はじめに
音声変換をするときによく使うものの使い方をまとめた自分用メモです。
間違いなどありましたらご指摘いただけると喜びます。
実装や表示の仕方などは
こちらのcolabにまとめています。
以下のコード(Python)で全部インポートできます。
必要に応じでインポートしてね。
import librosa
import librosa.display
import soundfile as sf
from nnmnkwii.util import example_audio_file, trim_zeros_frames
import matplotlib.pyplot as plt
import pyworld as pw
import pysptk
import pyreaper
import numpy as np
import IPython.display
LibROSA
この子を使うと音声関連の基本的なことは全部できます!
音声の読み込み
以下のコードの場合wavに音声のnumpy形式の一次元配列で格納される
srには音源のサンプルレートが格納される(今回の場合は22050)
引数のsrを変更すると元の音源のサンプルレートに関係なく変更することが可能
wav, sr = librosa.load('/file/no/path.wav', sr=22050)

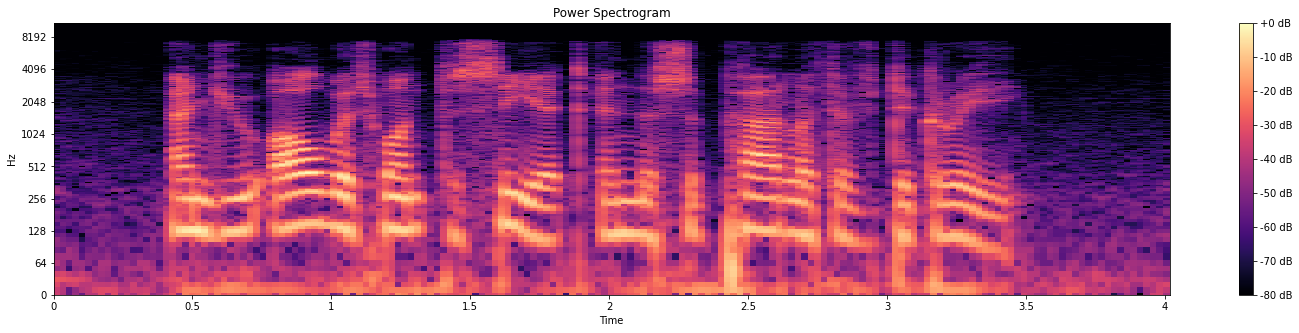
スペクトログラムの作成
以下のコードでスペクトログラムが取得できます。
spec_ = librosa.stft(wav)
spec = np.abs(spec_)
spec = librosa.amplitude_to_db(spec, ref=np.max)
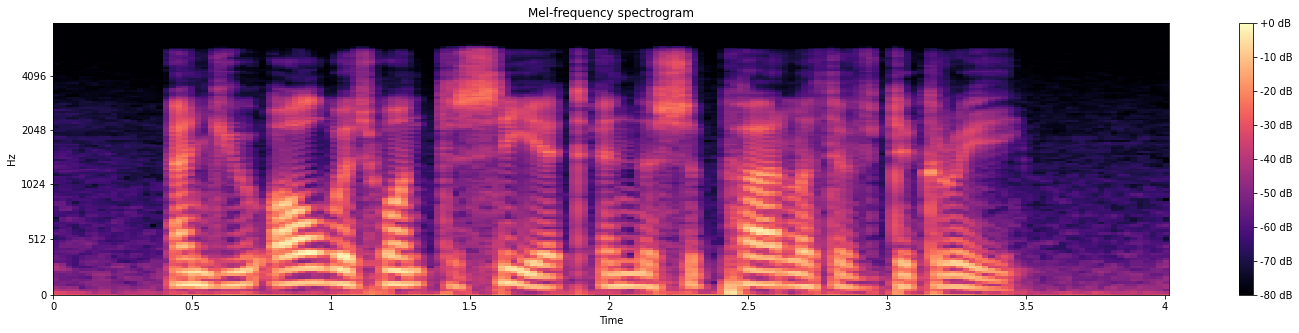
メルスペクトログラムの作成
mlsp = librosa.feature.melspectrogram(y=wav, sr=sr)
mlsp = librosa.power_to_db(mlsp, ref=np.max)
MFCCの作成
mfccs = librosa.feature.mfcc(y=wav, sr=sr)

それぞれの復元方法
復元の際に位相推定の手法であるgriffinlimを用いるのですがあまり精度はよくありません。
代替手法としてwavenetなどを用いる手法などがあります。
スペクトログラム
np.abs()を用いていないなら以下の方法でいけます
spec__to_wav = librosa.istft(spec_)
np.abs()を使った場合は位相推定をしないとなので以下で復元できます。
spec_to_wav = librosa.db_to_amplitude(spec)
spec_to_wav = librosa.griffinlim(spec_to_wav)
メルスペクトログラム
mlsp_to_wav = librosa.db_to_amplitude(mlsp)
mlsp_to_wav = librosa.feature.inverse.mel_to_audio(mlsp_to_wav)
MFCC(Mel Frequency Cepstral Coefficient)
mfccs_to_wav = librosa.feature.inverse.mfcc_to_audio(mfccs)
音声の保存
sf.write('./new_file.wav', wav, sr)
librosa.output.write_wav について
最近のバージョンで動かなくなったみたいです。
もし人のコードを動かしていてAttributeError: module 'librosa' has no attribute 'output'と怒られた場合、おそらくバージョン問題なので、以下のコマンドでなんとかなると思います。
pip install librosa==0.7.2
pip install numba==0.48.0
PyWORLD
音声分析合成システムWORLDのPython実装です。
UTAUなどにも使われているそうです。
音声合成や音声変換の時に非常に便利です!
Librosaで読み込んだ場合以下のようにnumpyの型を変換する必要があります。
wav = wav.astype(np.float64)
F0の推定
F0を推定する手法はふたつあります。
- dio + stonemask: 高速で低精度な手法
- harvest: 低速で高精度な手法
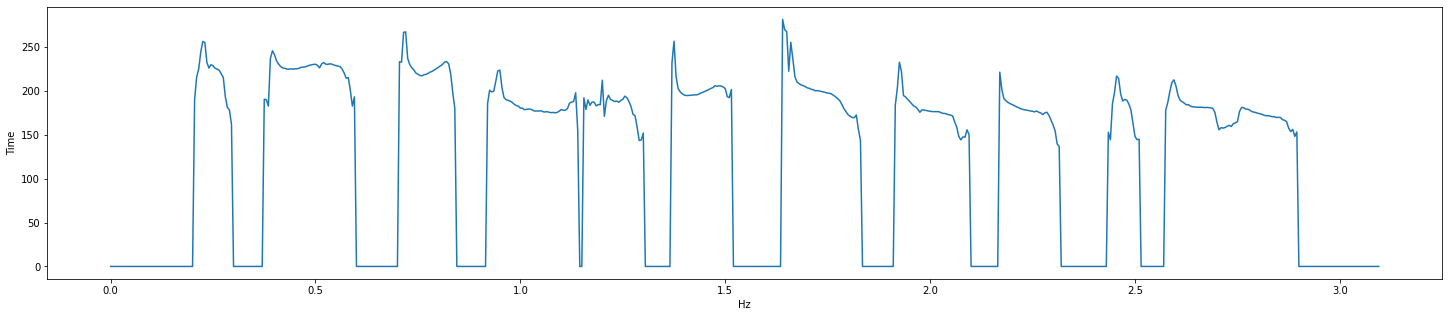
dio + stonemask
おれは人間をやめるぞ!ジョジョーーッ!!
_f0, t = pw.dio(wav, sr)
f0 = pw.stonemask(wav, _f0, t, sr)
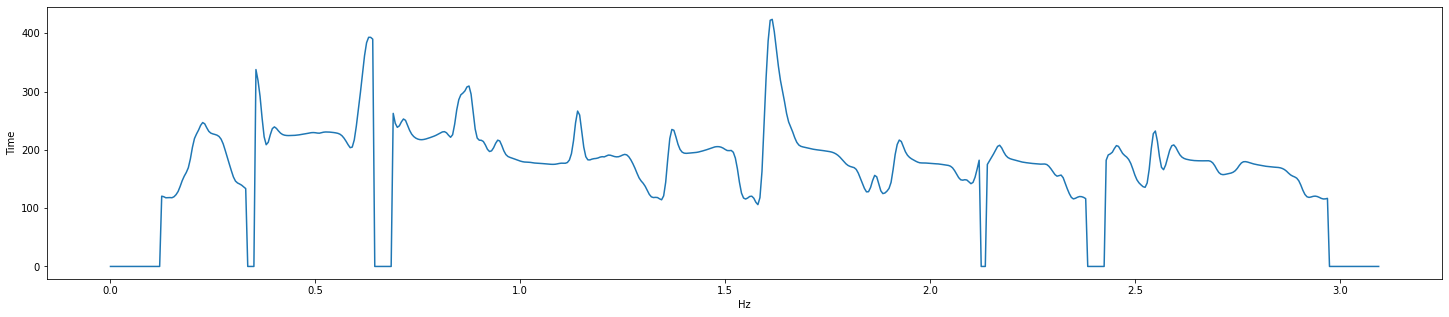
harvest
f0, t = pw.harvest(wav, sr)
スペクトル包絡の推定
sp = pw.cheaptrick(wav, f0, t, sr)

非周期性指標の推定
ap = pw.d4c(wav, f0, t, sr)
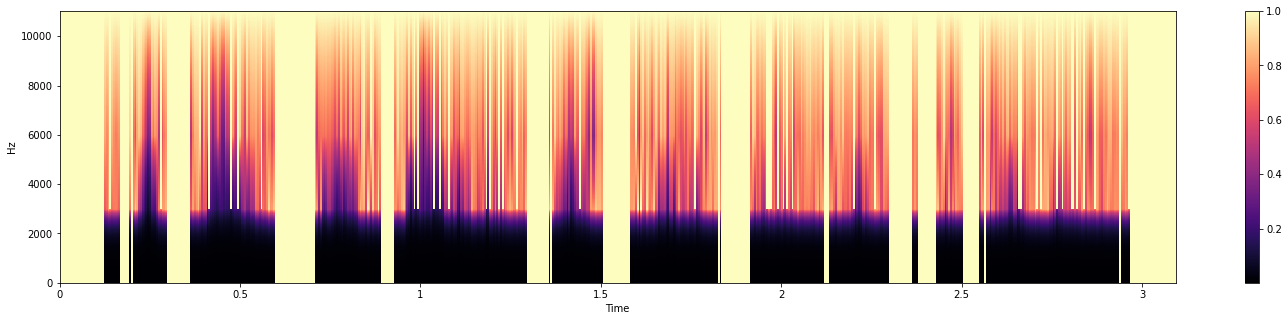
まとめてF0, スペクトル包絡, 非周期性指標を推定
f0, sp, ap = pw.wav2world(wav, sr)
MCEPs(Mel Cepstral Coefficients)の推定
mceps = pw.code_spectral_envelope(sp, sr, 24)

MCEPsからスペクトル包絡の復元
fftlen = pw.get_cheaptrick_fft_size(sr)
mceps_to_sp = pw.decode_spectral_envelope(mceps, sr, fftlen)
WORLDから音声の復元
world_to_wav = pw.synthesize(f0, sp, ap, sr)
pyreaper
F0の推定などができます。
自分は有声区間などを調べるときに使ったりしています。
ライブラリ名がかっこいいです。
使う場合は型がnp.int16じゃないといけないようです。
path = pysptk.util.example_audio_file()
wav, sr = librosa.load(path, sr=22050)
wav = (wav*32767).astype(np.int16)
推定する
pm_times, pm, f0_times, f0, corr = pyreaper.reaper(wav, sr)
Pitch mark
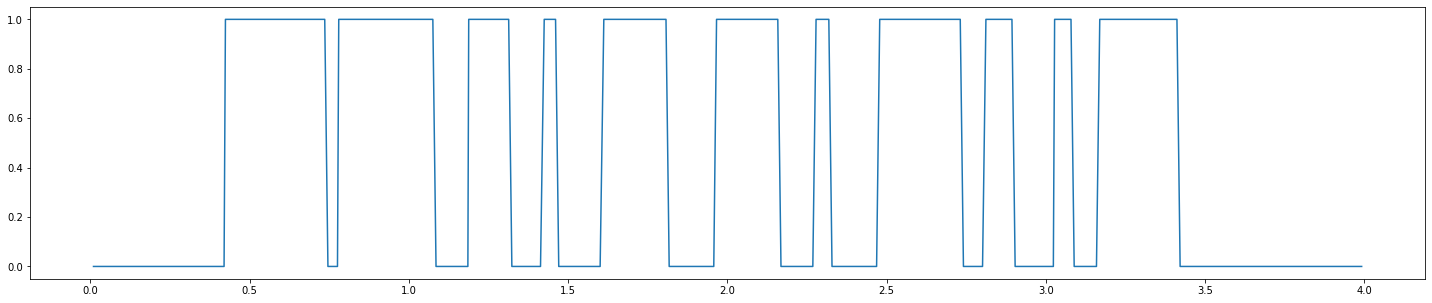
F0 contour

Correlations
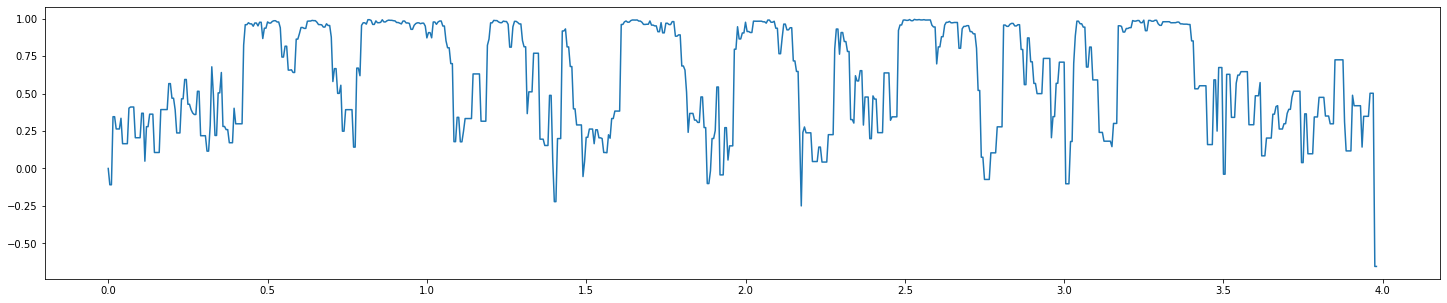
今後調査したいライブラリ
今回、調査したライブラリ以外も今後時間があったら調査して追記していこうと思います。
- nnmnkwii
- WaveNet vocoder
- inaSpeechSegmenter
- PyAudioAnalysis
- PyAudio
さいごに
音声分析合成関連のライブラリはアニオタホイホイな関数名が多く、
書いていて楽しいです。
参考文献
librosa — librosa 0.8.0 documentation
python报错-AttributeError: module ‘librosa‘ has no attribute ‘output‘
音声分析合成システムWORLD
Python-Wrapper-for-World-Vocoder
REAPER: Robust Epoch And Pitch EstimatoR
pyreaper