これは「Pandoc Advent Calendar 2019」の8日目の記事です。
7日目は niszet0 さん 、9日目は skyy_writing さん です。
ご存じの通り、Markdownにおいては「入力における段落1内の改行は改行にならずに空白と解釈される」という規則があります2。例えば、次のようなMarkdown文書3があったとします。
All human beings are born free and equal
in dignity and rights.
They are endowed with reason and conscience
and should act towards one another
in a spirit of brotherhood.
これが表すのは次のような“改行のない1つの段落”です。もちろん、実際に出力される際には行長に応じて(「なりゆき」で)適宜改行が入ります。
All human beings are born free and equal in dignity and rights. They are endowed with reason and conscience and should act towards one another in a spirit of brotherhood.
このような「改行にならない改行」のことをMarkdownの用語4で「ソフト改行(soft line-break)」といいます。ソフト改行は“Markdownの思想”を実践する上で欠かせない大事な機能であることは疑いのないところでしょう5。ところが、日本語(のような単語間空白を用いない言語)のMarkdown文書においてソフト改行を使おうとすると「余計な空白が入る」という問題が発生します。
本記事では、この「余計な空白」問題のPandocでの解決方法について解説します。
※Pandocの2.x版を前提とします。(実際に使用しているのは2.8.0.1版。)
英語なMarkdownの場合
日本語文書の話の前に、まずは先に示した英語の文書について、Pandocでの変換の様子を調べてみましょう。
All human beings are born free and equal
in dignity and rights.
They are endowed with reason and conscience
and should act towards one another
in a spirit of brotherhood.
ますはHTMLに変換してみます。
pandoc sample-en.md -o sample-en.html
以下のように改行が消えて1行で出力されました。HTMLでも入力中の改行はソフト改行になるはずですが、PandocのHTML変換のデフォルトでは、ソフト改行が空白文字に置き換えられるようです。
<p>All human beings are born free and equal in dignity and rights. They are endowed with reason and conscience and should act towards one another in a spirit of brotherhood.</p>
もちろん、HTMLを実際に表示する際には「なりゆき」で改行が入ります6。

次に、同じMarkdown文書をLaTeX形式に変換してみます。
pandoc sample-en.md -o sample-en.tex
All human beings are born free and equal in dignity and rights. They are
endowed with reason and conscience and should act towards one another in
a spirit of brotherhood.

改行の入る位置が変わりました。もちろん、LaTeXでも改行はソフト改行なのでPDF変換した際の出力には影響せず、やはり出力は「なりゆき」で改行されます。
以上をまとめると、Pandocではソフト改行と空白文字を適宜相互に置き換えていることがわかりました。
日本語なMarkdownでHTMLするとアレ
それでは、いよいよ日本語の文書について考えてみましょう。
すべての人間は、生まれながらにして
自由であり、かつ、尊厳と権利とについて平等である。
人間は、理性と良心を授けられてあり、
互いに同胞の精神をもって行動しなければならない。
これをHTMLに変換します。
pandoc sample-ja1.md -o sample-ja1.html
<p>すべての人間は、生まれながらにして 自由であり、かつ、尊厳と権利とについて平等である。 人間は、理性と良心を授けられてあり、 互いに同胞の精神をもって行動しなければならない。</p>

※「にして␣自由で」「ある。␣人間は」「あり、␣互い」の箇所に空白がある。
先ほどと同様に1行で出力され、ソフト改行が空白文字に変換されました7。英語の場合はそれでよかったのですが、日本語ではこれらの空白が「余計」になってしまいます。
日本語なMarkdownでLaTeXしても結局アレ
今度はsample-ja1.mdをLaTeXに変換します。
pandoc sample-ja1.md -o sample-ja1.tex
出力のLaTeXソースは以下の通りです。入力と全く同じテキストになりました。
すべての人間は、生まれながらにして
自由であり、かつ、尊厳と権利とについて平等である。
人間は、理性と良心を授けられてあり、
互いに同胞の精神をもって行動しなければならない。

画像は「デフォルトのテンプレート+LuaLaTeX+bxjsarticleクラスのPandocモード」でPDFに変換した結果の出力。(以降、日本語文書のPDF変換には同じ設定を用いる。)
pandoc sample-ja1.md -o sample-ja1.pdf --pdf-engine=lualatex
-V documentclass=bxjsarticle -V classoption=pandoc
LaTeXでは8「行末に日本語の文字がある場合はソフト改行は空白にせずに無視する」という規則があるので、今の場合は(Markdown文書入力時の意図の通りに)ソフト改行は無視されて想定通りの出力が得られています。
ということは、LaTeXの場合は日本語でもソフト改行が自由に使えるのでしょうか? 残念ながら必ずしもそうとはいえません。入力のMarkdown文書のソフト改行の位置を変えたもので試してみます。
すべての人間は、生まれながらにして
自由であり、かつ、尊厳と権利とについて
平等である。
人間は、理性と良心を授けられてあり、
互いに同胞の精神をもって
行動しなければならない。
これをLaTeXに変換します。
pandoc sample-ja2.md -o sample-ja2.tex
結果は次の通りです。
すべての人間は、生まれながらにして
自由であり、かつ、尊厳と権利とについて 平等である。
人間は、理性と良心を授けられてあり、 互いに同胞の精神をもって
行動しなければならない。
※「ついて␣平等で」「あり、␣互い」の箇所に空白がある。

今度はソフト改行の一部が空白文字に変わってしまいました。やはり、Pandocは日本語文書の場合でもソフト改行と空白文字を適宜変換して出力ソースの行長を整えようとするようです9。LaTeXでも日本語文字の間にある空白文字はそのまま空白として扱われる10ため、今度は出力に「余計な空白」が生じてしまいます。
日本語なMarkdownで非アレにHTMLする方法
これまでにみた通り、“Markdownの思想”に則ってソフト改行を利用しようとすると、HTMLとLaTeXの場合でチョット事情は異なりますが、日本語文書に関しては「余計な空白」が出るというアレな結果になりました。幸いなことに、Pandocではこの問題に対処するための種々の設定が用意されています。
まずはHTMLへの変換について考えましょう。
“ignore_line_breaks”拡張:入力のソフト改行を無視する
HTML出力の場合、要するに「入力のソフト改行は空白」となります。しかし日本語文書の入力で意図しているのは「入力のソフト改行は無視される」のはずです。結局、Markdownの解析方法を変更する必要があるわけです。
Pandoc’s Markdownの拡張のignore_line_breaksを有効にすると、まさにその「入力のソフト改行は無視される」という規則が適用されます。
pandoc -f markdown+ignore_line_breaks sample-ja1.md -o sample-ja1i.html
※入力形式(-f)をデフォルトのmarkdownからmarkdown+ignore_line_breaks(ignore_line_breaksを有効にしたPandoc’s Markdown)に変更しています。
<p>すべての人間は、生まれながらにして自由であり、かつ、尊厳と権利とについて平等である。人間は、理性と良心を授けられてあり、互いに同胞の精神をもって行動しなければならない。</p>
「余計な空白」がなくなって、想定通りの結果が得られました。
ただし、この方法には問題があります。「入力のソフト改行は無視される」という規則はいつでも適用できるわけではありません。入力が英語の場合は空白が入らないと不適切ですし、たとえ日本語文書であっても、中に部分的に英語(などの欧文)が含まれている場合は、その箇所には空白が必要でしょう。
世界人権宣言(Universal Declaration
of Human Rights)はすべての人民とすべての国が
達成すべき基本的人権についての宣言である。
この文書をignore_line_breaks付きでHTMLに変換すると次のようになります。本来Declaration␣ofであってほしいところが空白が欠けてしまいます。
<p>世界人権宣言(Universal Declarationof Human Rights)はすべての人民とすべての国が達成すべき基本的人権についての宣言である。</p>
“east_asian_line_breaks”拡張:入力のソフト改行を“いい感じ”に無視する
ignore_line_breaks拡張の欠点を解決したのがeast_asian_line_breaks拡張です。これを有効にすると、日本語文字11どうしの間にあるソフト改行だけが無視されて、それ以外のソフト改行は通常通り処理される(HTML出力の場合は空白文字になる)ようになります。
先ほどの“英語混じり”の日本語文書sample-ja3.mdをこの拡張を有効にして変換してみましょう。
pandoc -f markdown+east_asian_line_breaks sample-ja3.md -o sample-ja3e.html
<p>世界人権宣言(Universal Declaration of Human Rights)はすべての人民とすべての国が達成すべき基本的人権についての宣言である。</p>
完璧な出力が得られました!
チョット補足
- この節で紹介したMarkdown拡張を用いる方法は、HTML出力以外でも「そもそもソフト改行をサポートしない出力形式」(Word・textileなど)や「ソフト改行が必ず空白として解釈される出力形式」(reSTなど)でも同様に利用できます。
- 入力形式はMarkdownに限られます。ただし、
east_asian_line_breaks拡張はPandoc’s Markdown(markdown)以外のMarkdown変種(commonmarkやmarkdown_strictやgfmなど)でも利用できます12。 -
east_asian_line_breaks拡張では「日本語文字と非日本語文字の間にあるソフト改行」は無視されません。そのような箇所に空白を入れたくない人13は、文書の入力において適宜改行位置を調整しましょう。
日本語なMarkdownで非アレにLaTeXする方法
east_asian_line_breaks拡張自体はLaTeX出力の場合にも利用できますが、LaTeXのようにそれ自身が「ソフト改行を無視する規則」をもつ出力形式を使う場合は、次の2つの過程が同時におきて複雑になってしまいます。
- Pandocが自身の規則でソフト改行の一部を無視する。
- LaTeXが自身の規則でソフト改行の一部を無視する。
特に、日本語LaTeXのソフト改行の規則を熟知している人から見ると、「Pandocの規則」に基づく処理は想定外の結果と捉えられることがあるでしょう。
例えば次のような例を考えます。
世界人権宣言は
1948年12月10日に採択された。
LaTeXの規則としては「直前が日本語文字であるソフト改行は無視される」ことになるので、宣言はと1948年の間には空白文字は入らない14ことが期待されます。ところが、実際にPandocで変換した結果は次のようになります。
pandoc -f markdown+east_asian_line_breaks sample-ja4.md -o sample-ja4e.tex
世界人権宣言は 1948年12月10日に採択された。
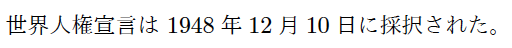
※east_asian_line_breaksの規則では宣言はと1948年の間のソフト改行は保持されます。そしてPandocが行長を整えるためにソフト改行を空白文字に置き換えるので、結局LaTeXの入力に空白が入ることになります。
そもそもここで問題を起こしているのは「Pandocがソフト改行と空白文字との間で相互変換を行う」ことであり、LaTeXの規則を知る人から見ると、一番好ましいのは「ソフト改行がそのままLaTeXのソフト改行として保持される」ことであるはずです。
--wrap=perserve:入力のソフト改行をLaTeXソース出力で保持する
Pandocの「ソフト改行と空白文字の相互変換」に関する挙動は--wrapオプションで制御できます15。
--wrapは引数をとるオプションです。デフォルトは--wrap=autoでこの場合は「行長を整えるためにソフト改行と空白文字との間で相互変換を行う」処理が有効になります。そして、--wrap=preserveを指定すると、相互変換が抑止されて「入力のソフト改行と空白文字は出力(のソース)中でもそのまま保持される、つまりソフト改行と空白文字として出力される」という動作になります。
先の例のsample-ja4.mdを--wrap=preserveを付けて変換してみましょう。
pandoc --wrap=preserve sample-ja4.md -o sample-ja4p.tex
※「Pandocがソフト改行を無視する」という動作はもはや不要であるため、east_asian_line_breaks拡張は指定しません。
世界人権宣言は
1948年12月10日に採択された。
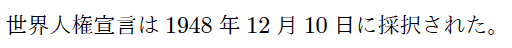
文字だけからなるMarkdown文書であるため結果的に入力と全く同じ出力となりました。「入力したそのまま」のソフト改行が反映されるので、LaTeXユーザが理解しやすい動作になっていることがわかります。
「日本語なMarkdownでLaTeXしても結局アレ」の節で失敗していたsample-ja2.mdも同様に変換してみましょう。容易に予想されるように、この場合も入力と出力は全く同じになります。
pandoc --wrap=preserve sample-ja2.md -o sample-ja2p.tex
すべての人間は、生まれながらにして
自由であり、かつ、尊厳と権利とについて
平等である。
人間は、理性と良心を授けられてあり、
互いに同胞の精神をもって
行動しなければならない。
完璧な出力が得られました!
まとめ
- HTMLする場合は →
-f markdown+east_asian_line_breaksを付ける。 - LaTeXする場合は →
--wrap=preserveを付ける。
皆さんも “Markdownの思想”に則った日本語Markdown文書をドンドンつくりましょう!
-
原則として、Markdownでは文章を空行で区切った各々の部分が段落となります。 ↩
-
異論については冷蔵庫に入れてカチカチにしちゃいましょう。 ↩
-
文章は「世界人権宣言」の第1条です。 ↩
-
正確には「Commonmarkの用語」ないしは「Pandocの用語」なのでしょう。 ↩
-
異論については冷蔵庫に入れてカチカチにしちゃいましょう。 ↩
-
画像はデフォルトのHTMLテンプレートを適用した結果の単体HTML文書の表示結果です。 ↩
-
ちなみに、仮に、ソフト改行が空白文字に変換されずに「HTMLのソフト改行」のままであったとすると、一部のブラウザ(Firefox)では「日本語文章中のソフト改行は空白にせずに無視する」という処置が行われます。この場合は「余計な空白」のない正常な表示が得られます。 ↩
-
正確にいうと「まともな日本語処理用設定が施されているLaTeXでは」。 ↩
-
ただし、元々空白もソフト改行もない箇所に新たに空白やソフト改行を入れることはありません。(英語の文書でそれをやると単語を途中で切ってしまうことになります。)なので、空白を入れない日本語文書の場合は“組み換え”の可能性がかなり限られます。sample-ja1.mdでは各行がある程度の長さを持っていたため“組み換え”ができずにそのまま出力されたわけです。 ↩
-
ただし、XeLaTeX(+zxjatype)の場合は日本語文字の間にある空白文字も無視されます。でもXeLaTeXはアレなのでやっぱりLuaLaTeXを使いましょう。 ↩
-
どの文字が「日本語文字」と見なされるかについては調べ切れていません。多分、何かのUnicodeの規定に従うのでしょうけど。 ↩
-
PandocがサポートするMarkdown変種には
markdown(Pandoc’s Markdown)とcommonmark(CommonMark)の2系統があります。markdown_phpextra、markdown_mmd、markdown_strictは“markdownの拡張の既定の有効状態を変更したもの”であり、gfmは“commonmarkの拡張の既定の有効状態を変更したもの”です。east_asian_line_breaks拡張は両方の系統でサポートされていますが、ignore_line_breaks拡張はmarkdownの系統でのみサポートされています。 ↩ -
HTMLを書く際に「日本語文字と非日本語文字の間に空白文字を入れる」という流儀の人もいます。 ↩
-
ここで「空白文字は入らない」というのは「LaTeXの入力ソースとして空白文字は入らない」ということです。LaTeXの組版処理においては「宣言は1948」のように日本語文字と非日本語文字が隣接している場合はそこに自動的に狭い空白(四分空き)を入れます。一方で「宣言は␣1948」の入力の場合は空白文字の位置に通常の欧文空白(幅は欧文フォントにより異なる)を入れることになりますが、この文章についてはそのような入力は一般には不適切でしょう。 ↩
-
もちろん出力形式がソフト改行をサポートしないものである場合は
--wrapの指定は無意味で常に「ソフト改行を空白に変換する」動作になります。また現状では、HTML出力の場合も同じ動作になるようです。 ↩