背景・目的
2022年7月に、RedshiftサーバレスがGAになりました。
少し間が空いてしまいましたが、どのような特徴があるか整理し、試してみます。
まとめ
- スケーリングを自動で実行する
- サーバレスのキャパシティはRPUという単位で設定する。RPUは32RPU〜512RPUの間で8 RPU単位で設定する。
- メンテナンスウィンドウは無い
- 名前空間とワークグループという概念が有る
- 名前空間は、データベースとオブジェクトとユーザのコレクションである。
- ワークグループは、コンピューティングリソースの集合
概要
特徴
下記の特徴があります。
- データウェアハウスをプロビジョニングして管理不要
- データウェアハウス容量のプロビジョニングとスケーリングを自動的に実行
メリット
下記のメリットがあります。
- データにアクセスして分析を行う際に、セットアップや調整、管理の必要はない
- データレイクとの統合などを使用して、データウェアハウス、データレイク、オペレーショナルなデータソースをシームレスにクエリできる
- インテリジェントなオートスケーリングにより、最も要求の厳しい不安定なワークロードでも、高いパフォーマンスとシンプルなオペレーションを実現できる
- ワークグループと名前空間を使用して、きめ細かなコスト管理でコンピューティングリソースとデータを整理できる
- 料金は、データウェアハウスが使用されている場合にのみ発生する。
考慮事項
下記の考慮事項があります。(正確な内容は、こちらをご確認ください。)
- メンテナンスウィンドウは使用できない。ソフトウェアの更新は自動で適用される。
- バージョンを切り替えても既存の接続やクエリの実行は中断されず、新しい接続は常にRedshift Serverlessと瞬時に接続して動作される。
- 3つのサブネットを使用し、3つのAZにまたがる必要がある。
- サーバレスのワークグループを作成する際は、IPアドレスに空きが必要。RPU(Redshift Processing Unit)が増えるにつれて、
- ※必要なIPアドレス数は必要。詳細はこちらのワークグループ作成時に必要な最低空きIPアドレス数を確認。
- プロビジョニングされたRedshiftクラスタからServerlessに移行した場合に、移行後にストレージ領域の割り当てが増加する。
- データシェアリングで、Serverlessがプロデューサーで、プロビジョニングクラスタがコンシューマの場合、プロビジョニングされたクラスターバージョンは1.038214以降の必要がある
- 最大のクエリ実行時間について、設定された実行時間を超えるとクエリを中心する。(設定可能な値は0〜86,399)
容量
容量の計算には、RPU(Redshift Processing Unit)という単位で容量が測定されます。ワークロードの処理に使用されるリソース
クエリの処理に使用する基本容量を設定する。基本容量はRPUで指定し、大きくすることでパフォーマンスが向上する。
基本容量の設定は、32 RPU〜512 RPUまで8RPU単位で設定が可能。(デフォルトは128 RPU)
請求
下記に請求について概要を記載します。詳細はこちらをご確認ください。
- クエリ実行では、秒単位のRPUで請求される。実行されていない場合は請求されない。
- ワークグループを作成する場合、基本容量を設定可能。
- Redshiftマネージドストレージ(RMS:Redshift Managed Storage)では、保存されたデータ量に基づき請求される。
- GB/月単位
- RPUの最大時間を設定することで、コスト予測が容易になる。制限に達した場合に、下記のアクションが可能
- ログエントリをシステムテーブルに書き込む。
- アラートを受信
- ユーザクエリをオフ
接続
下記の方法で接続できます。
- JDBCドライバ
- DataAPI
その他の接続について、下記に記載します。
- SSL接続がサポートされている
- マネージドVPCエンドポイントからServerlessへの接続
- 他のVPCエンドポイントからの接続
- RedshiftマネージドVPCエンドポイントから接続
- VPCeを作成すると、別のVPCのクライアントアプリからプライベートにアクセス可能。これによりトラフィックはインターネット経由しないのでパブリックIPは使用しない。
- 通信のプライバシーとセキュリティが向上する
- パブリックにアクセス可能なRedshift Serverlessへ接続
- パブリックインターネットのSQLクライアントからクエリを実行できる。
- パブリックにアクセス可能な設定を有効にすることで、ServelerssはElastic IPアドレスを作成する。VPC外部のクライアントはこれを使用して接続する。
ワークグループと名前空間の概要
下記に概要を記載します。
- 名前空間とは?
- データベースとオブジェクトとユーザのコレクション
- ストレージ関連の名前空間は、下記についてKMSキーをグループ化する
- スキーマ
- テーブル
- ユーザ
- データ
- ワークグループはコンピューティングリソースの集合
- RPU
- VPCサブネットグループ
- セキュリティグループ
- ネットワークとセキュリティ設定
- アクセス権限と、使用制限
- 各名前空間と関連付けるワークグループは1:1の関係
クエリとワークロードのモニタリング
- モニタリングビュー
- クエリとワークロードの使用状況を監視するために使用するシステムビュー
- pg_catalogスキーマ内にある
システムビューは、以下のモニタリング対象をサポートする
- ワークロードモニタリング
- ベースラインとビジネスSLAにあるものを識別
- 平常状態からの逸脱を迅速に特定する
- データのロードとアンロードのモニタリング
- COPYとUNLOADの転送されたバイト/行、完了したファイルの進捗状況をモニタリングする
- 障害と問題の診断
- システムテーブルを利用
- パフォーマンスチューニング
- 実行計画、統計、有効期限、リソース消費量
- ユーザオブジェクトでのイベントのモニタリング
- Materialized Viewの自動更新
- 課金のための使用状況の追跡
- 下記の目的のために、時間の経過に伴う使用状況の傾向変化をモニタリングする
- 予測計画並びに事業の拡大見通し
- コールドデータの削除、潜在的なコスト削減機会の特定
- 下記の目的のために、時間の経過に伴う使用状況の傾向変化をモニタリングする
イベント通知
EventBridgeを使用してイベント通知を管理し、DWHの変更に関する最新情報を伝える。
ログのモニタリング
- 接続、ユーザ、ユーザアクティビティに関するログをCWLのロググループにエクスポートできる。
- CWアラームを作成して、メトリクスを追跡できる。
- メトリクスは、下記に分割され、それぞれワークグループディメンションセットと名前空間ディメンションセットに分類される。
- コンピューティングメトリクス
- データ
- ストレージメトリクス
スナップショットと復旧ポイント
スナップショットは、名前空間内の全てのオブジェクトとデータが含まれます。
下記にスナップショット復旧のシナリオを記載します。
- サーバレススナップショットをサーバレス名前空間に復元
- サーバレススナップショットをプロビジョニングされたクラスターに復元
- プロビジョニングされたスナップショットをサーバレス名前空間に復元
データシェアリング
AWSアカウント内、複数アカウント、AWSリージョンでライブデータを互いに共有できる
実践
こちらを元に試してみます。
事前準備
VPCの作成
VPCと3つのAZにサブネットをそれぞれ作成します。またS3へのVPCeも作成しておきます。

Redshift サーバレスの作成と実行
ワークグループと名前空間の作成
-
サーバレスダッシュボードで「ワークグループを作成」をクリックします。

-
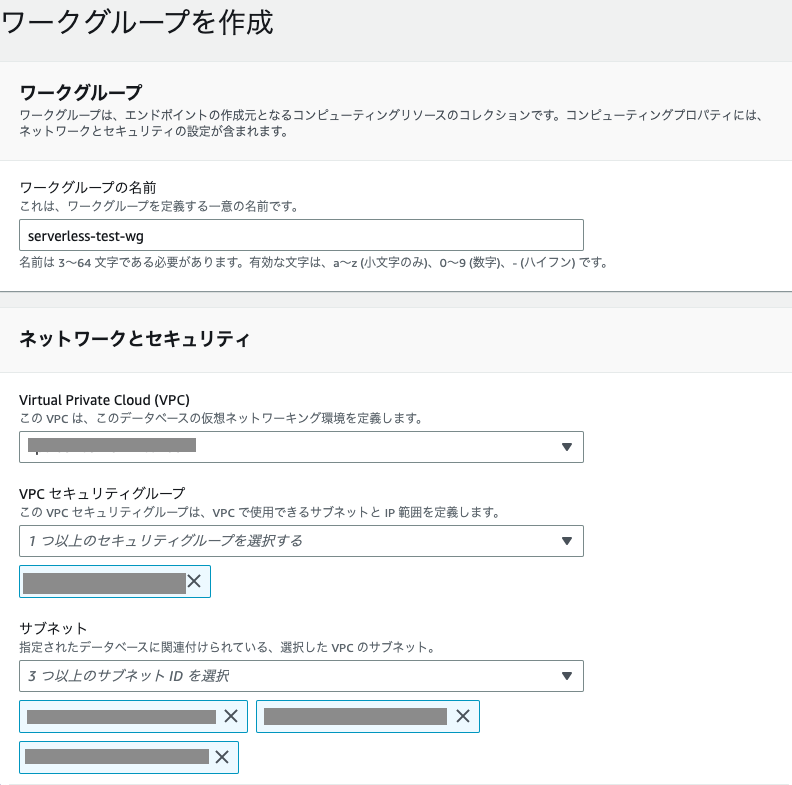
下記を指定して「次へ」をクリックします。
- 任意のワークグループ名
- 作成済みのVPC
- セキュリティグループ
- 作成済みの3つのサブネット
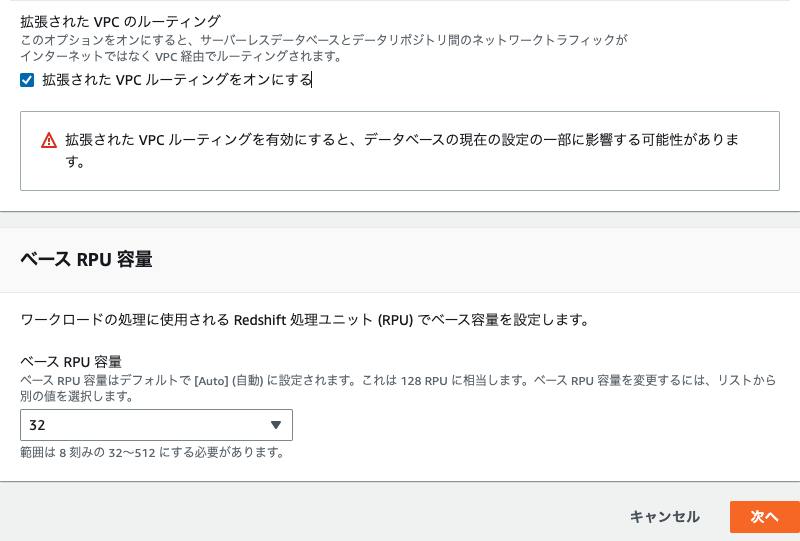
- 拡張されたVPCのルーティングをチェック
- ベールRPU容量を32(最小)
-
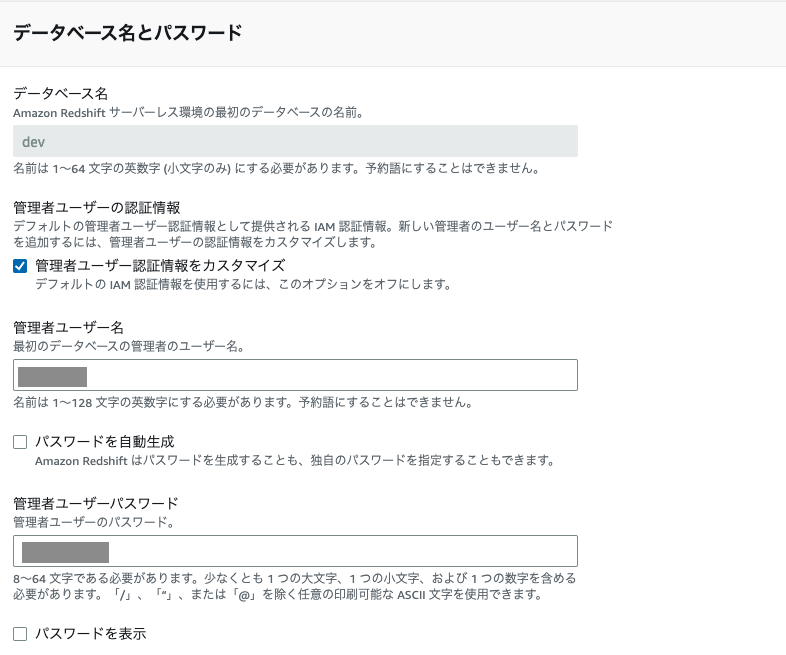
下記を指定して「次へ」をクリックします。
- 任意の名前空間
- データベースの管理者ユーザ名とパスワード
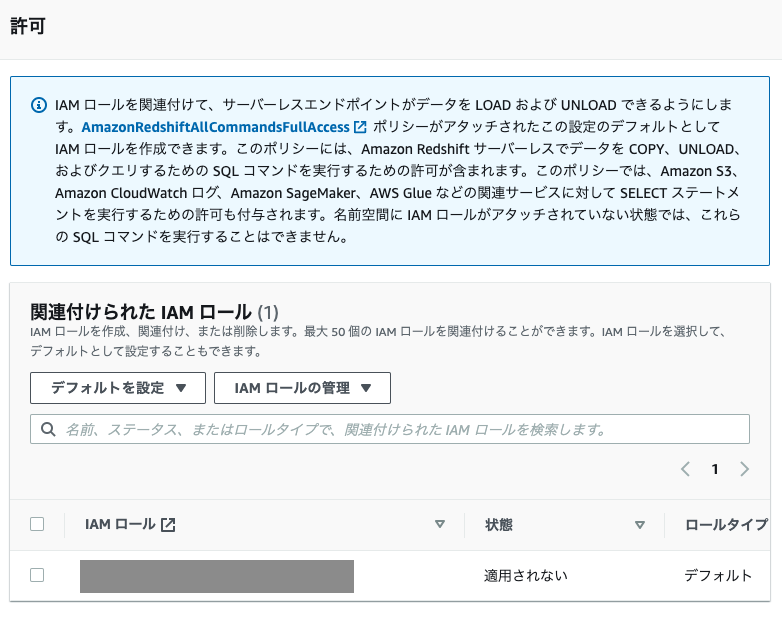
- IAMロール(デフォルト)を使用
- 監査ログ記録

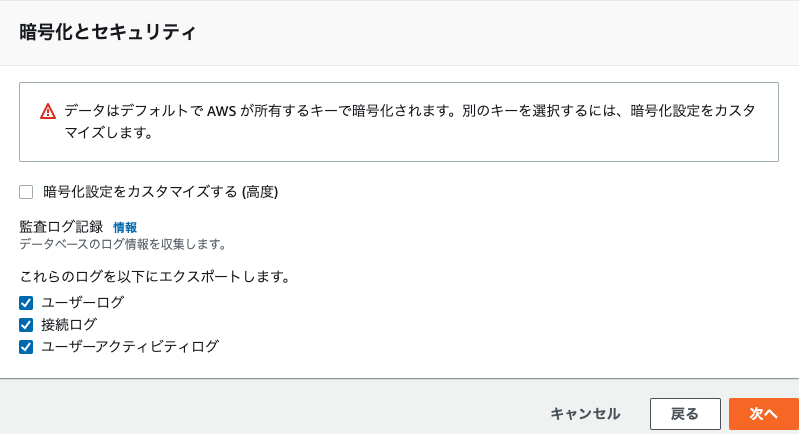
-
確認と作成画面で、内容に相違がなければ「作成」をクリックします。
-
しばらくすると、名前空間とワークグループがAvailableになります。

データの準備
-
「クエリデータ」をクリックし、クエリエディタを起動します。

-
作成したワーキンググループを選択します。
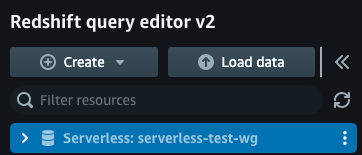
-
ポップアップされるので、下記を入力し「Create connection」をクリックします。
- Database user and password
- Database
- User name
- Password
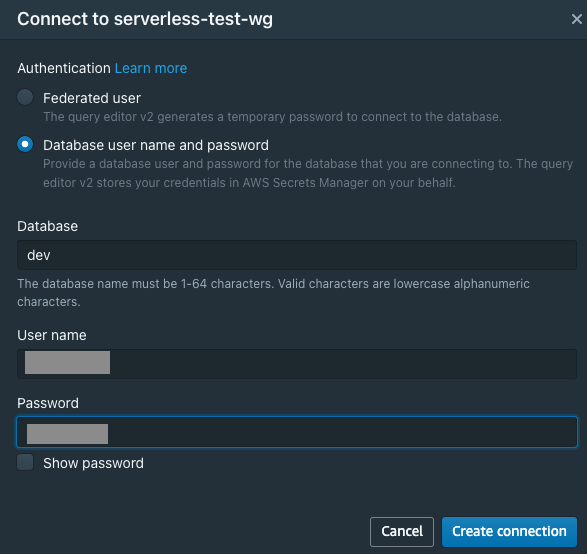
- Database user and password
-
sample_data_devのtickitのフォルダをクリックします。
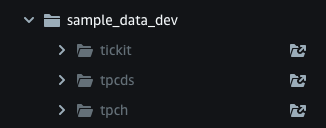
-
Create sample databaseがポップアップされるので「Create」をクリックします。
-
テーブルが作成されたようです。
-
下記のクエリを実行し、それぞれのデータ件数を確認してみます。
SELECT 'category' AS table_name ,count(1) FROM "sample_data_dev"."tickit"."category" UNION ALL SELECT 'date' AS table_name ,count(1) FROM "sample_data_dev"."tickit"."date" UNION ALL SELECT 'event' AS table_name ,count(1) FROM "sample_data_dev"."tickit"."event" UNION ALL SELECT 'listing' AS table_name ,count(1) FROM "sample_data_dev"."tickit"."listing" UNION ALL SELECT 'sales' AS table_name ,count(1) FROM "sample_data_dev"."tickit"."sales" UNION ALL SELECT 'users' AS table_name ,count(1) FROM "sample_data_dev"."tickit"."users" UNION ALL SELECT 'venue' AS table_name ,count(1) FROM "sample_data_dev"."tickit"."venue" -
下記のクエリを実行し、Selectできるか確認してみます。
- カリフォルニアを拠点とするイベントの上位5つの seller を見つけるクエリ ※サンプルデータは2008年のもの
select sellerid, username, (firstname ||' '|| lastname) as sellername, venuestate, sum(qtysold) from "sample_data_dev"."tickit"."sales" AS sales , "sample_data_dev"."tickit"."date" AS date , "sample_data_dev"."tickit"."users" AS users , "sample_data_dev"."tickit"."event" AS event , "sample_data_dev"."tickit"."venue" AS venue where sales.sellerid = users.userid and sales.dateid = date.dateid and sales.eventid = event.eventid and event.venueid = venue.venueid and year = 2008 and venuestate = 'CA' group by sellerid, username, sellername, venuestate order by 5 desc limit 5;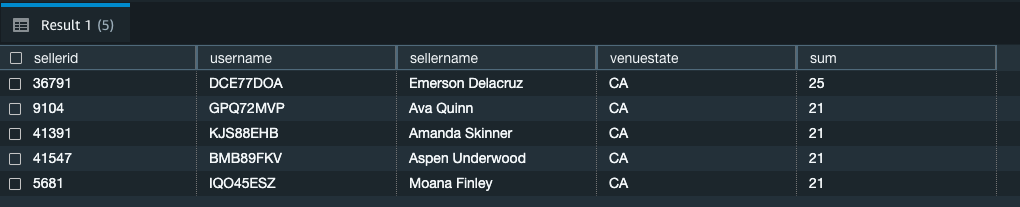
メトリクスの確認
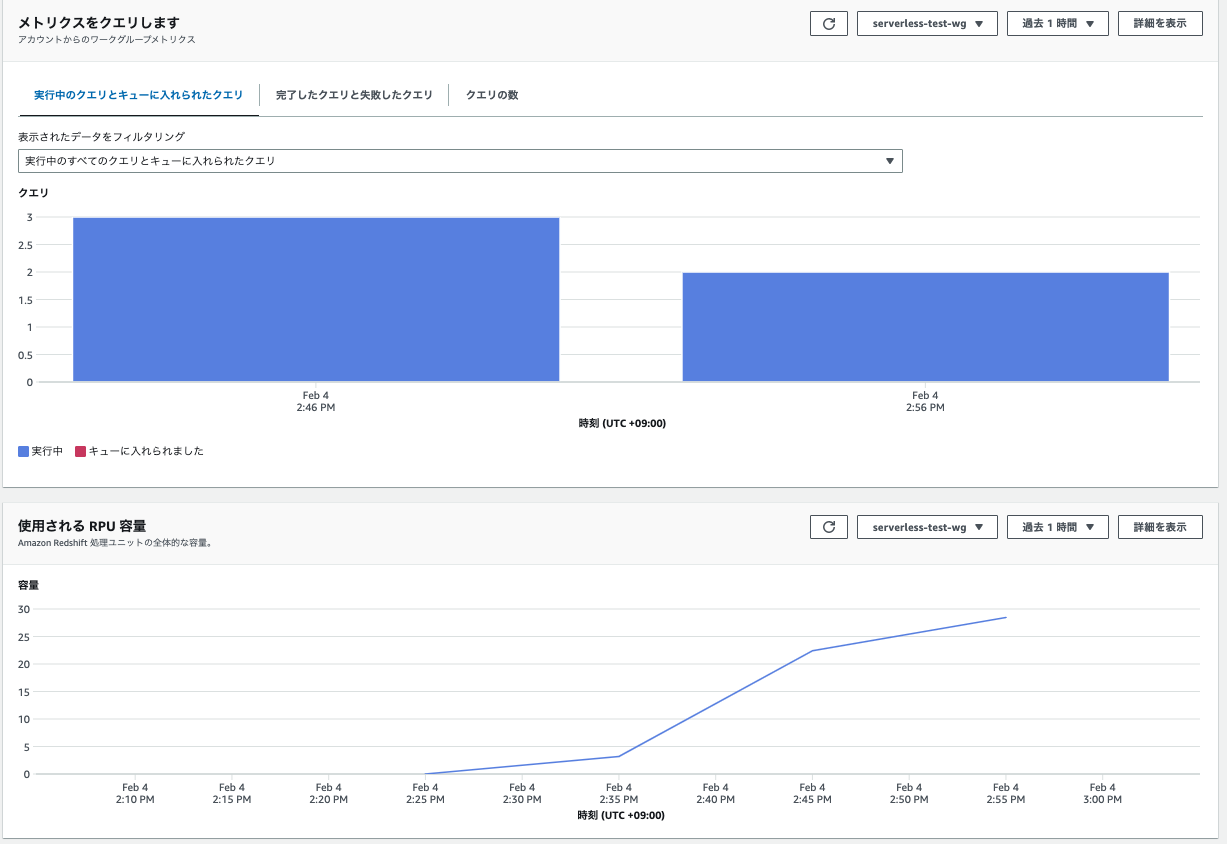
上記の作成からテストクエリの実行までの状態で、メトリクスを確認しています。
- ダッシュボードに遷移します。ダッシュボードでは下記が確認できます。
- クエリ
- 実行中のクエリとキューに入れられたクエリ
- 完了と失敗したクエリ
- 全てのクエリ
- 使用されるRPU容量
- クエリ
クエリの詳細
- 「詳細を表示」をクリックします。
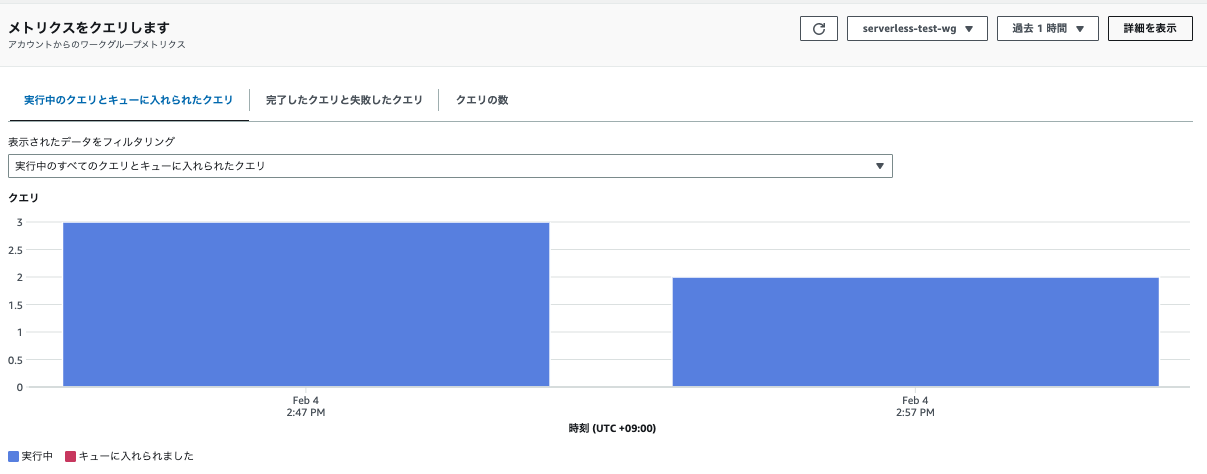
- クエリとデータベースでは下記が確認できます。
- 選択した範囲内と間隔のクエリの数
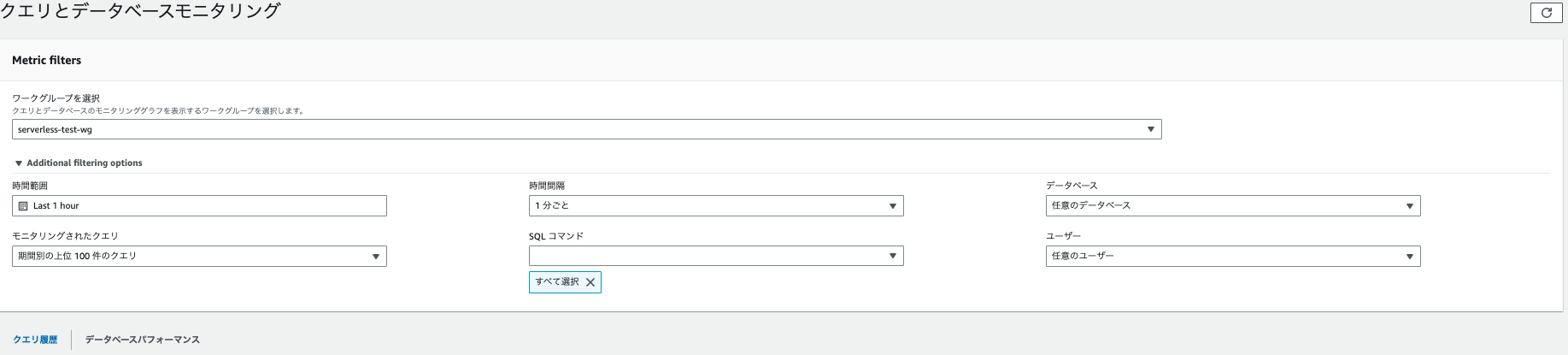
- クエリの状態と実行時間の長さでフィルタリングが可能

- SQLコマンド
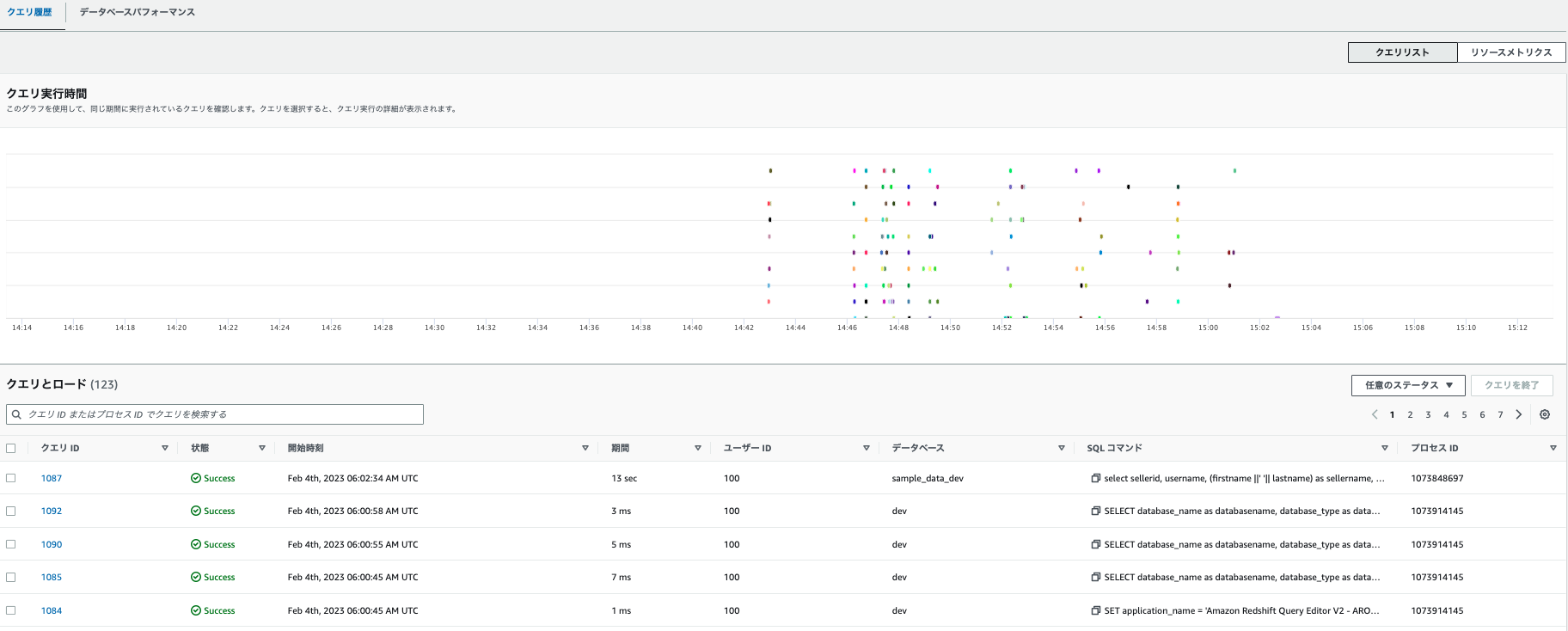
- 選択した範囲内と間隔のクエリの数
- 上記に指定した条件で、クエリがリスト化されます。
- 「リソースメトリクス」をクリックすると単位時間あたりのRPU数が確認できます。
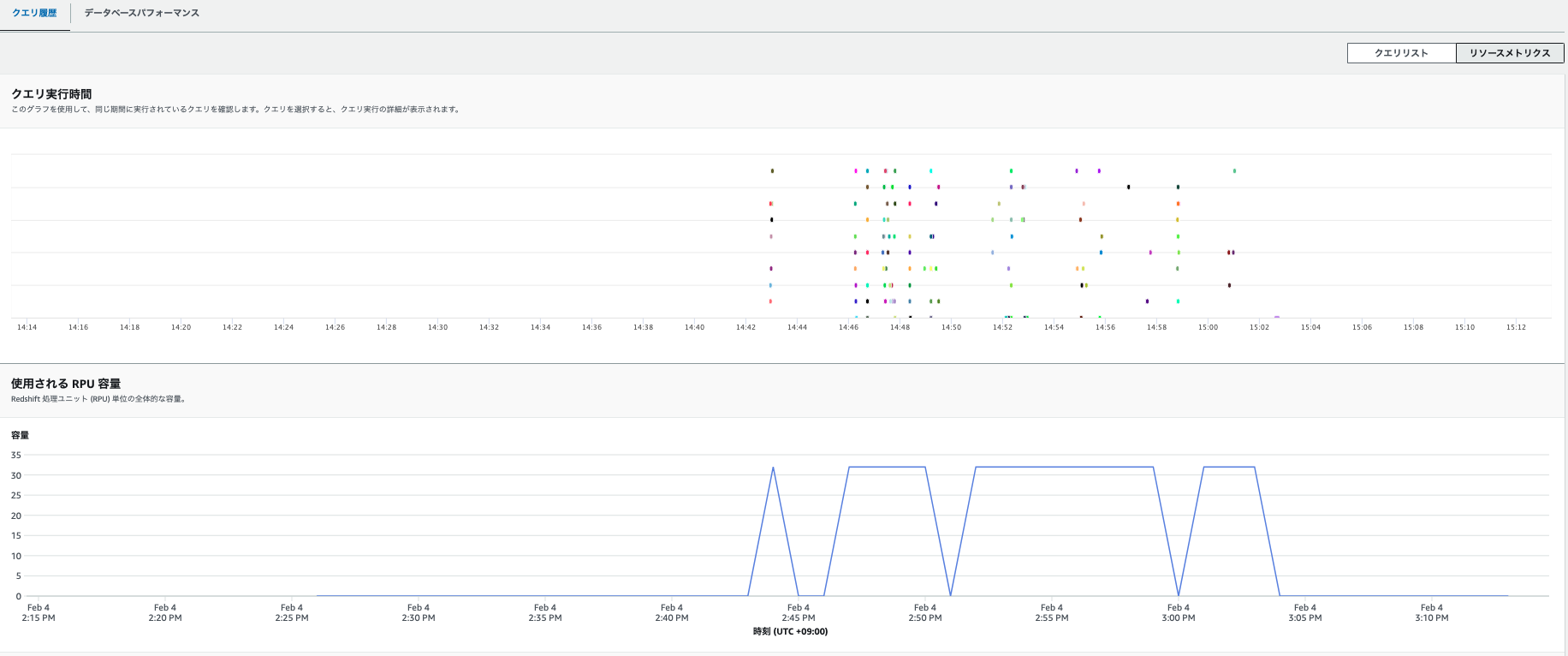
- 「データベースパフォーマンス」をクリックすると下記について確認できます。
- 1秒あたりに完了したクエリ

- クエリ期間
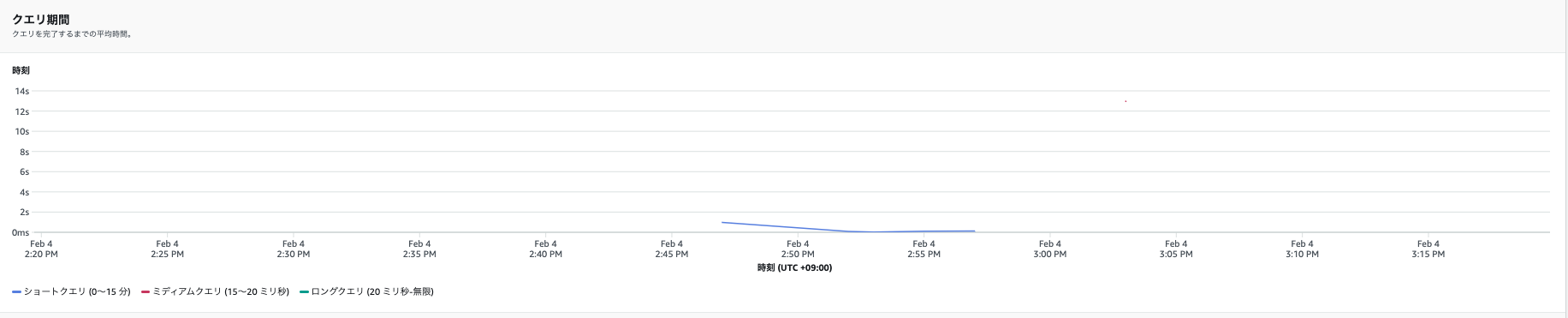
- データベース接続 ※ここでは表示されなかった

- 実行中のクエリ

- キューに入れられたクエリ ※ここでは表示されなかった

- RPU容量

- クエリの内訳 ※ここでは表示されなかった

- 1秒あたりに完了したクエリ
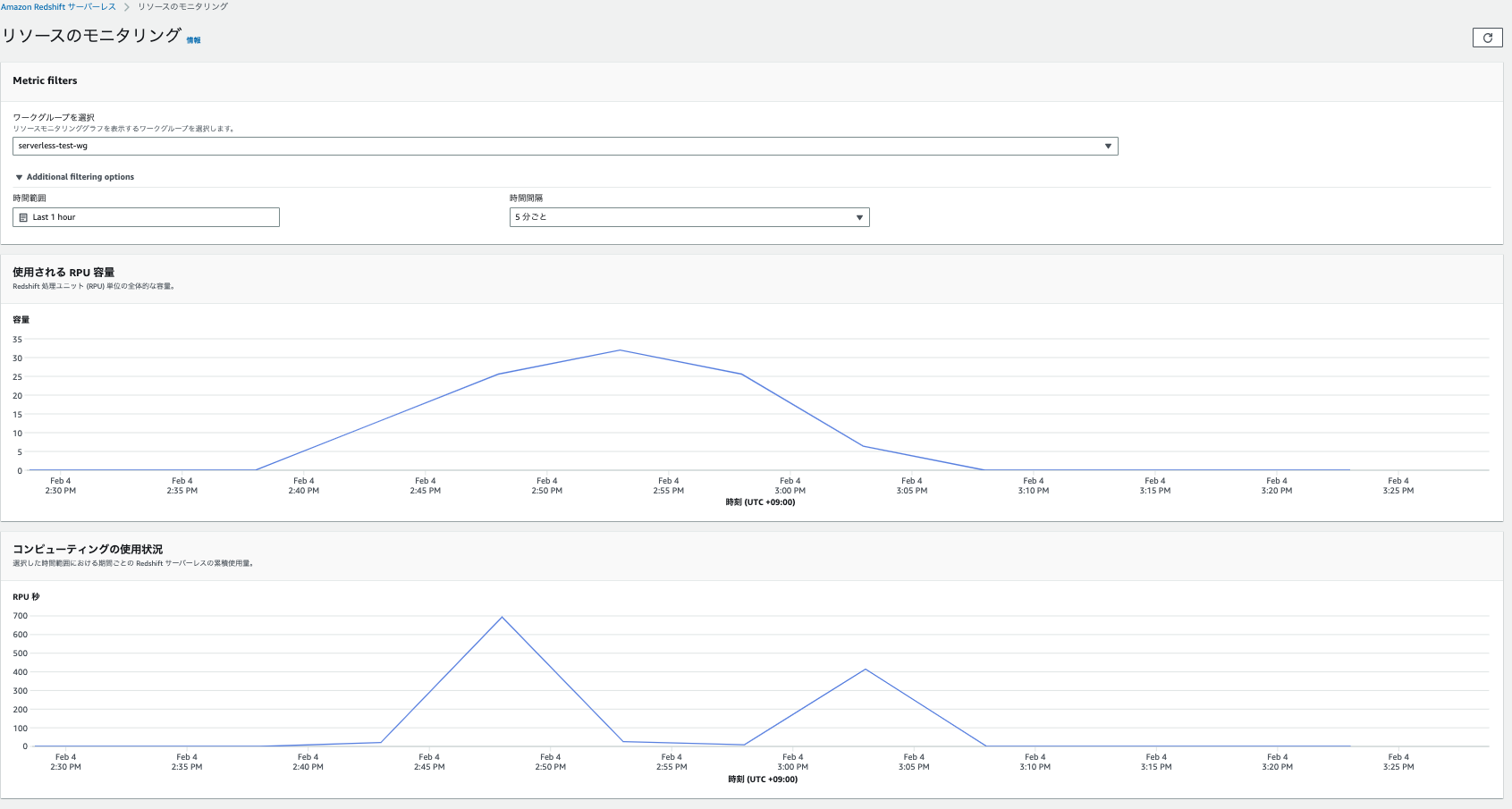
リソースのモニタリング
- ナビゲーションウィンドウの「リソースのモニタリング」をクリックします。
- RPUの容量とコンピューティング使用量状況を、範囲とサマリーする期間を指定して確認することができます。
アラームの設定と確認
-
ナビゲーションウィンドウの「アラーム」をクリックします。

-
「アラームの作成」をクリックします。

-
下記を指定してアラームの作成をクリックします。
- ワークグループ
- メトリクスのアラームに、ComputeCapacityでMinimum
- 1分間で1RPUより大きい場合
- アラーム名
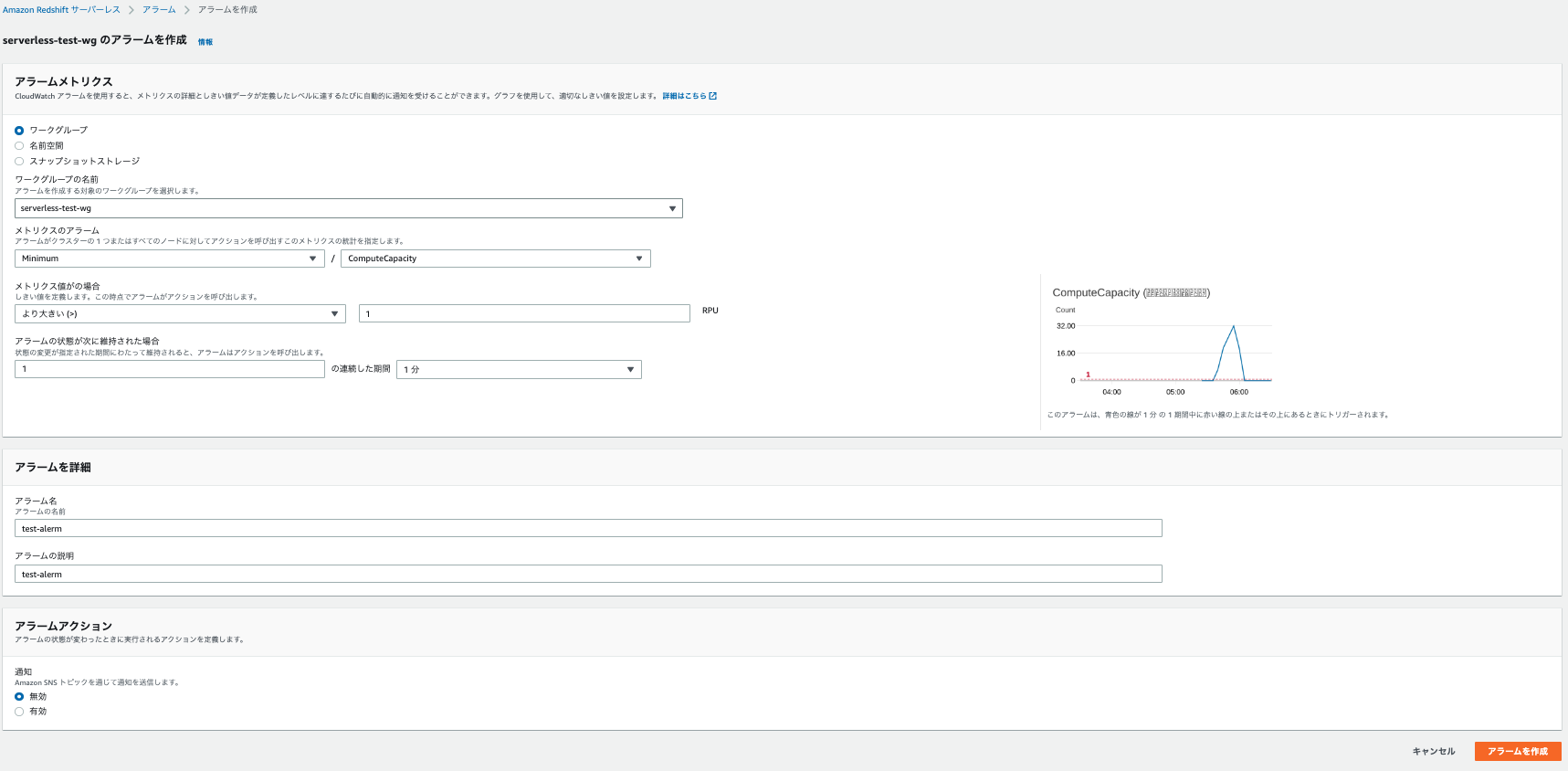
-
上記のクエリを何回か実行します。
-
アラームがでました。状態はALERMになっています。

-
アラーム名をクリックするとプレビューが確認できます。
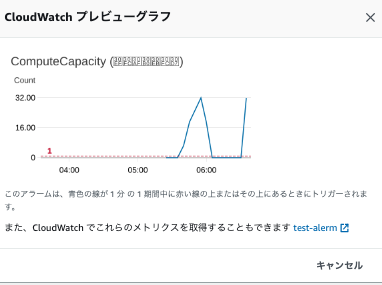
-
リンクをクリックしてCWで確認します。詳細が確認できます。
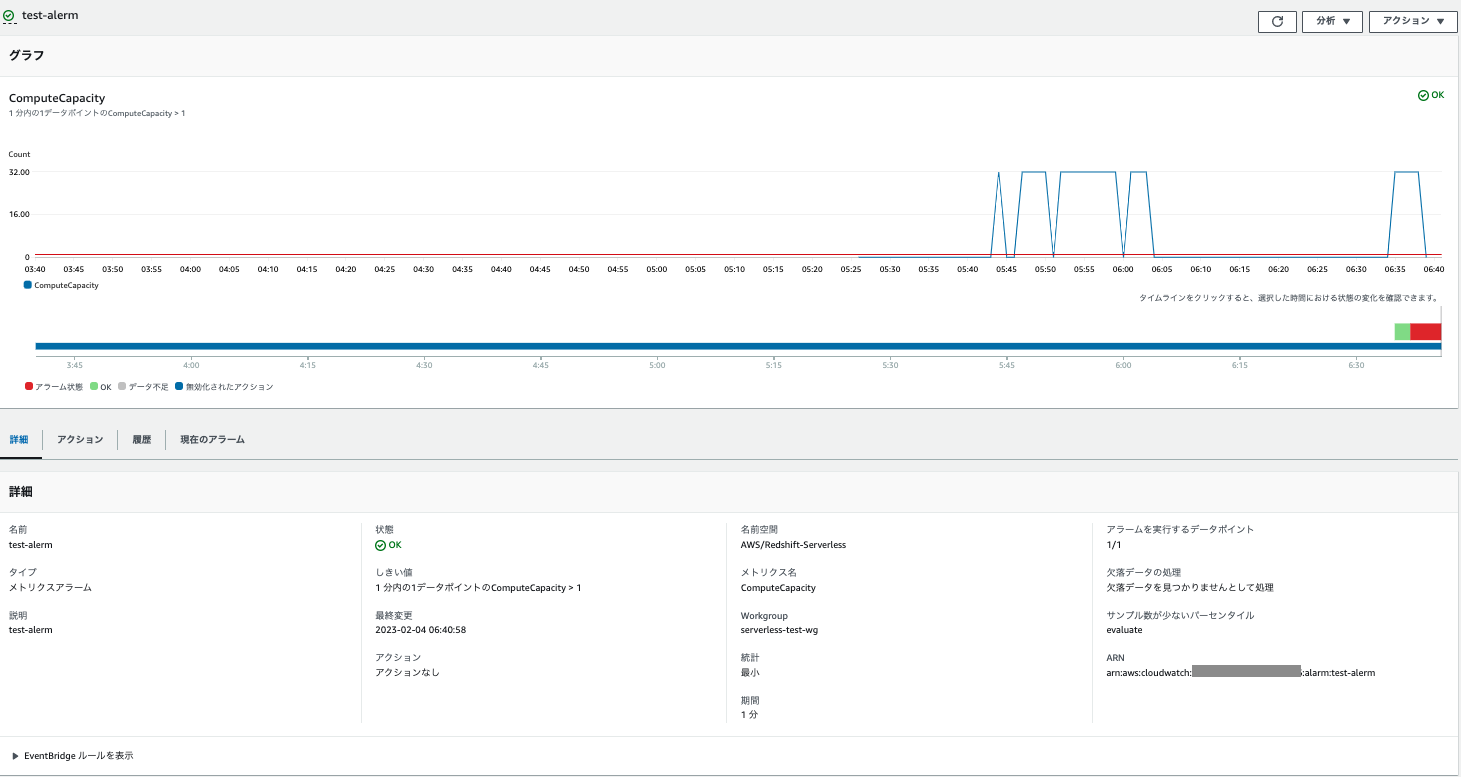
-
履歴をクリックして状態遷移を確認します。

考察
クラスタに作成するインスタンスタイプや数を指定せずに使用できるので、ライトに利用する場合に有効と感じました。
今後は、プロビジョニングクラスタと比較してどのような設定が可能かを確認したいと思います。
参考