はじめに
この記事はNTTテクノクロス Advent Calendar 2018の14日目の記事です。
NTTテクノクロスの西園 直人です。
普段はElastic Stackの一般企業への導入支援や、社内PJの技術支援などを担当しています。
NTTテクノクロスの公式ブログでもElasticな仲間たちと共に不定期にElastic Stack関連のブログを投稿しています。
さて、今回はElastic StackのAlertingを使用した際に、はまったことと、その対処方法について紹介します。
Alertingとは
Elasticsearchに格納されたインデックスについて、データの変更や異常を監視し、それに応じて必要なアクション(メールやSlackでの通知など)を実行する機能です。
Watch(監視ルール)と呼ばれる監視ルールを定義するルールベースの監視だけでなく、機械学習と組み合わせたルールベースでは難しいデータの変化に着目した監視も実現可能です。
Alertingはゴールド以上のサブスクリプション、機械学習はプラチナサブスクリプションで使用可能な機能となっています。
今回は1月間無償でElastic Stackの全機能を使用可能な、トライアルサブスクリプションを使用して動作確認をしています。

上記Kibana画面1のWatcherからUIベースで監視ルールの追加と動作確認が可能となっています。
Watchについて
Watchは大きく分けて以下の5つの要素で構成されています。
| 構成要素 | 説明 |
|---|---|
| Trigger | Watchの実行タイミングを規定 |
| Input | 監視対象とするデータの取得方法を規定 |
| Condition | Inputで取得したデータから、Actionを実施するかどうかの識別・制御ルールを規定 基本的には監視対象のインデックスへ検索クエリを実行して情報を取得する |
| Transform | Inputで取得したデータをActionsで利用するための処理を規定 Inputで取得したデータの整形等が必要ない場合は設定する必要はない |
| Actions | Conditionで規定した識別・制御ルールを満たした場合の実行内容を規定 |
今回定義するWatch
今回は以下のようなお題でWatchを作成します。
少々複雑なルールとなるため、UIで簡単に作成可能なthreshold alertではなく、json形式で規定するadvanced watchで作成しています。
- 監視対象のインデックス: 複数台のホストで動作するApache2のログデータが含まれるインデックス
- Watch:
- Apache2のインデックスを5分ごとに監視
- 各ホストごとに過去5分間で5xx系のレスポンステータスがいくつ発生しているか集計
- 各ホストのいずれかで5xx系のレスポンステータスが20件以上発生していた場合、20件以上発生しているホストを抽出
- Elasticsearchの動作ログに、20件以上発生しているホスト名と発生件数を出力する
上記のWatchを先程の構成要素に分割すると、以下のようになります。
| 構成要素 | 説明 |
|---|---|
| Trigger | 5分ごとに監視 |
| Input | Apache2のインデックスについて、各ホストごとに過去5分間で5xx系のレスポンステータスがいくつ発生しているか集計 |
| Condition | 各ホストのいずれかで5xx系のレスポンステータスが20件以上発生しているか確認 |
| Transform | 20件以上発生しているホストを抽出 |
| Actions | Elasticsearchの動作ログに、20件以上発生しているホスト名と発生件数を出力 |
使用したElastic Stackのバージョンとデータの流れ
元々の実験では以下のElastic Stackのコンポーネントとバージョンを使用しています。
※本記事を執筆時時点での最新バージョンは6.5.3となっており、後ほど記載するWatchの最終形は当該バージョンでも動作することを確認しています。
- Elasticsearch: 6.3.2
- Kibana: 6.3.2
- Filebeat: 6.3.2
データの流れはシンプルにとなっています。
Filebeat(Apache2と同居) -> Elasticsearch <- Kibana
インデックス設定
Apache2ログのMappingを含むインデックス設定はFilebeatのApache2モジュールの設定をそのまま流用しています。
今回使用するフィールドは以下となっています。
-
@timestamp: ログ出力時間を格納したフィールド。このフィールドを時系列データとして使用 -
apache2.access.response_code: Httpレスポンステータス -
host.name: Filebeat(Apache2)のホスト名
はまったこと
今回はまったことは以下となります。
- 監視漏れとなるデータが存在しない監視間隔
- 5xx系の発生件数が20件を超えていることの確認
- 20件以上発生しているホストを抽出してログ出力
上記のはまりポイントの詳細と対処方法について、以降紹介していきます。
1. 監視漏れとなるデータが存在しない監視間隔
5分間隔での監視実行そのものは、以下のようにTriggerを設定すれば実現できます。
"trigger": {
"schedule": {
"interval": "5m"
}
},
ボツ案
5分間のインデックス確認も単純に考えれば以下のように設定すればよいと考えていました。
"input": {
"search": {
"request": {
"indices": ["filebeat-*"],
"body": {
"size": 0,
"query": {
"bool": {
(中略)
"filter": {
"range": {
"@timestamp": {
"gte": "now-5m" <- 検索クエリ実行時刻の5分前より後のインデックスを対象
}
}
}
}
},
ただし、今回実現したいのはあくまでも、5分間隔で対象のインデックスを漏れなく監視することです。
上記の設定では、Elasticsearchへの負荷が一時的に大きくなり、きっちり5分間隔で監視が実行できなかった場合、監視漏れとなるデータが発生する可能性があります。(実際に実験で漏れが発生しました)
例えば、前回の監視実行から5分30秒後に監視の検索クエリが実行された場合、30秒分のデータが監視対象から漏れてしまいます。
改善案
では、漏れなく監視するためにはどう設定すればよいのでしょうか?
その肝はinputの検索クエリが検索対象とするデータの時間範囲にあります。
今回使用するsearch inputは複数の属性を持っており、その中には時間に関わる属性が存在します。
| 属性 | 説明 |
|---|---|
| ctx.execution_time | Watchの実行時刻 |
| ctx.trigger.triggered_time | Watchのtriggerが実行された時刻ctx.execution_timeとほぼ同一 |
| ctx.trigger.scheduled_time | Watchのtriggerの実行予定時刻 |
ctx.execution_time、または、ctx.trigger.triggered_timeを使用すると、now-5mと指定した場合と同じ問題をはらみます。
ctx.trigger.scheduled_timeを使用すると、triggerで指定した実行間隔を元に決定されるため、検索範囲がぶれることはなく、漏れなく監視が可能となります。
以下は、修正版となります。
"input": {
"search": {
"request": {
"indices": ["filebeat-*"],
"body": {
"size": 0,
"query": {
"bool": {
(中略)
"filter": {
"range": {
"@timestamp": {
"gte": "{{ctx.trigger.scheduled_time}}||-5m" <- Watchのtriggerの実行予定時刻の5分前より後のインデックスを対象
}
}
}
}
},
2. 5xx系の発生件数が20件を超えていることの確認
各ホストごとの5xx系のレスポンステータスの発生件数は、aggregationを使用した検索クエリで取得することができます。
"input": {
"search": {
"request": {
"indices": ["filebeat-*"],
"body": {
"size": 0,
"query": {
"bool": {
"should": [ <- レスポンステータスが500, 501, 503のいずれかであるドキュメントを抽出
{"term": {"apache2.access.response_code": "500"}},
{"term": {"apache2.access.response_code": "501"}},
{"term": {"apache2.access.response_code": "503"}}
],
"minimum_should_match": 1, <- レスポンステータスが500, 501, 503のどれか一つに合致すればよい
"filter": {
"range": {
"@timestamp": {"gte": "{{ctx.trigger.scheduled_time}}||-5m"}
}
}
}
},
"aggs": {
"apache2_alert": { <- 5xx系の発生件数をホスト単位で集計
"terms": {
"field": "host.name",
"size": 50
}
}
}
}
}
}
},
上記の検索は以下のようなレスポンスが返ります。
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 219,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"apache2_alert" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ <- 検索条件に合致するドキュメントについて、ホスト単位でその数を降順に並べてリストで返す。
{
"key" : "apache2.local", <- ホスト名
"doc_count" : 216 <- 合致したドキュメント数
},
{
"key" : "apache1.local",
"doc_count" : 3
}
]
}
}
}
では、検索クエリの結果をどのように使用すれば、いずれかのホストで20件以上の発生を確認できるのでしょうか?
ボツ案
真っ先に考えついたのは、「5xx系の発生件数が最も多いホストについて、20件以上となることを確認すればよいのでは?」という案でした。
conditionの設定は以下のようになります。
"condition": {
"compare": {
"ctx.payload.aggregations.apach2_alert.buckets.0.doc_count": { <- ctx.payloadがinputの実行結果が格納されるネームスペースで、aggregations.apach2_alertにaggregationの結果が格納される。さらに、buckets.0に5xx系の発生件数が最も多いホスト名とその件数が格納される。
"gte": 20
}
}
},
結論から言うと、「5xx系の発生件数が最も多いホストについて、20件以上となることを確認」は満たすことができました。
しかし、ある条件となったとき、Watchの実行が失敗し、エラーが発生してしまいます。
その条件とは、「5xx系の発生件数が全ホストで0件だった場合」です。以下は当該条件となった場合のレスポンスです。
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 0, <- 1つもヒットなし
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"apache2_alert" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ] <- aggregationの結果の配列が空となる
}
}
}
5xx系のレスポンステータスが発生していないため、ホストごとの集計結果の配列は空になります。
ボツ案のconditionでは空の配列の要素へアクセスしようとするため、Watchの実行が失敗してしまいます。
※なお、6.5.3ではこのエラーは発生しなくなっています。
改善案
さて、ボツ案をどのように改善したかというと、conditionでの条件比較を修正しました。
ボツ案ではconditionでcompareというある一つの要素に注目した比較を使用していました。
改善案ではこれをarray_compareという配列全体の要素に対して比較できる方法を使用しました。
改善案では、「最低1つ以上のホストで、5xx系が20件以上発生しているか」という条件を採用しています。
conditionの設定は以下のようになります。
"condition": {
"array_compare": {
"ctx.payload.aggregations.apache2_alert.buckets": { <- aggregationの結果が格納された配列全体を確認対象とする
"path": "doc_count", <- 比較する要素名
"gte": {
"value": 20 <- 閾値は変わらない。また、どれか一つのホストで閾値を超えればactionは実行される
}
}
}
},
3. 20件以上発生しているホストを抽出してログ出力
compareの条件に合致した際に、Elasticsearchの動作ログにシンプルな情報を出力するのであれば、以下のようなactionsの定義で十分です。
"actions": {
"apache2-logging-action": {
"logging": {
"level": "info",
"text": "A number of errors exceeding the threshold occurred in Apache2." <- 任意のメッセージを定義
}
}
}
ただし、上記ではエラー情報としては全く足りていません。
閾値を超えるエラーが発生したならば、最低限どのホストで何件のエラーが発生したのかという情報がほしくなります。
では、どのようにして情報を抽出して、actionsに渡せばよいのでしょうか?
そのような時に使用するのがtransformになります。
transformでは、inputの検索リクエストの結果を加工・整形してactionsにわたすことができます。
今回は、5xx系の発生件数をホスト単位で集計したaggregation apache2_alertの情報を加工・整形して、actionsにわたす方法を検討しました。
また、transformの中では、情報の加工のために、script機能を使用しました。
まず、transform内で使用するスクリプトをElasticsearchに事前登録します。
PUT _scripts/extract-buckets-above-threshold
{
"script": {
"lang": "painless",
"source": """
StringJoiner keys = new StringJoiner(', ');
for(bucket in ctx.payload.aggregations.apache2_alert.buckets) {
if(bucket.doc_count >= params.threshold) {
keys.add(bucket.key + ':' + bucket.doc_count)
}
}
return ['keys': keys.toString()]
"""
}
}
上記のスクリプトでは、aggregation apache2_alertの結果について、閾値を超えたbucketのホスト名とその件数の抽出した上で、ホスト名と件数を1つの組み合わせとし、コンマで結合した文字列keysを生成・返却しています。
例. apache2.local:25, apache3.local:21
上記のスクリプトをtransform内で、以下のように閾値をパラメータとして与えて呼び出します。
※本来ならctx.payload.aggregations.apache2_alert.bucketsもパラメータとして与えたかったのですが、変数展開っぽいことができず、断念しました。
"transform": {
"script": {
"id": "extract-buckets-above-threshold",
"params": {
"threshold": 20
}
}
},
transformで加工・整形した情報をactionsで、以下のように使用します。
"actions": {
"apache2-logging-action": {
"logging": {
"level": "info",
"text": "A number of errors exceeding the threshold occurred in Apache2. hosts - {{ctx.payload.keys}})
" <- {{ctx.payload.keys}}にactionsで生成した文字列が格納されている。
}
}
}
Watchの最終形
さて、長くなりましたが以下が作成したWatchの最終形となっています。
{
"trigger": {
"schedule": {
"interval": "5m"
}
},
"input": {
"search": {
"request": {
"indices": ["filebeat-*"],
"body": {
"size": 0,
"query": {
"bool": {
"should": [
{"term": {"apache2.access.response_code": "500"}},
{"term": {"apache2.access.response_code": "501"}},
{"term": {"apache2.access.response_code": "503"}}
],
"minimum_should_match": 1,
"filter": {
"range": {
"@timestamp": {"gte": "{{ctx.trigger.scheduled_time}}||-5m"}
}
}
}
},
"aggs": {
"apache2_alert": {
"terms": {
"field": "host.name",
"size": 50
}
}
}
}
}
}
},
"condition": {
"array_compare": {
"ctx.payload.aggregations.apache2_alert.buckets": {
"path": "doc_count",
"gte": {
"value": 20
}
}
}
},
"transform": {
"script": {
"id": "extract-buckets-above-threshold",
"params": {
"threshold": 20
}
}
},
"actions": {
"apache2-logging-action": {
"logging": {
"level": "info",
"text": "A number of errors exceeding the threshold occurred in Apache2. hosts - {{ctx.payload.keys}}"
}
}
}
}
動作確認
上記をWatchのEditに貼り付けて、Simulateから動作確認します。
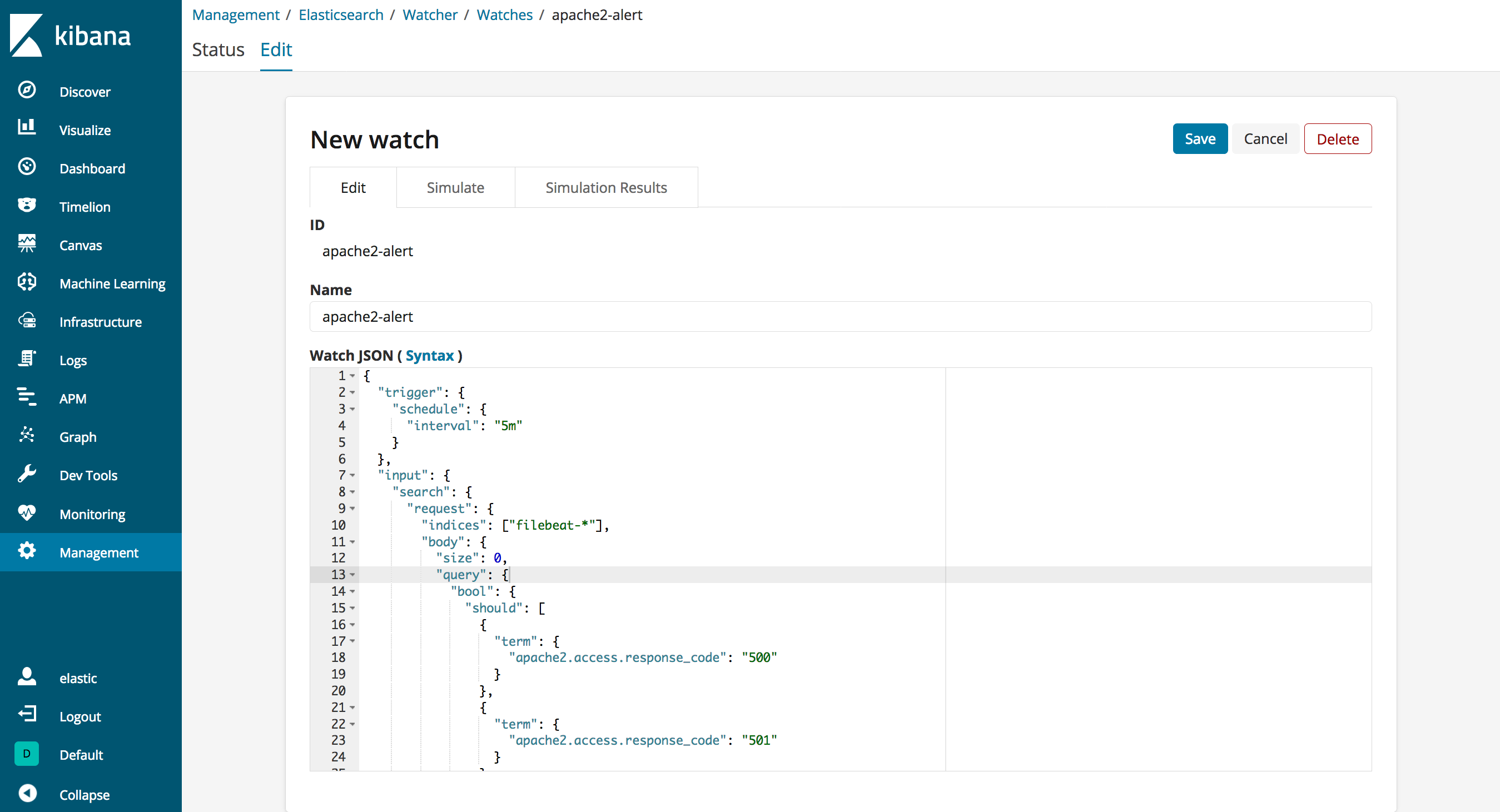
5xx系が閾値以上発生していない場合は、以下のようにstatusがOKとなり、transformとactionsは実行されません。

5xx系が閾値以上発生している場合は、以下のようにstatusがFiringになり、Elasticsearchの動作ログに情報が出力されます。
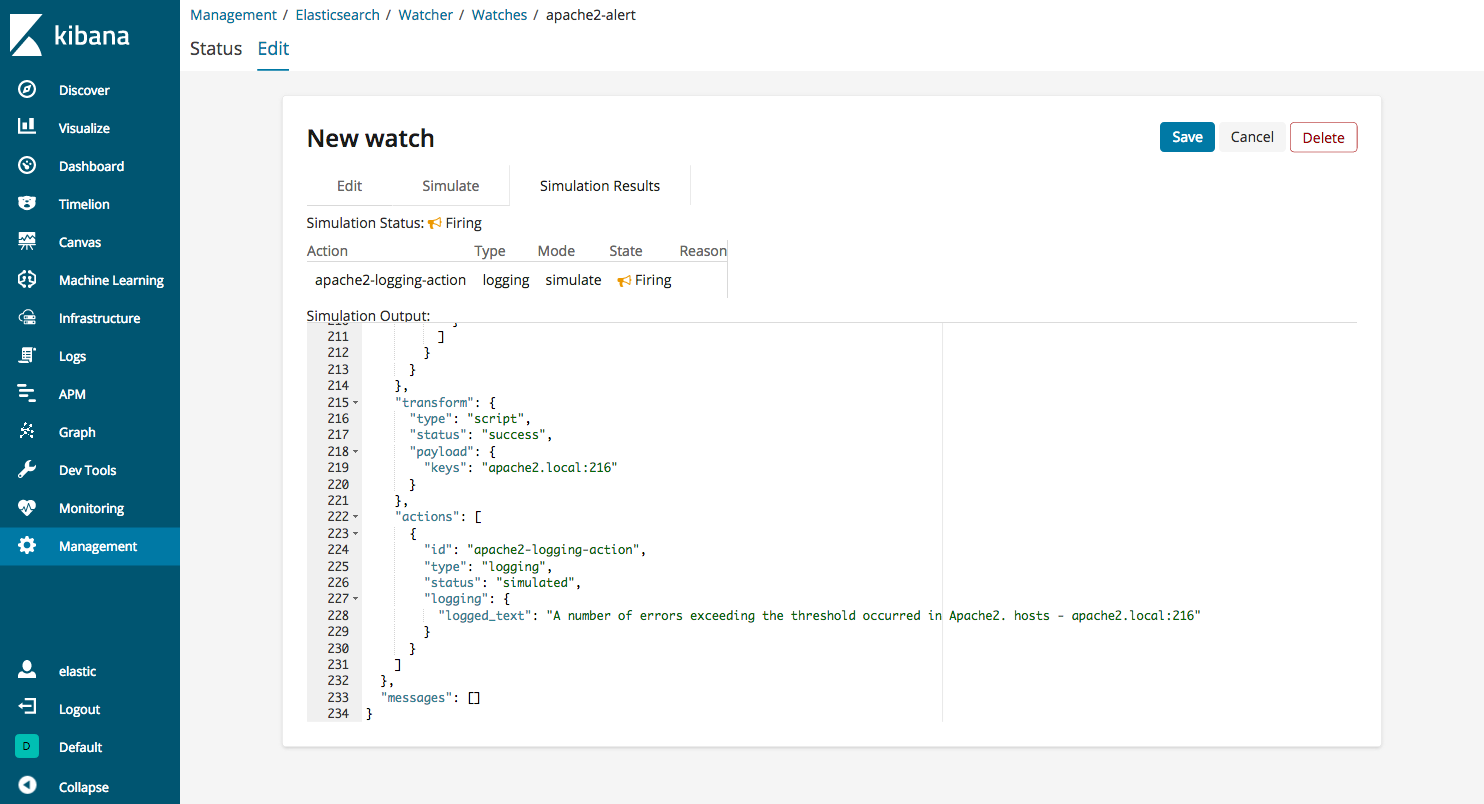
[2018-12-09T19:12:20,541][INFO ][o.e.x.w.a.l.ExecutableLoggingAction] [node-1] A number of errors exceeding the threshold occurred in Apache2. hosts - apache2.local:216
おわりに
柔軟に監視ルールが定義可能なAlertingですが、使いこなすためには幅広いElasticsearchに関する知識が必要です。
本記事がAlertingを使う誰かの一助となれば幸いです。
引き続き、NTTテクノクロス Advent Calendar 2018もお楽しみください。
明日の担当は、@manji0 さんです。
p.s. NTTテクノクロスの公式ブログも更新速度上げていきます。
-
目ざとい方はお気づきかと思いますが、このKibanaの画面は現在開発中の6.6.0のものとなっています。自前でビルドしちゃったので、ついでに載せちゃいました(^o^) ↩