背景・目的
以前、Sparkのファイルとパーティションの関係について確認してみた という記事で、読み込むファイルフォーマットとパラメータspark.sql.files.maxPartitionBytesの設定値により、Spark内部で取り扱うパーティション数がどのように変化するかを確認しました。
今回は、圧縮されたファイルでも分割されるか確認します。
まとめ
圧縮されたファイルのうち、gz圧縮は分割されず、snappy圧縮は分割されました。
| # | シナリオ | ファイルフォーマット | 圧縮形式 | 結果 |
|---|---|---|---|---|
| 1 | JSONファイルで非圧縮で分割されるか確認する | JSON | なし | 分割される |
| 2 | JSONファイルで圧縮済で分割されるか確認する | JSON | gz | 分割されない |
| 3 | Parquetファイルで非圧縮で分割されるか確認する | Parquet | なし | 分割される |
| 4 | Parquetファイルで圧縮済で分割されるか確認する | Parquet | snappy | 分割される |
実践
事前準備
シナリオ1
- JSON圧縮なしファイルをscenario1フォルダに配置します。ファイルサイズは441バイトです。
$ aws s3 ls {バケット名}/input/split/scenario1/test.json 2023-05-18 21:09:02 441 test.json $ $ aws s3 cp s3://{バケット名}/input/split/scenario1/test.json - | cat {"id":"1","value":1} {"id":"2","value":2} {"id":"3","value":3} {"id":"4","value":4} {"id":"5","value":5} {"id":"6","value":6} {"id":"7","value":7} {"id":"8","value":8} {"id":"9","value":9} {"id":"10","value":10} {"id":"11","value":11} {"id":"12","value":12} {"id":"13","value":13} {"id":"14","value":14} {"id":"15","value":15} {"id":"16","value":16} {"id":"17","value":17} {"id":"18","value":18} {"id":"19","value":19} {"id":"20","value":20} $
シナリオ2
- JSON圧縮済みファイルをscenario2フォルダに配置します。ファイルサイズは圧縮済みで146バイトです。
$ aws s3 ls s3://{バケット名}/input/split/scenario2/test-gz.json.gz 2023-05-18 22:05:28 146 test-gz.json.gz $ aws s3 cp s3://{バケット名}/input/split/scenario2/test-gz.json.gz - | gunzip {"id":"1","value":1} {"id":"2","value":2} {"id":"3","value":3} {"id":"4","value":4} {"id":"5","value":5} {"id":"6","value":6} {"id":"7","value":7} {"id":"8","value":8} {"id":"9","value":9} {"id":"10","value":10} {"id":"11","value":11} {"id":"12","value":12} {"id":"13","value":13} {"id":"14","value":14} {"id":"15","value":15} {"id":"16","value":16} {"id":"17","value":17} {"id":"18","value":18} {"id":"19","value":19} {"id":"20","value":20} $
シナリオ3
- scenario1のファイルを元にParquetファイルを作成し、scenario3フォルダに配置します。
from pyspark.sql import SparkSession print("** before ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) spark.conf.set('spark.sql.files.maxPartitionBytes','500') print("** after ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) session = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = session.read.json("s3://{バケット名}/input/split/scenario1/") df.count() print('** after ** Number of partitions: [{0}]'.format(df.rdd.getNumPartitions())) df.write.mode("overwrite").option("compression", "none").parquet("s3://{バケット名}/input/split/scenario3/") - ファイルを確認します。非圧縮で955バイトでした。metaを確認すると非圧縮であることが分かります。
$ aws s3 ls s3://{バケット名}/input/split/scenario3/part-00000-688aafb8-013e-4898-b876-b877173c2bea-c000.parquet 2023-05-18 22:30:23 955 part-00000-688aafb8-013e-4898-b876-b877173c2bea-c000.parquet $ aws s3 cp s3://{バケット名}/input/split/scenario3/part-00000-688aafb8-013e-4898-b876-b877173c2bea-c000.parquet . download: s3://{バケット名}/input/split/scenario3/part-00000-688aafb8-013e-4898-b876-b877173c2bea-c000.parquet to ./part-00000-688aafb8-013e-4898-b876-b877173c2bea-c000.parquet $ parquet-tools cat part-00000-688aafb8-013e-4898-b876-b877173c2bea-c000.parquet id = 1 value = 1 id = 2 value = 2 id = 3 value = 3 id = 4 value = 4 id = 5 value = 5 id = 6 value = 6 id = 7 value = 7 id = 8 value = 8 id = 9 value = 9 id = 10 value = 10 id = 11 value = 11 id = 12 value = 12 id = 13 value = 13 id = 14 value = 14 id = 15 value = 15 id = 16 value = 16 id = 17 value = 17 id = 18 value = 18 id = 19 value = 19 id = 20 value = 20 $ $ parquet-tools meta part-00000-688aafb8-013e-4898-b876-b877173c2bea-c000.parquet file: file:/xxxx/applicaiton-jobs-stages/part-00000-688aafb8-013e-4898-b876-b877173c2bea-c000.parquet creator: parquet-mr version 1.12.2 (build 88690eb334b5f0273c2b37d8d767559f594bf245) extra: org.apache.spark.version = 3.3.1 extra: org.apache.spark.sql.parquet.row.metadata = {"type":"struct","fields":[{"name":"id","type":"string","nullable":true,"metadata":{}},{"name":"value","type":"long","nullable":true,"metadata":{}}]} file schema: spark_schema -------------------------------------------------------------------------------- id: OPTIONAL BINARY L:STRING R:0 D:1 value: OPTIONAL INT64 R:0 D:1 row group 1: RC:20 TS:333 OFFSET:4 -------------------------------------------------------------------------------- id: BINARY UNCOMPRESSED DO:0 FPO:4 SZ:142/142/1.00 VC:20 ENC:PLAIN,BIT_PACKED,RLE ST:[min: 1, max: 9, num_nulls: 0] value: INT64 UNCOMPRESSED DO:0 FPO:146 SZ:191/191/1.00 VC:20 ENC:PLAIN,BIT_PACKED,RLE ST:[min: 1, max: 20, num_nulls: 0] $
シナリオ4
-
scenario1のファイルを元にParquet&Snappyファイルを作成し、scenario4フォルダに配置します。
from pyspark.sql import SparkSession print("** before ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) spark.conf.set('spark.sql.files.maxPartitionBytes','500') print("** after ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) print("** before ** spark.sql.parquet.compression.codec: [{0}] ".format(spark.conf.get('spark.sql.parquet.compression.codec'))) spark.conf.set('spark.sql.parquet.compression.codec','snappy') print("** before ** spark.sql.parquet.compression.codec: [{0}] ".format(spark.conf.get('spark.sql.parquet.compression.codec'))) session = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = session.read.json("s3://{バケット名}/input/split/scenario1/") df.count() print('** after ** Number of partitions: [{0}]'.format(df.rdd.getNumPartitions())) df.write.mode("overwrite").option("compression", "snappy").parquet("s3://{バケット名}/input/split/scenario4/") -
ファイルを確認します。Snappy圧縮で912バイトでした。また、metaを確認すると各カラムはsnappyで圧縮されていることが分かりました。
$ aws s3 ls s3://{バケット名}/input/split/scenario4/part-00000-608661fa-5198-4bea-a46d-7e1fbe294c66-c000.snappy.parquet 2023-05-18 23:26:19 912 part-00000-608661fa-5198-4bea-a46d-7e1fbe294c66-c000.snappy.parquet $ $ aws s3 cp s3://{バケット名}/input/split/scenario4/part-00000-608661fa-5198-4bea-a46d-7e1fbe294c66-c000.snappy.parquet . download: s3://{バケット名}/input/split/scenario4/part-00000-608661fa-5198-4bea-a46d-7e1fbe294c66-c000.snappy.parquet to ./part-00000-608661fa-5198-4bea-a46d-7e1fbe294c66-c000.snappy.parquet $ parquet-tools cat part-00000-608661fa-5198-4bea-a46d-7e1fbe294c66-c000.snappy.parquet id = 1 value = 1 id = 2 value = 2 id = 3 value = 3 id = 4 value = 4 id = 5 value = 5 id = 6 value = 6 id = 7 value = 7 id = 8 value = 8 id = 9 value = 9 id = 10 value = 10 id = 11 value = 11 id = 12 value = 12 id = 13 value = 13 id = 14 value = 14 id = 15 value = 15 id = 16 value = 16 id = 17 value = 17 id = 18 value = 18 id = 19 value = 19 id = 20 value = 20 $ parquet-tools meta part-00000-608661fa-5198-4bea-a46d-7e1fbe294c66-c000.snappy.parquet file: file:/xxx/part-00000-608661fa-5198-4bea-a46d-7e1fbe294c66-c000.snappy.parquet creator: parquet-mr version 1.12.2 (build 88690eb334b5f0273c2b37d8d767559f594bf245) extra: org.apache.spark.version = 3.3.1 extra: org.apache.spark.sql.parquet.row.metadata = {"type":"struct","fields":[{"name":"id","type":"string","nullable":true,"metadata":{}},{"name":"value","type":"long","nullable":true,"metadata":{}}]} file schema: spark_schema -------------------------------------------------------------------------------- id: OPTIONAL BINARY L:STRING R:0 D:1 value: OPTIONAL INT64 R:0 D:1 row group 1: RC:20 TS:333 OFFSET:4 -------------------------------------------------------------------------------- id: BINARY SNAPPY DO:0 FPO:4 SZ:119/142/1.19 VC:20 ENC:RLE,PLAIN,BIT_PACKED ST:[min: 1, max: 9, num_nulls: 0] value: INT64 SNAPPY DO:0 FPO:123 SZ:171/191/1.12 VC:20 ENC:RLE,PLAIN,BIT_PACKED ST:[min: 1, max: 20, num_nulls: 0] $
シナリオ
下記のシナリオで検証します。
- シナリオ1:JSONファイルで非圧縮で分割されるか確認する
- シナリオ2:JSONファイルで圧縮済で分割されるか確認する
- シナリオ3:Parquetファイルで非圧縮で分割されるか確認する
- シナリオ4:Parquetファイルで圧縮済で分割されるか確認する
シナリオ1 JSONファイルで非圧縮の場合に分割されるか
このシナリオは、以前も試したので問題なく分割されることは分かっていますが、念の為試します。
-
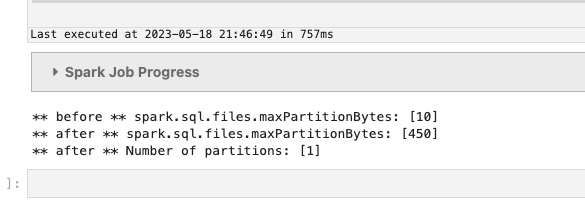
まずはファイルサイズ(441バイト) < 最大分割サイズ(450バイト)で試します。
from pyspark.sql import SparkSession print("** before ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) spark.conf.set('spark.sql.files.maxPartitionBytes','450') print("** after ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) session = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = session.read.json("s3://{バケット名}/input/split/scenario1/") df.count() print('** after ** Number of partitions: [{0}]'.format(df.rdd.getNumPartitions())) -
パーティションは1つです。
-
ファイルサイズ(441バイト) > 最大分割サイズ(200バイト)で試します。変更点だけ載せます。
spark.conf.set('spark.sql.files.maxPartitionBytes','200') -
想定通り分割されました。(パーティションは3つになりました。)

シナリオ2 JSONファイルで圧縮の場合に分割されるか
検証結果:JSONファイルをgz圧縮されたファイルは分割されません。
-
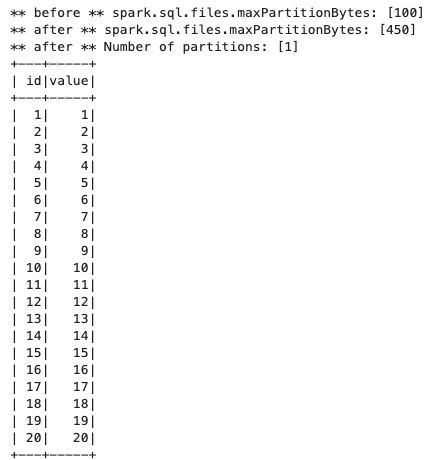
まずはファイルサイズ(146バイト) < 最大分割サイズ(450バイト)で試します。
from pyspark.sql import SparkSession print("** before ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) spark.conf.set('spark.sql.files.maxPartitionBytes','450') print("** after ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) session = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = session.read.json("s3://{バケット名}/input/split/scenario2/") df.count() print('** after ** Number of partitions: [{0}]'.format(df.rdd.getNumPartitions())) df.show() -
パーティションは1つです。
-
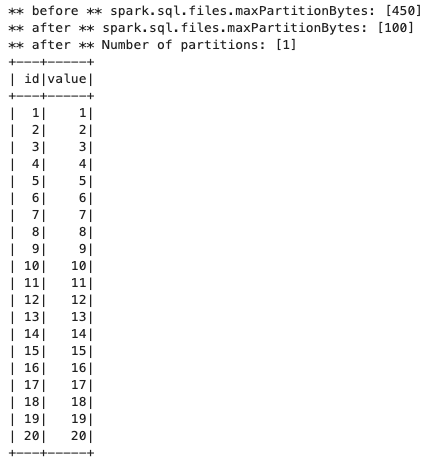
ファイルサイズ(146バイト) > 最大分割サイズ(100バイト)で試します。変更点だけ載せます。
spark.conf.set('spark.sql.files.maxPartitionBytes','100') -
分割されませんでした。(パーティションは1つのままです。)
シナリオ3 Parquetファイルで非圧縮の場合に分割されるか
このシナリオは、以前も試したので問題なく分割されることは分かっていますが、念の為試します。
-
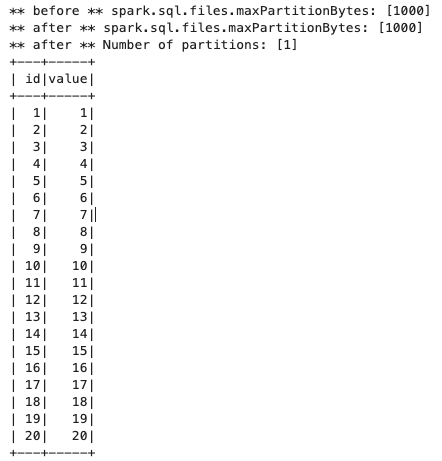
まずはファイルサイズ(955バイト) < 最大分割サイズ(1000バイト)で試します。
from pyspark.sql import SparkSession print("** before ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) spark.conf.set('spark.sql.files.maxPartitionBytes','1000') print("** after ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) session = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = session.read.parquet("s3://{バケット名}/input/split/scenario3/") df.count() print('** after ** Number of partitions: [{0}]'.format(df.rdd.getNumPartitions())) df.show() -
パーティションは1つです。
-
ファイルサイズ(955バイト) > 最大分割サイズ(100バイト)で試します。変更点だけ載せます。
spark.conf.set('spark.sql.files.maxPartitionBytes','100') -
想定通り分割されました。(パーティションは10になりました。)
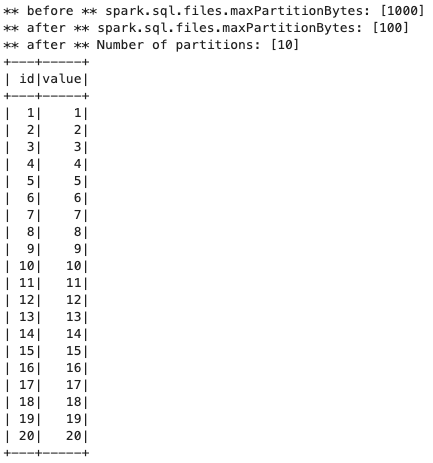
シナリオ4 Parquetファイルで圧縮の場合に分割されるか
-
まずはファイルサイズ(912バイト) < 最大分割サイズ(1000バイト)で試します。
from pyspark.sql import SparkSession print("** before ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) spark.conf.set('spark.sql.files.maxPartitionBytes','1000') print("** after ** spark.sql.files.maxPartitionBytes: [{0}] ".format(spark.conf.get('spark.sql.files.maxPartitionBytes'))) session = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = session.read.parquet("s3://{バケット名}/input/split/scenario4/") df.count() print('** after ** Number of partitions: [{0}]'.format(df.rdd.getNumPartitions())) df.show() -
パーティションは1つです。

-
ファイルサイズ(912バイト) > 最大分割サイズ(100バイト)で試します。変更点だけ載せます。
spark.conf.set('spark.sql.files.maxPartitionBytes','100') -
想定通り分割されました。(パーティションは10になりました。)
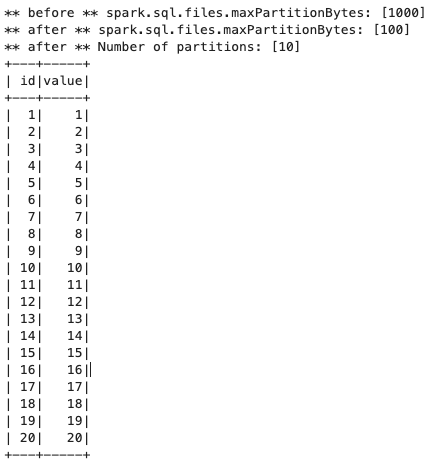
考察
今回、圧縮済みのファイルに対して、パーティション分割が有効になるか確認してみました。Snappy圧縮されたParquetファイルでは、パーティション分割されることが分かりました。
現時点では、Parquetファイルの詳細な仕様がわかっていないので確実なことは言えませんが、Parquetファイルは、各カラムごとに圧縮されているので、うまく分割できるのかもしれません。今後はParquetファイルの仕様を確認してみようと思います。
参考