背景・目的
Redshiftのデータ共有を使う機会があったので、このタイミングで知識と手順を簡単に整理します。
まとめ
- データ共有は、データは共有しコンピュートは分割する。
- ワークロードの分離や、組織間のコラボレーションに効果的
概要
データ共有とは?
使用すると、読み込み目的でRedshiftのクラスタ間でライブデータを安全、かつ簡単に共有できるとのことです。
ユースケース
以下のユースケースがあります。
- 様々な種類のビジネスクリティカルなワークロードのサポート
- 複数のBIクラスタや分析クラスタとデータを共有する一元的なETLクラスタを使用する。
- 個々のワークロードに対して読み込みワークロードの分離とチャージバックを提供する。
- 料金とパフォーマンスのワークロード固有の要件に応じて、個々でコンピューティングサイズとスケーリングを行える。
- (ETL専用クラスタと、アドホッククエリ用のクラスタなど)
- クロスグループコラボレーションの有効化
- チームやビジネスグループ間でシームレスなコラボ
- (営業と、マーケなど複数組織で利用など)
- チームやビジネスグループ間でシームレスなコラボ
- サービスとしてのデータ提供
- 組織全体でデータをサービスとして共有できる。
- 環境間でのデータ共有
- 開発、テスト、本番環境間でデータを共有する。
- (本番と同じデータを使用することで、生産性や品質が向上する。)と思われる。
- 開発、テスト、本番環境間でデータを共有する。
- Redshift内のデータにアクセするライセンスを共有する
- AWS Data Exchange カタログに Amazon Redshift データセットを出品できる。
データ共有の概念
データ共有には、以下の概念があります。
| 概念 | 説明 |
|---|---|
| データプロデューサー | データを共有するクラスタ オブジェクト(テーブルやビュー、UDFなど)を追加するとコンシューマクラスター(後述)が読み取り目的で参照できるようになる。 |
| データコンシューマー | プロデューサークラスタからデータを共有されるクラスタ。 ・同一アカウントまたは別アカウントでも可能。組織間や他のチームとの共同性用可能になる。 |
特徴
- データの整合性
- プロデューサクラスターおよびコンシューマークラスタートランザクションの一貫性を提供し、データの最新で一貫性のあるビューをすべてのコンシューマーと共有する。
- 様々なレベルでのデータ共有
- データベース、スキーマ、テーブル、ビュー (通常ビュー、遅延バインディングビュー、マテリアライズドビューを含む)、および SQL ユーザー定義関数 (UDF) など異なるレベルでデータ共有が可能。
- アクセス方法
- SQLインタフェイス、JDBC/ODBCドライバ、APIを使用してアクセスできる。
- クエリ実行では、以下の書式でアクセスします。
{コンシューマクラスタのDB名}.{スキーマ名}.{テーブル名}
- クロスアカウントおよびクロスリージョンでのデータ共有が可能。(もちろん同一アカウント、同一リージョンも可能。)
考慮事項
- 以下のインスタンスタイプのみサポート(2022/5現在)
- ra3.16xlarge
- ra3.4xlarge
- ra3.xlplus
- 暗号化
- クロスアカウントおよびクロスリージョンでのデータ共有の場合、プロデューサークラスターとコンシューマークラスターの両方を暗号化する必要がある。
- データ共有の単位
- 1 つのデータ共有を単一の Amazon Redshift データベースに関連付ける。そのデータベースから関連するデータ共有にのみオブジェクトを追加できる。
- 同じ Amazon Redshift データベースで複数のデータベース共有を作成できる。Amazon Redshift クラスター内で作成されたデータ共有には一意の名前を使用する。
- コンシューマークラスター内のデータ共有から作成されたデータベースを指す複数のスキーマを作成できる。
- 課金
- プロデューサークラスタ
- 共有データに対して課金が行われる。
- コンシューマークラスター
- 共有データへのアクセスに使用するコンピューティングに対して課金が行われる。
- プロデューサークラスタ
- AWS Data Exchange データ共有
- コンシューマークラスターは、提供されている AWS Data Exchange 製品と同じ AWS リージョン内にある必要がある。
- 共有データに対するクエリのパフォーマンスは、コンシューマークラスターの計算能力によって異なる。
実践
同一アカウント、同一リージョン内に2つのクラスタを用意してデータ共有を試します。
事前準備
最初に2つのRedshiftを用意します。分かりづらいですが、cluster-2をプロデューサー、cluster-3をコンシューマとします。
| クラスタ | |
|---|---|
| プロデューサー | cluster-2 |
| コンシューマー | cluster-3 |

プロデューサー側でオブジェクトを用意する。
スキーマ
producerスキーマを用意します。
- 作成
create schema producer;
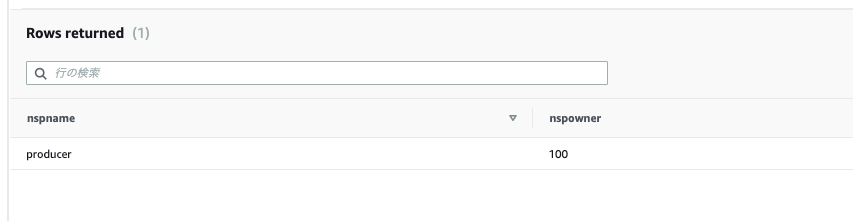
- 確認
select * from pg_namespace where nspname='producer'
テーブルとデータの準備
testテーブルの作成と、データをINSERTします。
- 作成
create table producer.test(
id numeric(10),
name CHARACTER VARYING(128) ENCODE ZSTD collate case_insensitive
)
insert into producer.test(id,name) values('1','AAAAAAAA');
insert into producer.test(id,name) values('2','BBBBBBBB');
- 確認
select * from producer.test

データが登録されました。これで、確認の準備が整いました。
データ共有の設定
コンシューマーの事前確認
- データベースとスキーマを確認し、データ共有前の状態でプロデューサーのオブジェクトが参照されていないことを確認します。
プロデューサーの設定
1.マネコンでデータ共有タブをクリックします。

2.名前空間で作成されたデータ共有で、「Create datashare」をクリックします。

3.データ共有画面で以下の設定を行います。
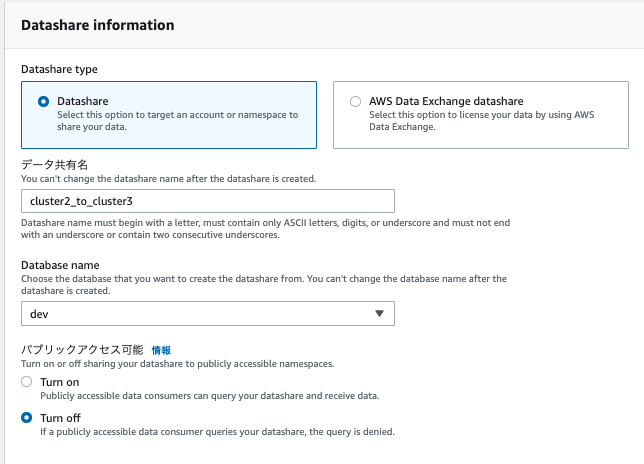
- Datashare typeを「Datashare」
- データ共有名を任意(ここでは「cluster2_to_cluster3」としています。)
- Database nameを対象のデータベース名「dev」
- パブリックアクセス可能は、「Turn off」
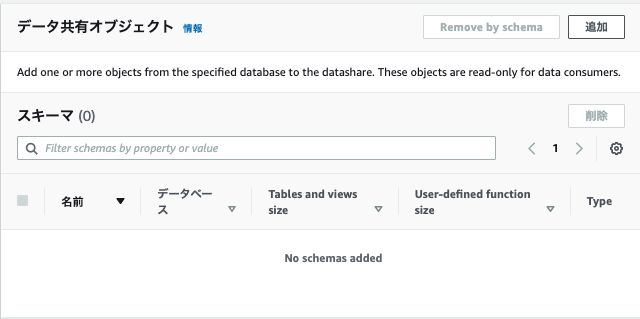
- データ共有オブジェクトで追加をクリックします。
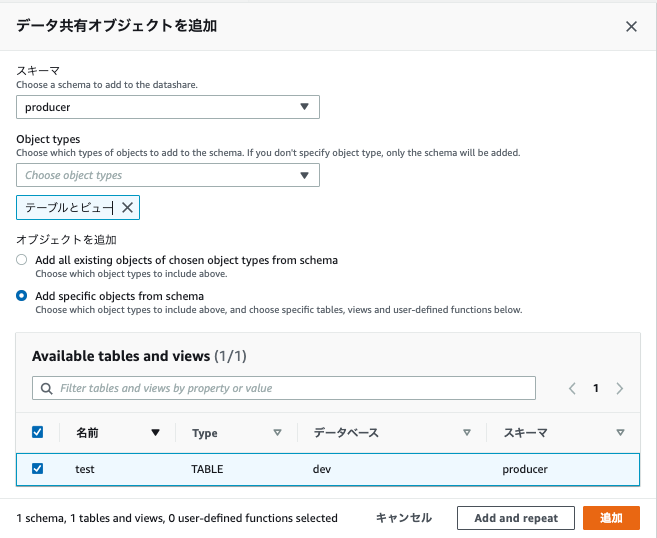
- スキーマを「producer」
- Object typesを「テーブルとビュー」
- オブジェクトを追加で「Add specific objects from schema」
- テーブルが選択できるので、「test」テーブルを選択し「追加」をクリックします。
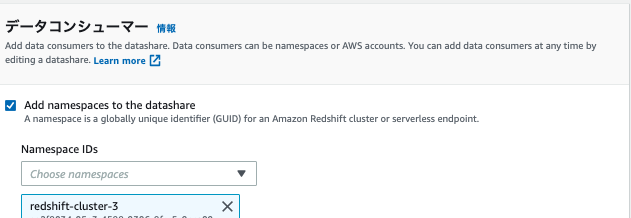
- データコンシューマで Add namespaces to the datashareをクリックし、コンシューマクラスタ「redshift-cluster-3」を選択します。
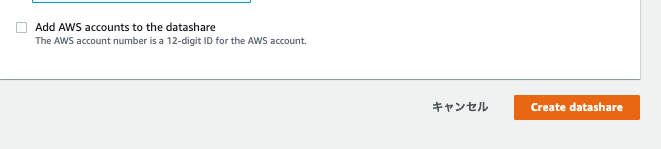
- Add AWS account to the datashareのチェックを外し、「Create datashare」をクリックします。
4.データ共有で作成されたデータ共有名を確認します。
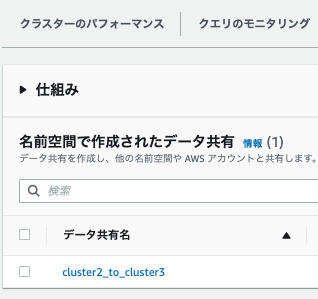
コンシューマの設定
プロデューサーで共有されたオブジェクトを参照できるように設定します。
1.コンシュマークラスタのマネコンで、データ共有タブから以下が参照できることを確認します。
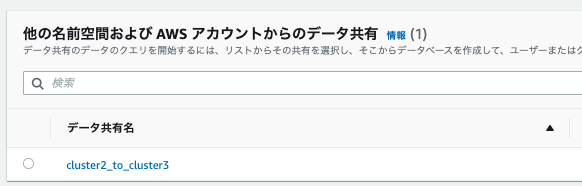
- データ共有名に、プロデューサーで設定した「cluster2_to_clsuter3」が見える。
2.データ共有名をクリックし、「データ共有からデータベースを作成」をクリックします。

3.以下を入力し、「作成」をクリックします。
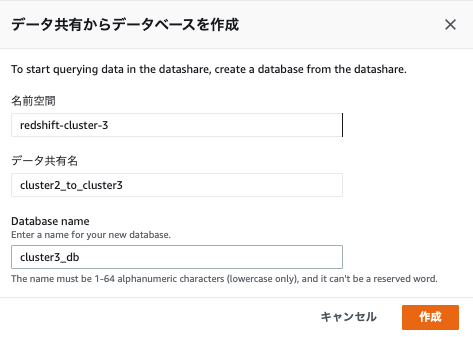
- 名前空間を「redshift-cluster-3」※デフォルト
- データ共有名を「cluster2_to_cluster3」※作成したデータ共有名がデフォルトで設定されている
- Database nameを任意の名称。ここでは「cluster3_db」としています。
4.以下の設定を確認します。
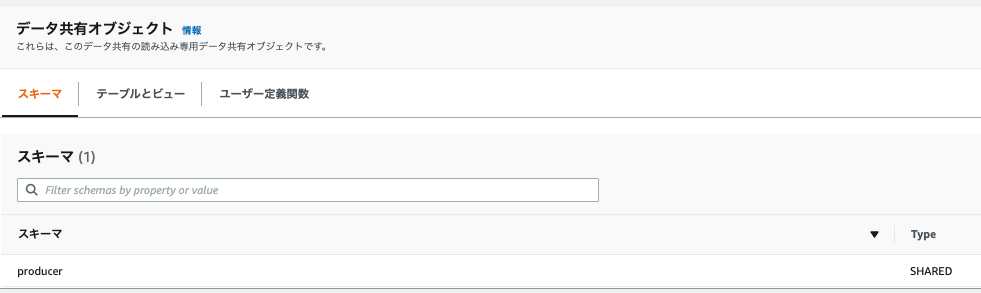
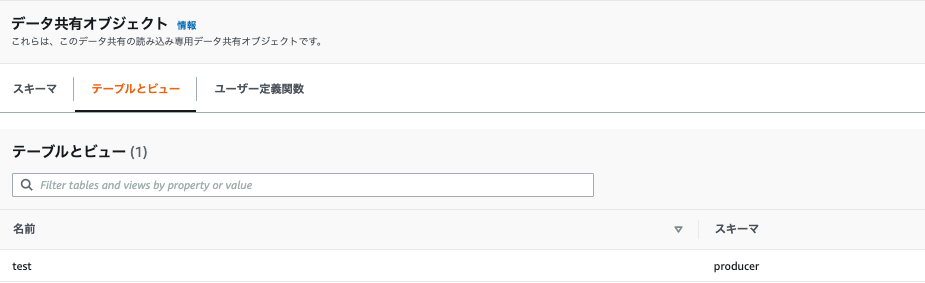
- コンシューマデータベースの「Database name」が設定された「cluster3_db」になっていること。
- データ共有オブジェクトのスキーマで「producer」が参照できること。
- テーブルとビューで、「test」テーブルが参照できること。
データの確認
Cluster3に接続し、SQLでデータが参照できることを確認します。
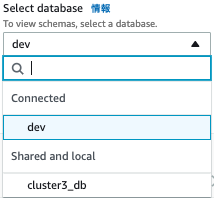
- 先程まで確認できなかったShared and localに「cluster3_db」が見えます。
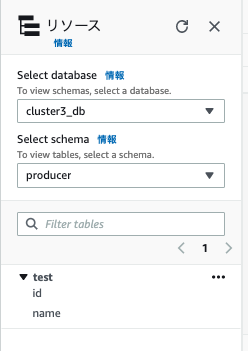
- cluster3_dbを選択すると、「producer」スキーマ、「test」テーブルが確認できました。
以下のSQLを実行しデータを確認します。
select * from cluster3_db.producer.test
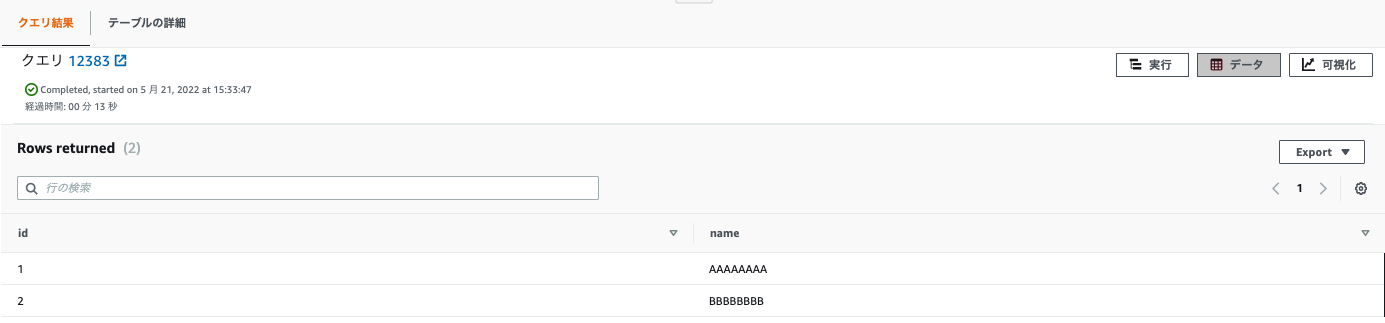
- プロデューサークラスタ(cluster2)で確認した内容と、同じ内容が確認できました。
データ共有の設定(スキーマ単位の設定)
テーブル単位の設定は面倒なので、スキーマ単位で設定してみます。
事前確認
1.プロデューサー
プロデューサーのテーブルを確認します。以下の3テーブルあります。
- test
- data_sharing_table
- data_sharing_table_test

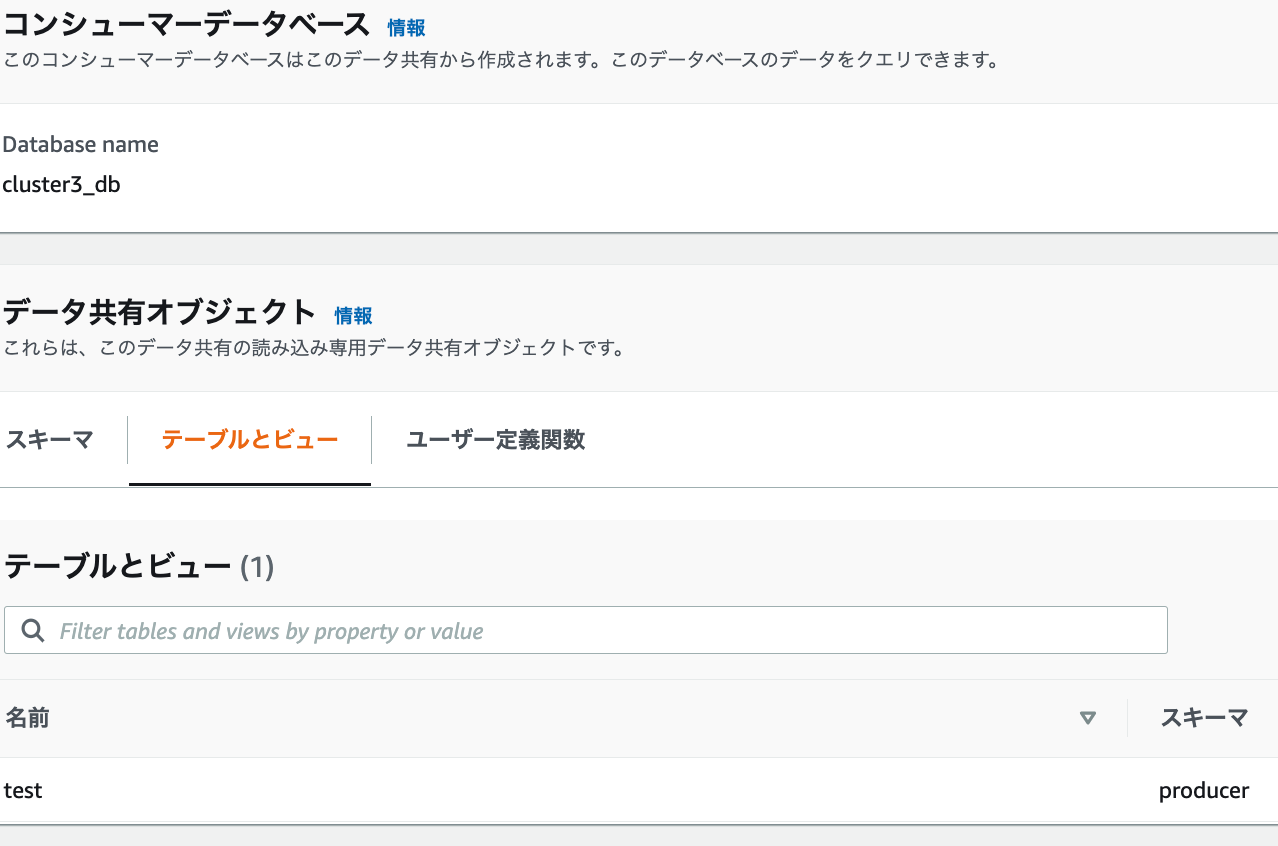
2.コンシューマ
現在のデータシェアリングの設定では、プロデューサーのtestテーブルのみ見えます。
プロデューサーの設定
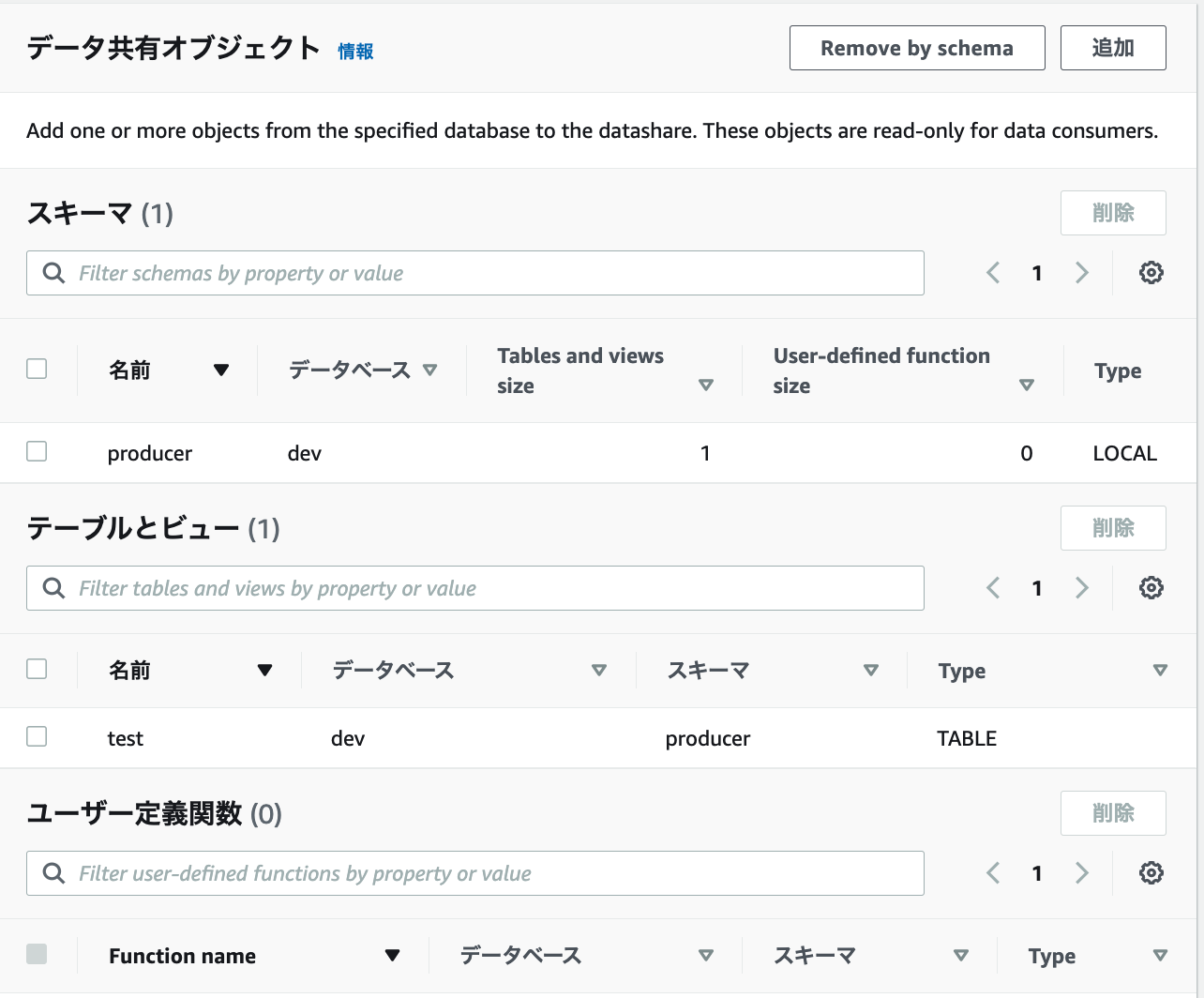
1.データ共有オブジェクトの追加をクリックします。
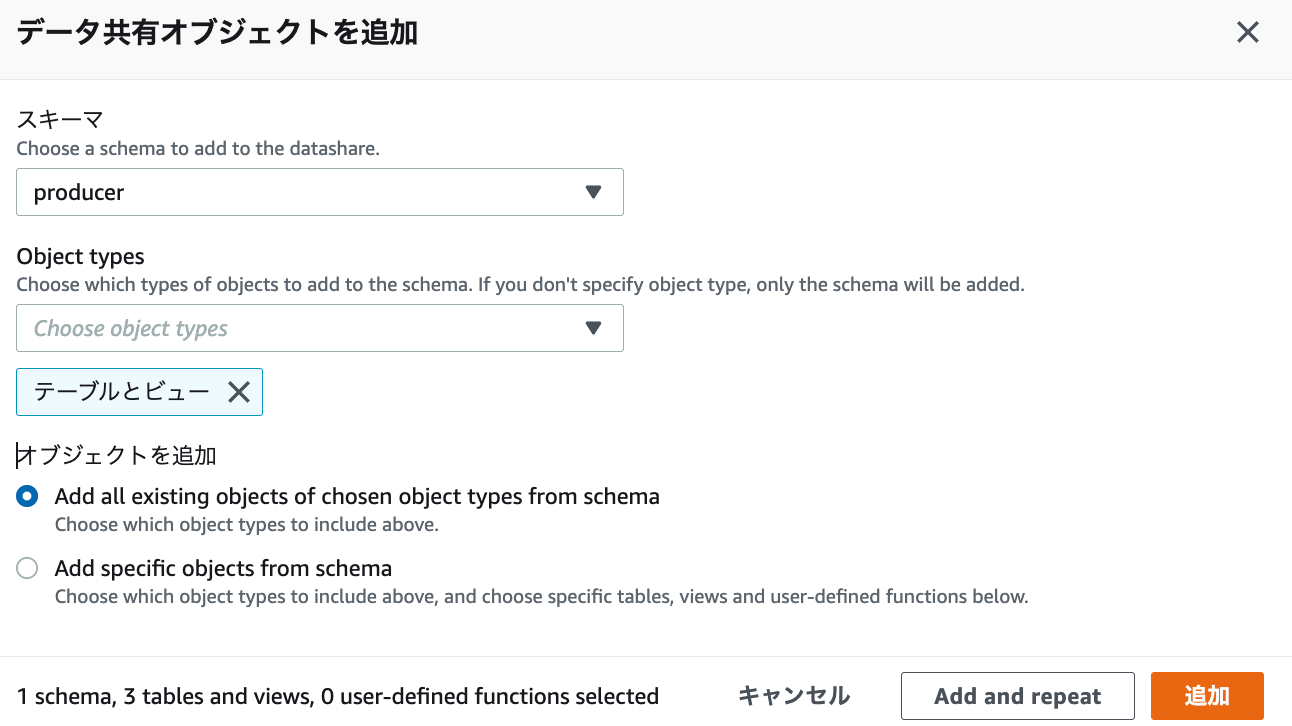
2.データ共有オブジェクトを追加。以下を選択し追加をクリックします。
- スキーマは、producerを選択
- Object typesは、テーブルとビューを選択
- オブジェクトを追加は、Add all existing objects of chosen object types from schemaを選択
- これによりスキーマ全体のオブジェクトが対象になります。
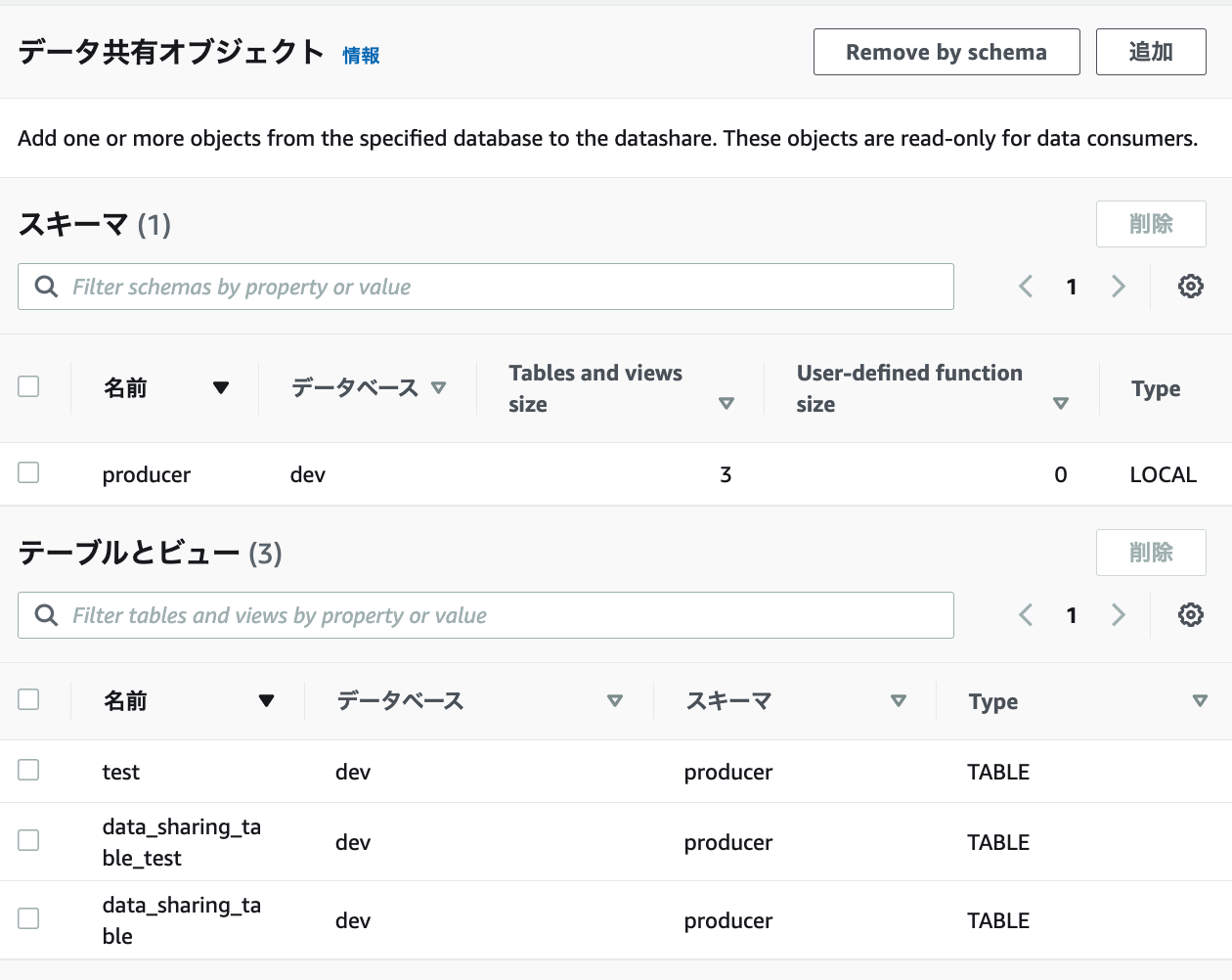
3.確認
設定前は、testテーブルだけでしたが、2つのテーブルが新たに追加されました。
「Add AWS accounts to the datashare」は外してSave Changesをクリックします。
コンシューマの確認
3つのテーブルが確認できました。
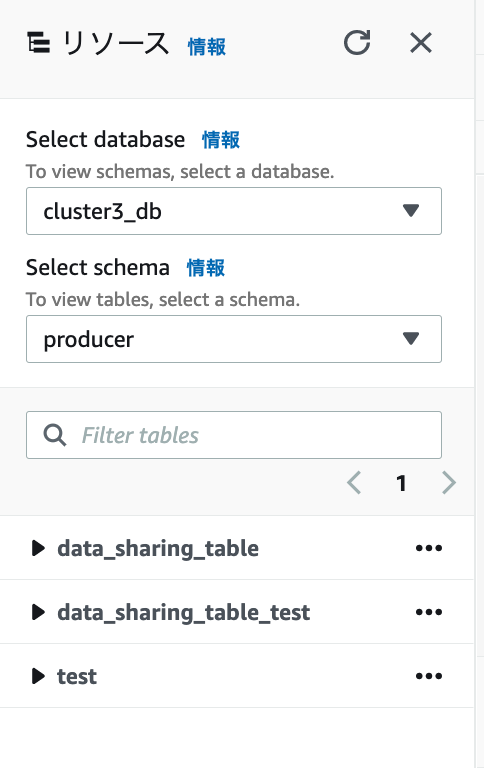
プロデューサーにテーブルを追加したテーブルは、設定なしでコンシュマーで確認できるか
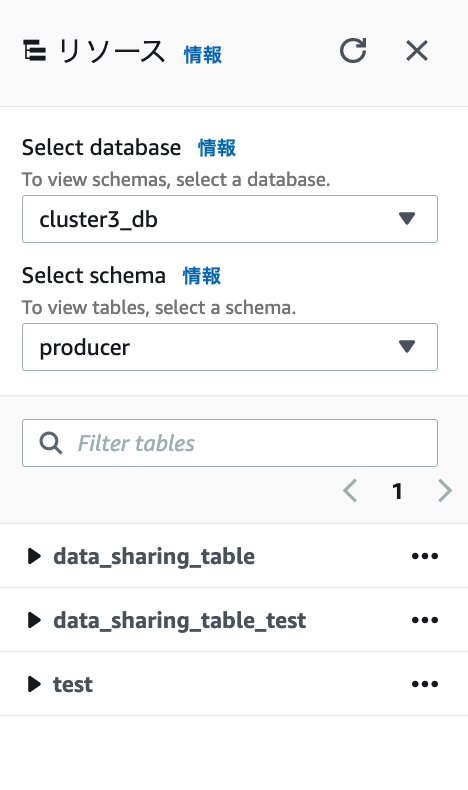
プロデューサーの設定
1.テーブル追加前の状態
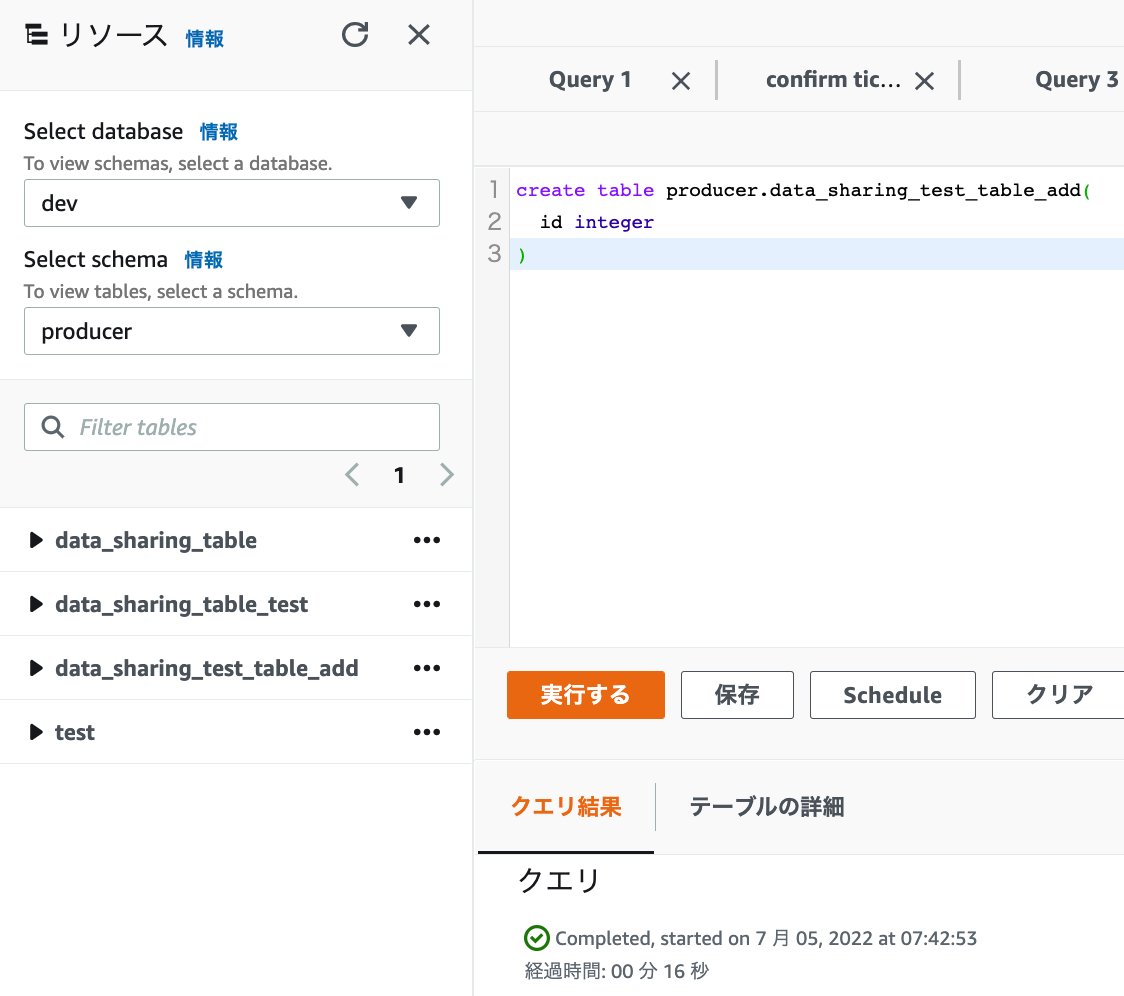
2.テーブル「producer.data_sharing_test_table_add」を作成します。
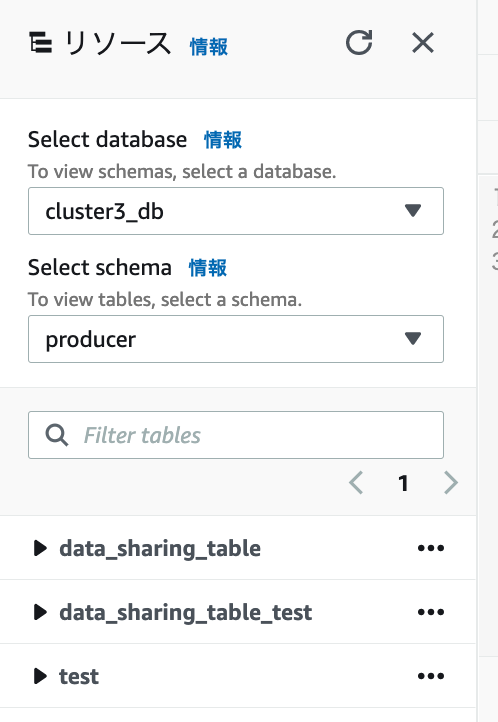
コンシュマーの確認
プロデューサーにテーブルを追加したら、コンシューマ先にも自動でテーブルが追加されると思っていましたが想定と違いました。
1.新しく追加されたテーブルは表示されない。
ALTER DATASHARE cluster2_to_cluster3 SET INCLUDENEW TRUE FOR SCHEMA producer;
考察
今回は、データ共有を試してみました。
コンシュマー側のコンピュートリソースが使用されるということで、比較的大きい会社の複数の組織名等でワークロードが異なる場合にクラスタを分けて構築し、データを共有することで
会社全体として見たときに利用料金は最適化されると感じました。
また、共通のクラスタで問題が起きがちなクエリの実行待ちなどのノイジネイバーの問題も解消できると思いました。
参考