背景・目的
- Glueで、50KiB/個 * 204,800,000個程度のファイルを、一定程度の個数(1,000個)を読み込むジョブを組みました。(これをファイルがなくなるまでループします、)
- 8H程度処理したタイミングでログを確認したところ、一回あたりの処理時間が延びてきた(※)ので原因を調査することにしました。いくつか選択肢がありますが、まずはメトリクスから確認してみます。
- ※ 処理時間(CWLに出力したログから算出)
- 49〜50回目あたりから徐々に遅くなり、65回目から急激に遅くなっている。
| ループ回数 | 実行時間 | 処理時間 |
|---|---|---|
| 1 | 2022-01-05T12:50:42.059+09:00 〜 2022-01-05T12:58:44.038+09:00 | 8分2秒 |
| 2 | 2022-01-05T12:58:44.038+09:00 〜 2022-01-05T13:06:17.517+09:00 | 7分33秒 |
| 3 | 2022-01-05T12:58:44.038+09:00 〜 2022-01-05T13:06:17.517+09:00 | 7分33秒 |
| ・・・ | ・・・ | ・・・ |
| 30 | 2022-01-05T16:25:19.703+09:00 〜 2022-01-05T16:32:47.366+09:00 | 7分26秒 |
| ・・・ | ・・・ | ・・・ |
| 45 | 2022-01-05T18:14:45.379+09:00 〜 2022-01-05T18:22:13.846+09:00 | 7分28秒 |
| ・・・ | ・・・ | ・・・ |
| 45 | 2022-01-05T18:14:45.379+09:00 〜 2022-01-05T18:22:13.846+09:00 | 7分28秒 |
| ・・・ | ・・・ | ・・・ |
| 47 | 2022-01-05T18:29:46.142+09:00 〜 2022-01-05T18:37:37.690+09:00 | 7分50秒 |
| 48 | 2022-01-05T18:37:37.690+09:00 〜 2022-01-05T18:45:39.013+09:00 | 8分2秒 |
| 49 | 2022-01-05T18:45:39.013+09:00 〜 2022-01-05T18:54:38.037+09:00 | 8分59秒 |
| 50 | 2022-01-05T18:54:38.037+09:00 〜 2022-01-05T19:04:01.441+09:00 | 9分23秒 |
| ・・・ | ・・・ | ・・・ |
| 55 | 2022-01-05T19:34:21.661+09:00 〜 2022-01-05T19:43:16.255+09:00 | 8分55秒 |
| ・・・ | ・・・ | ・・・ |
| 61 | 2022-01-05T20:22:19.254+09:00 〜 2022-01-05T20:31:21.600+09:00 | 9分2秒 |
| ・・・ | ・・・ | ・・・ |
| 64 | 2022-01-05T20:47:47.055+09:00 〜 2022-01-05T20:57:16.245+09:00 | 9分29秒 |
| 65 | 2022-01-05T20:57:16.245+09:00 〜 2022-01-05T21:47:33.050+09:00 | 50分17秒 |
| 66 | 2022-01-05T21:47:33.050+09:00 〜 2022-01-06T00:15:47.033+09:00 | 2時間28分14秒 |
| 67 | 2022-01-06T00:15:47.033+09:00 〜 2022-01-06T01:42:51.212+09:00 | 2時間26分64秒 |
| 68 | 2022-01-06T01:42:51.212+09:00 〜 2022-01-06T07:19:12.011+09:00 | 5時間34分21秒 |
- ここでは、遅くなっている原因の調査は別途行うとして、CloudWatchメトリクスを通して、各種指標を確認することを目的としています。
結論
- CloudWatchメトリクスにより、ディスク使用率、CPU使用率、NW転送量、メモリ使用率が分かる。
- プログラムでのメモリの使い方が怪しい事がわかった。
内容
設定方法
- Glue>ジョブで該当ジョブを選択しメトリクスタブを選択
- 追加メトリクスの表示をクリック
- 1/5 3:40 +00:00〜1/5 22:30+00:00を選択します。(UTCのため、上記のログから-9H)

-
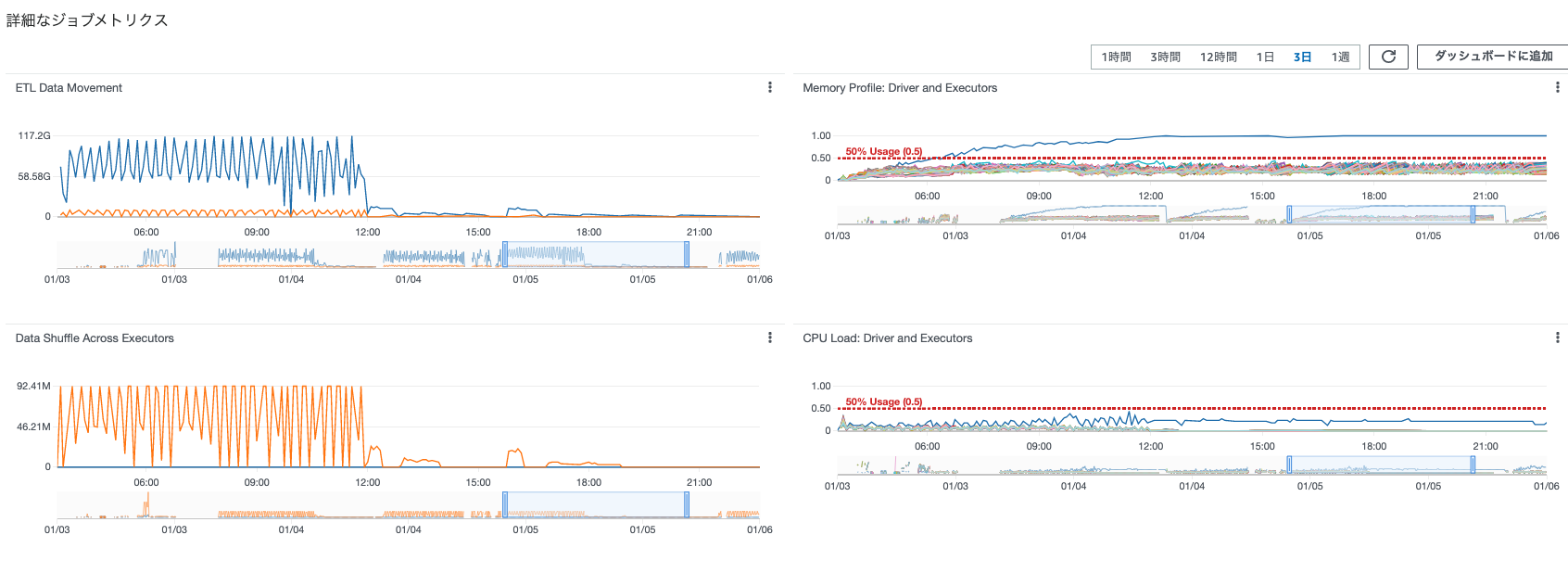
ETL DataMovementでは、以下の情報がわかります。
- オレンジ線: S3 Bytes Written
- 青線:S3 Bytes Read
- グラフの波形を見ると、12:00(JSTだと、21:00頃)からReadが行われていない事がわかります。この時間帯は65回目の処理(処理時間が50分17秒)が該当します。何らかが原因でReadがうまくできてなかったことがわかります。
-
Memory Profile : Driver and Executorsでは以下の情報がわかります。
- DriverとExecutorごとのメモリ使用率
- これをみるとDriverのメモリ使用率が徐々に上がり、1/5 6:00頃(JST 15:00頃)に50%を超過、1/5 12:00頃(JST21:00頃)にほぼ100%達していることがわかります。
- その他のExecutorは一定の使用率を保っていることがわかります。
- つまり、Driverプログラムで何らかしらの原因でメモリ使用量が増え続け、使用量100%に達した時点でRead処理に時間を要していることがわかります。
4.追加メトリクスの表示をクリックします。
5.詳細なジョブメトリクス画面で、前画面と同様に1/5 3:40 +00:00〜1/5 22:30+00:00を選択します。(UTCのため、上記のログから-9H)
- ETL Data MovementとMemory Profile: Driver and Executorsは、前画面と同様なので割愛します。
- Data Shuffle Across Executorsから、以下のことがわかります。
- Executor間のシャッフルによるデータ量がわかります。
- オレンジ線:Shuffle Bytes Written
- 青線:Shuffle Bytes Read
- これを見ると一回の処理で100M程度のシャッフルが行われていることがわかります。また、12:00(JST 21:00)以降では処理が行われていません。これは前述したとおり、そもそもS3のReadで処理がおこなわれてないためと考えられます。
- CPU Load: Driver and Executorsから以下のことがわかります。
- DriverのCPU使用率は50%程度
- 50%を超過しているものはない。
- 12:00(JST21:00)以降では、DriverのCPU使用率は一定以上で使われ続けている。

- Job Execution: Active Executors, Completed Stages & Maximum Needed Executors
- アクティブなExecutor、ステージの完了と、必要な最大Executorがわかる。(ちょっとわからないので後ほど調べる。)
考察
- デフォルトのCloudWatchメトリクスでボトルネックがCPU、メモリ、NWなのかまでわかりそう。
参考