背景・目的
以前、下記の記事でMLOpsについて整理しました。
今回も似たような内容ですが別のドキュメントを基に、MLOpsの基本原則やプロセス、そして導入による利点について整理します。
まとめ
下記に特徴をまとめます。
| 特徴 | 説明 |
|---|---|
| MLOpsとは | MLアプリケーション開発(Dev)とMLシステムのデプロイ、運用(Ops)を統合するMLカルチャーとプラクティス |
| MLOpsによりできること | 組織は、MLライフサイクル全体のプロセスを自動化・標準化できる |
| MLOpsのプロセス | プロセスには下記が含まれる ・モデル開発 ・テスト ・統合 ・リリース ・インフラ管理 |
| MLOpsの4つの重要な原則 | ・バージョン管理 ・オートメーション ・継続的 X ・モデルガバナンス |
| MLOpsの原則 / バージョン管理 | MLワークフローの再現性はデータ処理からMLモデルのデプロイまで、あらゆるフェーズで重要 |
| 機械学習のアセットの変更を追跡する ・結果の再現、ロールバックが可能になる ・MLトレーニングコード、モデル仕様はすべて、コードレビューフェーズを経る ・MLトレーニングモデルのトレーニングを再現可能、監査かのうにするため、それぞれがバージョン管理されている |
|
| MLOpsの原則 / オートメーション | MLパイプラインの様々なフェーズを自動化する これにより、再現性、一貫性、スケーラビリティを確保する 下記のフェーズが含まれる ・データインジェスト ・前処理 ・モデルトレーニング ・検証からデプロイ |
| 自動モデルトレーニングとデプロイのトリガーとなる要因(起因)は下記の通り。 ・メッセージング ・モニタリングまたはカレンダーイベント ・データ変更 ・モデルトレーニングコードの変更 ・アプリケーションコードの変更 |
|
| MLOpsの原則 / 継続的 X | 自動化により、テストを継続的に実行し、MLパイプライン全体にコードをデプロイできる |
| システム内のどこかで何らかの変更が行われた場合に継続的に発生する以下の 4 つのアクティビティを指す ・継続的インテグレーション ・継続的デリバリー ・継続的トレーニング ・継続的モニタリング |
|
| MLOpsの原則 / モデルガバナンス | ガバナンスには、MLシステムのあらゆる側面を管理して効率化する |
| 以下のようなアクティビティを行う必要がある ・データサイエンティスト、エンジニア、ビジネスステークホルダー間の緊密なコラボレーションを促進する ・明確なドキュメントと効果的なコミュニケーションチャネルを使用して、全員の足並みを揃える ・モデル予測に関するフィードバックを収集し、モデルをさらに再トレーニングするメカニズムを確立する ・機密データが保護され、モデルやインフラストラクチャへのアクセスが安全であること、コンプライアンス要件が満たされていることを確認する ・モデルを本番稼働前にビュー、検証、承認するための構造化されたプロセスを持つことも不可欠(公平性、偏見、倫理的配慮の確認が含まれる) |
|
| MLOps の利点 | ・市場投入までの時間を短縮 ・生産性の向上 ・効率的なモデル展開 |
| MLOps と DevOps の違い | ・MLOps は、機械学習プロジェクト向けに特別に設計されたベスト プラクティスのセット ・データの収集、モデルのトレーニング、検証、導入、継続的な監視と再トレーニングがある点が異なる |
概要
MLOps とは何ですか?
下記の記事を基に整理します。
MLOpsとは
機械学習オペレーション (MLOps) は、機械学習 (ML) のワークフローとデプロイを自動化および簡素化する一連のプラクティスです。機械学習と人工知能 (AI) は、現実世界の複雑な問題を解決し、お客様に価値を提供するために実装できる中核機能です。MLOps は、ML アプリケーション開発 (Dev) と ML システムのデプロイおよび運用 (Ops) を統合する ML カルチャーとプラクティスです。組織は MLOps を使用して ML ライフサイクル全体のプロセスを自動化および標準化できます。これらのプロセスには、モデル開発、テスト、統合、リリース、およびインフラストラクチャ管理が含まれます。
- MLOpsは、MLワークフローとデプロイを自動化・簡素化する一連のプラクティス
- MLアプリケーション開発(Dev)とMLシステムのデプロイ、運用(Ops)を統合するMLカルチャーとプラクティス
- 組織は、MLライフサイクル全体のプロセスを自動化・標準化できる
- プロセスには下記が含まれる
- モデル開発
- テスト
- 統合
- リリース
- インフラ管理
MLOpsが必要な理由
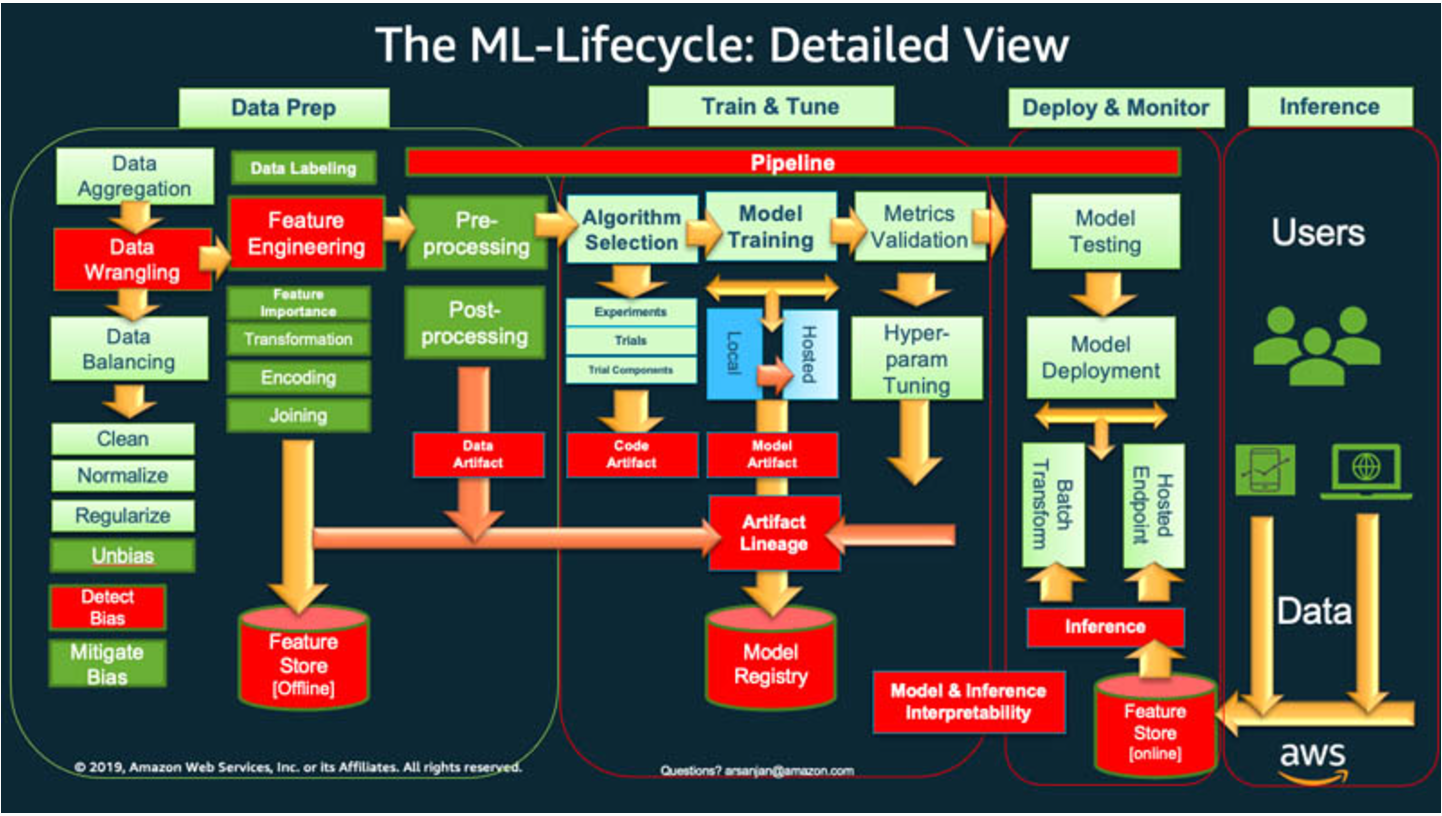
出典:https://aws.amazon.com/jp/what-is/mlops/
大まかに言うと、機械学習のライフサイクルを開始するには、組織は通常、データの準備から始める必要があります。さまざまなソースからさまざまなタイプのデータを取得し、集約、重複クリーニング、特徴量エンジニアリングなどのアクティビティを実行します。
- Data Prep データ準備
- 多様なソースから多様なタイプのデータを取得し、集約・重複クリーニング、特徴量エンジニアリング
その後、データを使用して ML モデルのトレーニングと検証を行います。その後、トレーニングされ検証されたモデルを、他のアプリケーションが API を介してアクセスできる予測サービスとしてデプロイすることができます。
- モデルのトレーニングと検証
- トレーニングされ検証されたモデルを他のアプリケーションがAPIを介して、アクセスできる予測サービスとしてデプロイする
探索的データ分析では、多くの場合、最適なモデルバージョンをデプロイできるようになるまで、さまざまなモデルを試してみる必要があります。そのため、モデルバージョンのデプロイとデータバージョニングが頻繁に行われることになります。アプリケーションがモデルをコードに統合したり使用したりするには、実験の追跡と ML トレーニングパイプラインの管理が不可欠です。
- 探索的データ分析
- 最適なモデルバージョンをデプロイできるようになるまで、様々なモデルを試してみる必要がある
- そのため、モデルバージョンのデプロイとデータバージョニングが頻繁に行われる
- 実験の追跡とMLトレーニングパイプラインの管理が必要
- 最適なモデルバージョンをデプロイできるようになるまで、様々なモデルを試してみる必要がある
MLOps は、アプリケーションコードやデータの変更を伴う新しい ML モデルのリリースを体系的かつ同時に管理するために不可欠です。MLOps の最適な実装では、ML アセットを他の継続的インテグレーションおよびデリバリー (CI/CD) 環境のソフトウェアアセットと同様に扱います。統合リリースプロセスの一環として、ML モデルをアプリケーションやサービス、およびそれらを使用するアプリケーションやサービスとともに、デプロイします。
- MLOpsの最適な実装では、MLアセットを他のCI/CDのソフトウェアと同様に扱う
- 統合リリースプロセスの一環として、MLモデルをアプリケーション、サービうs、それらを使用するアプリケーションやサービスとともにデプロイする
MLOps の原則とは何ですか?
次に、MLOps の 4 つの重要な原則について説明します。
MLOpsの4つの重要な原則
バージョン管理
このプロセスでは、機械学習アセットの変更を追跡します。これにより、結果を再現したり、必要に応じて以前のバージョンにロールバックしたりできます。ML トレーニングコードまたはモデル仕様はすべて、コードレビューフェーズを経ます。ML モデルのトレーニングを再現可能かつ監査可能にするため、それぞれがバージョン管理されています。
- 機械学習のアセットの変更を追跡する
- 結果の再現、ロールバックが可能になる
- MLトレーニングコード、モデル仕様はすべて、コードレビューフェーズを経る
- MLトレーニングモデルのトレーニングを再現可能、監査かのうにするため、それぞれがバージョン管理されている
ML ワークフローの再現性は、データ処理から ML モデルのデプロイまで、あらゆるフェーズで重要です。つまり、同じ入力が与えられた場合、各フェーズで同じ結果を得られるはずです。
- MLワークフローの再現性はデータ処理からMLモデルのデプロイまで、あらゆるフェーズで重要
オートメーション
機械学習パイプラインのさまざまなフェーズを自動化して、再現性、一貫性、スケーラビリティを確保します。これには、データインジェスト、前処理、モデルトレーニング、検証からデプロイまでのフェーズが含まれます。
- MLパイプラインの様々なフェーズを自動化する
- 再現性、一貫性、スケーラビリティを確保する
- 下記のフェーズが含まれる
- データインジェスト
- 前処理
- モデルトレーニング
- 検証からデプロイ
自動モデルトレーニングとデプロイのトリガーとなる要因には、次のようなものがあります。
- メッセージング
- モニタリングまたはカレンダーイベント
- データ変更
- モデルトレーニングコードの変更
- アプリケーションコードの変更
- 自動モデルトレーニングとデプロイのトリガーとなる要因(起因)
- メッセージング
- モニタリングまたはカレンダーイベント
- データ変更
- モデルトレーニングコードの変更
- アプリケーションコードの変更
自動テストにより、問題を早期に発見し、エラーの修正と学習を迅速に行うことができます。Infrastructure as Code (IaC) により、自動化がより効率的になります。ツールを使用して、インフラストラクチャを定義および管理できます。これにより、再現性が確保され、さまざまな環境に一貫してデプロイできます。
- 自動テストにより、問題を早期に発見し、エラーの修正と学習を迅速に行える
- IaCにより、自動化がより効率的になる
- ツールを使用してインフラを定義、管理できる
- これにより再現性が確保され、様々な環境に一貫してデプロイ可能
継続的 X
自動化により、テストを継続的に実行し、ML パイプライン全体にコードをデプロイできます。
- 自動化により、テストを継続的に実行し、MLパイプライン全体にコードをデプロイできる
MLOps では、継続的とは、システム内のどこかで何らかの変更が行われた場合に継続的に発生する以下の 4 つのアクティビティを指します。
- 継続的インテグレーションにより、コードの検証とテストをパイプライン内のデータやモデルにまで広げる
- 継続的デリバリーにより、新しくトレーニングされたモデルまたはモデル予測サービスを自動的にデプロイする
- 継続的トレーニングにより、ML モデルを自動的に再トレーニングし、再デプロイできるようにする
- 継続的モニタリングにより、ビジネスに関連するメトリクスを使用したデータモニタリングとモデルモニタリングを行う
- システム内のどこかで何らかの変更が行われた場合に継続的に発生する以下の 4 つのアクティビティを指す
- CIにより、コードの検証とテストをパイプライン内のデータやモデルにまで広げる
- CDにより、新しくトレーニングされたモデルまたはモデル予測サービスを自動的にデプロイする
- 継続的トレーニングにより、ML モデルを自動的に再トレーニングし、再デプロイできる
- 継続的モニタリングにより、ビジネスに関連するメトリクスを使用したデータモニタリングとモデルモニタリングを行う
モデルガバナンス
ガバナンスには、ML システムのあらゆる側面を管理して効率化することが含まれます。ガバナンスのためには以下のような多くのアクティビティを行う必要があります。
- ガバナンスには、MLシステムのあらゆる側面を管理して効率化する
- データサイエンティスト、エンジニア、ビジネスステークホルダー間の緊密なコラボレーションを促進する
- 明確なドキュメントと効果的なコミュニケーションチャネルを使用して、全員の足並みを揃える
- モデル予測に関するフィードバックを収集し、モデルをさらに再トレーニングするメカニズムを確立する
- 機密データが保護され、モデルやインフラストラクチャへのアクセスが安全であること、コンプライアンス要件が満たされていることを確認する
- 以下のようなアクティビティを行う必要がある
- データサイエンティスト、エンジニア、ビジネスステークホルダー間の緊密なコラボレーションを促進する
- 明確なドキュメントと効果的なコミュニケーションチャネルを使用して、全員の足並みを揃える
- モデル予測に関するフィードバックを収集し、モデルをさらに再トレーニングするメカニズムを確立する
- 機密データが保護され、モデルやインフラストラクチャへのアクセスが安全であること、コンプライアンス要件が満たされていることを確認する
また、モデルを本番稼働前にレビュー、検証、承認するための構造化されたプロセスを持つことも不可欠です。これには、公平性、偏見、倫理的配慮の確認が含まれる場合があります。
- モデルを本番稼働前にビュー、検証、承認するための構造化されたプロセスを持つことも不可欠
- 公平性、偏見、倫理的配慮の確認が含まれる
MLOps の利点は何ですか?
機械学習は、組織がデータを分析し、意思決定のための洞察を引き出すのに役立ちます。ただし、これは革新的で実験的な分野であり、独自の課題が伴います。機密データの保護、予算の少なさ、スキル不足、そして絶えず進化するテクノロジーがプロジェクトの成功を制限します。制御とガイダンスがなければ、コストが急増し、データ サイエンス チームが望ましい結果を達成できない可能性があります。
MLOps は、制約に関係なく ML プロジェクトを成功に導くためのマップを提供します。ここでは、MLOps の主な利点をいくつか紹介します。
市場投入までの時間を短縮
MLOps は、データ サイエンスの目標をより迅速かつ効率的に達成するためのフレームワークを組織に提供します。開発者とマネージャーは、モデル管理においてより戦略的かつ機敏に行動できるようになります。ML エンジニアは、宣言型の構成ファイルを通じてインフラストラクチャをプロビジョニングし、プロジェクトをよりスムーズに開始できます。
モデルの作成と展開を自動化することで、運用コストを抑えながら市場投入までの時間を短縮できます。データ サイエンティストは組織のデータを迅速に調査し、すべてのユーザーにより多くのビジネス価値を提供できます。
生産性の向上
MLOps の実践により、生産性が向上し、ML モデルの開発が加速します。たとえば、開発環境や実験環境を標準化できます。その後、ML エンジニアは新しいプロジェクトを立ち上げ、プロジェクト間でローテーションし、アプリケーション間で ML モデルを再利用することができます。また、迅速な実験とモデル トレーニングのための繰り返し可能なプロセスを作成できます。ソフトウェア エンジニアリング チームは、ML ソフトウェア開発ライフサイクルを通じて連携して調整し、効率を高めることができます。
効率的なモデル展開
MLOps は、運用環境でのトラブルシューティングとモデル管理を改善します。たとえば、ソフトウェア エンジニアはモデルのパフォーマンスを監視し、トラブルシューティングのために動作を再現できます。モデルのバージョンを追跡して一元管理し、さまざまなビジネス ユース ケースに適したものを選択できます。
モデル ワークフローを継続的インテグレーションおよび継続的デリバリー (CI/CD) パイプラインと統合すると、パフォーマンスの低下を抑え、モデルの品質を維持できます。これは、アップグレードやモデル調整後も変わりません。
組織内でMLOpsを実装する方法
3つのレベルがある
| レベル | 概要 | 説明 |
|---|---|---|
| MLOpsレベル0 | 手動の ML ワークフローとデータ サイエンティスト主導のプロセスが特徴 | データの準備、ML トレーニング、モデルのパフォーマンスと検証など、すべてのステップは手動で行われる。 ステップ間の移行は手動で行う必要があり、各ステップはインタラクティブに実行および管理される モデルを作成するデータ サイエンティストと、それをデプロイするエンジニアが分離される ML モデルとその他のアプリケーション コードには、CI/CD の考慮事項はない。 同様に、アクティブなパフォーマンス監視も存在しない |
| MLOpsレベル1 | ML パイプラインを自動化することでモデルを継続的にトレーニングすることを目的としている | トレーニング済みのモデルを他のアプリに提供するために定期的に実行されるトレーニング パイプラインをデプロイする 下記の特徴がある ・大幅な自動化を伴う迅速なML実験ステップ ・ライブパイプライントリガーとして最新のデータを使用して本番環境でモデルを継続的にトレーニングする ・開発、試作、本番環境で同じパイプラインを実装 |
| MLOps レベル 2 | より多くの実験を行い、継続的なトレーニングを必要とする新しいモデルを頻繁に作成したい組織向け | モデルを数分で更新し、毎時間または毎日再トレーニングし、同時に数千台のサーバーに再デプロイする技術主導の企業に適している MLOpsレベル1に加えて、下記が必要 ・MLパイプラインオーケストレーター ・複数のモデルを追跡するためのモデルレジストリ |
MLOps と DevOps の違いは何ですか?
MLOps と DevOps はどちらも、ソフトウェア アプリケーションを開発、展開、監視するプロセスを改善することを目的としたプラクティスです。
DevOps は、開発チームと運用チームの間のギャップを埋めることを目的としています。DevOps は、コードの変更が自動的にテストされ、統合され、効率的かつ確実に本番環境に展開されるようにするのに役立ちます。DevOps はコラボレーションの文化を促進し、リリース サイクルの高速化、アプリケーションの品質の向上、リソースのより効率的な使用を実現します。
一方、MLOps は、機械学習プロジェクト向けに特別に設計されたベスト プラクティスのセットです。従来のソフトウェアの導入と統合は比較的簡単ですが、ML モデルには独自の課題があります。これには、データの収集、モデルのトレーニング、検証、導入、継続的な監視と再トレーニングが含まれます。
MLOps は、ML ライフサイクルの自動化に重点を置いています。モデルが開発されるだけでなく、体系的かつ繰り返し展開、監視、再トレーニングされることを保証します。DevOps の原則を ML に取り入れます。MLOps により、ML モデルの展開が高速化され、時間の経過とともに精度が向上し、実際のビジネス価値が提供されるという保証が強化されます。
- MLOps は、機械学習プロジェクト向けに特別に設計されたベスト プラクティスのセット
- データの収集、モデルのトレーニング、検証、導入、継続的な監視と再トレーニングがある点が異なる
考察
MLOpsの導入は、機械学習プロジェクトにおいて、下記の4つの原則があることを学びました。今後も継続して深堀りしていきたいと思います。
- バージョン管理
- データ処理からモデルデプロイまでの全フェーズでの再現性を確保し、変更履歴を追跡することで、結果の再現やロールバックが可能
- オートメーション
- データインジェスト、前処理、モデルのトレーニング、検証、デプロイといった各フェーズを自動化することで、再現性、一貫性、スケーラビリティを向上させる
- 継続的インテグレーションとデリバリー(CI/CD)
- システム内の変更に対して継続的にテストとデプロイを行うことで、迅速なモデル更新と品質保証を実現する
- モデルガバナンス
- データサイエンティスト、エンジニア、ビジネスステークホルダー間のコラボレーションを促進し、モデルの公平性、倫理的配慮、セキュリティ、コンプライアンスを確保する
参考