背景・目的
昨年12月に、オライリーより「大規模データ管理」(日本語)が出版されたので読んでみました。
本ページでは第5章の整理を行います。
まとめ
用語の整理
本ページでは下記の用語を使用しています。
| 用語 | 解説 |
|---|---|
| EDA(event-driven architecture) | イベント駆動アーキテクチャ サービス駆動ではなくイベント駆動を中心に考えたアーキテクチャ |
| イベント | 状態の変化、何かが注文したなど |
| ストリーミングアーキテクチャ | 様々なソースから生成されたデータを連続的にリアルタイムで処理、分析するもの 下記から構成されている。 ・イベントプロデューサー ・イベントコンシューマー ・イベントプラットフォーム |
| パブリックストリームとプライベートストリーム | 同一ドメイン内に閉じるか否か、技術データからビジネスデータかの違いがある。 |
第5章 イベントとレスポンスの管理:ストリーミングアーキテクチャ
本章では、ストリーミングアーキテクチャを解説する。
ストリーミングアーキテクチャ
ストリーミングアーキテクチャとは、様々なソースから生成されたデータを連続的にリアルタイムで処理、分析するものを指している。
(ストリーミングアーキテクチャというという名称は、ストリーミングデータとイベントストリーム処理が由来である。)
イベントとの相互作用、イベントへの反応に重点を置いており、アプリケーションとシステムを非同期で接続します。
リアルタイムストリーミングデータは、下記のようなビジネス上競争優位性をもたらします。
- より素早い対応により顧客満足度を高める。
- 不正行為判定
- Webのカスタマーエクスペリエンス改善
非同期イベントモデルがもたらすもの
アプリや統合プラットフォームでは、イベントやメッセージをキューに送り、他のシステムがそれを取得するのを待つ。
疎結合により依存関係がなくなります。このような非同期通信により、Scaled Architectureをレジリエンスがある状態になる。
イベント駆動形アーキテクチャ(event-driven architecture)とは
サービス駆動ではなくイベント駆動を中心に考えたアーキテクチャを指している。
イベントとは「状態の変化」を指しており、例えば、下記のようなものがあります。
- 新規顧客の登録・注文
- 飛行機の着陸
イベントが発生するたびにメッセージが生成され、メッセージングプラットフォームに配信されます。各メッセージはイベントに関するデータを保持しています。
設計思想の異なる「メディエータートポロジー」と「ブローカトポロジー」のリファレンスモデルがあります。
メディエータートポロジー
イベント処理を管理するために、ある程度の中央コントロールや調整が必要な場合に、アーキテクチャ設計で使われます。
- 一般的には、メディエーターとメッセージキューで構成されます。
- 受信したトピックやチャネルごとにイベントコンシューマに一度だけ配信され処理されます。
- 一度だけ処理されることを保証するため、コンシューマーで受信したあとにメッセージは削除orフラグが立てられます。
- ソフトウェアアーキテクチャ実装には、下記が利用できます。
- ESB(Enterprise Service Bus)
- Apache Camel
- Spring Integration

ブローカートポロジー
中央のメディエーターが存在しない点がメディエータートポロジーと異なる。
- イベントは軽量なメッセージブローカーにブロードキャストされる。
- イベントの流れが比較的単純&中央でのオーケストレーションが不要な場合にこのモデルが使用できる。
- 不正検知のように、複数のシステムに一度に通知する場合、同じメッセージを複数のイベントコンシューマーに配信するときに便利とのこと。
- イベント処理は比較的単純&中央でのイベントオーケストレーションや調整が必要ないのでスケーラブル。
- ソフトウェアアーキテクチャ実装には、下記が利用できます。
- Apache Kafka
- RabbitMQ
- ActiveMQ
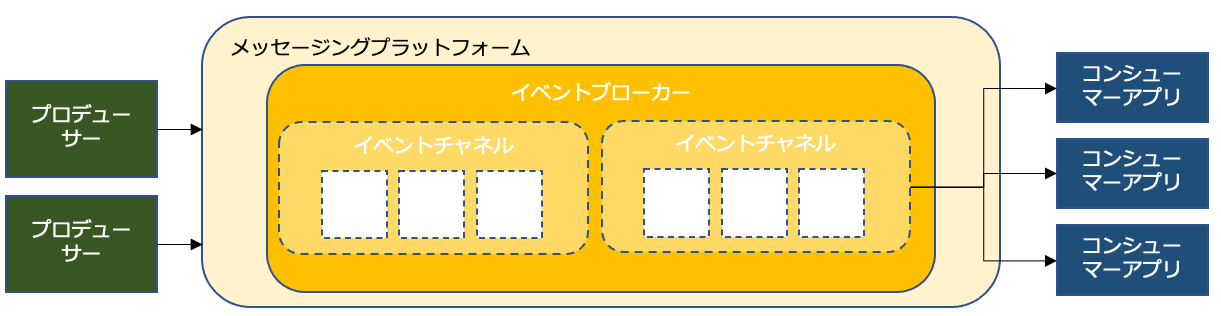
イベント処理スタイル
EDA(event-driven architecture)トポロジーモデルには、イベント処理するためのスタイルがある。
イベントの複雑さと実装されたユースケースにより決定され、多くの場合は、様々なスタイルが組合わされる。
| シンプルイベント処理 (SEP:Simple event processing) |
イベントストリーム処理 (ESP:Event stream processing) |
複合イベント処理 (CEP:Complex event processing) |
|
|---|---|---|---|
| 複雑さ | 最もシンプル | 中間 | 最も複雑 |
| 説明 | 特定の測定可能な状態の変化に対して、直接関連するイベントを処理し複雑なワークフローは発生しない。 | ストリームと複数イベントに対して、集約、フィルタリング、結合など複雑な処理を同時に適用するもの。 既存のストリームから新しいストリームを生成するだけであれば、ステートレスにできます。 他のモデル(Pub-Sub)と組み合わせる事が多い。Pub-Subモデルの拡張 |
分析を行い、より複雑な事象が発生したかどうかを判断するためにパターンを見つける場合に使用されます。 分析対象となるイベントは、長期間に渡り評価される場合があり、同時に複数のソースから発生する場合もある。 一般的に必ずイベントストリームと組み合わせされます。 |
ストリーミングアーキテクチャ
イベントストリーミングは、リアルタイムアプリケーションの構築や、流通するデータのリアルタイム変換、他のアプリケーションやシステムへのデータ提供を可能にする。
イベントの反応性、分散機能、アプリケーションデータベースの転送機能は、ストリーミングアーキテクチャに不可欠な要素であり下記から構成される。
- イベントプロデューサー
- イベントコンシューマー
- イベントプラットフォーム
イベントプロデューサー
イベントプロバイダーとも呼ばれ、データソースからデータを収集、メッセージの形式変換、フィルタリング・集約、プロトコル変換を行うためにはコンポーネントを追加する必要がある。
下記のような方法と選択肢がある。
- フロントエンドとユーザインターフェイスイベント。Webページの閲覧、商品をカートに入れるなど
- アプリケーションイベント。JavaなどのCRMアプリケーションなどでKafkaにデータをプッシュする
- アプリケーションデータベースの読み出し。ストレージ層を読み出すことでDBに加えられrた変更をキャプチャしてイベントを発生させる。CDCなど
イベントコンシューマー
イベントコンシューマーではユースケースの要件とどのテクノロジーを選択するかによってバリエーションが決まる。
最もシンプルなユースケースは、メッセージブローカーを使用することでイベントプロバイダーとイベントコンシューマを分離する。
イベントプラットフォーム
イベントプロバイダーとイベントコンシューマ間の相互作業を管理する。基本的な動作はメッセージを受信し、複数のコンシューマに送信する。
EDAのコア機能を設計する方法には様々な方法がある。
- データの保存
- RESTインターフェイスを持つような最新のデータベース
- データ統合、分析
- マイクロサービス
- Apache Flink
- Apache NiFi
- Apache Spark
- Active MQ
- ZeroMQ
- RabbitMQ
- Apache Kafka
パブリッククラウドでは下記のようなものが使用できる。
- AWS
- DynamoDB
- SQS
- Kinesis
- Azure
- Event Grid
- Event Hubs
- Service Bus
- CosmosDB
- Queue Storage
- Google
- Dataflow
- Apache Beam
上記のようなプラットフォームやツールをEDAのバックボーンとして利用することで、下記のことが可能になる。
- イベントの流通・保存
- アプリケーションとの履歴を保持
これにより、いくつかの高度なパターンが実装できる
- イベント駆動型サービスコレオグラフィ
- プロセスの更新、コマンドを非同期で流通させて複数のアプリケーションが対応できるようにするもの
- 保持期間を高めに設定することで、イベントソーシングとコマンドソーシングという2つのパターンが使える。
イベントソーシングとコマンドソーシング
イベントソーシングとは
アプリケーションの状態やDBの変更が全ての一連のイベントとしてImmutableのログや追記型データストアに保存される。メリットとしては下記のようなものがある。
- 変更しないので、監査証跡が残る。
- 全てのイベントを時系列で詳しく確認できる
- 過去の任意の時点の状態に復旧可能
- イベントの巻き戻し、再生、操作が可能
- イベントを集約し、具体化できる
- CQRSを実現する際に、イベントソースのマテリアライズドビューを構築するときにも利用できる
- 複数の分散読み出し専用データストアを構築できる。
- 他のドメインとの調整を気にしない、イベントをSubscribeするアプリから分離される。

コマンドソーシングとは
コマンドをインターセプトすることで、イベントソーシングとは逆の方向に機能する。
コマンドを発行するシステムのAPIに届く前に、まずキューやトピックにプッシュされる。ここからソーシングされ最終的にターゲットシステムに配信される。
すべてのコマンドを永続化することで、問題が発生した場合は対応できる。
ガバナンスモデル
トピックやキューなどのストリーミングチャネルはイベントプロバイダーが所有する。
他のドメインのコンシューマーが他のドメインのプライベート通信チャネルを拾ってしまわないように、一つのクラスタでプライベートとパブリック通信を分離することが推奨される。
| プライベートストリーム | パブリックストリーム (ビジネスストリームとも呼ばれる) |
|
|---|---|---|
| メッセージの特性 | 技術的なものも許される | ビジネス上のものに限定 |
| スコープ | ドメイン内に限る | 他のドメインでコンシュームされる |
| 概要 | アプリケーション内部ロジックの一部とみなされる。 イベントを生成したドメインだけが、このイベントをコンシュームできる。 他のドメインが直接コンシュームすることはない。 |
ビジネスでコンシュームされるので読み出しに最適化されている。 |
ビジネスストリーム
ドメインが他のドメインとデータを交換したりイベントを配信する場合、RDSやAPIアーキと同じポリシーに従う必要がある。
有効なビジネスストリームを作成するという目標を達成するために、イベントプロバイダーにイベントの書き換えを強いる可能性がある。
方法としていくつかの選択肢がある。
アプリケーション境界内
複雑な内部データ構造を、よりビジネス的な意味を保つ構造に変換する。
最終的には変換結果である非正規化テーブルがアプリケーションデータベースに格納され、このテーブルがストリームの入力となる。
これによりコンシューマが複雑なロジックに悩まされずに済む。(隠蔽化される)
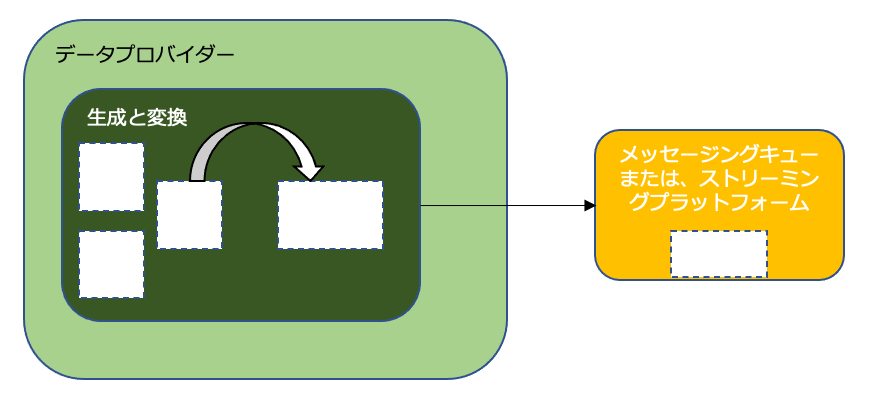
サードパーティー製ツールの使用
複雑なデータ構造で、調整やアクセスが困難なアプリは、ビジネスイベントを生成する前にサードパーティ製のツールを使うと良い。
Rawの技術データからパブリックストリーム用のイベント変換では、アプリケーションの外側で行われるが、ドメイン境界内で実行される。
(Apache NiFi、Apache Flumeなどはアプリケーションとストリーミングプラットフォームの間に配置可能。)
これにより、イベントのリッチ化が可能。
リッチ化後はデータを中央のストリーミングプラットフォームにプッシュし他のドメインでコンシュームできるようにする。
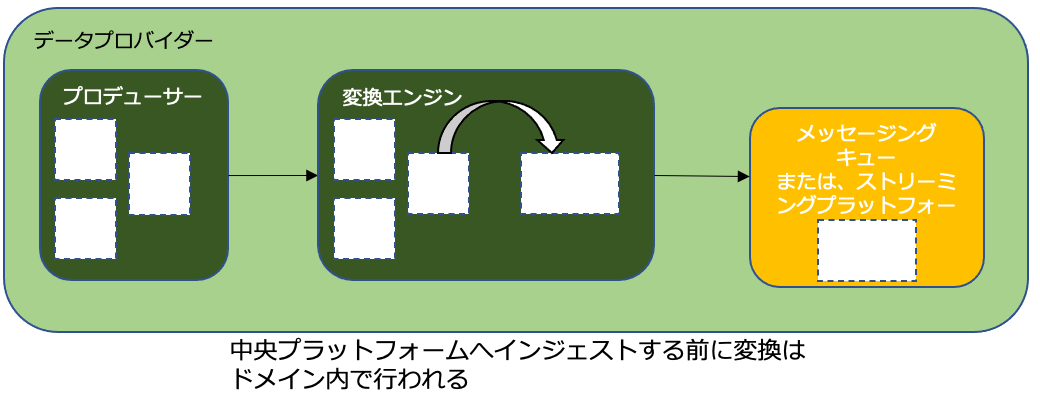
インジェストの後処理
中央プラットフォームにインジェストした後、データを変換する方法もある。プラットフォーム内で、データをある構造から別の構造にリアルタイム変換できる。
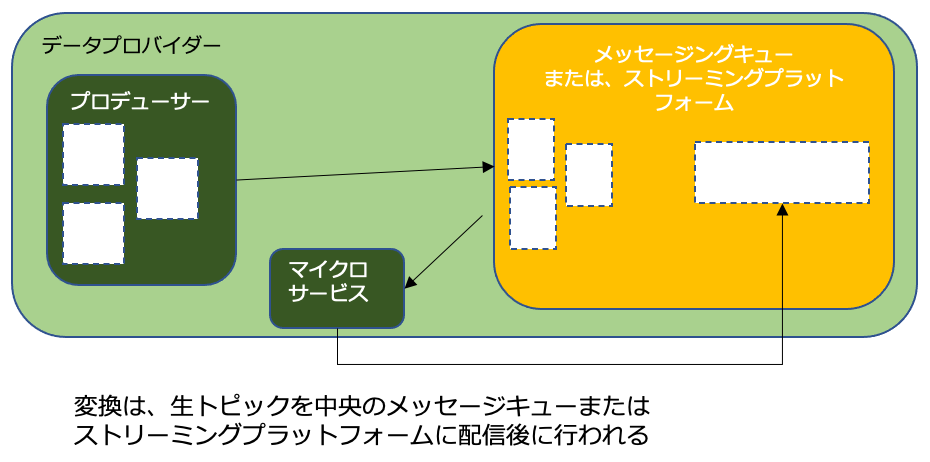
ストリーミングの消費パターン
ニーズがより多様でユースケースに依存するので、複雑さが増す。イベントコンシューマがストリームデータを処理する方法についていくつかのバリエーションがある。
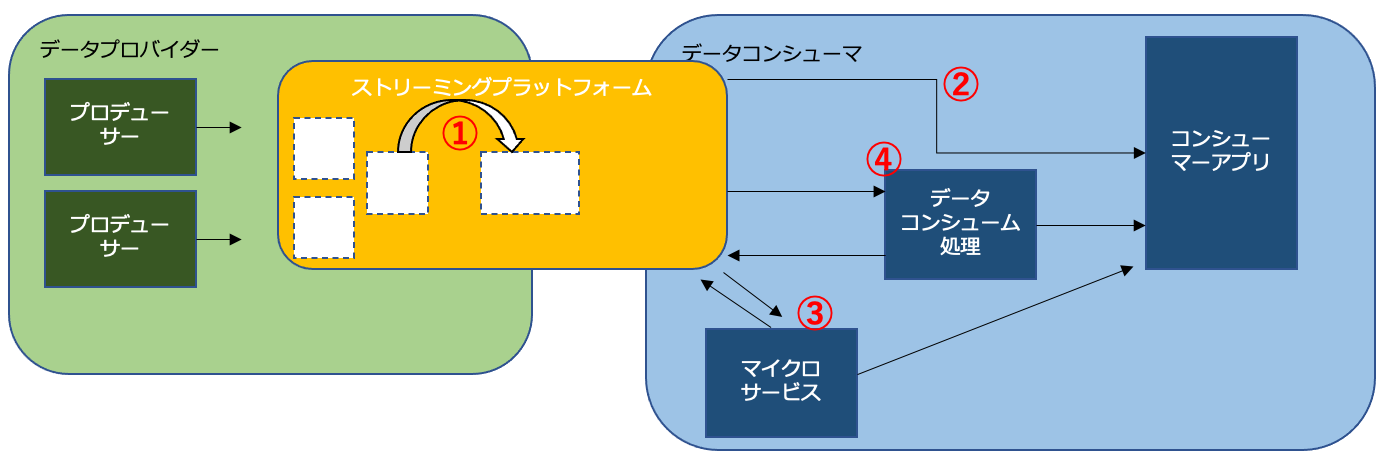
- ①②プラットフォームの機能の利用
- 中央プラットフォームを直接使用する。
- 変換されてプラットフォームから持ち出されて、コンシューマーアプリに所望の形式でルーティングされるようにもできる
- ③マイクロサービスとイベントフレームワーク
- イベントコンシューマのユースケースに合わせてイベントを変換し、リッチ化する
- Kafka Streams、Spring Cloud Stream、Akka、Axonなど使用できる
- 変換されたデータを中央プラットフォームにインジェストし直すか、コンシュマーアプリに直接インジェストするか選択できる。中央にインジェストすると他のドメインでも利用可能。
- ④ストリーミング分析サービス
- 分析的なユースケースをサポートする
- ストリーミングコンポーネントを追加dケイル
- Apache Samza、Spark Streaming、Beam、StormなどのOSSフレームワークを利用できる
イベントによる状態転送
プライベートストリームを使ってドメイン内のアプリケーションの状態を転送するパターンもある。
(例えば、運用システムにおいて、クラウドプロバイダーが提供する分析機能を活用したい場合など。)
RDSの役割を実現
データ長期保存の場合、ストリーミングプラットフォームをDBとして使用し、読み取り専用データストアの役割を担わせる。
ストリーミングを使用したRDSの構築
読み取り専用データストアは、ストリームから構築することも可能。
データはまずインジェストされ、変換された後、ストリーミングプラットフォームから新たに作成されたDBに転送されます。
ドメインを統括するコントロールとポリシー
非同期、永続化されない、アプリケーションとエンタープライズデータ流通の目的が密結合になり混同してしまうため、中央ストリーミングプラットフォームを、アプリケーションのバックエンドとして使用することは推奨していない。
保証と一貫性
ストリーミングはバッチ処理よりも複雑で、障害や不整合への対処は複雑になる。下記に注意点を記載する。
一貫性(整合性)レベル
Eventual ConsistencyとStrong Consistencyの2種類がある。
- 結果整合性(Eventual Consistency)
- イベントは受信者がいるかにかかわらずプラットフォームに送信される
- 重要ではないデータに対しては有効
- 強一貫性(Strong Consistency)
- イベントが失われないことを保証するために、イベントによっては何度も配信されるものもある
at least once、exactly once、once at most
上記のEventual ConsistencyとStrong Consistencyには、様々な処理モデルがある。
- at least once
- 少なくとも一回
- メッセージが失われないことを保証
- 一意性や一度だけ配信されることを保証されるわけではない
- once、exactly
- 正確に一回
- 各イベントが正確に一度だけ配信
- メッセージは失われず、重複もない
- once at most
- 多くても一回
- 失われても良い可能性あり
メッセージ順序
全てのメッセージを生成順に処理しなければならない場合などは、Kafkaなど使えば一つのパーティションを使えば可能。
複数のパーティションが必要な場合は、メッセージ内のプロパティを使う。
デッドレターキュー
正常に配信されなかったメッセージのためのキューを追加されているものが、ストリーミングプラットフォームにはある。
例えば、下記のようなものあり、メッセージはシステムから削除されない。これを調査などに使用される。
- サイズ超過
- 不正な形式のメッセージ
- 存在しないトピックに送信されたメッセージ
- メッセージが取り出されなかったためにしきい値に到達したメッセージ
ストリーミングの相互運用性
Pub/Sub間のインターフェイスで、複数のプログラミング言語間で透過的な相互運用を可能にするプラットフォームもある。
インターフェイス記述言語を使用して、メッセージをエンコードするようなプロトコルを使うのが一般的で、データシリアライゼーションをサポートするフレームワークを使用も検討すべきとのこと。
データシリアライゼーションフレームワークの役割と特徴は下記のとおりである。これにより多くのシステムやプログラミング言語、他のフレームワークからデータを使用できるようになり、データ処理を向上させる。
| 役割 | 機能 |
|---|---|
| データ移動の際の互換性 バージョン管理 ポータビリティ |
データを標準形式へと一貫性のある変換 圧縮 暗号化 |
シリアライゼーションフレームワークとプロトコルなどは下記のようなものがある。
- Apache Avro
- Protocol Buffers
- Apache Thrift
- MQTT
- AMQP
ガバナンスとセルフサービスモデルのためのメタデータ
ストリーミングアーキにはメタデータ機能、メタデータ要件が付加されています。重要なものにはトピックレジストリがあり、次のようなものが含まれる。
- メッセージキューとトピックの所有権登録
- スキーマドキュメント管理
- メッセージキュートとプックレジストリは、メッセージのスキーマレイアウトをドキュメント化する必要がある
- XML、JSONなどは、XMLスキーマ、JSONスキーマを使用する
- AvroやProtobufなどはIDLを使用する
- メッセージキュートとプックレジストリは、メッセージのスキーマレイアウトをドキュメント化する必要がある
- バージョン管理
- リネージ
参考