はじめに
RAGの仕組みを概念的に理解している方は多いのではないでしょうか?
また、langchainを使って、実装している人も多いのではないでしょうか?
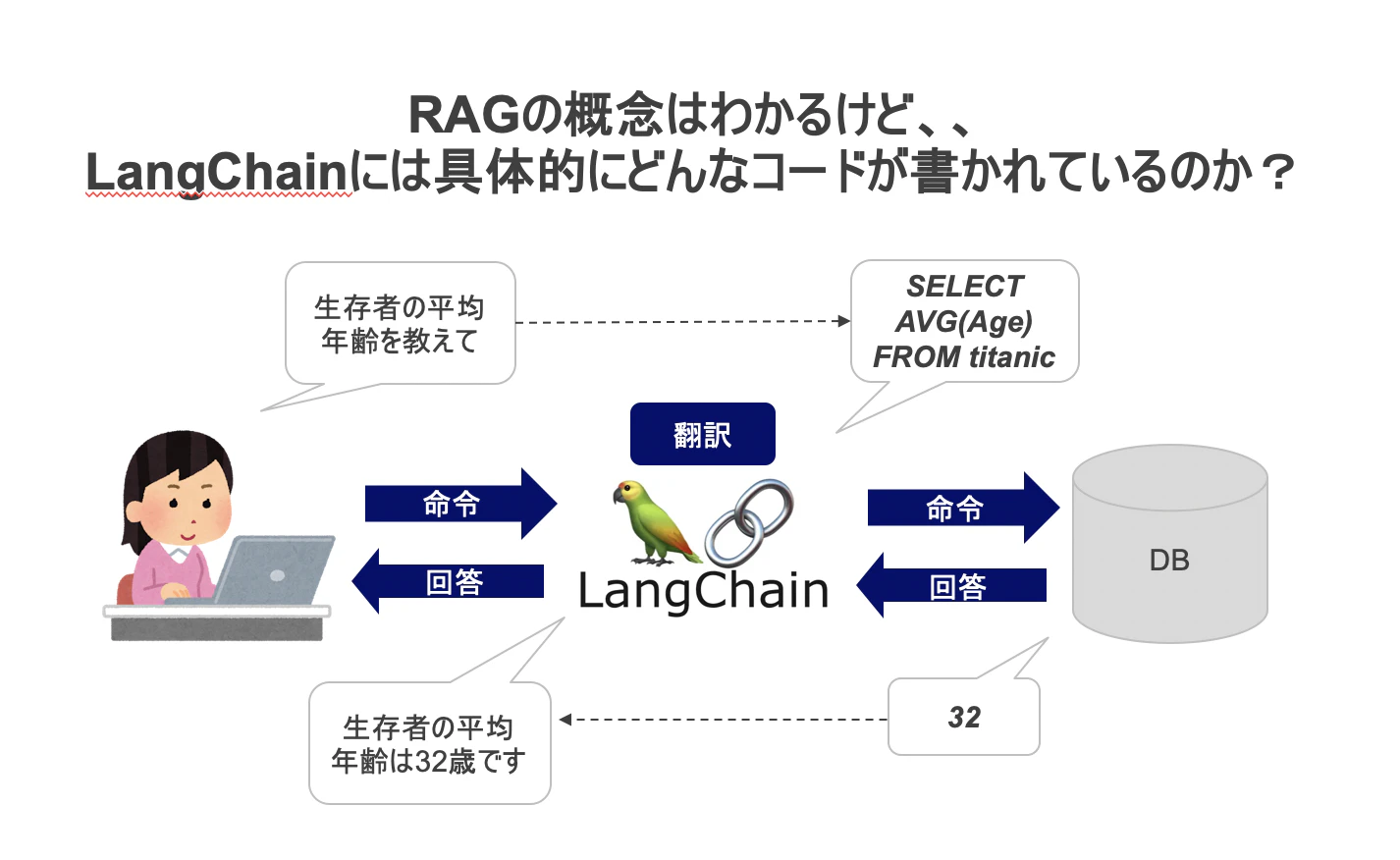
しかし、実際にどのような仕組みでRAG(langchain)が動いているのかを知っている人は多くないと思います。RAGでは自然言語からクエリを作り、それを実行するというプロセス上、プログラムが予期せぬ挙動を勝手に実行してしまうリスクがあります。(例:DBを消してしまう)
本記事では、実際のコードを見ながらlangchainを使ったRAGの処理内容を理解することで、思考停止でブラックボックス的にLangChainのライブラリを使わないようにする手助けをします。
なお、本記事では便宜的に通常のデータベースを対象にRAGをするシンプルなケースを考えます。
RAG実装で欠かせないLangChainとは?
LangChainは、AIを使って質問に答える際に、データベースや文書などから必要な情報を自動で引き出し、それを元に答えを作るRAGと呼ばれる仕組みを実装したpythonのライブラリです。
「RAG(Retrieval-Augmented Generation)」は、質問に対して情報を検索して、そのデータを使ってAIが答えを作る方法です。たとえば、質問に関連する情報をデータベースや文書から探し、それをもとにAIが回答を生成します。
「SQL」はデータベースから情報を取り出すための言語で、LangChainは質問に応じてSQLを使い、自動でデータを引き出して答えを作ります。
つまり、LangChainはRAGを使って、データベースや文書から必要な情報を取り、AIがそれを使って賢く答えるためのツールです。
LangChainの概要
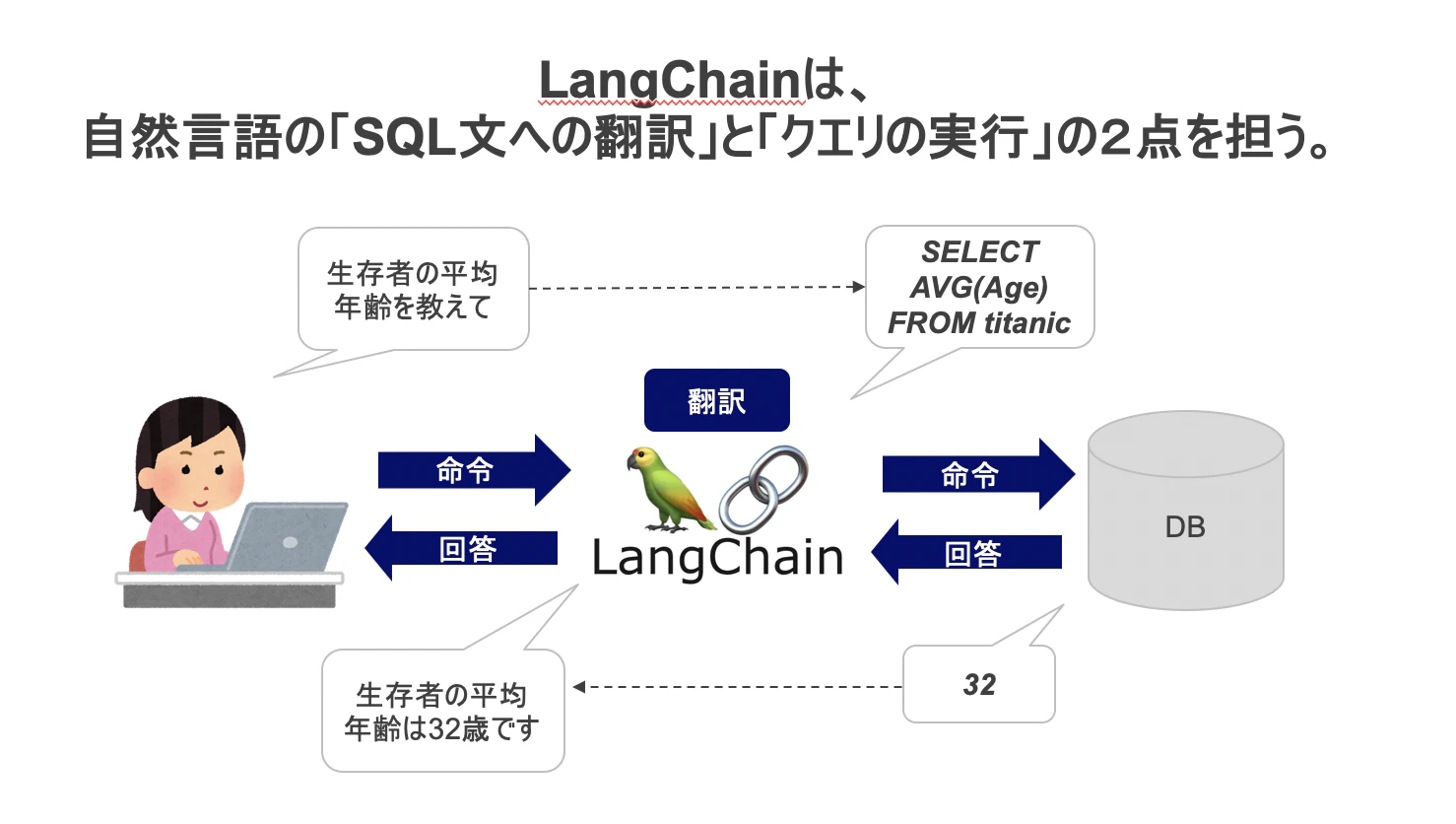
LangChainは、ものすごくざっくりいうと「SQL文への翻訳」と「SQLクエリの実行」の2つを実行してくれます。普通のChatGPTやOpenAI APIだけでは特定のデータベースに対して自然言語クエリで質問し答えを得るためにはかなり工夫が必要です。その工夫をエンジニア達が肩代わりしてくれてオープンにしてくれています。
RAGとLangChainの詳細
RAGとLangChainの詳しい説明は、以下いずれかの記事を読んでいただければ分かると思います。
LangChainが動く仕組み
DBに対して、自然言語でクエリを投げた時を例に、LangChainが実際に何をしているのかをみていきます。
LangChainの公式ドキュメントもチュートリアルとしては分かりやすいのですが、「仕組みの理解」という観点では少々理解が難しいです。
そこで今回は、実際のコードを例にしながら、どのような挙動をしているのかを見ていきます。
まず、私たちがデータベースに対して自然言語で質問をする時、以下のようなコードを書きます。
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
agent_executor.invoke({"input": "生存者の平均年齢を教えて"})
この時「create_sql_agent()」という関数が使われています。ここに「SQL文への翻訳」と「SQLクエリの実行」を行ってくれるコードが書かれているわけです。
そして私たちが良くわからず呼び出している「create_sql_agent()」という関数は、以下のライブラリに、その正体が書かれています。
長いコードですが、基本的に「SQL文への翻訳」と「SQLクエリの実行」の2つが実装されているので、該当箇所を見ていきます。
1.自然言語のSQL文への翻訳処理
薄々勘づいている方も多いと思いますが、生成AIに翻訳をさせています。
{"input": "生存者の平均年齢を教えて"}
という入力を受けたら、以下のプロンプトが実行されます。
You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most 5 results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use date('now') function to get the current date, if the question involves "today".
Use the following format:
Question: Question here
SQLQuery: SQL Query to run
SQLResult: Result of the SQLQuery
Answer: Final answer here
Only use the following tables:
[33;1m[1;3m{table_info}[0m
Question: [33;1m[1;3m{input}[0m
日本語に訳すと以下になります。
あなたはSQLiteの専門家です。入力された質問に対して、最初に文法的に正しいSQLiteクエリを作成して実行します。その後、クエリの結果を確認し、質問に対する答えを返します。
ユーザーが質問内で取得する例の数を特定しない限り、SQLiteのLIMIT句を使用して最大5件の結果をクエリします。最も情報量の多いデータを返すために結果を並べ替えることもできます。
テーブルから全てのカラムをクエリしてはなりません。質問に答えるために必要なカラムのみをクエリします。カラム名は全て二重引用符(")で囲み、区切られた識別子として扱います。
テーブルに存在しないカラムをクエリしないよう注意してください。また、どのカラムがどのテーブルにあるかにも注意を払ってください。
"今日"に関連する質問の場合は、date('now')関数を使用して現在の日付を取得することにも注意してください。
次の形式を使用します:
Question: 質問内容をここに入力
SQLQuery: 実行するSQLiteクエリ
SQLResult: クエリの結果
Answer: 質問に対する最終的な答え
次のテーブルのみを使用します: {table_info}
Question: {input}
ご覧の通り、「create_sql_agent()」の中身にはこのようなプロンプトが書かれています!
この例ではSQLiteのクエリですが、OracleやCSV、ベクトルデータベースなど、それぞれ挙動が異なるため、langchainのエンジニア達がそれぞれプロンプトを用意してくれています。
なお、このようなプロンプトを自分で用意し、本当の意味で0からRAGを実装することも可能です。人の書いたブラックボックスなプロンプトを使うこと自体リスクなので、langchainを使わない方が良いケースも存在します。
2.SQLクエリの実行
上述のプロンプトで、自然言語をSQLに変換する準備が整いました。
その後は、以下のような形でSQLを実行することになります。
まず、質問文とデータベースのテーブル情報をもつinputs情報が定義されています。
inputs = {
"input": lambda x: x["question"] + "\nSQLQuery: ",
"table_info": lambda x: db.get_table_info(
table_names=x.get("table_names_to_use")
),
続いて「create_sql_agent()」が呼び出された時のreturnの定義が記されています。ここで、SQLを実行しています。
return (
RunnablePassthrough.assign(**inputs) # inputs を使ってデータを準備
| (
lambda x: {
k: v
for k, v in x.items()
if k not in ("question", "table_names_to_use") # question, table_names_to_use を除外
}
)
| prompt_to_use.partial(top_k=str(k)) # プロンプトに `top_k` を追加
| llm.bind(stop=["\nSQLResult:"]) # LLM を使ってクエリ生成。SQLQuery の生成がここで行われる
| StrOutputParser() # 生成されたクエリを解析
| _strip # 空白などを削除
)
StrOutputParser() というコードでSQLクエリが実行されています。
こちらも超ざっくりですが、イメージとしては、SQLite3のような形でDBへpythonから指示します。(以下の記事が参考になります)
Parsersの詳細については、公式より具体的な説明があり、こちらが参考になります。
なお、langchainでは「|」を使うことで、チェーンという単位で処理を行います。
下記の記事が非常に分かりやすく、参考にさせて頂きました。
INPUT(prompt)からOUTPUT(output_parser)までの処理が、"|"をパイプ演算子のように使い書かれています。
よりシンプルな理解をする場合には、こちらのリンクが参考になりました。
まとめ
今回はlangchainの「create_sql_agent()」関数の実際のコードを見ながら、「自然言語のSQL文への翻訳処理」と「SQLクエリの実行」がどのように行われていくかを紹介しました。
実行されていること自体はシンプルなため、langchainを使わずにRAGを実装することは可能です。また、詳細な説明は割愛しましたが、ブラックボックスなライブラリとしてlangchainを使ってしまうと「DBへの予期せぬ指示」が発生するリスクがあります。例えば、自然言語で「データを全て消して」というとDBがすっからかんになってしまう可能性があります。
本記事を参考にRAGの具体的な裏側の仕組みを知ることで、自身でのRAGの実装の手助けになれば嬉しいです。