背景・目的
AWS Glue Studio visual ETL adds 10 new visual transformsで、Glueで新たに10個のTransformが追加されたので試してみたいと思います。
概要
下記のTransfromが追加になりました。
- Concatenate
- オプションのスペーサーを使用して他の列の値を使用して、新しい文字列列を作成する。
- Split string
- 正規表現を使用して文字列をトークンの配列に分割し、分割方法を定義する。
- Array to columns
- 配列からカラムに変換する。
- Add current timestamp
- データが処理された時間で行をマークする。
- 監査の目的や、データ パイプラインのレイテンシを追跡するのに役立つとのこと。
- Pivot rows to columns
- 新しい列になる選択された列で一意の値を回転させることにより、数値列を集計します。 複数の列が選択されている場合、値が連結されて新しい列の名前が付けられます。
- Unpivot columns to rows
- Pivotの反対。
- Lookup
- キーがデータ内の定義されたルックアップ列と一致する場合に、定義されたカタログテーブルから列を追加できる。
- Explode
- ネストされた構造から、操作しやすい個々の行に値を抽出する。
- Derived column
- データ内の他の列、および定数とリテラルを使用できる数式または SQL 式に基づいて新しい列を定義する。
- Autobalance processing
- ワーカー間でデータをより適切に再配布する。
実践
準備
-
S3バケットを準備します。
-
下記のトランザクションデータを上記で作成したS3バケットに配置します。
{"year":"2023","month":"04","day":"01","id":"1","values":"1,2,3,4,5","array":[1,2,3,4,5],"country":"uk","amount":32,"total":254} {"year":"2023","month":"04","day":"02","id":"2","values":"6,7,8,9,10","array":[6,7,8,9,10],"country":"de","amount":42,"total":254} {"year":"2023","month":"04","day":"03","id":"3","values":"11,12,13,14,15","array":[11,12,13,14,15],"country":"us","amount":64,"total":254} {"year":"2023","month":"04","day":"04","id":"4","values":"16,17,18,19,20","array":[16,17,18,19,20],"country":"uk","amount":67,"total":254} {"year":"2023","month":"04","day":"05","id":"5","values":"21,22,23,24,25","array":[21,22,23,24,25],"country":"de","amount":4,"total":254} {"year":"2023","month":"04","day":"06","id":"6","values":"26,27,28,29,30","array":[26,27,28,29,30],"country":"de","amount":7,"total":254} {"year":"2023","month":"04","day":"07","id":"7","values":"31,32,33,34,35","array":[31,32,33,34,35],"country":"de","amount":6,"total":254} {"year":"2023","month":"04","day":"08","id":"8","values":"36,37,38,39,40","array":[36,37,38,39,40],"country":"de","amount":12,"total":254} {"year":"2023","month":"04","day":"09","id":"9","values":"41,42,43,44,45","array":[41,42,43,44,45],"country":"de","amount":90,"total":254}
-
UnPivot用のデータを上記で作成したS3バケットに配置します。
{"day":"01","de":null,"uk":32,"us":null} {"day":"02","de":42,"uk":null,"us":null} {"day":"03","de":null,"uk":null,"us":64} {"day":"04","de":null,"uk":67,"us":null} {"day":"05","de":4,"uk":null,"us":null} {"day":"06","de":7,"uk":null,"us":null} {"day":"07","de":6,"uk":null,"us":null} {"day":"08","de":12,"uk":null,"us":null} {"day":"09","de":90,"uk":null,"us":null} -
次に、下記のマスタデータを上記で作成したS3バケットに配置します。
{"m_id":"1","name":"goods-1"} {"m_id":"2","name":"goods-2"} {"m_id":"3","name":"goods-3"} {"m_id":"4","name":"goods-4"} {"m_id":"5","name":"goods-5"} {"m_id":"6","name":"goods-6"} {"m_id":"7","name":"goods-7"} {"m_id":"8","name":"goods-8"} {"m_id":"9","name":"goods-9"}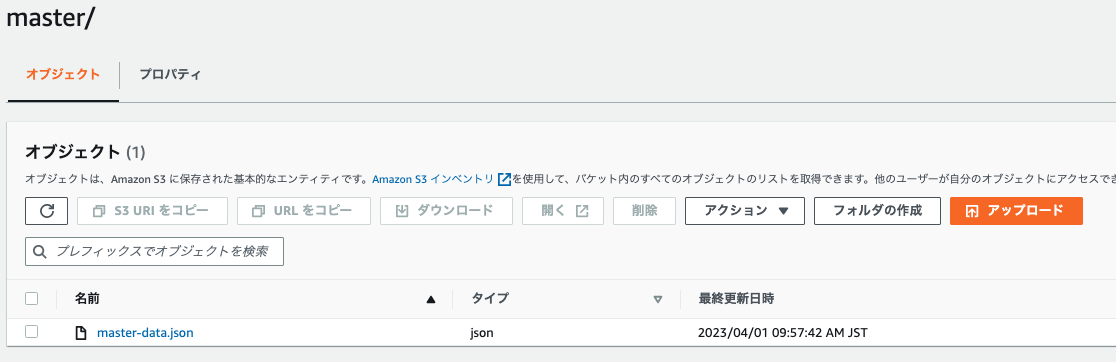
-
マスタデータについては、Lookup機能のためにGlueカタログに登録します。Glueのナビゲーションペインからdatabasesをクリックします。

-
Databasesの「Add database」をクリックします。

-
データベース名を入力し「Create database」をクリックします。(ここでは、transform_test_dbとしました。)

-
次に作成したtransform_test_dbにテーブルを作成します。「Add table」をクリックします。

-
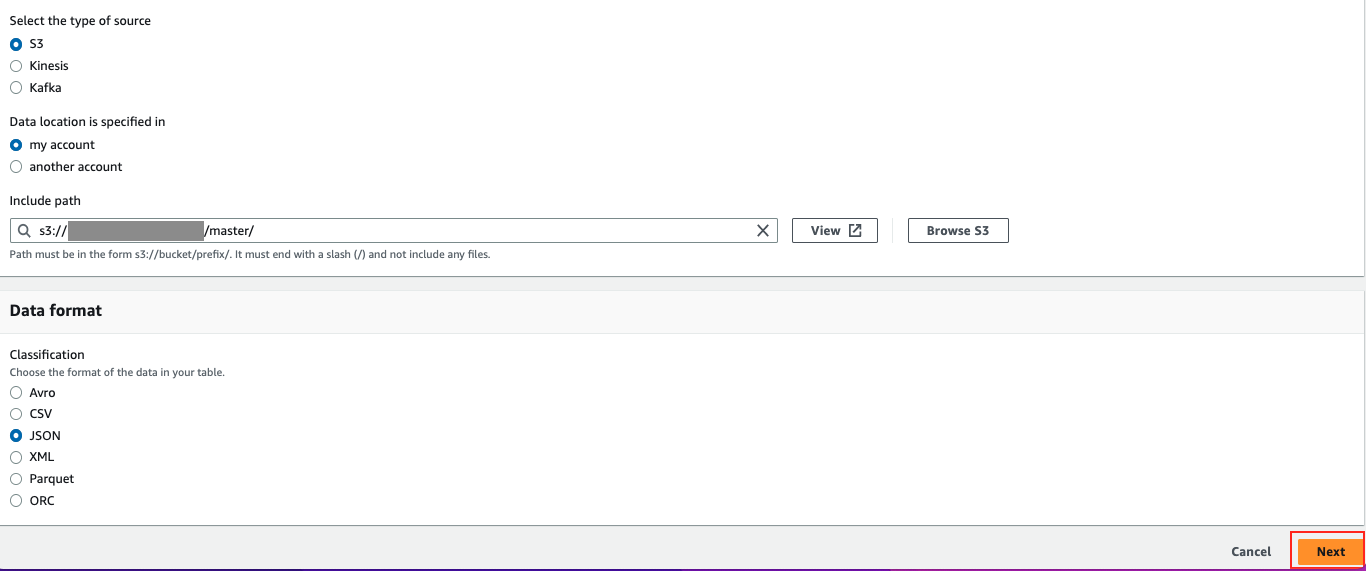
下記を指定して、「Next」をクリックします。
- テーブル名:master_table
- データベース名:transform_test_db
- S3パス:作成したマスタデータが配置されているパス
- データフォーマット:JSON

-
Schemaにカラムを追加し、次にNextをクリックします。

-
Review and Createの画面でCreateをクリックすれば完了です。(キャプチャなし)
-
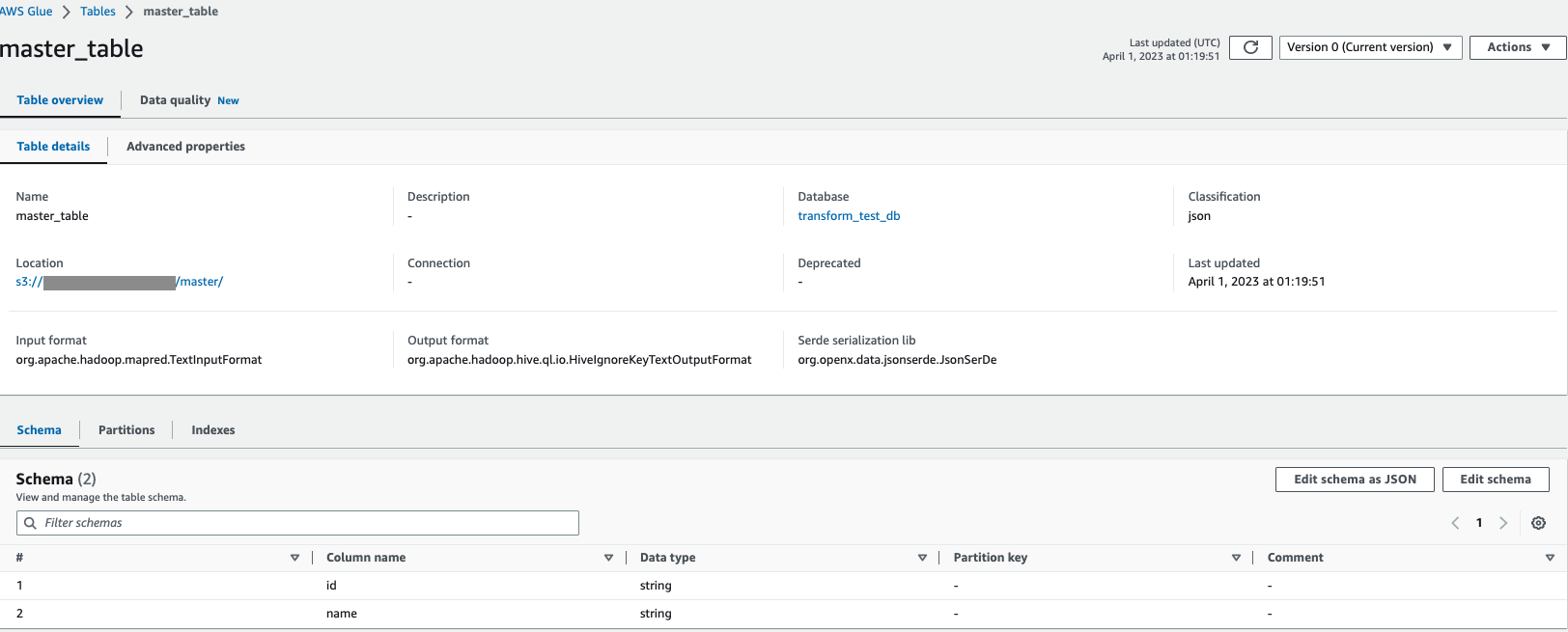
下記のようなテーブルが出来上がりました。
実装
Using the Concatenate Columns transform to append columns
想定結果
下記のような結果になることを期待します。
- インプットデータ
| year | month | day |
|---|---|---|
| 2023 | 04 | 01 |
| 2023 | 04 | 02 |
| 2023 | 04 | 03 |
| 2023 | 04 | 04 |
| 2023 | 04 | 05 |
| 2023 | 04 | 06 |
| 2023 | 04 | 07 |
| 2023 | 04 | 08 |
| 2023 | 04 | 09 |
- アウトプットデータ
| year | month | day | date_column |
|---|---|---|---|
| 2023 | 04 | 01 | 2023-04-01 |
| 2023 | 04 | 02 | 2023-04-02 |
| 2023 | 04 | 03 | 2023-04-03 |
| 2023 | 04 | 04 | 2023-04-04 |
| 2023 | 04 | 05 | 2023-04-05 |
| 2023 | 04 | 06 | 2023-04-06 |
| 2023 | 04 | 07 | 2023-04-07 |
| 2023 | 04 | 08 | 2023-04-08 |
| 2023 | 04 | 09 | 2023-04-09 |
設定
-
TransformでConcatenated columnを選択します。
-
下記のパラメータを設定します。
- Concatenated columnには、新しいdate_columnとして設定します。
- Columnsには、year,month,dayを設定します。
- Spacerには、"-"を設定します。

-
ジョブの終了後、出力結果を確認します。想定通りの結果でした。
$ aws s3 cp s3://{出力バケット名}/concatenate/run-1680323878067-part-r-00000 - | cat {"year":"2023","month":"04","day":"01","date_column":"2023-04-01"} {"year":"2023","month":"04","day":"02","date_column":"2023-04-02"} {"year":"2023","month":"04","day":"03","date_column":"2023-04-03"} {"year":"2023","month":"04","day":"04","date_column":"2023-04-04"} {"year":"2023","month":"04","day":"05","date_column":"2023-04-05"} {"year":"2023","month":"04","day":"06","date_column":"2023-04-06"} {"year":"2023","month":"04","day":"07","date_column":"2023-04-07"} {"year":"2023","month":"04","day":"08","date_column":"2023-04-08"} {"year":"2023","month":"04","day":"09","date_column":"2023-04-09"} $
Using the Split String transform to break up a string column
想定結果
下記のような結果になることを期待します。
- インプットデータ
| id | values |
|---|---|
| 1 | 1,2,3,4,5 |
| 2 | 6,7,8,9,10 |
| 3 | 11,12,13,14,15 |
| 4 | 16,17,18,19,20 |
| 5 | 21,22,23,24,25 |
| 6 | 26,27,28,29,30 |
| 7 | 31,32,33,34,35 |
| 8 | 36,37,38,39,40 |
| 9 | 41,42,43,44,45 |
- アウトプットデータ
| id | values | values_array |
|---|---|---|
| 1 | 1,2,3,4,5 | [1,2,3,4,5] |
| 2 | 6,7,8,9,10 | [6,7,8,9,10] |
| 3 | 11,12,13,14,15 | [11,12,13,14,15] |
| 4 | 16,17,18,19,20 | [16,17,18,19,20] |
| 5 | 21,22,23,24,25 | [21,22,23,24,25] |
| 6 | 26,27,28,29,30 | [26,27,28,29,30] |
| 7 | 31,32,33,34,35 | [31,32,33,34,35] |
| 8 | 36,37,38,39,40 | [36,37,38,39,40] |
| 9 | 41,42,43,44,45 | [41,42,43,44,45] |
設定
- TransformでSplit Stringを選択します。
- 下記のパラメータを設定します。

- ジョブの終了後、出力結果を確認します。想定通りの結果でした。
$ aws s3 cp s3://{出力バケット名}/splitstring/run-1680324727754-part-r-00000 - | cat {"id":"1","values":"1,2,3,4,5","values_array":["1","2","3","4","5"]} {"id":"2","values":"6,7,8,9,10","values_array":["6","7","8","9","10"]} {"id":"3","values":"11,12,13,14,15","values_array":["11","12","13","14","15"]} {"id":"4","values":"16,17,18,19,20","values_array":["16","17","18","19","20"]} {"id":"5","values":"21,22,23,24,25","values_array":["21","22","23","24","25"]} {"id":"6","values":"26,27,28,29,30","values_array":["26","27","28","29","30"]} {"id":"7","values":"31,32,33,34,35","values_array":["31","32","33","34","35"]} {"id":"8","values":"36,37,38,39,40","values_array":["36","37","38","39","40"]} {"id":"9","values":"41,42,43,44,45","values_array":["41","42","43","44","45"]} $
Using the Array To Columns transform to extract the elements of an array into top level columns
想定結果
下記のような結果になることを期待します。
- インプットデータ
| id | array |
|---|---|
| 1 | [1,2,3,4,5] |
| 2 | [6,7,8,9,10] |
| 3 | [11,12,13,14,15] |
| 4 | [16,17,18,19,20] |
| 5 | [21,22,23,24,25] |
| 6 | [26,27,28,29,30] |
| 7 | [31,32,33,34,35] |
| 8 | [36,37,38,39,40] |
| 9 | [41,42,43,44,45] |
- アウトプットデータ
| id | array | column1 | column2 | column3 | column4 | column5 |
|---|---|---|---|---|---|---|
| 1 | [1,2,3,4,5] | 1 | 2 | 3 | 4 | 5 |
| 2 | [6,7,8,9,10] | 6 | 7 | 8 | 9 | 10 |
| 3 | [11,12,13,14,15] | 11 | 12 | 13 | 14 | 15 |
| 4 | [16,17,18,19,20] | 16 | 17 | 18 | 19 | 20 |
| 5 | [21,22,23,24,25] | 21 | 22 | 23 | 24 | 25 |
| 6 | [26,27,28,29,30] | 26 | 27 | 28 | 29 | 30 |
| 7 | [31,32,33,34,35] | 31 | 32 | 33 | 34 | 35 |
| 8 | [36,37,38,39,40] | 36 | 37 | 38 | 39 | 40 |
| 9 | [41,42,43,44,45] | 41 | 42 | 43 | 44 | 45 |
設定
-
Transformで Array to Columnsを選択します。
-
下記のパラメータを設定します。
- Array type column: array
- Output columns:カラム名を設定

-
ジョブの終了後、出力結果を確認します。想定通りの結果でした。
$ aws s3 cp s3://{出力バケット名}/array-to-columns/run-1680325460174-part-r-00000 - | cat {"id":"1","array":[1,2,3,4,5],"column1":1,"column2":2,"column3":3,"column4":4,"column5":5} {"id":"2","array":[6,7,8,9,10],"column1":6,"column2":7,"column3":8,"column4":9,"column5":10} {"id":"3","array":[11,12,13,14,15],"column1":11,"column2":12,"column3":13,"column4":14,"column5":15} {"id":"4","array":[16,17,18,19,20],"column1":16,"column2":17,"column3":18,"column4":19,"column5":20} {"id":"5","array":[21,22,23,24,25],"column1":21,"column2":22,"column3":23,"column4":24,"column5":25} {"id":"6","array":[26,27,28,29,30],"column1":26,"column2":27,"column3":28,"column4":29,"column5":30} {"id":"7","array":[31,32,33,34,35],"column1":31,"column2":32,"column3":33,"column4":34,"column5":35} {"id":"8","array":[36,37,38,39,40],"column1":36,"column2":37,"column3":38,"column4":39,"column5":40} {"id":"9","array":[41,42,43,44,45],"column1":41,"column2":42,"column3":43,"column4":44,"column5":45} $
Using the Add Current Timestamp transform
想定結果
下記のような結果になることを期待します。
- インプットデータ
| id |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
- アウトプットデータ
| id | current_timestamp |
|---|---|
| 1 | 実行時のタイムスタンプ |
| 2 | 実行時のタイムスタンプ |
| 3 | 実行時のタイムスタンプ |
| 4 | 実行時のタイムスタンプ |
| 5 | 実行時のタイムスタンプ |
| 6 | 実行時のタイムスタンプ |
| 7 | 実行時のタイムスタンプ |
| 8 | 実行時のタイムスタンプ |
| 9 | 実行時のタイムスタンプ |
設定
-
Transformで Array to Columnsを選択します。
-
下記のパラメータを設定します。
- Timestamp column: タイムスタンプが入る新しいカラム名
- TImestamp format: タイムスタンプのフォーマット

-
ジョブの終了後、出力結果を確認します。想定通りの結果でした。
$ aws s3 cp s3://{出力バケット名}/current-timestamp/run-1680339840654-part-r-00000 - | cat {"id":"1","current_timestamp":"2023-04-01 09:03:58"} {"id":"2","current_timestamp":"2023-04-01 09:03:58"} {"id":"3","current_timestamp":"2023-04-01 09:03:58"} {"id":"4","current_timestamp":"2023-04-01 09:03:58"} {"id":"5","current_timestamp":"2023-04-01 09:03:58"} {"id":"6","current_timestamp":"2023-04-01 09:03:58"} {"id":"7","current_timestamp":"2023-04-01 09:03:58"} {"id":"8","current_timestamp":"2023-04-01 09:03:58"} {"id":"9","current_timestamp":"2023-04-01 09:03:58"} $
Using the Pivot Rows to Columns transform
想定結果
下記のような結果になることを期待します。
- インプットデータ
| year | month | day | country | amount |
|---|---|---|---|---|
| 2023 | 04 | 01 | uk | 32 |
| 2023 | 04 | 02 | de | 42 |
| 2023 | 04 | 03 | us | 64 |
| 2023 | 04 | 04 | uk | 67 |
| 2023 | 04 | 05 | de | 4 |
| 2023 | 04 | 06 | de | 7 |
| 2023 | 04 | 07 | de | 6 |
| 2023 | 04 | 08 | de | 12 |
| 2023 | 04 | 09 | de | 90 |
- アウトプットデータ
| day | uk | de | us |
|---|---|---|---|
| 01 | 32 | ||
| 02 | 42 | ||
| 03 | 64 | ||
| 04 | 67 | ||
| 05 | 4 | ||
| 06 | 7 | ||
| 07 | 6 | ||
| 08 | 12 | ||
| 09 | 90 |
設定
-
Transformで Array to Columnsを選択します。
-
下記のパラメータを設定します。
- Aggregation column: 対象のカラム
- Aggregation: 集計関数を指定
- Columns to convert: 列方向にPivotするカラム

-
ジョブの終了後、出力結果を確認します。想定通りの結果でした。
$ aws s3 ls s3://{出力バケット名}/pivot/ | grep run-1680341133397 2023-04-01 18:25:35 81 run-1680341133397-part-r-00000 2023-04-01 18:25:35 122 run-1680341133397-part-r-00001 2023-04-01 18:25:35 119 run-1680341133397-part-r-00002 2023-04-01 18:25:35 40 run-1680341133397-part-r-00003 $ for i in `seq 0 3`;do aws s3 cp s3://{出力バケット名}/pivot/run-1680341133397-part-r-0000$i - | cat ;done -- 並び替えています。 {"day":"01","de":null,"uk":32,"us":null} {"day":"02","de":42,"uk":null,"us":null} {"day":"03","de":null,"uk":null,"us":64} {"day":"04","de":null,"uk":67,"us":null} {"day":"05","de":4,"uk":null,"us":null} {"day":"06","de":7,"uk":null,"us":null} {"day":"07","de":6,"uk":null,"us":null} {"day":"08","de":12,"uk":null,"us":null} {"day":"09","de":90,"uk":null,"us":null} $
Using the Unpivot Columns To Rows transform
想定結果
下記のような結果になることを期待します。
- インプットデータ
| day | uk | de | us |
|---|---|---|---|
| 01 | 32 | ||
| 02 | 42 | ||
| 03 | 64 | ||
| 04 | 67 | ||
| 05 | 4 | ||
| 06 | 7 | ||
| 07 | 6 | ||
| 08 | 12 | ||
| 09 | 90 |
- アウトプットデータ
| day | country | amount |
|---|---|---|
| 01 | uk | 32 |
| 02 | de | 42 |
| 03 | us | 64 |
| 04 | uk | 67 |
| 05 | de | 4 |
| 06 | de | 7 |
| 07 | de | 6 |
| 08 | de | 12 |
| 09 | de | 90 |
設定
-
Transformで Unpivot Columns into Rowsを選択します。
-
下記のパラメータを設定します。
- Unpivot names columns:列方向の集計キー
- Unpivot values columns:列方向の集計値
- Columns to unpivot into new value columns:対象とする現在のカラム

-
ジョブの終了後、出力結果を確認します。想定通りの結果でした。
$ aws s3 ls s3://{出力バケット名}/unpivot/ | grep run-1680344166300 2023-04-01 19:16:09 79 run-1680344166300-part-r-00000 2023-04-01 19:16:09 119 run-1680344166300-part-r-00001 2023-04-01 19:16:09 116 run-1680344166300-part-r-00002 2023-04-01 19:16:09 39 run-1680344166300-part-r-00003 $ for i in `seq 0 3`;do aws s3 cp s3://{出力バケット名}/unpivot/run-1680344166300-part-r-0000$i - | cat ; done {"day":"01","country":"uk","amount":32} {"day":"02","country":"de","amount":42} {"day":"03","country":"us","amount":64} {"day":"04","country":"uk","amount":67} {"day":"05","country":"de","amount":4} {"day":"06","country":"de","amount":7} {"day":"07","country":"de","amount":6} {"day":"08","country":"de","amount":12} {"day":"09","country":"de","amount":90} $
Using the Lookup transform to add matching data from a catalog table
lookupがうまく利用できなかったため。一旦飛ばします。
Using the Explode Array or Map Into Rows transform
想定結果
下記のような結果になることを期待します。
- インプットデータ
| id | array |
|---|---|
| 1 | [1,2,3,4,5] |
| 2 | [6,7,8,9,10] |
| 3 | [11,12,13,14,15] |
| 4 | [16,17,18,19,20] |
| 5 | [21,22,23,24,25] |
| 6 | [26,27,28,29,30] |
| 7 | [31,32,33,34,35] |
| 8 | [36,37,38,39,40] |
| 9 | [41,42,43,44,45] |
- アウトプットデータ
| id | element |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 1 | 4 |
| 1 | 5 |
| 2 | 6 |
| 2 | 7 |
| 2 | 8 |
| 2 | 9 |
| 2 | 10 |
| 3 | 11 |
| 3 | 12 |
| 3 | 13 |
| 3 | 14 |
| 3 | 15 |
| 4 | 16 |
| 4 | 17 |
| 4 | 18 |
| 4 | 19 |
| 4 | 20 |
| 5 | 21 |
| 5 | 22 |
| 5 | 23 |
| 5 | 24 |
| 5 | 25 |
| 6 | 26 |
| 6 | 27 |
| 6 | 28 |
| 6 | 29 |
| 6 | 30 |
| 7 | 31 |
| 7 | 32 |
| 7 | 33 |
| 7 | 34 |
| 7 | 35 |
| 8 | 36 |
| 8 | 37 |
| 8 | 38 |
| 8 | 39 |
| 8 | 40 |
| 9 | 41 |
| 9 | 42 |
| 9 | 43 |
| 9 | 44 |
| 9 | 45 |
設定
-
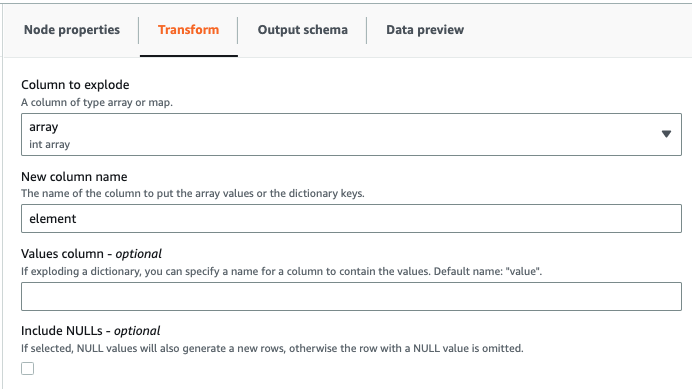
Transformで Explode Array or Map Into Rows を選択します。
-
下記のパラメータを設定します。
- Column to explode:配列が含まれる旧カラム名
- New column name:新しいカラム名
-
ジョブの終了後、出力結果を確認します。想定通りの結果でした。
$ aws s3 cp s3://{出力バケット名}/explode/run-1680354171584-part-r-00000 - | cat {"id":"1","new_array":1} {"id":"1","new_array":2} {"id":"1","new_array":3} {"id":"1","new_array":4} {"id":"1","new_array":5} {"id":"2","new_array":6} {"id":"2","new_array":7} {"id":"2","new_array":8} {"id":"2","new_array":9} {"id":"2","new_array":10} {"id":"3","new_array":11} {"id":"3","new_array":12} {"id":"3","new_array":13} {"id":"3","new_array":14} {"id":"3","new_array":15} {"id":"4","new_array":16} {"id":"4","new_array":17} {"id":"4","new_array":18} {"id":"4","new_array":19} {"id":"4","new_array":20} {"id":"5","new_array":21} {"id":"5","new_array":22} {"id":"5","new_array":23} {"id":"5","new_array":24} {"id":"5","new_array":25} {"id":"6","new_array":26} {"id":"6","new_array":27} {"id":"6","new_array":28} {"id":"6","new_array":29} {"id":"6","new_array":30} {"id":"7","new_array":31} {"id":"7","new_array":32} {"id":"7","new_array":33} {"id":"7","new_array":34} {"id":"7","new_array":35} {"id":"8","new_array":36} {"id":"8","new_array":37} {"id":"8","new_array":38} {"id":"8","new_array":39} {"id":"8","new_array":40} {"id":"9","new_array":41} {"id":"9","new_array":42} {"id":"9","new_array":43} {"id":"9","new_array":44} {"id":"9","new_array":45} $
Using the Derived Column transform to combine other columns
想定結果
下記のような結果になることを期待します。
- インプットデータ
| id | amount |
|---|---|
| 1 | 32 |
| 2 | 42 |
| 3 | 64 |
| 4 | 67 |
| 5 | 4 |
| 6 | 7 |
| 7 | 6 |
| 8 | 12 |
| 9 | 90 |
- アウトプットデータ
| id | amount | total | percentage |
|---|---|---|---|
| 1 | 32 | 254 | 12.5984251968504% |
| 2 | 42 | 254 | 16.53543307086614% |
| 3 | 64 | 254 | 25.19685039370079% |
| 4 | 67 | 254 | 26.37795275590551% |
| 5 | 4 | 254 | 1.5748031496062993% |
| 6 | 7 | 254 | 2.7559055118110236% |
| 7 | 6 | 254 | 2.3622047244094486% |
| 8 | 12 | 254 | 4.724409448818897% |
| 9 | 90 | 254 | 35.43307086614173% |
設定
-
Transformで Derived Column を選択します。
-
下記のパラメータを設定します。
- Name of the deriverd column:新しいカラム名
- SQL Expression:計算式

-
ジョブの終了後、出力結果を確認します。想定通りの結果でした。
$ aws s3 cp s3://{出力バケット名}/derived/run-1680356577677-part-r-00000 - | cat {"id":"1","amount":32,"total":254,"percent":"12.598425196850394%"} {"id":"2","amount":42,"total":254,"percent":"16.53543307086614%"} {"id":"3","amount":64,"total":254,"percent":"25.19685039370079%"} {"id":"4","amount":67,"total":254,"percent":"26.37795275590551%"} {"id":"5","amount":4,"total":254,"percent":"1.5748031496062993%"} {"id":"6","amount":7,"total":254,"percent":"2.7559055118110236%"} {"id":"7","amount":6,"total":254,"percent":"2.3622047244094486%"} {"id":"8","amount":12,"total":254,"percent":"4.724409448818897%"} {"id":"9","amount":90,"total":254,"percent":"35.43307086614173%"} $
Using the Autobalance Processing transform to optimize your runtime
想定結果
下記のような結果になることを期待します。
- インプットデータ
| id | values |
|---|---|
| 1 | 1,2,3,4,5 |
| 2 | 6,7,8,9,10 |
| 3 | 11,12,13,14,15 |
| 4 | 16,17,18,19,20 |
| 5 | 21,22,23,24,25 |
| 6 | 26,27,28,29,30 |
| 7 | 31,32,33,34,35 |
| 8 | 36,37,38,39,40 |
| 9 | 41,42,43,44,45 |
- アウトプットデータ
- 上記のデータを5分割します。
設定
-
Transformで Autobalance Processing を選択します。
-
下記のパラメータを設定します。
- Number of partitions: Repartitionの数
- Repartition columns:Repartitionのキー

-
ジョブの終了後、出力結果を確認します。想定通りの結果でした。(ファイルの一つは0バイトでした。)
$ aws s3 ls s3://{出力バケット名}/autobalance-processing/ 2023-04-01 22:50:22 36 run-1680357021481-part-r-00000 2023-04-01 22:50:22 73 run-1680357021481-part-r-00001 2023-04-01 22:50:23 0 run-1680357021481-part-r-00002 2023-04-01 22:50:22 73 run-1680357021481-part-r-00003 2023-04-01 22:50:22 138 run-1680357021481-part-r-00004 $ $ for i in `seq 0 4`;do fn=`echo run-1680357021481-part-r-0000$i`;echo $fn; aws s3 cp s3://{出力バケット名}/autobalance-processing/$fn - | cat ;done run-1680357021481-part-r-00000 {"id":"6","values":"26,27,28,29,30"} run-1680357021481-part-r-00001 {"id":"4","values":"16,17,18,19,20"} {"id":"8","values":"36,37,38,39,40"} run-1680357021481-part-r-00002 run-1680357021481-part-r-00003 {"id":"3","values":"11,12,13,14,15"} {"id":"7","values":"31,32,33,34,35"} run-1680357021481-part-r-00004 {"id":"1","values":"1,2,3,4,5"} {"id":"2","values":"6,7,8,9,10"} {"id":"5","values":"21,22,23,24,25"} {"id":"9","values":"41,42,43,44,45"}$
考察
今回、GlueのTransformが複数追加されました。explodeやAutobalance Processing(repartition)などはよく利用するので便利になりました。
参考