背景・目的
データマネジメントのデータ品質管理を調べていた際、データプロファイリングツールについて気になりました。
データプロファイリングツールの候補として、AWS Glue DataBrew(移行、DataBrewと書きます。)について整理および動作確認を行います。
まとめ
- TB単位のRawデータに対して、コードを書かずにデータのプロファイリングや変換、正規化が可能
- サーバの管理が不要
概要
こちらのドキュメントを元に整理します。
What is AWS Glue DataBrew?
下記の特徴があります。
- ユーザがコードを書かずにデータをクリーンアップ、および正規化できるようにする視覚的なデータプリパレーションツール
- 分析や機械学習用のデータを準備する時間を最大80%削減できる
- 250を超える、既成の変換から選択して下記のようなデータ準備タスクを自動化できるとのことです。
- 異常のフィルタリング
- データの標準形式への変換
- 無効な値の修正
- ビジネスアナリスト、データサイエンティスト、データエンジニアがより簡単に共同作業し、Rawデータからインサイトを得られる
- サーバレス
- TB単位のRawデータを探索、変換可能
- 直感的なI/Fを使って対話的に検出、視覚化、クリーンアップ、変換が可能
- データ品質の問題を特定するための提案を行う
- 変換をレシピのステップとして保存し、後で更新、他のデータセットで再利用、継続的にデプロイが可能
Core concepts and terms in AWS Glue DataBrew
DataBrewの概念と用語の概念を記載します。
| 用語 | 概要 |
|---|---|
| Project | DataBrew の対話型データ準備ワークスペースを指します。 下記のような関連項目をコレクションとして管理します。 ・データ ・変換 ・スケジュール |
| Dataset | 列またはフィールドに分割された行またはレコードを意味します。 DataBrew プロジェクトを作成するときは、変換または準備するデータに接続するか、データをアップロードします。 DataBrew の場合、データセットはデータへの読み取り専用接続です。 DataBrew では実際のデータを変更したり保存したりすることはできません。 |
| Recipe | レシピとは、DataBrew に作用させるデータの一連の命令またはステップです。 レシピには多くのステップを含めることができ、各ステップには多くのアクションを含めることができます。 、データに加えるすべての変更を設定します。 後で、レシピの完成品を確認する準備ができたら、このジョブを DataBrew に割り当て、スケジュールできます。 レシピをダウンロードして、他のプロジェクトで再利用できます。 レシピの複数のバージョンを公開することもできます。 |
| Job | 、レシピの作成時に設定した命令を実行することにより、データを変換する仕事を引き受けます。これらの命令を実行するプロセスはジョブと呼ばれます。 ジョブは、事前に設定されたスケジュールに従ってデータ レシピを実行できます。 スケジュールも、オンデマンドでも実行できます。 |
| Data lineage | ビジュアルインターフェイスで、このビューでは、データが元の場所からさまざまなエンティティをどのように流れるかを示します。 その起源、影響を受けた他のエンティティ、時間の経過とともに何が起こったのか、どこに保管されていたのかを確認できます。 |
| Data profile | データをプロファイリングすると、DataBrew はデータ プロファイルと呼ばれるレポートを作成します。 |
Product and service integrations
DataBrew は、ネットワーキング、管理、ガバナンスのために次の AWS サービスと連携します。
- Amazon CloudFront
- AWS CloudFormation
- AWS CloudTrail
- Amazon CloudWatch
- AWS Step Functions
DataBrew は、次の AWS データレイクおよびデータ ストアと連携します。
- AWS Lake Formation
- Amazon S3
DataBrew は、データをアップロードするために次のファイル形式と拡張子をサポートしています。
- CSV
- Excel
- JSON
- ORC
- Parquet
DataBrew は出力ファイルを Amazon S3 に書き込み、次のファイル形式と拡張子をサポートします。
- CSV
- Parquet
- Glue Parquet
- Avro
- ORC
- XML
- JSON
- Tableau Hyper
実践
Getting started with AWS Glue DataBrewを元に動作を確認してみます。
Prerequisites
- IAMロールを作成し、AWSGlueDataBrewFullAccessPolicyをアタッチしました。
Step 1: Create a project
-
DataBrewのトップページで「プロジェクトを作成」をクリックします。

-
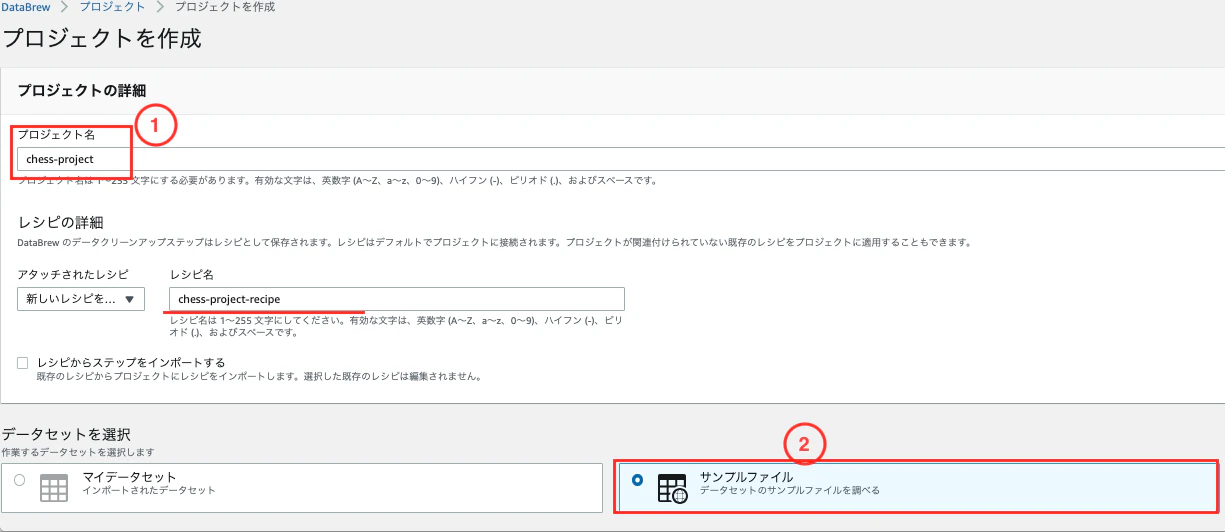
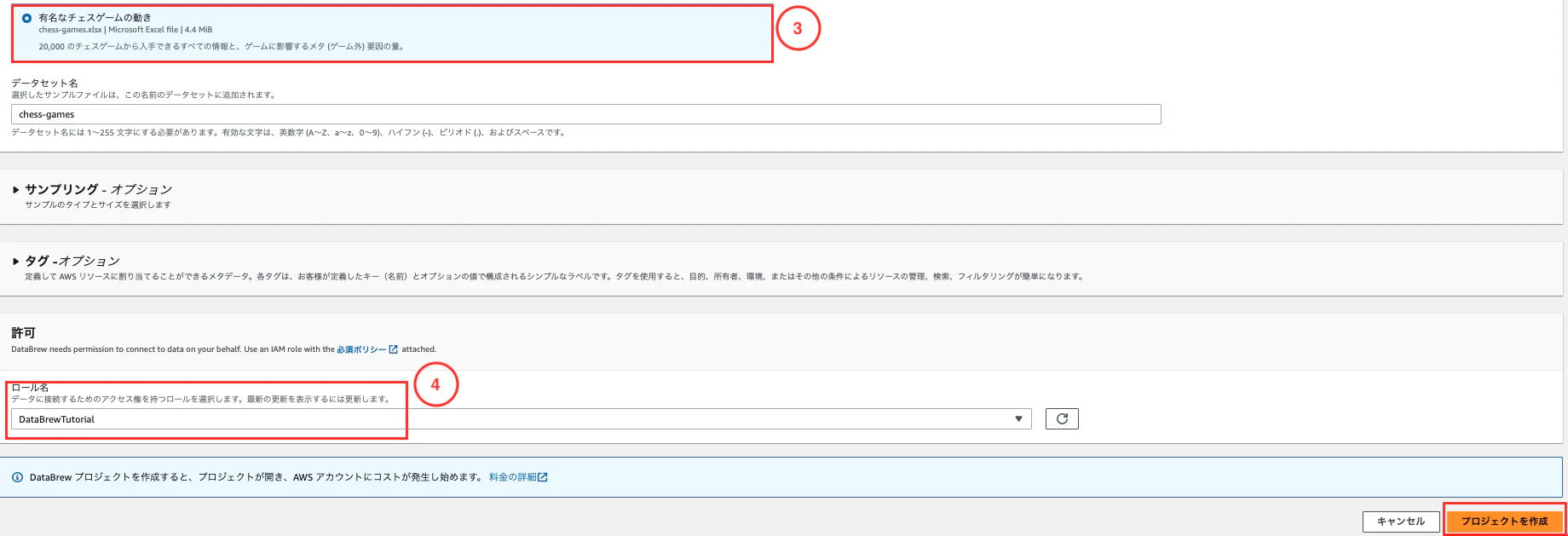
下記を入力し、「プロジェクトを作成」をクリックします。
- プロジェクト名に「chess-project」を入力
- データセットの選択ペインで「サンプルファイル」を選択
- 有名なチェスゲームの動きを選択
- ロール名に作成したIAMロールを選択
-
プロビジョニングが開始されます。
-
しばらくすると作成されます。デフォルトでは最初の500行で構成されます。
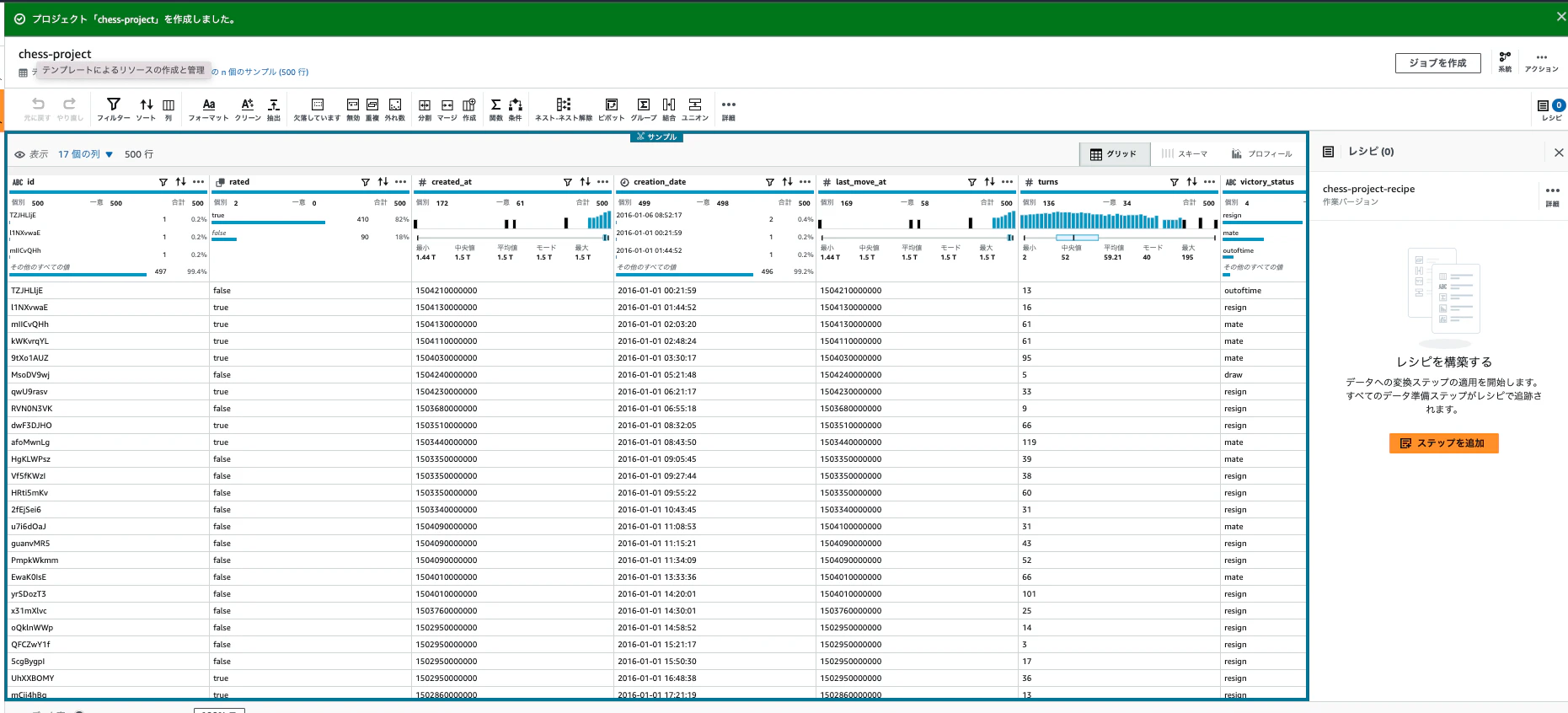
Step 2: Summarize the data
-
変換ツールバーで、「フィルター」、「条件別」、「以上」を選択します。
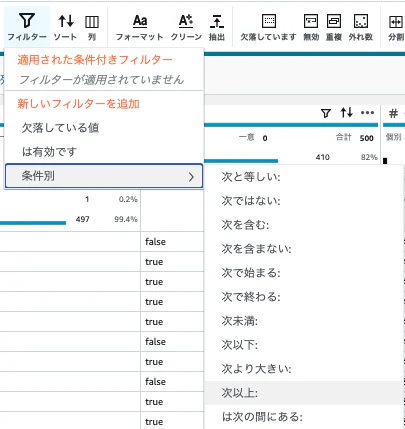
-
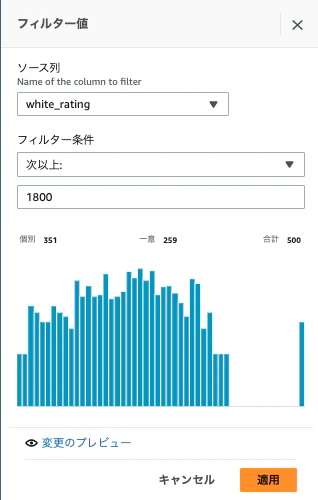
下記を設定し、「適用」をクリックします。データは66行に絞られました。
- ソース列-white_rating
- フィルタ条件-1800以上

-
次に、データをサマリします。グループをクリックします。

-
グループのプロパティにて、下記を設定すると、プレビューが表示されます。確認後、「終了」をクリックします。
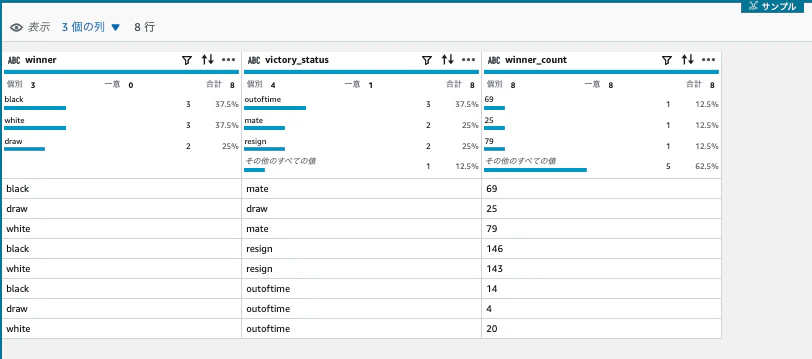
- 最初の行で、winnerでグループ化
- 2行目で、victory_statusでグループ化
- 3行目で、wineerで、集計をカウント
- グループタイプでは、「新しいテーブルとしてグループ」を選択します。
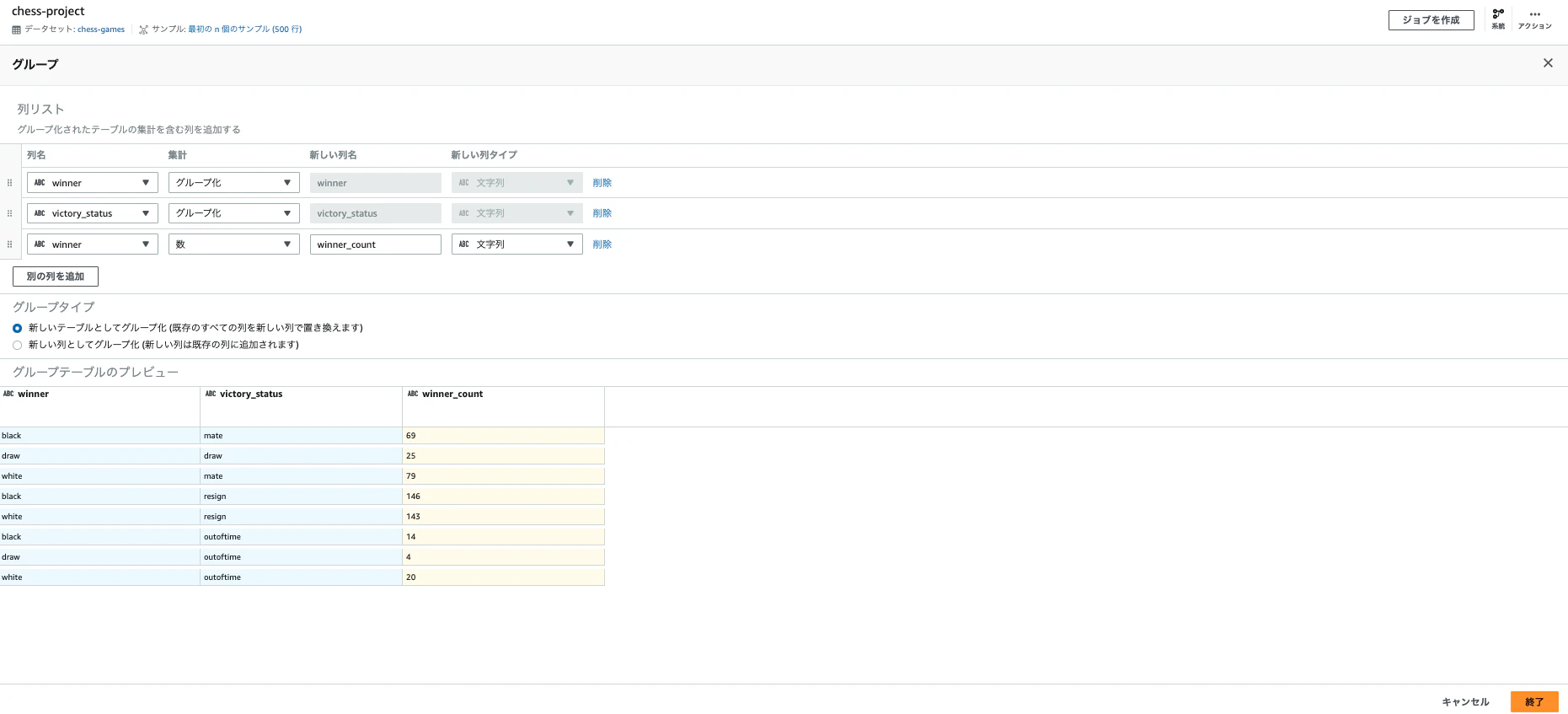
-
8行に絞り込まれました。
Step 3: Add more transformations
このステップでは、レシピにさらに変換を追加し、その別のバージョンを公開します。
-
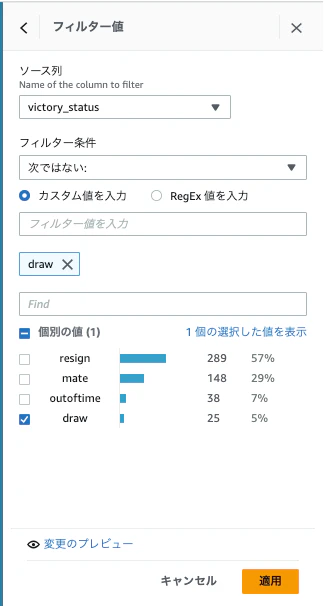
下記を設定し、「適用」をクリックします。
- victory_status
- フィルタ条件:Is not
- 値:draw
-
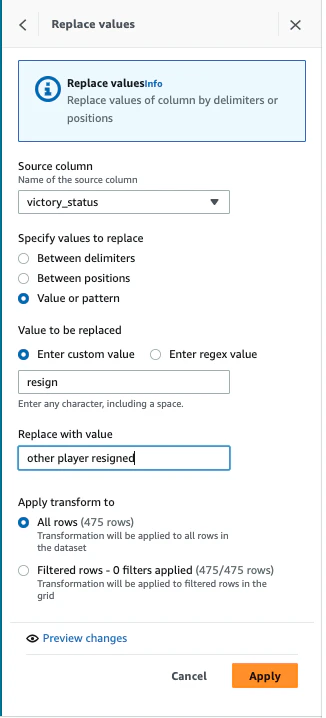
ここから、victory_statusを変更します。変換ツールバーで、消去>置換>値またはパターンを置換を選択します。

-
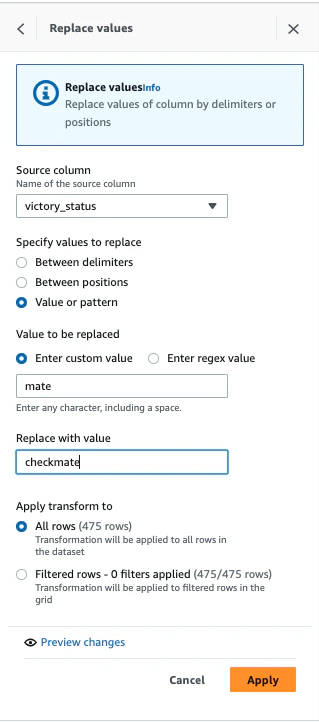
下記を入力し、Applyをクリックします。
- Source column:victory_status
- Specify values to replace:Valye or pattern
- Enter custom value: mate
- Replace with value: checkmate
- Apply transform to:All rows
-
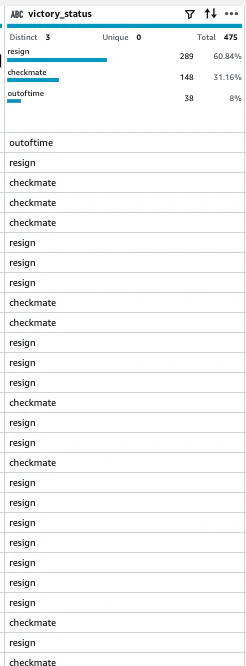
victory_statusが「checkmate」に変わりました。
-
同様に、victoryを「resign」を「other player resigned」に変換します。
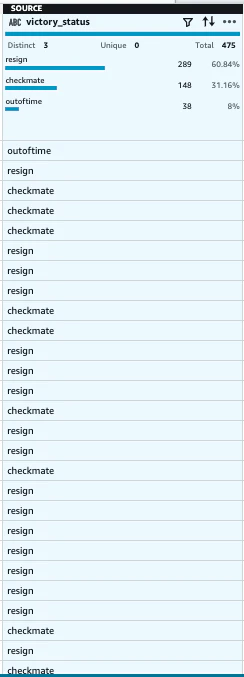
-
変更されました。
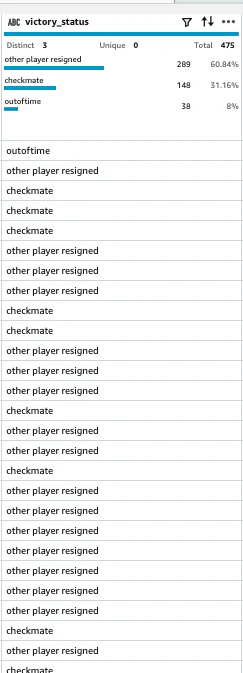
-
同様にvictoryの「outoftime」を「time ran out」に変換します。
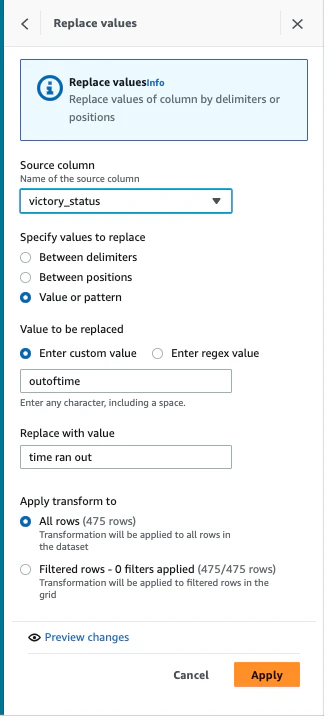
-
最後に、レシピペイン右側にある「公開」を選択して作業内容を保存します。
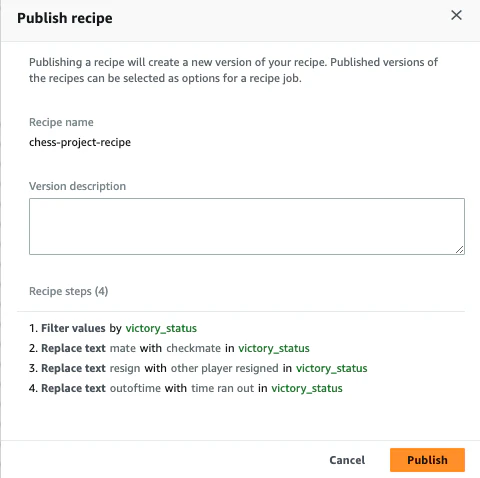
Step 4: Review your DataBrew resources
サンプル プロジェクトを操作したので、これまでに作成した DataBrew リソースを確認します。
-
ナビゲーションペインで「データセット」をクリックします。データセットが確認できました。

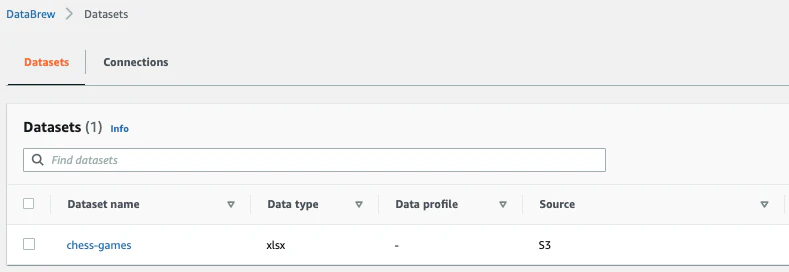
-
ナビゲーションペインで「Project」をクリックします。プロジェクトが確認できました。

-
ナビゲーションペインで「Recipe」をクリックします。先程Publish したRecipeが確認できました。
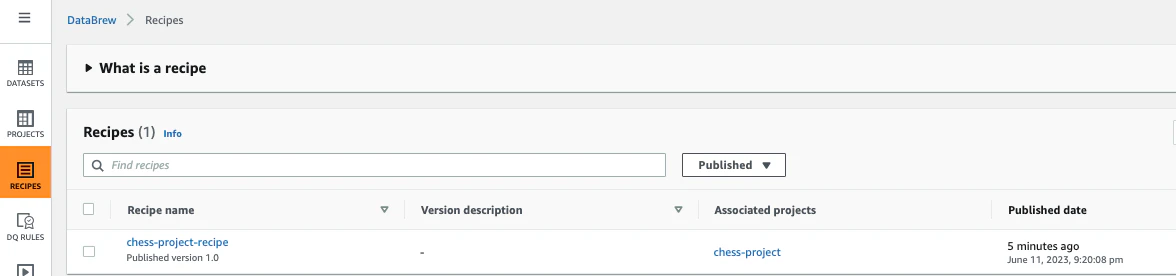
-
recipe名をクリックすると、先程変更した内容が確認できます。
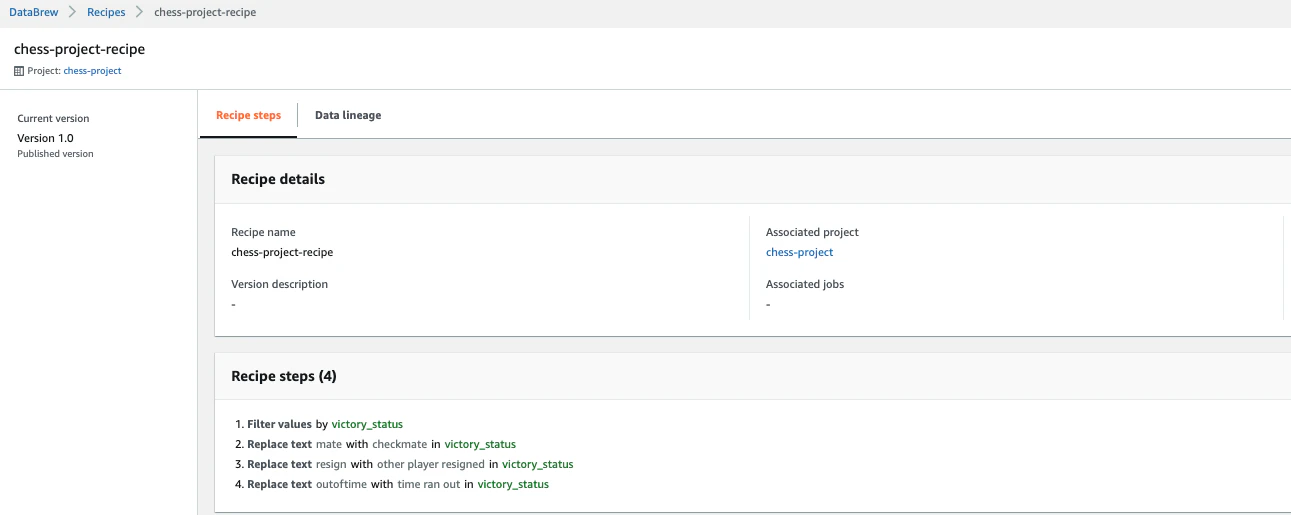
-
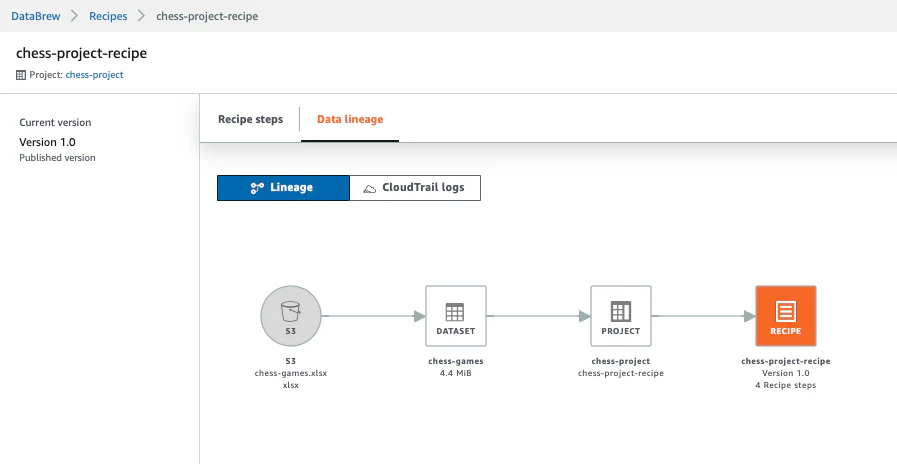
Data linageタブをクリックすると、データの変遷が確認できます。(S3→Dataset→Project→Recipe)
Step 5: Create a data profile
プロジェクトで作業する場合、DataBrew はサンプル内の行数や各列の一意の値の分布などの統計を表示します。 これらの統計やその他多くの統計は、サンプルのプロファイルで確認できます。
データ プロファイルをリクエストするには、プロファイル ジョブを作成して実行します。
-
ナビゲーションペインの「jobs」をクリックします。
-
Create jobをクリックします。
-
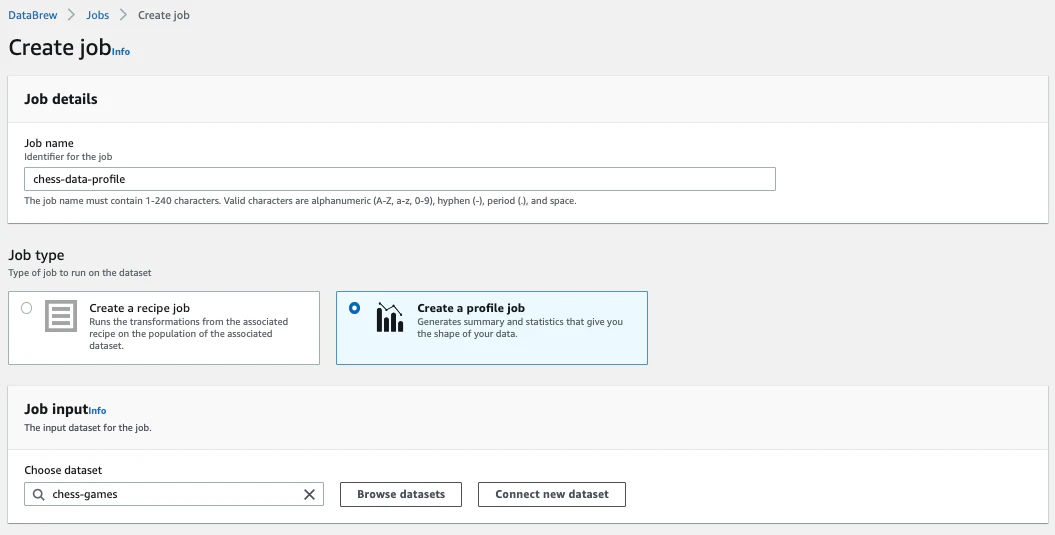
下記を設定し、「Create and run job」をクリックします。
- ジョブ名に、chess-data-profile
- ジョブタイプで Create a profile job
- データセット名で、chess-games
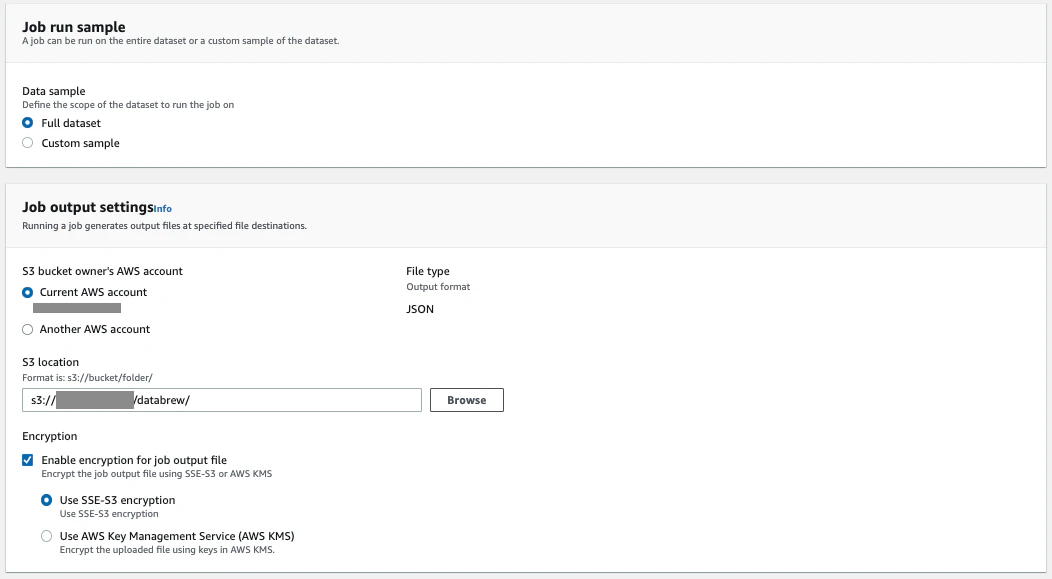
- job run sampleではFull charset
- Job output settingsでは、S3バケットを設定
- Permissionsでは、作成したIAMロールを設定

-
実行後のStatusは、Runningになります。Succeededになるまで待ちます。
-
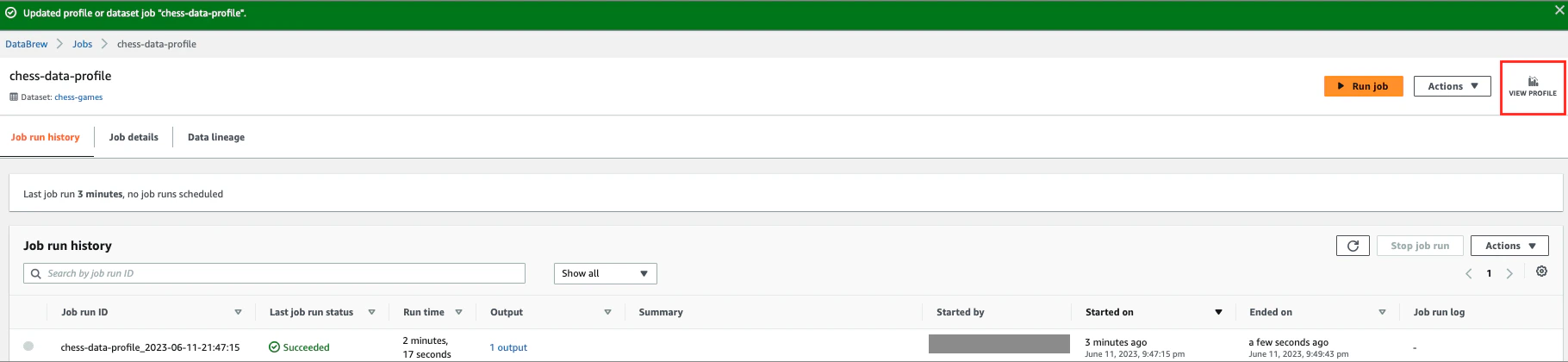
Succeededになったので、VIEW PROFILEをクリックします。
-
Data profile previewでプロファイルを確認できます。
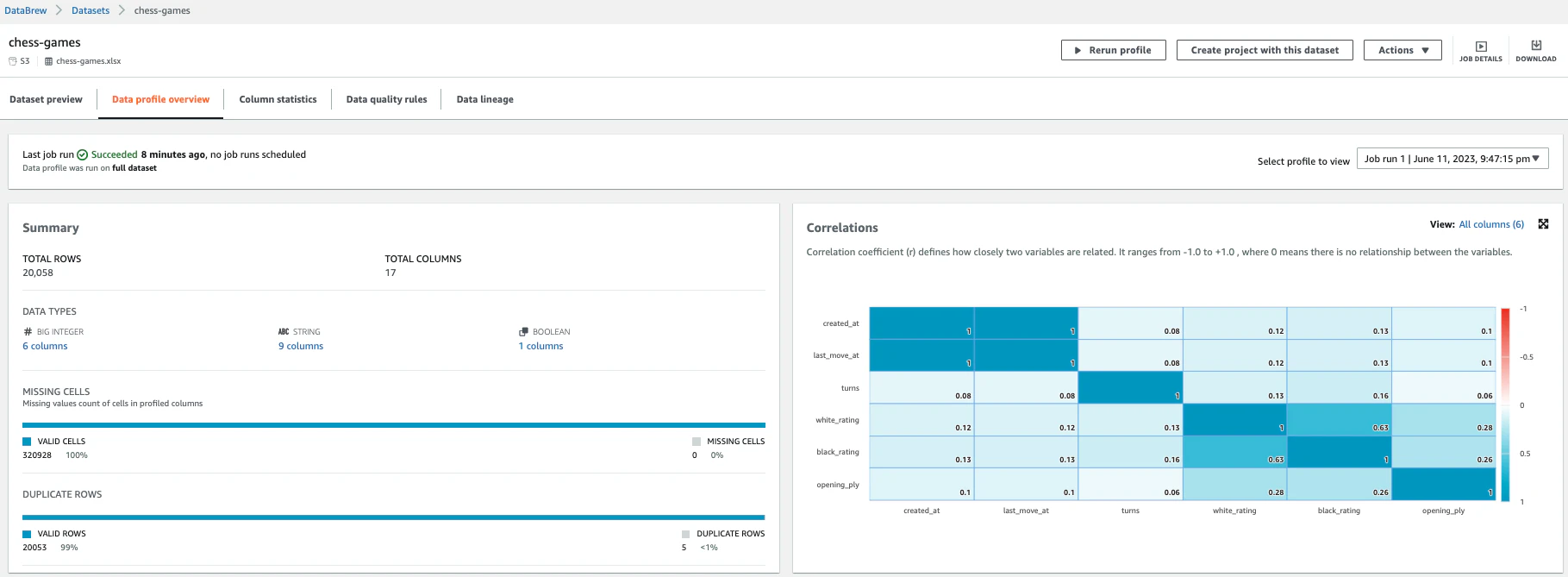
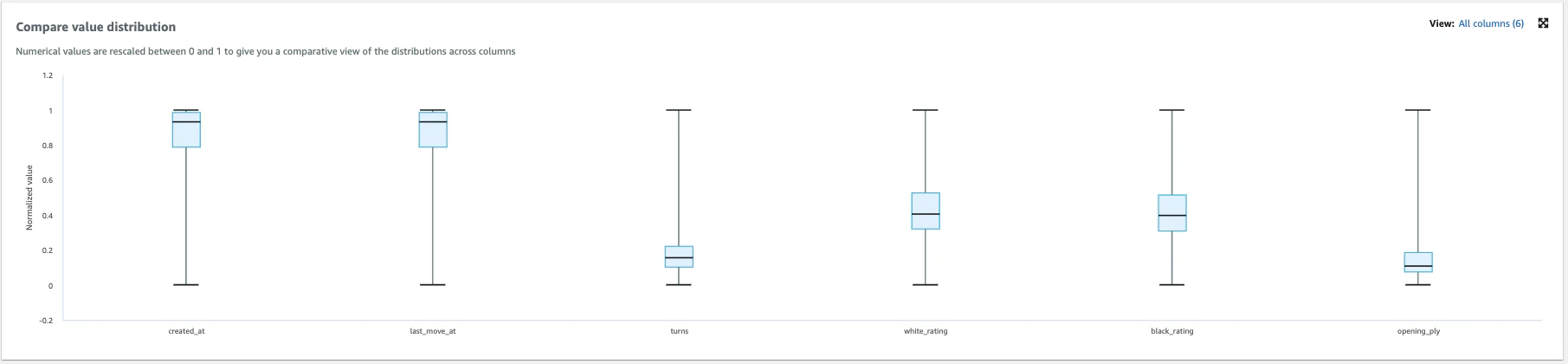
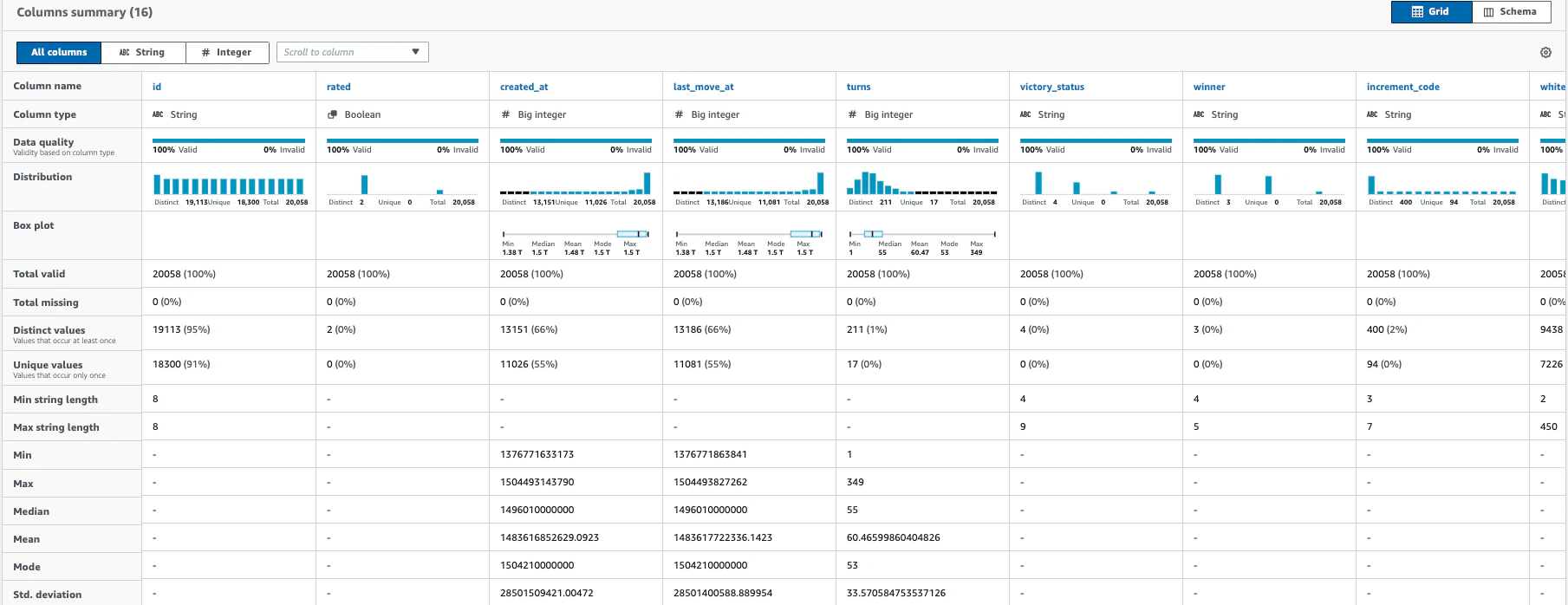

-
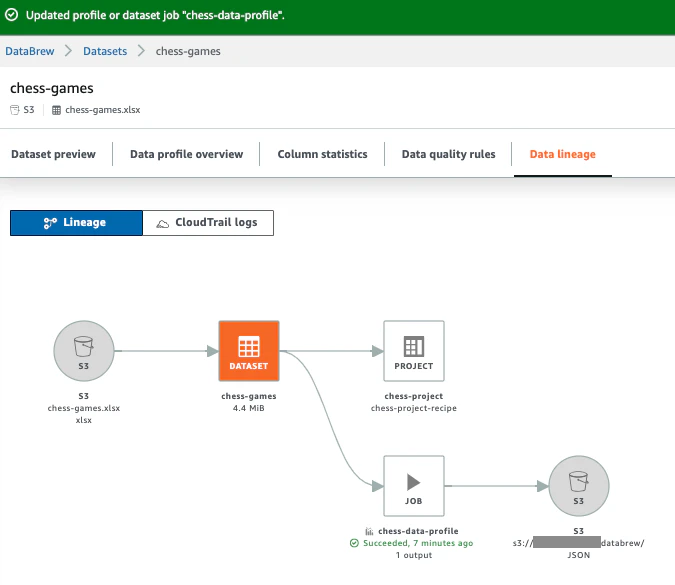
Data linageタブをクリックすると、プロファイルのジョブと出力されたProfileが確認できます。
Step 6: Transform the dataset
DataBrew レシピ ジョブを作成してデータセット全体を変換します。
ジョブが実行されると、DataBrew はレシピをデータセット内のすべてのデータに適用し、変換されたデータを Amazon S3 バケットに書き込みます。 変換されたデータは、元のデータセットから分離されます。 DataBrew はソース データを変更しません。
-
ナビゲーションペインで「JOBS」をクリックし、「Create Job」をクリックします。
-
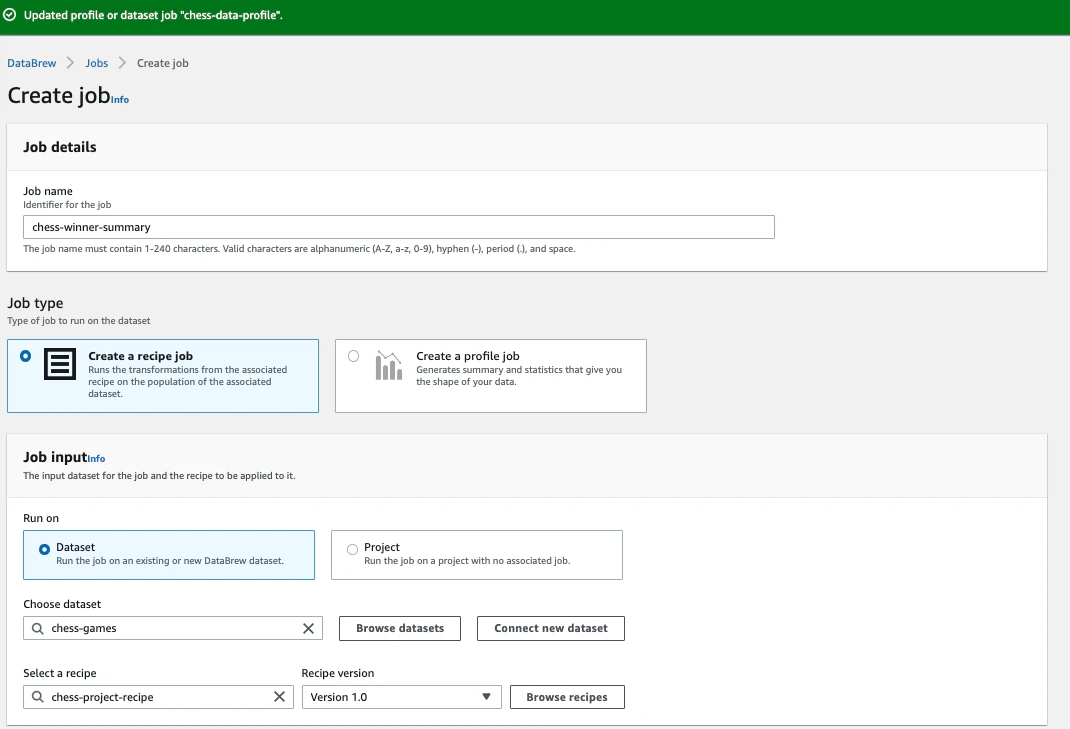
下記を設定し、「Cerate and run job」をクリックします。
- job name:chess-winner-summary
- job type: Create a recipe job
- Job Input: dataset、chess-games、chess-project-recipe
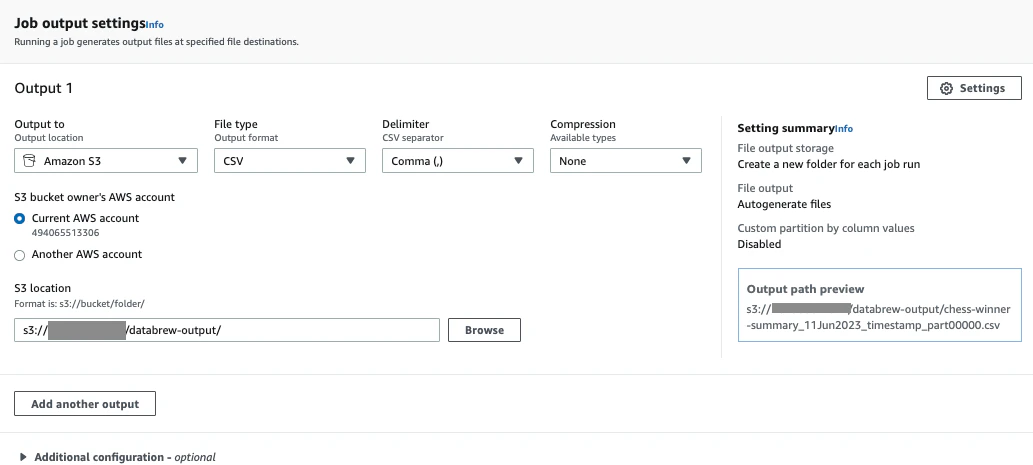
- Job output settings : S3のパス
- Permissions :作成したIAMロール

-
完了しました。
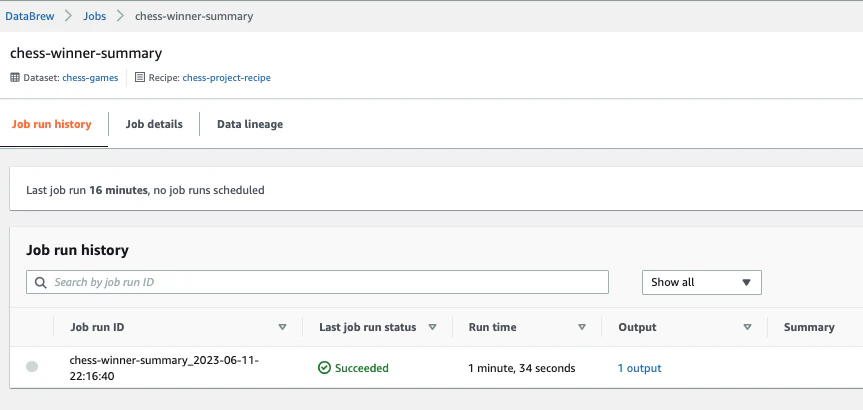
-
Data linageタブをクリックすると、S3に出力されている事がわかります。
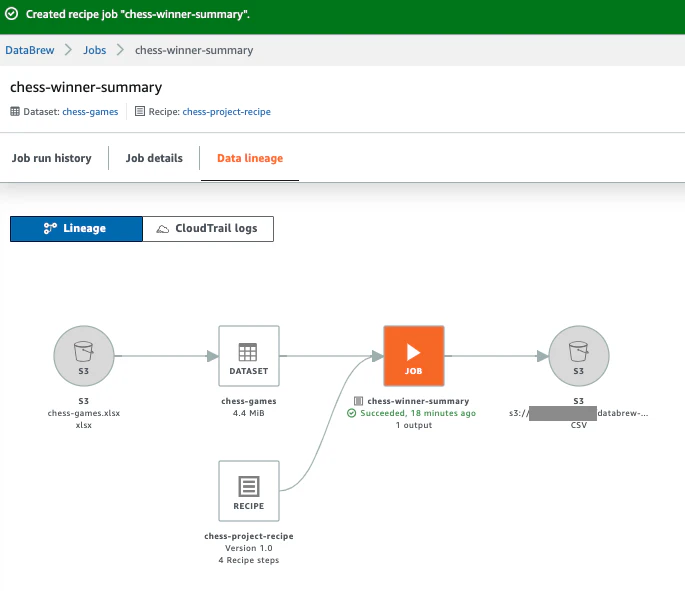
-
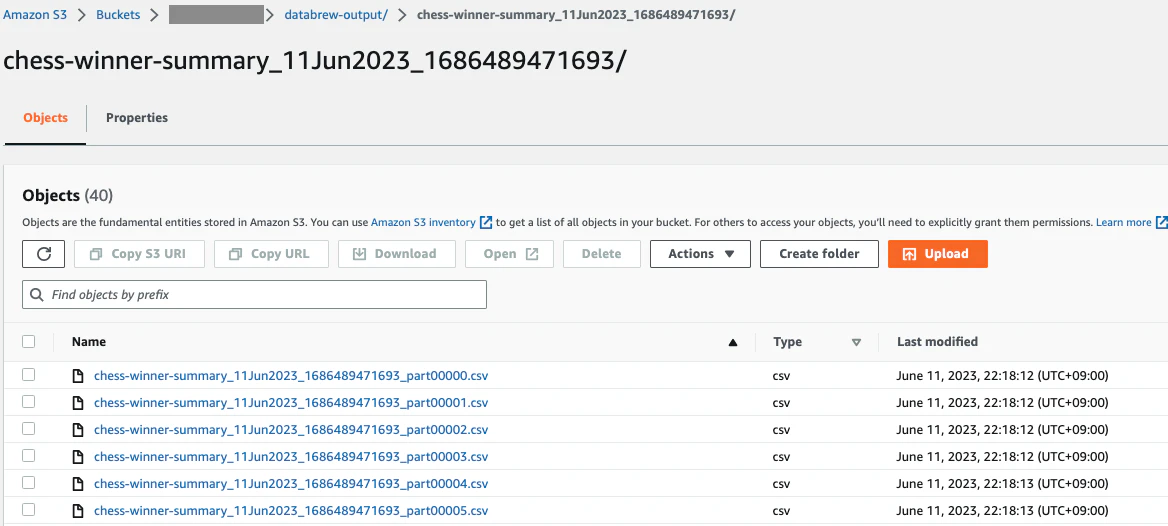
S3ファイルが作成されていました。
-
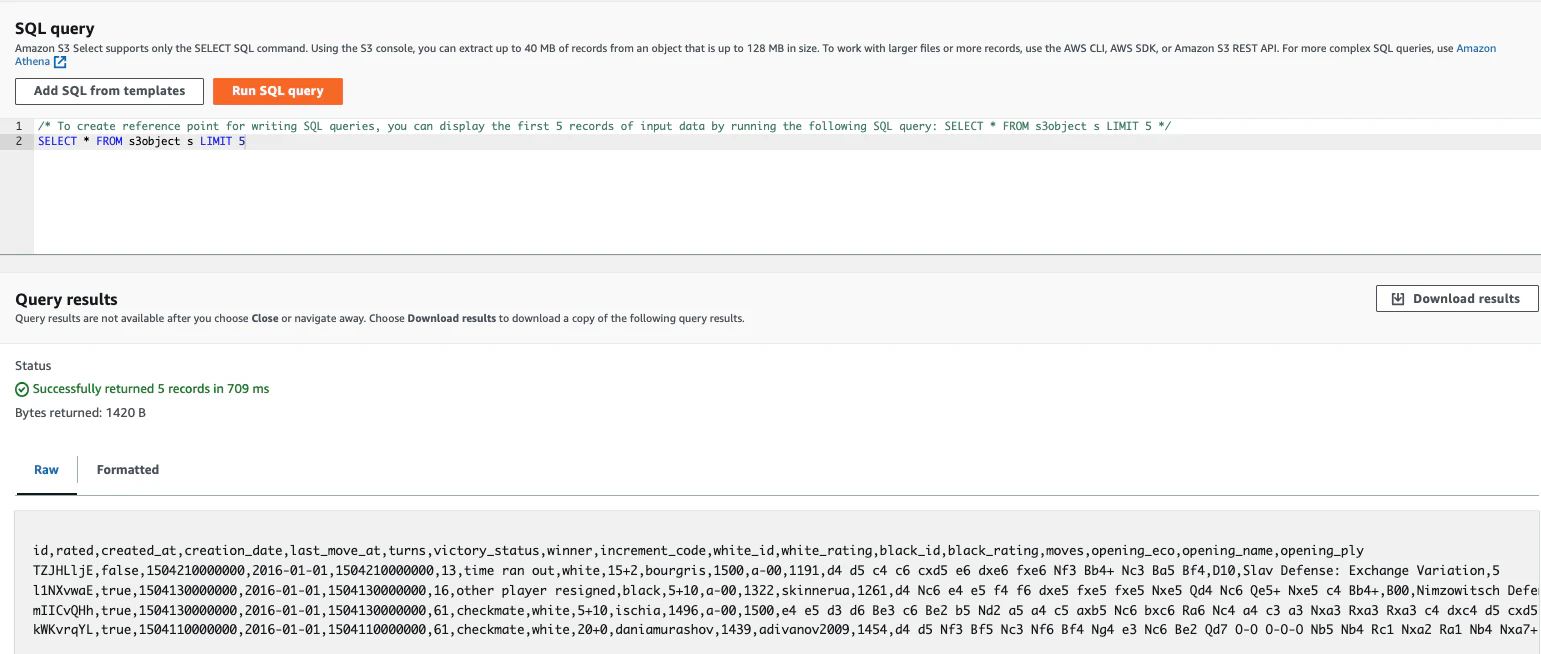
CSVファイルも確認ができました。
考察
今回、あらためて、DataBrewを使用してみました。
プロファイリングでは、データの特徴などが簡単に確認できるため、データの調査や現状確認に有用だと感じました。
また、データの変換などは、GUIを使用して行うのでGlueなどのETLのプログラミングが不要なため、初めての方でも利用しやすいのではないかと感じました。
参考