背景・目的
前回、Databricks Auto Loaderを試してみたでは、Auto Loaderについて知識の整理や、簡単なハンズオンを試してみました。
今回は、Auto Loaderのファイル通知モードを試してみます。
まとめ
ファイル通知モードで登場するAWSリソースは下記の通り。(だと思います。)

概要
ファイル通知モードの簡単な整理については、こちらにまとめました。
実践
こちらを元に試します
AWS コンソールを使用してインスタンスプロファイルを作成する
- AWSにサインインし、IAMに移動します
- IAMで「ロールを作成」をクリックします
- 「AWSのサービス」>ユースケース「EC2」を選択し、「次へ」をクリックします
- ポリシーは選択せずに、「次へ」をクリックします
- ロール名を入力し、「ロールを作成」をクリックします
- 作成したロールを選択します
- 許可を追加>インラインポリシーを作成をクリックします

- 下記を貼り付け、「次へ」を選択します
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<s3-bucket-name>" ] }, { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObject", "s3:PutObjectAcl" ], "Resource": [ "arn:aws:s3:::<s3-bucket-name>/*" ] } ] } - ポリシー名を入力し、「ポリシーの作成」をクリックします
バケットポリシーを作成する
- 下記のバケットポリシーをS3にアタッチします
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Example permissions", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-s3-access>" }, "Action": [ "s3:GetBucketLocation", "s3:ListBucket" ], "Resource": "arn:aws:s3:::<s3-bucket-name>" }, { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-s3-access>" }, "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObject", "s3:PutObjectAcl" ], "Resource": "arn:aws:s3:::<s3-bucket-name>/*" } ] }
Databricks デプロイを作成した IAMロールを見つける
- アカウントコンソールにログインします
- ワークスペースを選択し、CredentialsボックスのロールARNの末尾にあるロール名をコピーします
EC2 ポリシーに S3 IAMロールを追加する
- AWSのIAMに移動します
- IAMロールから、上記のDatabricksをデプロイで作成したIAMロールを選択します
- 下記をStatement配列の末尾に追加します
{ "Effect": "Allow", "Action": "iam:PassRole", "Resource": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-s3-access>" } - 変更を保存します
インスタンスプロファイルを Databricks に追加する
- ワークスペース管理者としてワークスペースにサインインします
- 画面右上の個人メニューから「Settings」をクリックします
- 「Security」をクリックします
- Instance profilesの「Manage」をクリックします

- 「Add instance profile」をクリックします
- 作成したいIAMロールのInstance profile ARNを貼り付け、「Add」をクリックします

IAMポリシーの作成とアタッチ
- 下記のIAMポリシーを作成します
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DatabricksAutoLoaderSetup", "Effect": "Allow", "Action": [ "s3:GetBucketNotification", "s3:PutBucketNotification", "sns:ListSubscriptionsByTopic", "sns:GetTopicAttributes", "sns:SetTopicAttributes", "sns:CreateTopic", "sns:TagResource", "sns:Publish", "sns:Subscribe", "sqs:CreateQueue", "sqs:DeleteMessage", "sqs:ReceiveMessage", "sqs:SendMessage", "sqs:GetQueueUrl", "sqs:GetQueueAttributes", "sqs:SetQueueAttributes", "sqs:TagQueue", "sqs:ChangeMessageVisibility" ], "Resource": [ "arn:aws:s3:::<bucket-name>", "arn:aws:sqs:<region>:<account-number>:databricks-auto-ingest-*", "arn:aws:sns:<region>:<account-number>:databricks-auto-ingest-*" ] }, { "Sid": "DatabricksAutoLoaderList", "Effect": "Allow", "Action": [ "sqs:ListQueues", "sqs:ListQueueTags", "sns:ListTopics" ], "Resource": "*" }, { "Sid": "DatabricksAutoLoaderTeardown", "Effect": "Allow", "Action": [ "sns:Unsubscribe", "sns:DeleteTopic", "sqs:DeleteQueue" ], "Resource": [ "arn:aws:sqs:<region>:<account-number>:databricks-auto-ingest-*", "arn:aws:sns:<region>:<account-number>:databricks-auto-ingest-*" ] } ] } - IAMロールにアタッチします
クラスタにInstance profileをアタッチ
- Computeをクリックします
- 対象のClusterを選択し、「Edit」をクリックします
- Instance profileで作成したインスタンスプロファイルを選択し、保存します
ファイルの用意
- ファイルを用意します

コード
- Notebookを作成
- 下記のコードを貼り付けます。
option("cloudFiles.useNotifications","true")を追加しています# Import functions from pyspark.sql.functions import col, current_timestamp # Define variables used in code below file_path = "s3://XXXXX/test2" table_name = f"autoloader_test_file_notice" checkpoint_path = f"s3://XXXXX/etl_quickstart/autoloader_test_file_notice" # Clear out data from previous demo execution spark.sql(f"DROP TABLE IF EXISTS {table_name}") dbutils.fs.rm(checkpoint_path, True) # Configure Auto Loader to ingest JSON data to a Delta table (spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.schemaLocation", checkpoint_path) .option("inferSchema","true") .option("cloudFiles.useNotifications","true") .load(file_path) .select("*", col("_metadata.file_path").alias("source_file"), current_timestamp().alias("processing_time")) .writeStream .option("checkpointLocation", checkpoint_path) .trigger(availableNow=True) .toTable(table_name)) - 実行します
- 下記のコードを実行します
df = spark.read.table(table_name) display(df) - 表示されました

AWSリソースの確認
上記の実行により、AWSリソースが作成されているので確認します
S3の確認
- S3のトップページに移動します
- 対象のバケットを選択し、「プロパティ」をクリックします
- イベント通知では、送信先にSNSが指定されています

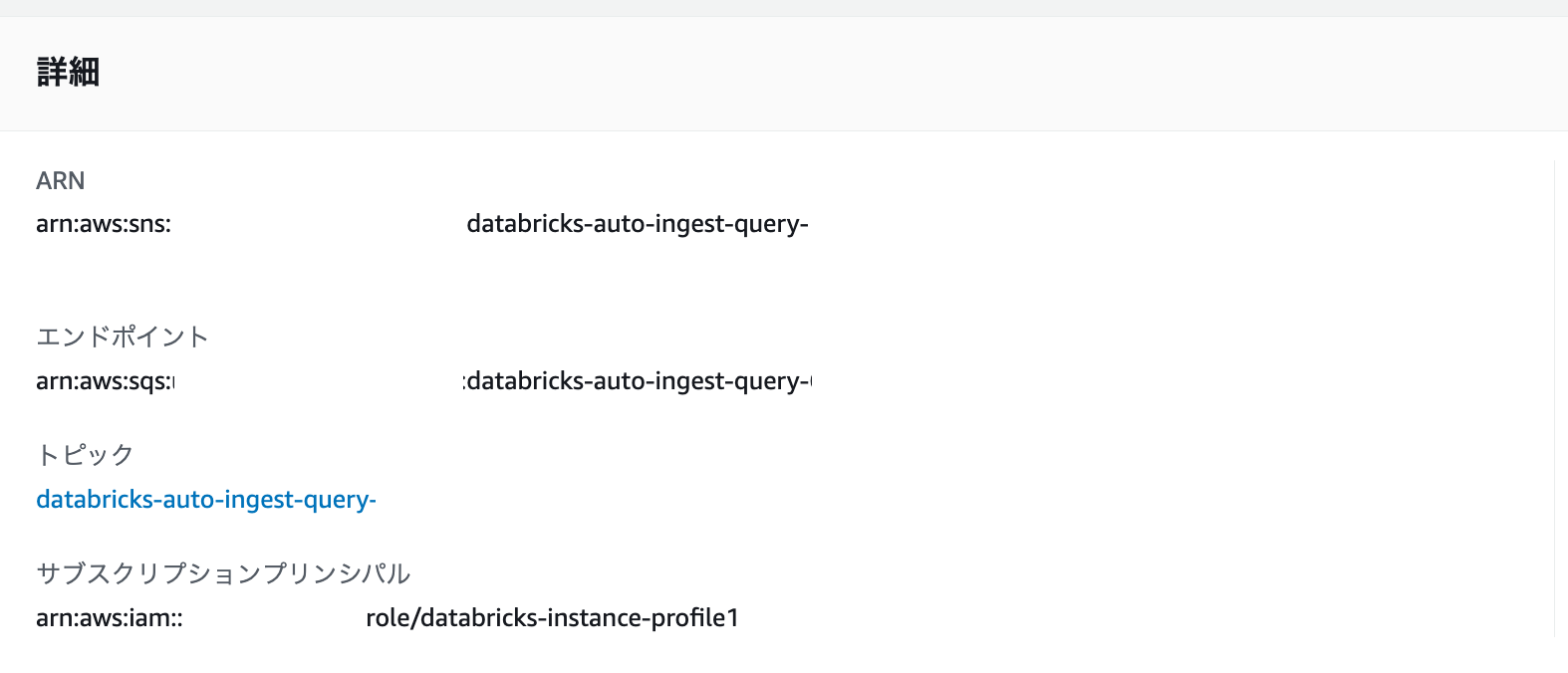
SNSの確認
- SNSのトップページに移動します
- トピックを選択します
- トピックが作成されているので、クリックします

- サブスクリプションをクリックします

- エンドポイントに、SQSが指定されています
SQSの確認
- SQSトップページに移動します
- 作成されていました。クリックします

考察
今回、ファイル通知モードで、Auto Loaderを構成しました。ディレクトリリストモードと比較してスケーラビリティが高い構成とのことで、大量データを扱う場合は良いのかもしれませんね。
しかし、ドキュメントにも記載があるように、ストレージサービス(S3)のファイル通知の仕組みに依存しており、100%を保証していないので、バックフィルが必須とのことでした。次回はバックフィルについて調べてみたいと思います。
参考