背景・目的
前回、OpenSearchについて整理しましたが、今回はベクトル検索を整理します。
まとめ
下記に特徴を整理します。
| 特徴 | 説明 |
|---|---|
| ベクトル検索とは | 最近傍検索ともいわれている 特定の入力に最も類似する項目を見つけるための強力な手法 |
| 使用例 | ・ユーザの意図を理解するためのセマンティック検索 ・レコメンド ・画像認識 ・不正検出 |
| Vector embeddings | ・テキスト、画像、音声などの数値表現であるベクター埋め込みを使用 ・多次元ベクターとして保存され、意味、コンテキスト、構造のより深いパターンと類似性を捉える ・LLMは、入力テキストからベクター埋め込みを作成できる |
| Similarity search | ・vector embeddingは、高次元空間内のベクトル ・位置と方向は、オブジェクト間の意味のある関係を捉える ・ベクトル検索は、クエリ ベクトルを保存されたベクトルと比較し、最も近い一致を返すことで、最も類似した結果を見つける ・OpenSearch は、k 近傍法 (k-NN) アルゴリズムを使用して、最も類似したベクトルを効率的に識別する ・正確な単語の一致に依存するキーワード検索とは異なり、ベクトル検索は、この高次元空間内の距離に基づいて類似性を測定する |
| Calculating similarity | ベクトル類似度は、多次元空間における2つのベクトルの近さを測定 最近傍検索や関連性による結果のランク付けなどのタスクを容易にする |
| サポートしている距離メトリック(空間) | OpenSearchはベクトル類似度を計算するための複数の距離メトリック(空間)をサポートしている ・L1(Manhattan distance) ・L2 (Euclidean distance) ・L∞ (Chebyshev distance) ・Cosine similarity ・Inner product ・Hamming distance ・Hamming bit |
| ベクトル検索の実装 | k 近傍検索 (k-NN 検索) |
| K-NN検索 | ベクトルのインデックス全体でクエリ ポイントに最も近い k 個の近傍を検索する 近傍点を決定するには、ポイント間の距離を測定するために使用する空間 (距離関数) を指定できる |
| ベクトルのインデックスから k 近傍を取得する | ・Approximate search (approximate k-NN, or ANN) ・Exact search |
概要
Vector search basics
下記を基に整理します。
Vector search, also known as similarity search or nearest neighbor search, is a powerful technique for finding items that are most similar to a given input. Use cases include semantic search to understand user intent, recommendations (for example, an “other songs you might like” feature in a music application), image recognition, and fraud detection. For more background information about vector search, see Nearest neighbor search.
- ベクトル検索は、最近傍検索ともいわれている
- 特定の入力に最も類似する項目を見つけるための強力な手法
- 使用例
- ユーザの意図を理解するためのセマンティック検索
- レコメンド
- 画像認識
- 不正検出
Vector embeddings
Unlike traditional search methods that rely on exact keyword matches, vector search uses vector embeddings—numerical representations of data such as text, images, or audio. These embeddings are stored as multi-dimensional vectors, capturing deeper patterns and similarities in meaning, context, or structure. For example, a large language model (LLM) can create vector embeddings from input text, as shown in the following image.
-
テキスト、画像、音声などの数値表現であるベクター埋め込みを使用
-
多次元ベクターとして保存され、意味、コンテキスト、構造のより深いパターンと類似性を捉える
-
LLMは、入力テキストからベクター埋め込みを作成できる

Similarity search
A vector embedding is a vector in a high-dimensional space. Its position and orientation capture meaningful relationships between objects. Vector search finds the most similar results by comparing a query vector to stored vectors and returning the closest matches. OpenSearch uses the k-nearest neighbors (k-NN) algorithm to efficiently identify the most similar vectors. Unlike keyword search, which relies on exact word matches, vector search measures similarity based on distance in this high-dimensional space.
- vector embeddingは、高次元空間内のベクトル
- 位置と方向は、オブジェクト間の意味のある関係を捉える
- ベクトル検索は、クエリ ベクトルを保存されたベクトルと比較し、最も近い一致を返すことで、最も類似した結果を見つける
- OpenSearch は、k 近傍法 (k-NN) アルゴリズムを使用して、最も類似したベクトルを効率的に識別する
- 正確な単語の一致に依存するキーワード検索とは異なり、ベクトル検索は、この高次元空間内の距離に基づいて類似性を測定する
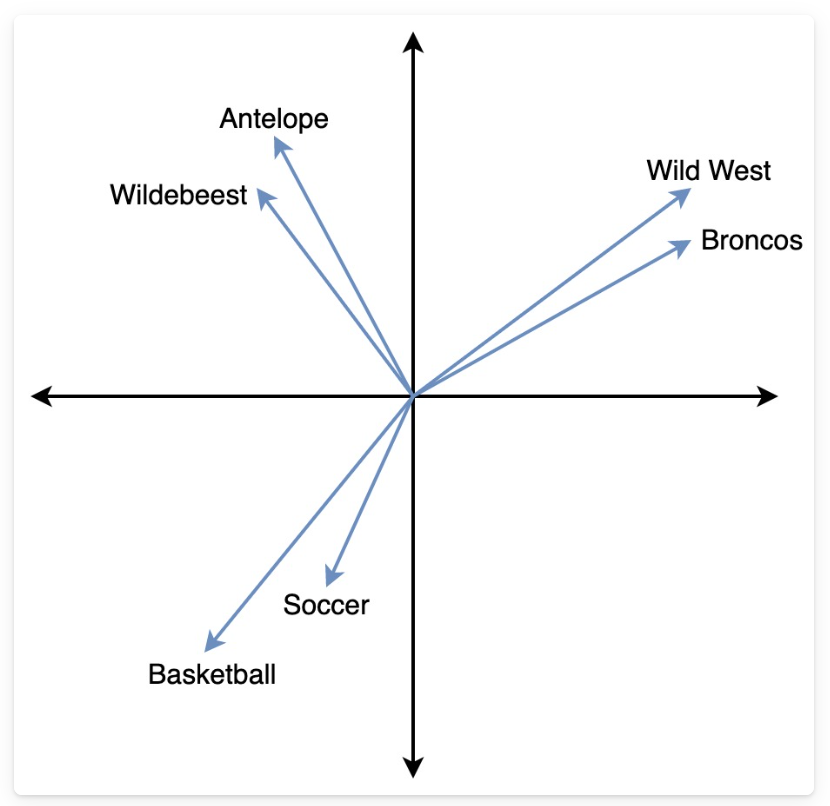
In the following image, the vectors for Wild West and Broncos are closer to each other, while both are far from Basketball, reflecting their semantic differences.
Calculating similarity
Vector similarity measures how close two vectors are in a multi-dimensional space, facilitating tasks like nearest neighbor search and ranking results by relevance. OpenSearch supports multiple distance metrics (spaces) for calculating vector similarity:
- L1 (Manhattan distance): Sums the absolute differences between vector components.
- L2 (Euclidean distance): Calculates the square root of the sum of squared differences, making it sensitive to magnitude.
- L∞ (Chebyshev distance): Considers only the maximum absolute difference between corresponding vector elements.
- Cosine similarity: Measures the angle between vectors, focusing on direction rather than magnitude.
- Inner product: Determines similarity based on vector dot products, which can be useful for ranking.
- Hamming distance: Counts differing elements in binary vectors.
- Hamming bit: Applies the same principle as Hamming distance but is optimized for binary-encoded data.
- ベクトル類似度は、多次元空間における2つのベクトルの近さを測定
- 最近傍検索や関連性による結果のランク付けなどのタスクを容易にする
- OpenSearchはベクトル類似度を計算するための複数の距離メトリック(空間)をサポートしている
- L1(Manhattan distance):ベクトル成分間の絶対差を合計
- L2 (Euclidean distance): 二乗差の合計の平方根を計算し、大きさに応じて変化させる
- L∞ (Chebyshev distance): 対応するベクトル要素間の最大絶対差のみを考慮
- Cosine similarity: 大きさではなく方向に焦点を当てて、ベクトル間の角度を測定
- Inner product: ベクトルのドット積に基づいて類似性を判断します。これはランキングに役立つ
- Hamming distance: バイナリ ベクトル内の異なる要素をカウント
- Hamming bit: ハミング距離と同じ原理を適用しますが、バイナリエンコードされたデータに最適化されている
To learn more about the distance metrics, see Spaces.
Preparing vectors
下記を基に整理します。
In OpenSearch, you can either bring your own vectors or let OpenSearch generate them automatically from your data. Letting OpenSearch automatically generate your embeddings reduces data preprocessing effort at ingestion and search time.
OpenSearch では、下記が可能
- 独自のベクトルを使用する
- OpenSearch にデータからベクトルを自動的に生成させる
Option 1: Bring your own raw vectors or generated embeddings
You already have pre-computed embeddings or raw vectors from external tools or services.
- すでにベクトルがある場合
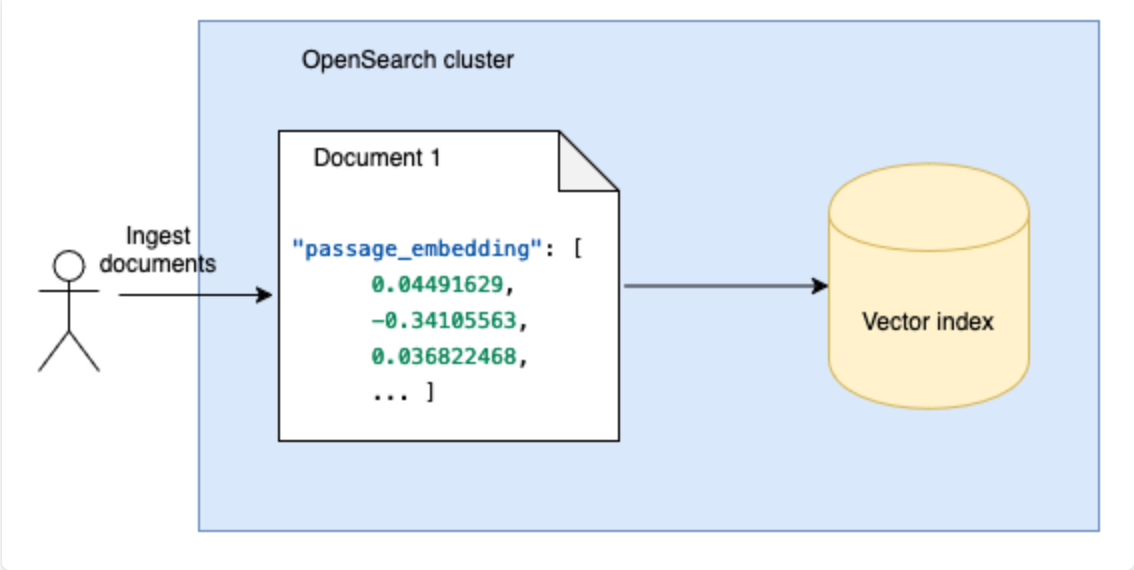
- Ingestion: Ingest pregenerated embeddings directly into OpenSearch.
Ingestion:
事前に生成された埋め込みを OpenSearch に直接取り込む
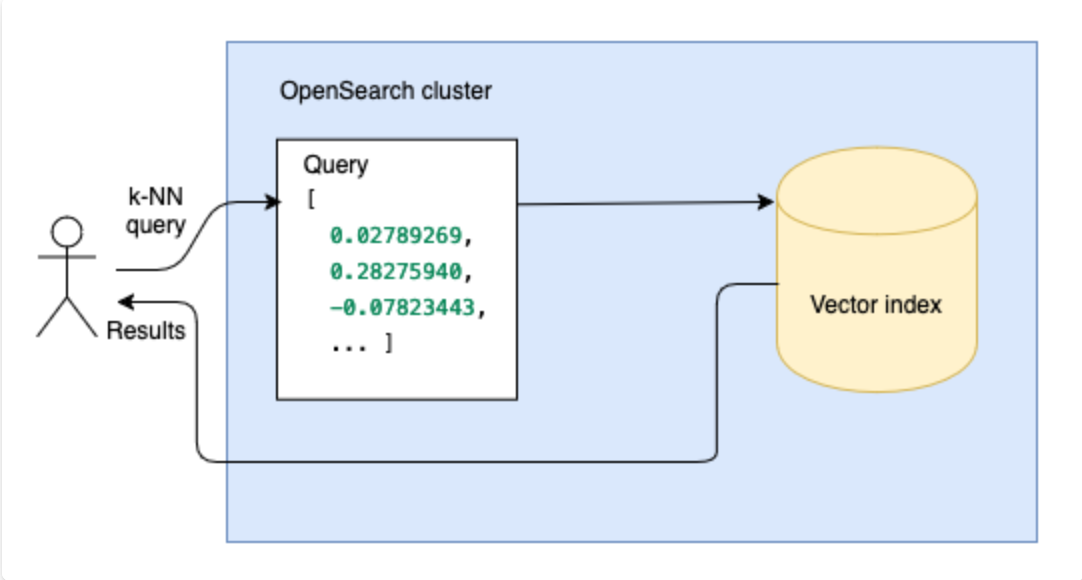
- Search: Perform vector search to find the vectors that are closest to a query vector.
Search:
ベクトル検索を実行して、クエリ ベクトルに最も近いベクトルを検索する
Option 2: Generate embeddings within OpenSearch
Use this option to let OpenSearch automatically generate vector embeddings from your data using a machine learning (ML) model.
- OpenSearch は機械学習 (ML) モデルを使用してデータからベクトル埋め込みを自動的に生成する
- Ingestion: You ingest plain data, and OpenSearch uses an ML model to generate embeddings dynamically.
Ingestion:
プレーンなデータを取り込むと、OpenSearch は ML モデルを使用して埋め込みを動的に生成

- Search: At query time, OpenSearch uses the same ML model to convert your input data to embeddings, and these embeddings are used for vector search.
Search:
クエリ時に、OpenSearch は同じ ML モデルを使用して入力データを埋め込みに変換し、これらの埋め込みはベクトル検索に使用される

Vector search techniques
下記を基に整理します。
OpenSearch implements vector search as k-nearest neighbors, or k-NN, search. k-NN search finds the k neighbors closest to a query point across an index of vectors. To determine the neighbors, you can specify the space (the distance function) you want to use to measure the distance between points.
- OpenSearchは、ベクトル検索を k 近傍検索 (k-NN 検索) として実装されている
- K-NN検索は、ベクトルのインデックス全体でクエリ ポイントに最も近い k 個の近傍を検索する
- 近傍点を決定するには、ポイント間の距離を測定するために使用する空間 (距離関数) を指定できる
OpenSearch supports three different methods for obtaining the k-nearest neighbors from an index of vectors:
- Approximate search (approximate k-NN, or ANN): Returns approximate nearest neighbors to the query vector. Usually, approximate search algorithms sacrifice indexing speed and search accuracy in exchange for performance benefits such as lower latency, smaller memory footprints, and more scalable search. For most use cases, approximate search is the best option.
- Exact search: A brute-force, exact k-NN search of vector fields. OpenSearch supports the following types of exact search:
- Exact search with a scoring script: Using a scoring script, you can apply a filter to an index before executing the nearest neighbor search.
- Painless extensions: Adds the distance functions as Painless extensions that you can use in more complex combinations. You can use this method to perform a brute-force, exact vector search of an index, which also supports pre-filtering.
- ベクトルのインデックスから k 近傍を取得するための 3 つの異なる方法をサポートしている
- Approximate search (approximate k-NN, or ANN):
- 通常、近似検索アルゴリズムは、レイテンシの短縮、メモリ使用量の削減、検索のスケーラビリティの向上などのパフォーマンス上の利点と引き換えに、インデックス作成速度と検索精度を犠牲にする
- ほとんどのユースケースでは、近似検索が最適なオプション
- Exact search:
- ベクトル フィールドのブルート フォースによる完全 k-NN 検索
- OpenSearch は、次の種類の完全検索をサポートしている
- Exact search with a scoring script
- スコアリングスクリプトを使用すると、最近傍検索を実行する前にインデックスにフィルターを適用できる
- Painless extensions
- より複雑な組み合わせで使用できる Painless 拡張機能として距離関数を追加する
- この方法を使用すると、インデックスのブルートフォース、正確なベクトル検索を実行できる
- 事前フィルタリングもサポート
- Exact search with a scoring script
- Approximate search (approximate k-NN, or ANN):
In general, you should choose the ANN method for larger datasets because it scales significantly better. For smaller datasets, where you may want to apply a filter, you should choose the custom scoring approach. If you have a more complex use case in which you need to use a distance function as part of the scoring method, you should use the Painless scripting approach.
- 一般に、大規模なデータセットの場合は、スケーリングが大幅に優れているため、ANN メソッドを選択する必要がある
- フィルターを適用する可能性のある小規模なデータセットの場合は、カスタム スコアリング アプローチを選択する必要がある
- スコアリング方法の一部として距離関数を使用する必要がある、より複雑なユースケースがある場合は、Painless スクリプト アプローチを使用する必要がある
Approximate search
OpenSearch supports multiple backend algorithms (methods) and libraries for implementing these algorithms (engines). It automatically selects the optimal configuration based on the chosen mode and available memory. For more information, see Methods and engines.
- OpenSearch は、複数のバックエンド アルゴリズム (メソッド) と、これらのアルゴリズムを実装するためのライブラリ (エンジン) をサポートしている
- 選択したモードと使用可能なメモリに基づいて、最適な構成が自動的に選択される
Using sparse vectors
Neural sparse search offers an efficient alternative to dense vector search by using sparse embedding models and inverted indexes, providing performance similar to BM25. Unlike dense vector methods that require significant memory and CPU resources, sparse search creates a list of token-weight pairs and stores them in a rank features index. This approach combines the efficiency of traditional search with the semantic understanding of neural networks. OpenSearch supports both automatic embedding generation through ingest pipelines and direct sparse vector ingestion. For more information, see Neural sparse search.
- ニューラル スパース検索は、スパース埋め込みモデルと転置インデックスを使用することで、高密度ベクトル検索の効率的な代替手段を提供し、BM25 と同様のパフォーマンスを実現する
- 大量のメモリと CPU リソースを必要とする密なベクトル方式とは異なり、スパース検索ではトークンと重みのペアのリストを作成し、ランク機能インデックスに保存する
- 従来の検索の効率性とニューラル ネットワークの意味理解を組み合わせたもの
- OpenSearch は、取り込みパイプラインによる自動埋め込み生成と、直接のスパース ベクトル取り込みの両方をサポートしている
Combining multiple search techniques
Hybrid search enhances search relevance by combining multiple search techniques in OpenSearch. It integrates traditional keyword search with vector-based semantic search. Through a configurable search pipeline, hybrid search normalizes and combines scores from different search methods to provide unified, relevant results. This approach is particularly effective for complex queries where both semantic understanding and exact matching are important. The search pipeline can be further customized with post-filtering operations and aggregations to meet specific search requirements. For more information, see Hybrid search.
- ハイブリッド検索は、OpenSearch の複数の検索手法を組み合わせることで検索の関連性を高める
- 従来のキーワード検索とベクトルベースのセマンティック検索を統合
- ハイブリッド検索は、構成可能な検索パイプラインを通じて、さまざまな検索方法からのスコアを正規化および組み合わせて、統一された関連性の高い結果を提供
- 意味の理解と正確な一致の両方が重要な複雑なクエリに特に効果的
- 検索パイプラインは、特定の検索要件を満たすために、フィルタリング後の操作と集計を使用してさらにカスタマイズできる
考察
今回、Vector Searchを整理してみました。
次回以降、実際に試したいと思います。
参考