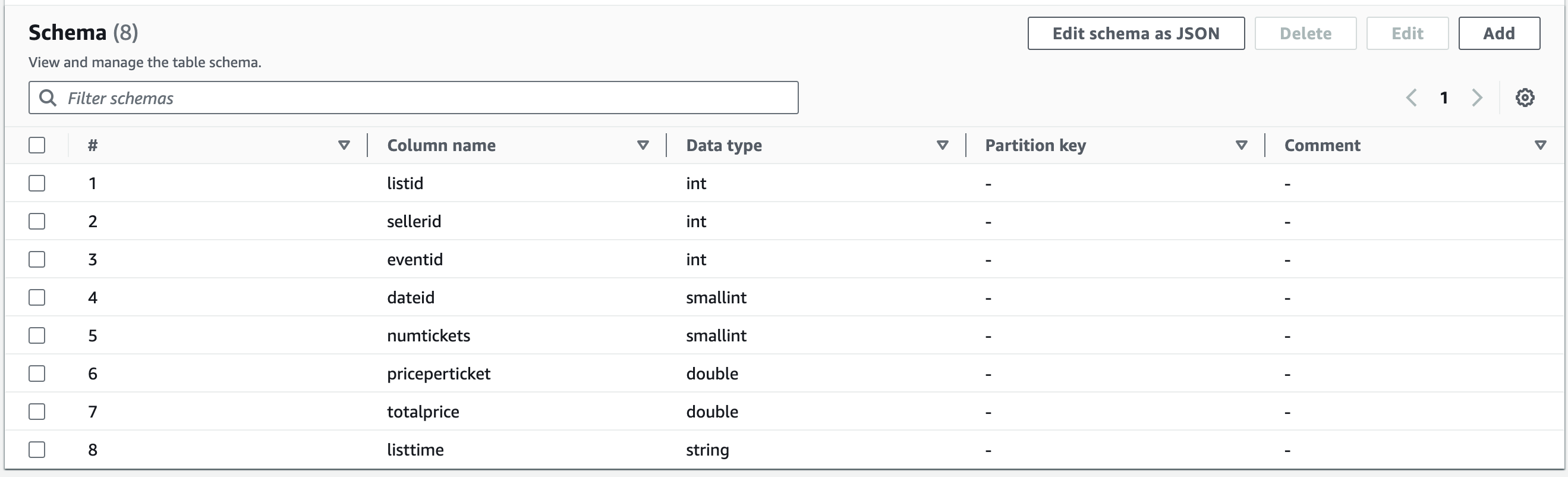
-
確認画面で、「Create」をクリックします。
データの確認
- Athenaのクエリエディタを開きます。
- 下記のクエリを実行しAthenaで読み取れるか確認します。
SELECT listid,sellerid,eventid,dateid,numtickets,priceperticket,totalprice,listtime FROM "tickitdb"."listing" limit 10;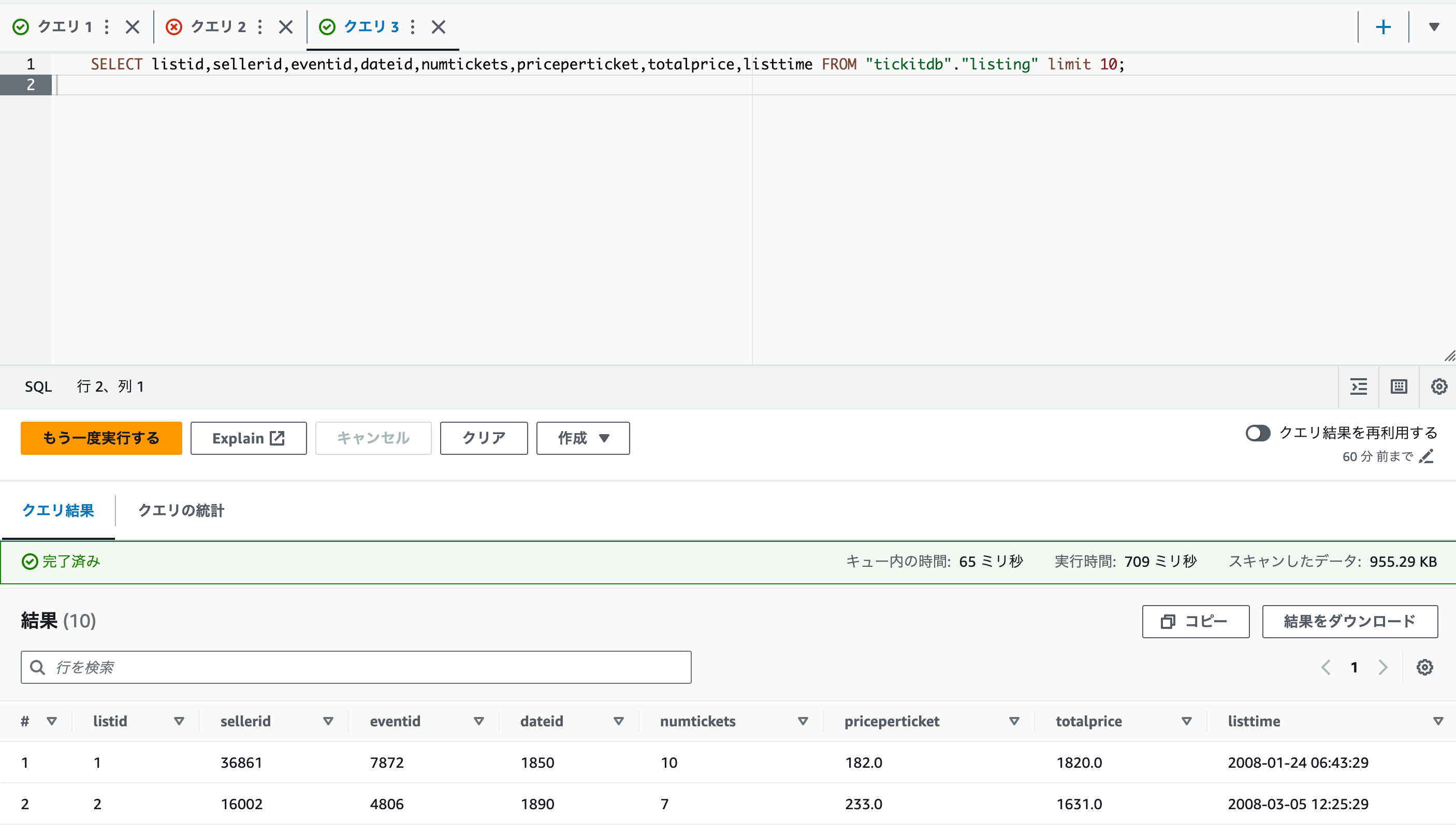
統計情報を生成する
事前確認
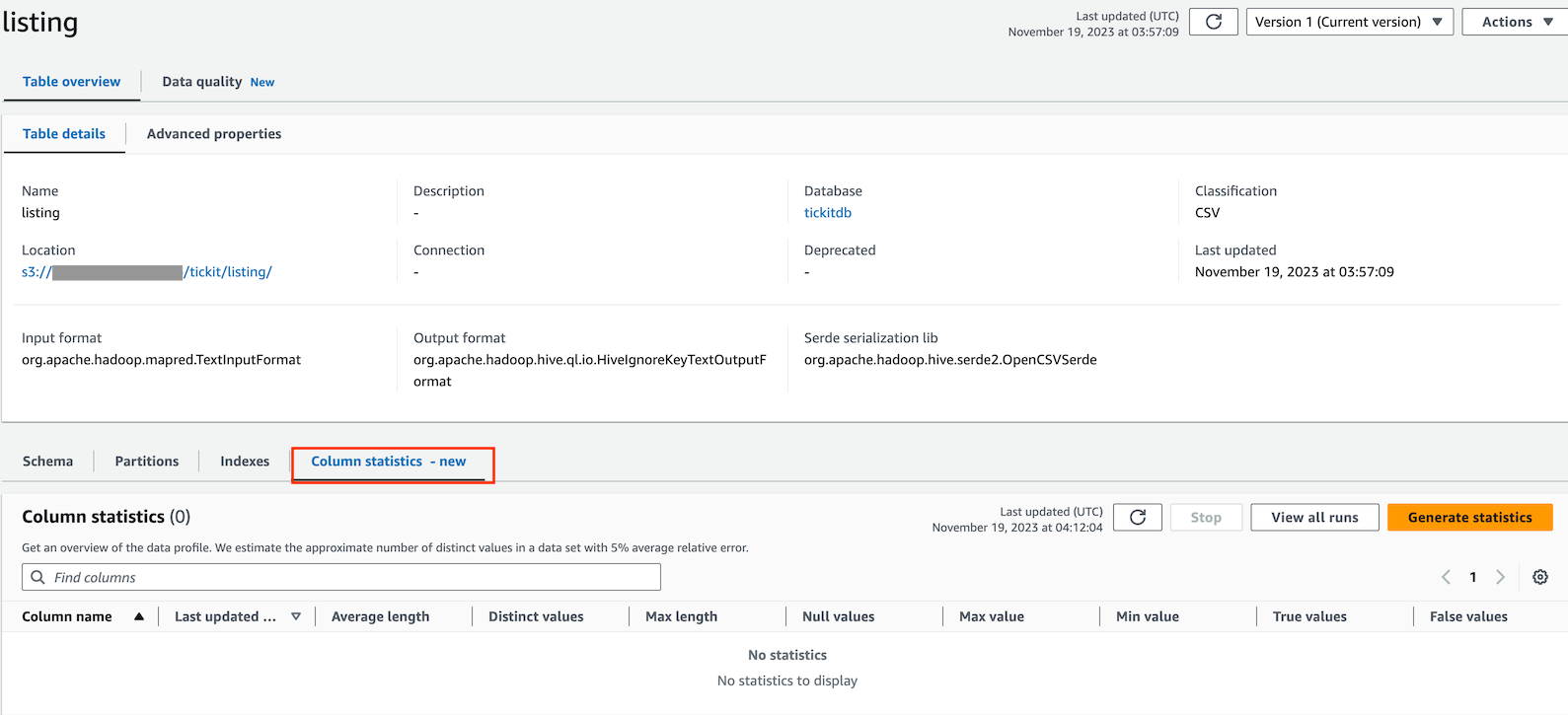
- 事前に列統計を確認するため、作成したGlueのテーブルを確認します。
- テーブルの「Cloumn statics」タブをクリックします。なにもないことがわかります。
統計を生成
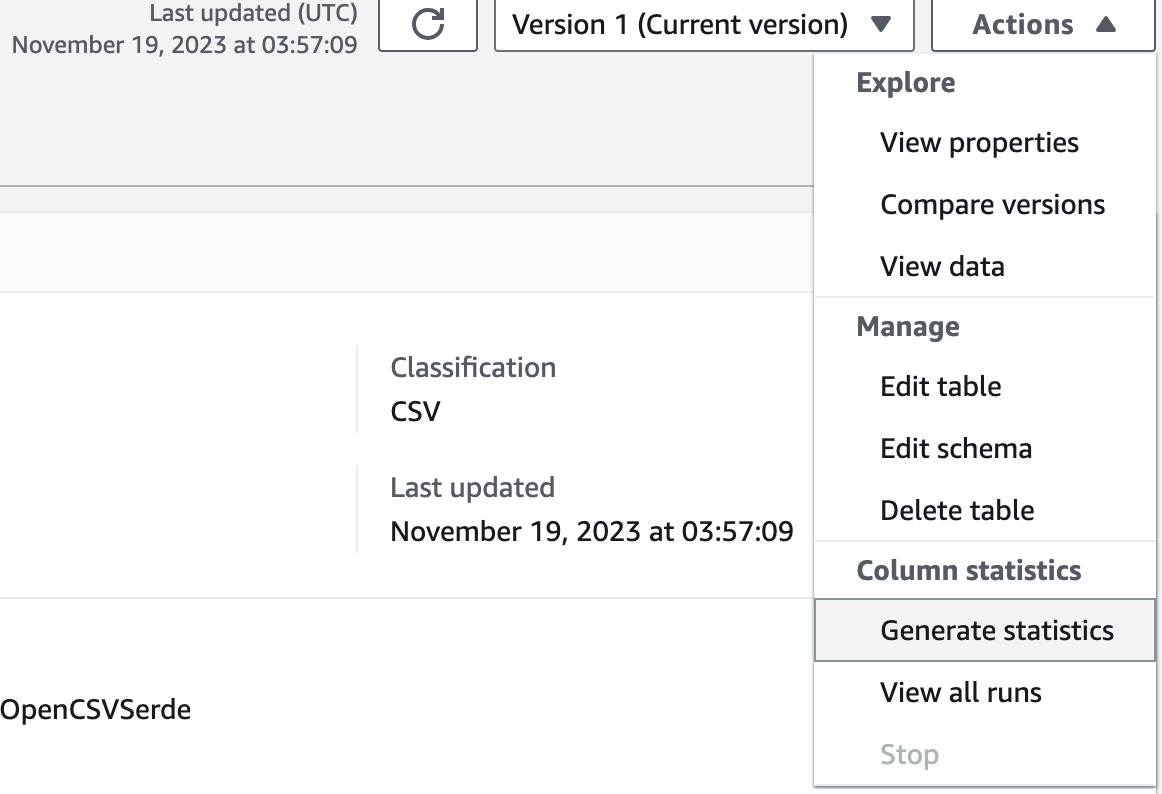
-
当該テーブルのActionのプルダウンから、「Generate statistics」をクリックします。
-
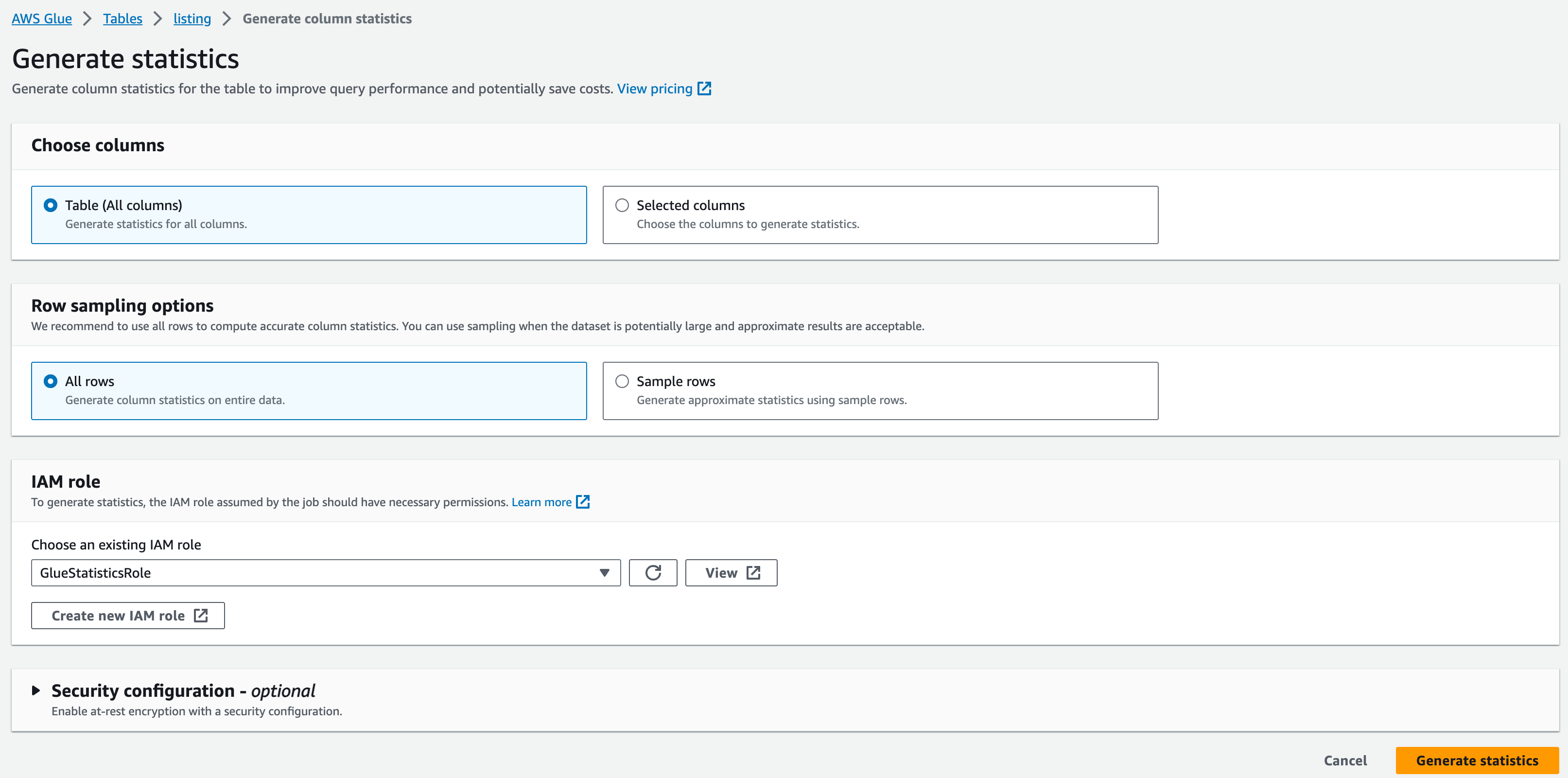
下記を選択し、「Generate statistics」をクリックします。
- Columnは全て
- Rowは全て
- IAMロールは、作成したものを選択
-
4分程度で完了しました。

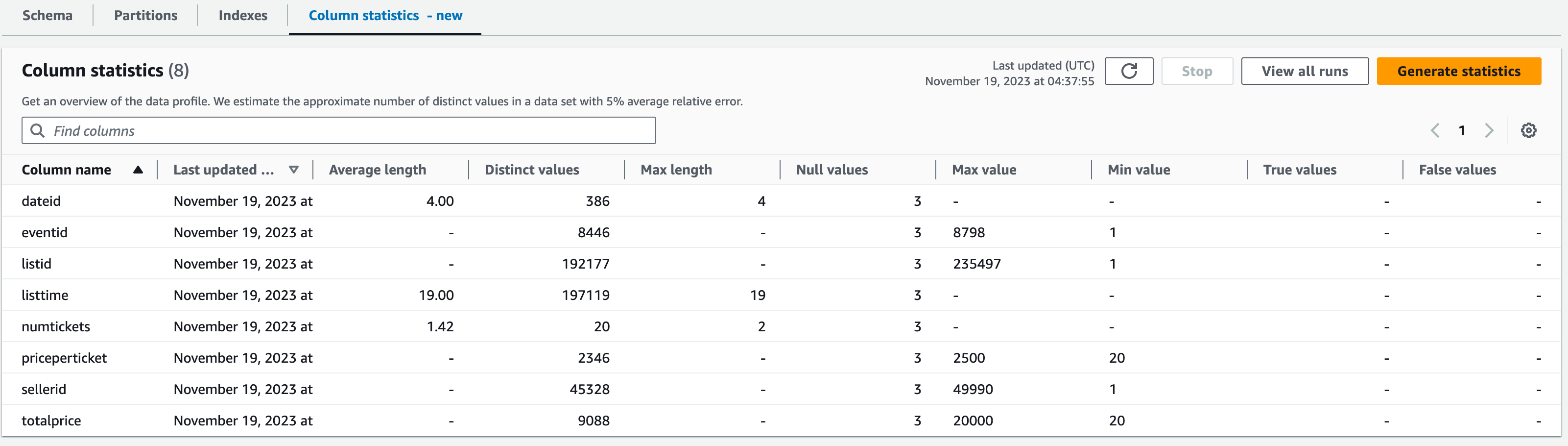
確認
- 確認できました。
考察
Glueデータカタログで統計情報が扱えるようになったことがわかりました。
今回は、性能について確認しませんでしたが、今後は、複雑なクエリを用意し、実行計画の差異や、もう少し大きいデータを用意して性能の違いを確認したいと思います。
参考