はじめに
初投稿になります。
私は戦略コンサル→マーケターという経歴のビジネスサイドの人間です。普段はエクセルでデータ分析をしたり、たまにPythonを触ったりしています。
この記事では私のような非エンジニアのビジネスサイドの人間でも、実務で「簡単に」「素早く」RAG(Retrieval-Augmented Generation)を使いこなす方法をまとめています。
具体的には、GoogleColab+langchainで実質3行で実装する方法を載せています。
noteに事例も載せています。
やりたい事
| 名前 | 性別 | 年齢 |
|---|---|---|
| 田中 | 男性 | 25 |
| 山田 | 女性 | 35 |
| ・・・ | ・・・ | ・・・ |
上記のようなデータを分析する際に、PandasやSQLのややこしいコードを書かずに、自然言語でデータ分析を実行できるようにします。
現状:ややこしいコードを書く必要がある↓
grouped_df = df.groupby('性別')['年齢'].mean()
filtered_df = df[(df['性別'] == '女性') & (df['年齢'] >= 30)]
やりたい事:日本語で直接指示ができる↓
性別ごとの平均年齢を教えて
30歳以上の女性を列挙して
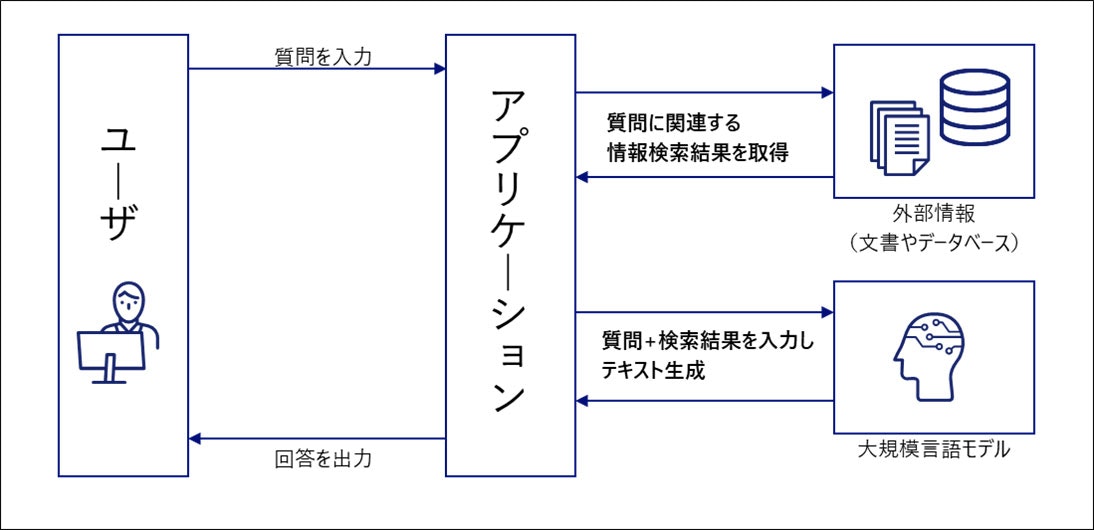
アプローチ
流れは以下です。
- AIに自然言語で指示をする(例: 性別ごとの平均年齢を教えて)
- AIがSQLに変換する(例: df.groupby('性別')['年齢'].mean())
- AIがSQLを実行し、回答を返答する(例: 男性:31歳、女性26歳)
参考:NRI 用語解説一覧 RAG
https://www.nri.com/jp/knowledge/glossary/lst/alphabet/rag
実装は、Google Colaboratory(https://colab.research.google.com/) 上に行います。
肝心のRAGは最もメジャーなOSSのlangchain(https://www.langchain.com/) を使用します。
langchainは、自然言語をSQLに変換して実行するまでの処理を全て実行するようなライブラリです。対象のデータは、データベースやエクセル、ベクトルデータベース(PDF等をDB化したもの)など幅広く対応しています。
実装
- OpenAI APIを使用するため、APIキーの取得を行う必要があります
(参考:https://qiita.com/Isaka-code/items/b50983796636503b44c5) - langchainのコードの詳細は公式ドキュメントを参照ください
(https://python.langchain.com/docs/integrations/toolkits/pandas/) - 今回はcsvをdataframeにした後、RAGをしています
!pip install openai
!pip install langchain
!pip install langchain-openai
!pip install langchain_experimental
import os
import pandas as pd
from langchain.agents.agent_types import AgentType
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain_openai import OpenAI
os.environ['OPENAI_API_KEY'] = "自分のAPIキーを入力"
# サンプルデータとしてタイタニックのデータセットを読み込ませる。(任意のcsvなどに変更する)
df = pd.read_csv(
"https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv"
)
# エージェントを立ち上げる
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True)
# 質問を投げ、回答を得る
rep = agent.invoke("性別ごとの平均年齢を日本語で教えて")
print(rep["output"])
回答:
女性の平均年齢は27.92歳、男性の平均年齢は30.73歳です。
langchainのPandas Dataframeのドキュメント
https://python.langchain.com/docs/integrations/toolkits/pandas/
まとめ
シンプルですが、csvの部分を任意のファイルに変更するだけで実務ですぐに使用可能なRAGのシステムになります。
また、実装したコードはライブラリのインポートを除くと実質以下の3行になります。
# サンプルデータとしてタイタニックのデータセットを読み込ませる。(任意のcsvなどに変更する)
df = pd.read_csv("https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv")
# エージェントを立ち上げる
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True)
# 質問を投げ、回答を得る
print(agent.invoke("性別ごとの平均年齢を日本語で教えて"))
終わりに
2024年4月からアウトプットのためにQiitaとnoteを始めました。「フォロー」や「いいね」頂けると励みになります!