簡単なプログラムを作ってみました
まずはプログラムを作ってみたいので、UTF-8文字列をCP932文字のバイト配列へ変換するプログラムを作成してみました。作成したプログラムはここにアップしました。
変換表の考え方
UTF-8 から CP932 へ変換するのに、私は UTF-8 から UTF-16、その後、CP932へ変換します。UTF-8 から UTF-16 は計算式で変換できるのですが、UTF-16 から CP932 へ変換するには簡単な計算式はありません。コード値を紐付けるための変換表が必要になります。今回はこの変換表を配列で作成しました(変換テーブルはThe Unicode Consortiumからいただきました)
配列の宣言は、
let to_group: [u8; 1024];
; で型をサイズを区切って宣言するのですね。: と良く間違えるのですが、その都度、間違いを丁寧に指摘してもらえるので修正は楽です。
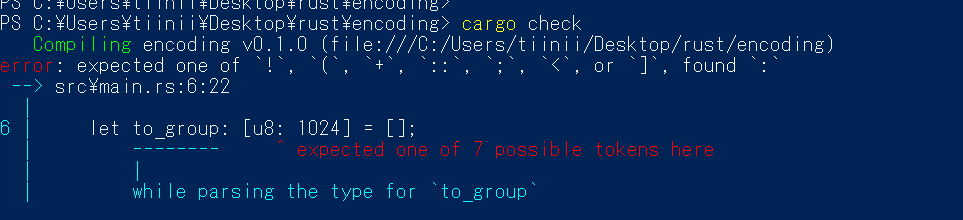
ドキュメントに記述のあった cargo check コマンドは文法チェックのみしてくれるので、少し記述したらチェックを繰り返すのに便利でした。
UTF-16 と CP932で共通で使用できる文字は 16bit長なので 65536 ^ 2 の配列を作成すれば簡単に実装できるのですが、折角なので、大分類用テーブル、値を保持するテーブルと二段階に分けて実装してみました。
イメージとして変換元値の上位数ビットで大分類テーブルから値を保持するテーブルの識別値を取得し、下位数ビットを検索キーにして値を保持するテーブルから変換値を取得する。という処理です。
ビット演算は、以下のようなコードになります。
*ptr.offset(i+0) as u32 & 0x3f
左シフト(<<)、右シフト(>>)が使えるところなど、C/C++と構文が一緒なので、覚えやすかったです。
アプリケーションの実行
アプリケーションに「あいうえお123漢字」を与えて実行した結果は、以下のとおりです。

最後に
Rust はコンパイルを通すまでが結構大変という意見が多く、コードを書くまでは心配していましたが、コンパイラのメッセージは親切で修正はしやすく感じます。
公式ドキュメントにあるように、まずは 「コンパイラを味方にする」 ことから始めるべきでしょう。