背景・目的
昨年12月に、オライリーより「大規模データ管理」(日本語)が出版されたので読んでみました。
本ページでは第6章の整理を行います。
第6章:すべてをまとめる
ここでは、第5章までの内容を様々な視点でアーキテクチャを簡単に振り返っている。
アーキテクチャを下記のデータ管理の原則に結びつける。
- ガバナンス
- データモデリング
- メタデータ管理
全てのアーキテクチャで下記に均一に適用されていることを確認する。
- セキュリティ
- ガバナンス
- メタデータ
- データモデリング
全てのアーキテクチャのデータ設計とインターフェイス設計について説明する。
- どの統合パターンを選ぶべきか
- どの組み合わせが可能か、ハイブリッドやマルチクラウドモデルで何が最も効果など学ぶ
- ドメインのエンドポイントを一意のデータセットと要素を表す抽象化レイヤーに接続することで、一意的な一貫性を確保する方法について見る
アーキテクチャの振り返り
内部ドメインとアプリケーションの複雑さは、他のドメインから隠さないこと。コンシュームに最適化されたデータはデータレイヤーを介して公開しなければならない。
通信とデータ交換を必要とする全てのアプリはデータレイヤーに接続されるが、分離されたまま。ドメインが作業が終えて、データが統合アーキのいずれかを介してコンシュームされる準備が整うと、そのデータは誰でも利用できるようになります。
下記は、3つの異なるアーキテクチャとメタデータがどの様に組み合わせるかを示したオーバビューである。

3つのアーキテクチャは、目的に応じた方法もサポートし、様々なパターンを選択することも可能。
下記に、統合アーキテクチャの各部分がどの様にデータ交換に対応するか整理したものを記載します。
| アーキテクチャ | 特徴 |
|---|---|
| RDSアーキテクチャ | 主にビジネスインテリジェンスや分析など、より大量のデータを扱うユースケースに対応する |
| APIアーキテクチャ | リアルタイムの同期通信に重点を置いたアーキテクチャ。最新アプリケーションだけではなく、レガシーシステム間の通信にも使用できる。 |
| ストリーミングアーキテクチャ | イベント駆動型通信のこと。イベンツ駆動型通信を通じて、リアルタイムにデータを変換し、他のアプリに通知できる。 |
強化パターン
上記に上げたアーキテクチャは、必ずしも単体で使うものではなく。いくつかを組み合わせて互いを強化できる。
ゲートウェイルーティングとインデックステーブル
- RDSとAPIを組み合わせて、クエリトラフィックをRDSへルーティングし、コマンドトラフィックを運用システムへルーティングできる。
- CQRSとよく似ている。
- リアルタイムユースケースと運用ユースケースに対応するには、ゲートウェイルーティングパターンとインデックステーブルを組み合わせる。
- インデックステーブルとは?
- クエリで頻繁に参照されるデータストアのフィールドにインデックスを作成すること
- これらのパターンを使うことで、読み出し専用データストアから取得するデータをアプリがより迅速に特定できるようになりクエリ性能を向上させられる。
分散型RDS
アプリの状態をリアルタイムにRDSに複製することで、特にクエリの多いデータをデータコンシューマーの近くに保存できる。
下記の場合に便利です。
- 運用システムに対する重い読み出しの影響を緩和
- ワークロードをクラウドに移行する際の帯域幅を削減

図) RDSとストリーミングプラットフォーム、APIゲートウェイを組み合わせることで、クラウド帯域を削減することができる例
キューベースの負荷平準化
APIへの大量リクエストが殺到すると、下記のような問題が生じる可能性がある。
- サービスが停止する
- 適切にリクエストに応答しない
解決にはAPIアーキテクチャとストリーミングアーキテクチャを組み合わせてバッファとして機能するキューを作成し、APIアーキテクチャへのリクエストを保持するようにする。
これを、キューベースの負荷平準化とも呼ばれている。
ノーティファイア
データが利用できるようになったことを知らせるためにRDSの通知サービスが必要になる。
この通知には、ストリーミングアーキテクチャを使うべきとのこと。
ストリーミングインジェスト
ストリーミングプラットフォームを使用して、アプリケーションの状態を転送することでRDSを構築する。
複数のNW位置にまたがる分散型RDSを構築する場合に便利。
企業における相互運用性標準
データの所有権や流通が移譲され、非中央集権化されると、企業レベルでの相互運用性やドメイン間通信の標準化が重要になる。
データ管理には、相互運用性と設計原則を明確に設定する事が重要で、RDS、API、ストリーミングイベントであまり違いはない。
安定したデータエンドポイント
互いのデータに直接アクセスするアプリケーションは密結合であり、何かしらの変更が他のアプリケーションに直接影響する。
そのため、多くのソフトウェアアーキテクトや、ソフトウェアエンジニアは結合型アーキテクチャを構築しないようにしている。
Scaled Architectureでは、データプロバイダーとデータコンシューマのアプリケーションが主に結合するのは、データレイヤーであり、
完全に自律し、相手のことを意識しないことが理想像。これを実現するには、結合に関していくつかの原則を設定する必要がある。
Scaled Architectureでは、ドメインが互いのインタフェイスを使用する際に、スキーマの互換性を保証する必要がある。
よくある問題として、データベースの構造は時間の経過とともに変化する。例えば以下のようなことが起き、クエリが失敗することになります。
- 新しいカラムが追加され、古いカラムが削除される。
- カラムは複数のカラムに変換されることもある
スキーマの進化は、データベース構造の変更に対処し、スキーマの互換性を保つプロセス。このスキーマの進化はデータ管理に置いて重要。
理想的なのは、ドメインが新旧スキーマを持つデータをシームレスに扱えるようにすること。
スキーマの進化には、互換性の問題への対処も含まれている。互換性には、下記のようなものがあります。
| 互換性の種類 | 概要 | 例 |
|---|---|---|
| 後方互換性 | 新しいスキーマを使用するドメインが、以前のスキーマで作成されたデータを読めるようにすることを意味する。 | フィールドを削除しデフォルト値に設定すること |
| 前方互換性 | 新しいスキーマで提供されたデータが古いスキーマを使うドメインで利用できることを意味する。 | 新しいフィールド追加や、オプションフィールドの削除が挙げられる。 フィールドを追加してデータを提供してもデータが欠落することはないため、ドメインに直接影響与えない。 |
| 完全互換性 | スキーマが後方互換性と前方互換性を両方を持っていることを意味する。 スキーマは古いデータを新しいスキーマで読み出すことできるように進化している。 |
前方と後方の組み合わせ |
互換性の管理は、多くの場合、バージョン管理によって行われる。ベストプラクティスは、v.MAJOR.MINOR.PATCHというバージョン管理方法を使うこと。
システムやインターフェイスの根本的な変更が必要で、互換性が保証されない場合は、新しいインタフェイスを作成する必要がります。
インタフェイスが壊れるような変更を管理、防止するための方法としては、データ配信契約(サービス契約)を使用する方法がある。
データ配信契約
Scaled Architectureの中でも非常に重要な点。広く使われるようになるとバージョン管理の実装、互換性・配備の管理が必要になる。
これをしないと、再利用率が低くなりインタフェイスが壊れる可能性がある。
2つの契約レベルは下記のとおりです。
| 最も基本的なレベル | 高度なレベル | |
|---|---|---|
| 概要 | 全てのインタフェイスの契約をドキュメント化 | インタフェイスやダッシュボードを介して全てのドメインが契約データを利用できること これによりドメインはCI/CDのパイプラインでテストルーチンを自動化できる。 インタフェイスのどの部分がコンシュームされるか知ることで、チームは配信・公開されるあらゆるデータに対して検証を行うテストルーチンを作成できる。 構造に対して検証することで互換性を保証する。 |
| 登録される内容 | スキーマ 転送携形態 アプリケーションとの関係 |
左記の通り |
| 保存場所 | メタデータリポジトリ | 左記の通り |
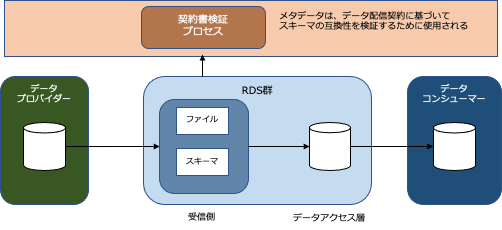
RDSハンドシェイクサービス
アーキテクチャのRDS検証モデルを強化するために、ハンドシェイクサービスを実装することができます。
ハンドシェイクサービスは、下記の機能や特徴がある。
- データ配信後に確認や検証を行いエラーコードを返す。
- RDSへのデータ配信は全てログに記録され、監視される。
アクセス可能でアドレス可能なデータ
データをアクセス可能でアドレス指定可能にするには、下記を管理しておく必要があります。
- プロトコルやデータ形式
- リソース
- ストレージ
- イベント
- APIの位置
さらに、効率的にするには、全てのURIを中央リポジトリやConsulなどの構成管理システムで公開を検討する。
ネットワーク間通信の原則
データグラビティでは、データにも重力がありデータのあるところにサービスやアプリケーションをデータの近くに引き寄せられると解説されています。
パブリッククラウドやSaaS、オープンデータを使用した場合に、すべてのデータを中央に保存することで大きな問題が生じる。
同じデータを何度もコピーすると、NW帯域がすぐに足りなくなる。
消費地に向けてデータを複製する
NW帯域が不足する問題の解決策は、ステートフルな処理をコンシュームされる場所に分散させること。

- 遅延と帯域幅の問題を解決するために、APIゲートウェイにキャッシュレイヤーを追加することを推奨する
- MW上で行ったり来たりルーティングされることになるため、分離は常にデータの発生の近くで行われるのが原則。
非同期の発想で考える
ネットワークをまたぐ場合に、障害発生するとアプリケーションはそのデータにアクセスできなくなる。そのため非同期の発想で考える。
下記の利点と欠点があります。
| 利点 | 欠点 |
|---|---|
| ・最小限の影響にとどまる ・負荷が増加した場合に、よりかんたんにスケールアップできる ・アプリケーション通信は、一時的なNW障害に対して、より堅牢 ・再送機構、フォールバック機能、連鎖的な影響を抑止するサーキットブレイカーなど耐障害性を高める重要な機能を実装できる |
・通信がリアルタイムにで行われないため、何か問題が発生した場合にデバックや調査が難しい ・アプリケーションのコンポーネントを追加しなければならない場合がある。 |
ドメインの分離
同期/非同期の分離は、ドメイン駆動設計と強い関係がある。同期通信と非同期通信パターンに関する原則を追加する。

上記では、5つのドメインがあり、下記のパターンがあります。
- すべてのアプリ通信はドメイン境界内にとどまる。アプリのコンテキストは同じまま。結合度が高いのでこれらのアプリは一緒に配備が良い。同じリソースグループや仮想プライベートネットワークを使う。
- 通信は物理環境内にとどまるが、ドメインを超える。データが境界を超えるときにコンテキストが変わる。アプリ通信は同じ物理環境内で行われるが、各ドメインのコンピュートリソースは異なるリソースグループや仮想プライベートNWに配備する。
- 通信は物理環境とドメインの両方を超える。アプリが障害に見舞われる可能性が高い。そのため耐障害性をさらに考慮する必要がある。
- 通信はドメイン内にとどまるが、データはNWを超えて複製される。アプリのコンテキストは変わらないと想定されるが、NWに影響されるのでNWに関する考慮が必要
- SaaSプロバイダーや外部のコンシューマーなど外部パーティとの通信が発生。データが企業環境から離れるのでセキュリティやNWについて考慮しなければならない。
NWプラットフォームの接続性の問題に悩まされないため、可能な限り非同期通信にすることを推奨する。原則としてはコンテキスト境界を超える場合は、データレイヤーをその原則とともに使用する。
すべてのメタデータを捕捉する。
例外的な場合
遅延が問題となるアプリケーションの場合、データレイヤーを使わずにドメインやアプリケーションを超えてデータを流通させる例外がある。
例えば、銀行など支払いを速く処理するかが強く求められる場合など。
ハブスポークネットワークリポジトリ
より強く分離する方法は、ネットワークでドメインを分離するハブスポークネットワーク型ネットワークアーキテクチャを使う。
- ハブ
- データレイヤのコンポーネントを含めた共有サービスは、ハブに配置し異なるドメインへの橋渡しを行う。(ピアリングとも言う。)
- セキュリティとIDアクセス管理の制御を追加することもできる
- スポーク
- ドメイン内のリソースは分離され論理的に独立したネットワークに配備。
エンタープライズ標準
分散型へのデータ所有権への移行は、データ製品に幅広い標準を適用して初めて機能する。企業標準がない状態での分散と接続は、無秩序、混乱、非互換性が生まれる。
消費最適化の原則
データ消費に真剣に取り組むには、データを資産として捉える必要がある。この理念の基、下記についてそれぞれのデータオーナーが責任を負う必要がある。
- データ品質
- 表現力
- 粒度
- 情報のリッチさ
データコンシューマにとって、データが理解・利用しにくいものになってしまうため、データはできるだけ多くのコンシューマに提供できるように適度な粒度で提供されなければならない。
データコンシューマが複雑なアプリロジックを構築したり、大規模な結合を実行したり、データを解釈したりするのに苦労したりするのは避けたい。
そのためには、下記に示すインタフェイス設計に関するガイドラインに従うようにチームに強く求める。
- RDS、API、ストリームのいずれに対しても、汎用的なブループリントとしてデータエンドポイントを設計する。可能なら全て同じメタデータまたはコードから生成されることが望ましい。
- 消費最適化されたデータを提供する。
- 過度に正規化された物理モデルや過度に技術的な物理モデルをより再利用しやすく論理的にグループ化されたデータセットに変換する必要がある。
- これをドメイン集約と呼ぶ。
- データとコンテキストは、運用システムやトランザクションシステムが生成するものに近いものにする
- データプロバイダーは自分のデータモデルを他のドメインのニーズに合わせてはならない。
- できるだけ多くのドメインが再利用できるような包括的なデータセットを提供する。
- あるデータコンシューマだけのために非常に特殊なデータ形式を使わない。
- データ利用者が本当に関心の高いデータのみ提供する
- システム内でのみ使用されるデータは提供しない
- データ要素は不可分でなければならない
- その属性はこれ以上意味のあるサブコンポーネントに分割できないようなものにする
- 不可分なデータ要素は、正確な意味を持つ。
- 正しい値を得るために、データの分割や連結、複雑なロジックの実行などをドメインに矯正すべきではない
- 一貫性のあるドメイン識別子を使用する
- 相互参照と外部キーの関係性は、データセット全体を通して不可欠。一貫性をもつ必要がある
- データコンシューマがデータセットを結合する際には、キーを操作する必要がないようにする。
- データは、データセット全体で一貫した形式とする
- 表現形式、構文が同じであること
- コンシューマ側で正しい値を得るためにアプリケーションロジックを適用する必要がないようにする
- ローカルでマスタではない参照データは、変化しやすいので消費しやすい安定した粒度の粗いデータに抽象化する必要がある。
- データが参照データ管理やマスタデータ管理の対象の場合、エンタープライズ識別子を提供する。
上記のインタフェイス設計ガイドラインに従って、データコンシューマの視点からシステムを見ると2つの変換ステップが必要である。
- データがデータプロパイダーからRDSをなどのデータデータレイヤに配信されるとき
- このときには、コンテキストは変わらない。
- データレイヤーからデータコンシューマのアプリにデータが渡されるとき
- コンテキストは変わる。
メタデータの検索性
データレイヤのデータエンドポイントの所有権と説明責任は常に提供側のドメインにある。
例えば、RDS、API、ストリーミングエンドポイントを使って同時にデータを配信した場合でも、所有権は全て同じドメインで、同じコンテキスト境界に属する。
データの所有権とガバナンスは、データの透明性と信頼性を確保する上で重要な要素である。
データの所有権、ゴールデンデータ絵sっと、インタフェイスに関するメタデータを全てのドメインで利用できるようにするためには、エンタープライズメタデータモデルを活用する。
意味的一貫性
検索機能を実現するためには、データの一貫性を守ることも重要です。そのためには、アプリケーションのデータモデルとインタフェイスモデルを十分にドキュメント化される必要がある。
特に重要なことは、全てのデータ属性がゴールデンデータセットの要素につながっている必要がある
対応するメタデータの提供
スケーラブルなアーキテクチャを実現するための労力の大半は、メタデータ駆動型のアーキテクチャを実現することに費やされる。
データを検索しやすくし、他者が使用・再利用できるようにし、適切な制限をかけるにはデータの中にメタデータを埋め込むことが必要。
様々なシステム間でデータを簡単に転送できるようにし、ロックインを回避するためにはメタデータを公開して、全てのパーティが利用できるようにすることも必要。
検索性を高めるためには、最終的には全てがカタログ、レジストリ、開発者ポータルに集約されないとならない。
データの出どころと移動
リネージは、データガバナンスの中でも非常に重要。データが企業内を流れる際のトレーサビリティを提供する。このような情報は、下記の目的で必要。
- コンプライアンス
- 法規制
- プライバシー
- 倫理
- アドバンスドアナリティクスモデルの再現性と透明性
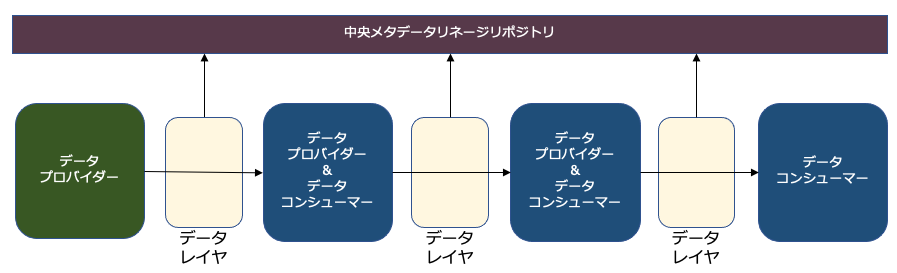
常にリネージを把握するためには、必ずデータレイヤーを使用することが原則になる。
これにより、データが消費され、コンシューマ側で変換され、流通するたびにデータレイヤーが何度も再利用される。
データレイヤーのリネージは、データが通過するたびに自動的に生成されたり、ドメインによって手動で作成・配信される。
リネージは中央のリネージリポジトリの中に保存されます。適切に設計されていれば、全てのアーキテクチャの統合コンポーネントは自動的にリネージをインジェストすることができる。
リネージの最低限の要件としては、どのアプリケーションが、どの統合アーキ、プラットフォーム、統合機能を使用して度のデータを変換したかを特定すること。
参考