この記事は、私(@zr_tex8r)が以前(2009~2010年)に書いた記事「upLaTeXを使おう」を、現在(2017年)の情勢に合わせて改訂したものである。
この文書では、主にpLaTeX使用者向けに、upTeX上で動くLaTeXである「upLaTeX」の解説を行う。またupLaTeXの機能を支援する拙作のマクロパッケージについて紹介する。
upTeXのインストール
TeX Liveにおいては、upTeXエンジンはpTeXと同じコレクション(collection-langjapanese)に含まれている。従って、pTeXが使えるのであればupTeXも使える状態のはずである。
W32TeXの場合は、インストール対象のアーカイブにuptex-w32.tar.xzを加える。
周辺ツール
TeX LiveやW32TeXに含まれるdvipsやdvipdfmxはupTeXに対応している。
その他の「和文Unicode版」のツールには以下のものがある。
- upbibtex: 和文Unicode版のBibTeX。
- upmendex: 和文Unicode版のMakeindex。
- upmpost: 和文Unicode版のMetaPost。
フォントの設定
TeX Live/W32TeXの初期状態ではupTeXの標準和文フォントに対してIPAexフォントがマップされる(つまりdvipdfmxでPDF文書を作るとIPAexが埋め込まれる)。フォントの設定については以下のTeX Wikiの記事を参照。
dvioutについて
dvioutについての解説は別の記事にまとめた。
upLaTeX使用法:基礎編
文書作成時の注意
文書の文字コード
upTeXの入力漢字コード(入力文書の文字コード)はUTF-8が既定になっている。従って、文書ファイルをUTF-8で作成する必要がある。(ただし、uplatexの-kanjiオプションで入力漢字コードを変更することができる。)
参考: pTeXの既定の入力漢字コードは環境により異なり、Shift_JIS、EUC-JP、UTF-8のいずれの可能性もある。W32TeXの場合はShift_JISが既定になっている。
文書クラスの指定
和文用の文書クラスに関しては、upLaTeXに対応したものを用いる必要がある。標準的な文書クラスに関しては、upLaTeXに対応した設定が用意されている。具体的には、先頭の\documentclassの指定を次のように変える必要がある。
- pLaTeXの標準クラス(jarticle/jreport/jbook/tarticle/treport/tbook)の場合: 先頭に
uを付加した名前のクラスを代わりに用いる。
(例)\documentclass[fleqn]{jarticle}→\documentclass[fleqn]{ujarticle} -
jsclassesバンドル(新ドキュメントクラス)のクラス(jsarticle/jsreport/jsbook)の場合: オプションに
uplatexを追加する。
(例)\documentclass[report,12pt]{jsbook}→\documentclass[report,12pt,uplatex]{jsbook} -
BXjsclsバンドルのクラス(bxjsarticle/bxjsreport/bxjsbook/bxjsslide)の場合: オプションに
uplatexを指定する。 -
jlreqクラスの場合: オプションに
uplatexを指定する。ただし省略してもよい。
欧文の文書中に日本語を混ぜる等の目的で、pLaTeXでも欧文の文書クラス(article等)が用いられることがあるが、この場合はupLaTeXでもそのまま通用させることができる。
注意: 和文文書クラスについては、必ず公式の説明書などを見てupLaTeX対応であることを確認すべきである。決して「uplatexで実際にコンパイルが通ったからupLaTeX対応である」と勝手に判断してはいけない。
upLaTeX文書の例
あとは、pLaTeXの文書を書くのとほとんど同じである。pLaTeXで使っているパッケージは、和文と無関係のものなら必ず使えるはずであり、和文用のものもほとんどが使えることが期待できる。
% 文字コードはUTF-8にする
\documentclass[uplatex,b5j]{jsarticle} % uplatexオプションを入れる
%\documentclass[b5j]{ujarticle} % jarticle系にしたい場合はこっち
\usepackage[scale=.8]{geometry} % ページレイアウトを変更してみる
\usepackage[T1]{fontenc} % T1エンコーディングにしてみる
\usepackage{txfonts} % 欧文フォントを変えてみる
\usepackage{plext} % pLaTeX付属の縦書き支援パッケージ
\usepackage{okumacro} % jsclassesに同梱のパッケージ
\begin{document}
\title{とにかくup{\LaTeX}を使ってみる}
\author{匿名希望}
\西暦\maketitle % 漢字のマクロ名もOK
\section{日本語と数式}
\textbf{ゼータ関数}(zeta function)というのは
\begin{equation} % 数式中の漢字もOK
\zeta(s) \stackrel{定義}{=} \sum_{n=1}^\infty \frac{1}{n^s}
= \prod_{p\colon 素数}\frac{1}{1-p^{-s}}
\end{equation}
とかいう奴のこと。
\section{縦書き}
\setlength{\fboxsep}{.5zw}
縦書きの例は
\fbox{\parbox<t>{12zw}{%
\setlength{\parindent}{1zw}
{\TeX}(テック、テフ)はStanford大学のKnuth教授に
よって開発された組版システムである。
{p\TeX}は\株 アスキーが{\TeX}を日本語対応
(縦書きを含む)にしたものである。
\par\bigskip
このように\bou{縦書き}についても{p\TeX}と
全く同様に文書を作成できます。
\par\bigskip
平成\rensuji{20}年\rensuji{4}月\rensuji{1}日
\par\medskip
平成\kanji20年\kanji4月\kanji1日
}}%
こんなの。
\section{okumacroで遊んでみる}
\ruby{組}{くみ}\ruby{版}{はん}、\ruby{等}{とう}\ruby{幅}{はば}、
\keytop{Ctrl}+\keytop{A} \keytop{Del}
\keytop{Ctrl}+\keytop{S} \return、
\MARU{1}\MARU{2}\MARU{3}
\par\bigskip
\begin{shadebox}
\挨拶 それでは。敬具
\end{shadebox}
\end{document}
このLaTeX文書のファイル名をtest1.texとすると、以下のコマンドでPDF文書に変換できる。
uplatex test1
dvipdfmx test1
(表題部より下の部分の出力)

Unicode文字の利用:BMP内文字
単にUTF-8で入力ファイルを書くだけならば、pTeXでも可能である(起動オプションに-kanji=utf8を指定)が、その場合でもASCII+JIS X 0208の外の文字を「直接」処理することはできない。これに対してupTeXは、最初からUnicodeを前提としているので、全てのUnicode文字をJISの文字と全く同様に扱うことができる。つまりjapanese-otfパッケージ等の補助を必要としない。
\documentclass[uplatex,papersize,a5paper]{jsarticle}
%
% パッケージ読込なし!
%
\begin{document}
万有引力の法則を発見した科学者は誰か。
\begin{itemize}
\item[㋐] 森鷗外
\item[㋑] 内田百閒
\item[㋒] 鄧小平
\item[㋓] 李承燁
\item[㋔] ウィリアム・ヘンリー・ゲイツⅢ世
\item[㋕] 以上のどれでもない
\end{itemize}
\end{document}

ただし、Unicode内部処理が可能なのは和文のみであり、欧文に関しては、upTeX は従来の8ビット欧文TeX(pdfTeXを含む)と同じ能力しか持たないことを改めて注意しておく。(欧文の処理については後の節を参照されたい。)「欧文文字」を和文扱いにしてUnicode内部処理を利用するというトリック1は原理的には可能であるが、和文処理を目的であるという性質に起因した様々な制限があり、またそもそもそのような用途は想定されていないので、標準のupLaTeXにそのためのサポートは存在しない。以下で、upLaTeXの和文Unicode処理に関する注意点を挙げる。
- 実際に文字が出力(表示・印刷)されるかどうかは、その為に用いられるフォントに文字の字形(グリフ)があるかに依存する。通常、日本語用のフォントが使用されているはずなので、日本語の文脈に現れない文字(例えばジョージア文字)は使用できない。特にdvipdfmxの通常の設定では、Adobe-Japan1の字形に対応しないUnicode文字は使用できない。
- さらに、全ての文字に対して全角幅であることを仮定している(pTeXの和文フォントと同じ)ので、例えフォントに字形が存在しても、それが全角幅でない場合は正しく処理されない。JIS X 0213(拡張JIS)の一部の記号(例えばU+228A[1-2-36]2“⊊”)は、日本語フォントで全角幅になっていないことが多いことに注意。JIS X 0208にあるロシア文字・ギリシャ文字は全角幅で「正常に」出力されるが、無論それはロシア語・ギリシャ語の組版としては全く役に立たない。
- Unicode規定の文字合成、リガチャ、その他のグリフ置換は(例えフォントがその為の情報を持っていたとしても)一切適用されない。従って、JIS X 0213に含まれる文字でUnicodeでは合成が必要であるもの(例えば1-4-873“か゚”(=304B 309A))は使用できない。
- BMPの外にある文字については、次小節を参照。
- 中国語・韓国語の出力については、後の節を参照。
- pTeXと同じく、
-kanjiオプションで入力コードを指定できるが、既定のUTF-8以外の指定では直接入力可能な文字はJIS X 0208に限定され、ShiftJIS2004等の符号化方式は使えない。この場合でも、次に述べるコード入力(\UI)は使用できる。
Unicode文字の直接入力が困難な場合は、拙作のpxbaseパッケージを読み込むと、\UI{‹コード値の16進›}でそのコード値の文字が出力できる。
\documentclass[uplatex,papersize,a5paper]{jsarticle}
\usepackage{pxbase} % \UIを使用する
\begin{document}
「超絶技巧練習曲」「ハンガリー狂詩曲」等の難度の高い
ピアノ曲が有名な、ハンガリー生まれの作曲家は誰か。
\begin{itemize}
\item[\UI{32D0}] 森\UI{9DD7}外
\item[\UI{32D1}] \UI{9127}小平
\item[\UI{32D2}] ウィリアム・ヘンリー・ゲイツ\UI{2162}世
\item[\UI{32D3}] いい加減にしろ
\end{itemize}
\end{document}

半角カタカナの扱い
upLaTeXにおいては、半角カタカナは他の和文文字と(字幅を除いて)全く同様に扱われる。すなわちUTF-8で入力して処理できる。
\documentclass[uplatex,a4paper]{jsarticle}
\begin{document}
笑った → ワラタ → ワロタ → ワロス
\end{document}
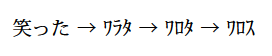
Unicode文字の利用:BMP外の文字
upTeX自身はBMP(基本多言語面)の文字(コード値U+10000未満の文字)とそれ以外の文字(U+10000以上の文字―前述の理由で実質利用可能なのはSIP(第2面)の漢字に限られる)を区別せずに取り扱う。従って、現在のupLaTeXにおいてはBMP外の文字を使うのに特段の処置は必要としない。
\documentclass[uplatex,a4paper]{jsarticle}
\usepackage{pxbase} % \UIを使うため
\begin{document}
土屋さん / \UI{5721}屋さん / \UI{2123D}屋さん \par
土屋さん / 圡屋さん / 𡈽屋さん \par
\end{document}

しかし、2018年2月以前のupLaTeXにおいては、当時の周辺ツール実装の事情により、upLaTeXの既定のフォント設定4では敢えてBMPの文字のみが扱えるようになっていた。ここでは古いupLaTeXでBMP外の文字を使う方法を説明する。
BMP外の文字を使える設定を簡単に手に入れるには、拙作のpxbabelパッケージを用いて以下のようにすればよい。直接入力も\UIによるコード指定も可能である。どうしてBabelが登場するのか等は取り敢えず気にしないことにしよう(気になる人は後の解説を参照)。
注意: 改訂新版の本記事のpxbabelについての記述はv1.1[2017/05/29]を前提にしていて、原則として新しい簡潔な書き方を採用している。古い版ではここで挙げた書き方が使えないので注意してほしい。
\documentclass[uplatex,a4paper]{jsarticle}
\usepackage{pxbase}
\usepackage[japanese]{pxbabel} % これを追加
\begin{document}
土屋さん / \UI{5721}屋さん / \UI{2123D}屋さん \par
土屋さん / 圡屋さん / 𡈽屋さん \par
\end{document}
参考: BXjsclsバンドルのクラス(bxjsarticleなど)を使う場合は、古いupLaTeXにおいても最初からBMP外の文字が使える設定になっている。
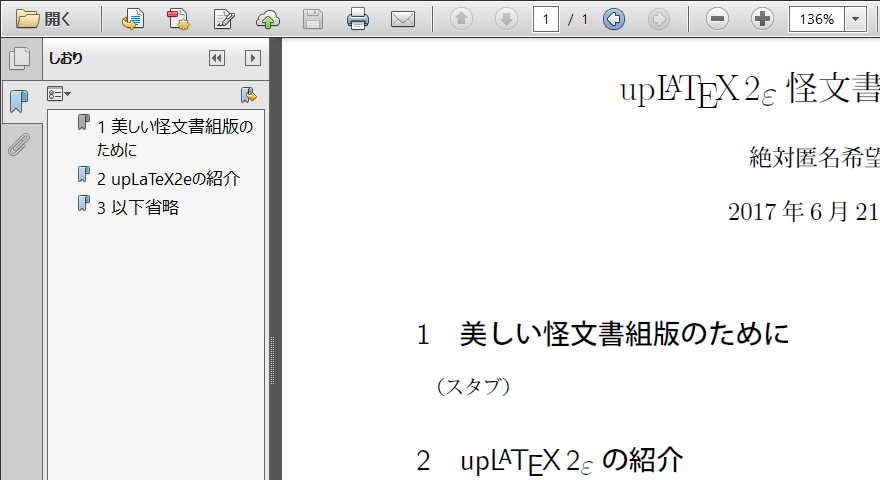
日本語のPDFしおりの作成
pLaTeXにおいてhyperrefパッケージとdvipdfmxを用いて和文文字を含むしおりや文書情報を含んだPDF文書を作る場合、pxjahyperパッケージを使う必要があった。これはupLaTeXにおいても変わらない。
\documentclass[uplatex,dvipdfmx,b5paper]{jsarticle}% ドライバ指定が必要
\usepackage[bookmarks=true,bookmarksnumbered=true,
bookmarkstype=toc]{hyperref}
\usepackage{pxjahyper}
\hypersetup{pdftitle={upLaTeX2e怪文書作成入門},pdfauthor={絶対匿名希望},
pdfkeywords={upTeX,upLaTeX,怪文書,Unicode,CJK}}
\begin{document}
\title{{up\LaTeXe}怪文書作成入門}
\author{絶対匿名希望}
\maketitle
\section{美しい怪文書組版のために}
(スタブ)
\section{{up\LaTeXe}の紹介}
(スタブ)
\section{以下省略}
\end{document}
注意: やや直感に反するが、upLaTeXを使う場合はhyperrefに
unicodeオプションは指定してはいけない。(pxjahyperの0.3a版ではunicodeオプションのサポートが追加されているが、実験的機能の扱いである。)
upLaTeX使用法:応用編
japanese-otfパッケージの利用
upLaTeXではUnicode文字は標準で使えるが、「Unicodeでも統合(包摂)されている『葛』の2つの字体を書き分ける」とか「Unicodeにない記号を使う等の目的でAdobe-Japan1のグリフを使いたい」という場合にはjapanese-otfパッケージが必要になる。
upLaTeXでjapanese-otfパッケージ(LaTeXパッケージ名はotf)を読み込む時には、\usepackageのオプションにuplatexを指定する必要がある。ただし、クラスオプションにuplatexがある場合はそれが“グローバルに適用される”ためパッケージでの指定は不要である5。
この点を除けば、あとはpLaTeXの場合と全く同じように\CIDが使えるようになる。\UTFはわざわざ使う意味がないが、otfのオプションmultiを指定して\UTFCや\UTFM等を使うのは有意義かもしれない。(韓国語・中国語の文字を直接書きたい場合は後の節を参照。)
\documentclass[uplatex,a4paper]{jsarticle}
\usepackage{otf}
\renewcommand{\theenumi}{\ajLabel\ajKuroMaruKaku{enumi}}
\renewcommand{\labelenumi}{\theenumi}% 番号は黒丸四角で
\begin{document}
\begin{enumerate}
\item 奈良県\CID{1481}城市
\item 東京都\CID{7652}飾区
\end{enumerate}
\end{document}

注意:
deluxe、expert等でjapanese-otfのフォント設定を拡張されたものに変えている場合は、その設定がCJK言語が無効である場合にのみ機能する(「BMP外の文字の扱い」と「japanese-otfの拡張設定」が両立できていないため)ことに注意。
ちなみに、直接ソースに書いた「葛」がどちらの字体になるかはフォントの設定に依存する。
参考: dvipdfmxの場合の概略を述べておく。設定されているフォントがCID-keyedでない場合は、そのフォントが(既定の属性値で)規定した字体が選択される。一方、設定されているフォントがCID-keyedである場合は、CMapの設定に依存し、
H/VまたはUniJIS-UTF16-H/Vの場合は2000JIS/83JISの例示字体、UniJIS2004-UTF16-H/Vの場合は2004JISの例示字体に対応する字体が選択される。(ちなみにこの話はJISまたはUnicodeを入力符号とする和文フォント(JFM)全てに当てはまり、japanese-otfパッケージやupTeXとは無関係である。)
欧文のUTF-8入力との併用
普通の(8ビットの)欧文LaTeXでUTF-8入力を扱う方法として、utf8入力エンコーディング、およびその拡張版であるucsパッケージのutf8x入力エンコーディングの使用がある。これはUTF-8入力をバイト列として読み込みマクロ処理を通すことでLaTeXが持っている非英語文字出力(fontenc)の枠組に持ち込もうとするものである。(下の例でBabelはフォントエンコーディングを適切に切り替える役割を果たしている。)
% 欧文LaTeX文書; 文字コードはBOM無UTF-8
\documentclass[a5paper]{article}
\usepackage[scale=.7]{geometry}
\usepackage[LGR,T2A,T1]{fontenc}
\usepackage[utf8]{inputenc} % これで欧文 UTF-8 が扱える
\usepackage[greek,russian,english]{babel}
\begin{document}
This document contains English, Română,
\foreignlanguage{greek}{Ελληνικά}, and
\foreignlanguage{russian}{русский язык}.
\end{document}
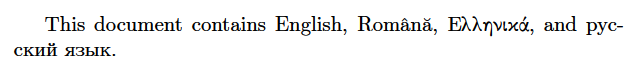
ところが、upLaTeXの既定の設定だと、ASCII以外の全てのUnicode文字が和文文字として解釈され(つまり入力エンコーディングの処理には回らない)、和文文字のフォントで出力しようとする。結果は、字形が表示されない、全角幅で表示される等、まともなものにならない。pTeXでは、本来欧文扱いしてほしい文字(ギリシャ文字・キリル文字の一部)がJIS X 0208に入っている時に同じ現象が起こったが、upTeXではほぼ全てのUnicode文字について起こることになる。
このため、upTeXではUnicodeのブロック毎に、それに属する文字がを和文文字として解釈するか、それともあたかも欧文TeXのようにUTF-8バイト列のままにする(そしてinputencにマクロ処理させる;これを**「欧文扱い」**と呼ぶ)かを選択することができる。この機能を支援する拙作のパッケージがpxcjkcatパッケージである。このパッケージの使用法の詳細はマニュアルに任せることにし、ここでは欧文中心の文書に適した一括設定を利用することにする。次の例のようにpxcjkcatをprefernoncjkオプション付きで読み込めばよい。
% upLaTeX文書; 文字コードはUTF-8
\documentclass[a5paper]{article}% 欧文用クラス
\usepackage[scale=.7]{geometry}
\usepackage[prefernoncjk]{pxcjkcat} % これを追加
\usepackage[LGR,T2A,T1]{fontenc}
\usepackage[utf8]{inputenc}
\usepackage[greek,russian,english]{babel}
\begin{document}
This document contains English, Română, 日本語,
\foreignlanguage{greek}{Ελληνικά}, and
\foreignlanguage{russian}{русский язык}.
\end{document}
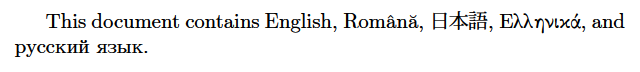
この設定では、漢字・かな・ハングル等の明らかな「CJK文字」以外は全て欧文扱いになる。pxcjkcatのオプションにprefernoncjkの代わりにprefercjkvarを指定すると、ギリシャ・キリル文字は欧文扱いだが、欧文引用符(“ ”)等の句読点類は和文扱いになる。
参考: pxcjkcatの
prefernoncjk設定では、japanese-otfパッケージの読込(nomacrosでない場合)が失敗する。これは、これらのパッケージのマクロ名に使われている○や□等の記号が欧文扱いになるからである。この場合、japanese-otfをpxcjkcatより前に読み込めばよい。どうしても順序を変えたくない場合は、japanese-otfの読込の\usepackage命令を\withcjktokenforcedの引数に入れるという方法もある。さらに、○等の記号が入った命令を実際に使う場合は、該当の部分を\withcjktokenforcedに入れる必要がある。
\documentclass[uplatex,a4paper]{jsarticle}
\usepackage[prefernoncjk]{pxcjkcat}
\withcjktokenforced{\usepackage[noreplace]{otf}}
\begin{document}
\withcjktokenforced{\○秘} / % ここでも \withcjktokenforced が必要
% これでは面倒なのでマクロにしたい…という場合、そのマクロ
% 定義を \withcjktokenforced に入れる必要がある。
\withcjktokenforced{\newcommand{\MaruHi}{\○秘}}
\MaruHi % 使うときは自由
\end{document}

GT書体フォントの利用
pLaTeXで「GT書体フォント」を使用するためのパッケージには、gtftexパッケージ等があるが、これはupLaTeXでは使えない。(多くの場合、和文フォントを扱うパッケージはエンコーディングの影響を受けるのでそのままではupLaTeXでは使えない。)拙作のPXgtfontパッケージはpLaTeX/upLaTeXの両方に対応しているので、これを用いてGT書体フォントを利用することができる。
\documentclass[uplatex,papersize,a5paper]{jsarticle}
\usepackage{pxgtfont}
\begin{document}
これは\GI{17106}論でなく髙島屋でもない。
\end{document}

中国語・韓国語の扱い
upTeXでは日本語、韓国語、簡体字中国語、繁体字中国語の4つの「CJK言語」(と呼ぶことにする)の為のフォント設定(TFM定義)が用意されている。これらをupLaTeXで使うために適切に設定しBabelの枠組を利用して切り替える機能を提供する拙作のパッケージがpxbabelパッケージである。
このパッケージの詳細はPXbaseバンドルの解説記事に任せるとして、ここではpxbabelを用いた例を2つ紹介する。 最初は基底言語が英語である例である。
\documentclass[a4paper]{article}% 欧文用クラス
\usepackage[scale=.7]{geometry}
\usepackage[prefernoncjk]{pxcjkcat}
\usepackage[LGR,T2A,T1]{fontenc}
\usepackage[utf8]{inputenc}
\usepackage[japanese,korean,schinese,tchinese,% CJKな言語
greek,russian,english]{pxbabel}% メインはenglish
\usepackage{pxbabel}
\begin{document}
This document contains English, Română,
\foreignlanguage{japanese}{日本語},
\foreignlanguage{korean}{한국어},
\foreignlanguage{schinese}{简体中文},
\foreignlanguage{tchinese}{繁體中文},
\foreignlanguage{greek}{Ελληνικά},
\foreignlanguage{russian}{русский язык},
and tlhIngan Hol.
\end{document}

次は基底言語が日本語である例である。
\documentclass[uplatex,papersize,a5paper]{jsarticle}
\usepackage[schinese,korean,japanese]{pxbabel}% メインはjapanese
\begin{document}
1927年に人類初の大西洋単独無着陸飛行に成功した
アメリカの飛行家は誰か。
\begin{itemize}
\item[㋐] 森鷗外
\item[㋑] \foreignlanguage{schinese}{邓小平}
\item[㋒] \foreignlanguage{korean}{이승엽}
\item[㋓] William Henry Gates III
\item[㋔] 返す言葉も無い
\end{itemize}
\end{document}

なお、現在の言語が「日本語(japanese)である場合」と「CJK言語以外(english等)である場合」は「和文」フォント(和文TFM)はともに日本語用のフォントとなるが、以下のような違いがある。
- 日本語である場合: BMPの外の文字も使用可能な特別なフォントが設定される。
- CJK言語以外である場合: 文書クラスで指定された既定の和文フォントが設定される。ujarticleやjsarticleの場合、これはBMPの文字しか扱えない。
前の節で述べたBMP外の文字を扱う方法はこのインタフェースを利用したものである。
付録:upLaTeX機能一覧
pLaTeXと比べた場合の拡張機能、およびそれに深く関わる機能を挙げる。
upTeXの機能
-
\disablecjktoken:全てのUnicode文字を「欧文扱い」にする。入力に関して8ビット欧文TeXと同じになる。 -
\enablecjktoken:「欧文・和文扱い」の別を「本来の状態」(和文カテゴリコードに従った状態;pxcjkcatで設定した状態)に戻す。 -
\forcecjktoken:ASCII文字以外のUnicode文字を「和文扱い」にする。
pxbase/bxbaseパッケージの機能
-
\UI{<コード値16進>,...}:指定されたUnicode符号位置の文字を出力する。upLaTeXではupTeX自身の機能を使うので他のパッケージの補助が不要になる。
pxcjkcatパッケージの機能
-
\cjkcategorymode{<モード>}:Unicode文字の「和文・欧文扱い」の別を切り替える命令。<モード>に指定できる値は以下の通り。なお、pxcjkcatパッケージの読込時のオプションにモード値を指定することも可能。-
forcecjk:upTeXの既定の設定と同じ。ASCIIブロックのみが「欧文扱い」でそれ以外の全てが「和文扱い」となる。 -
prefercjk:AdobeのCJK文字集合(Adobe-Japan1等)の何れかと共通部分をもつUnicode文字ブロックの文字を「和文扱い」とし、残りを「欧文扱い」とする。 -
prefercjkvar:prefercjkにおいて、ギリシャ文字・キリル文字を全て「欧文扱い」に変更したもの。 -
prefernoncjk:prefercjkvarにおいて、さらに一部の句読点や記号を「欧文扱い」に変更したもの。
-
-
\cjkcategory{<ブロック>,...}{<カテゴリ>}:各Unicodeブロックの「和文カテゴリコード」を直接変更する命令。<ブロック>にはブロックID(例えば“Cyrillic”ならcyrl)または非ASCII文字1つ(その文字の属するブロックを表す)で指定する。<カテゴリ>は設定する「和文カテゴリコード」値であり、「noncjk(欧文扱い)」「kanji(漢字扱い)」「kana(仮名扱い)」「cjk(和文記号扱い)」「hangul(ハングル扱い)」のいずれかである。後ろの4つはともに「和文扱い」であるが、upLaTeXでの扱いが異なる部分がある。
pxbabelパッケージの機能
「upTeXで用意されたCJKフォント設定を用いる」(参照)目的でpxbabelパッケージを使う場合は、パッケージ読込は次のようにする。
\usepackage[korean,schinese,tchinese,japanese]{pxbabel}
ここでオプションにはjapanese(日本語)、korean(韓国語)、schinese(簡体字中国語)、tchinese(繁体字中国語)の言語オプションのうち必要なものを列挙する。これによりBabelでその名前の言語が定義され、言語を指定することで対応するフォントに切り替わるようになる。また、babelパッケージ読込時の規則と同様に、一番最後に書いたオプション(上の例の場合はjapanese)が基底言語と見なされる。(詳細はPXbaseバンドルの解説記事を参照。)
この目的で最低限必要なBabelの命令を挙げておく。
-
\foreignlanguage{<言語オプション>}{<テキスト>}:<テキスト>を指定の言語で出力する。 -
\begin{otherlanguage*}{<言語オプション>}<テキスト>\end{otherlanguage*}[環境]:環境内のテキストを指定の言語で出力する。 -
\selectlanguage{<言語オプション>}:使用言語を切り替える(以降のテキストを指定の言語で出力する)。切替は局所的(グルーピングに従う)である。
-
これを実行するには“プロポーショナル幅をもつ和文VFを作る”等の高度な技術が必要になる。かつて、実際にそのようなトリックを実験的に行っていた例が存在した。 ↩
-
SUBSET OF WITH NOT EQUAL TO/真部分集合2 ↩
-
半濁点付き平仮名か ↩
-
なお、ここでいう「フォント設定」とは所謂「論理フォント(TFM定義)」のことで、DVIウェアのフォントマップ設定とは無関係である。) ↩
-
従って、jsclassesやBXjsclsのクラスを使う場合は、クラスオプションで
uplatexを指定するのでパッケージ側のオプションは普通指定しない。標準クラスはそれ自身はuplatexを見ないが、その場合でもjapanese-otfのuplatexをクラスの側に指定することもできる。だから、「uplatexが必要なら必ずクラスの側につける」という習慣にしておくのもいいだろう。 ↩