はじめに
MeCabは気軽に形態素解析できるのですがIPA辞書では上手く切れない事も多いですよね。
NEologdの辞書もありますが、化合物(化学物質)となると中々難しそうです。
JSTのJ-GLOBAL(旧:日本化学物質辞書)のデータから作成した
MeCab用の化合物辞書が有る事をアジア特許情報研究会の方に教えて頂きました。
早速R、PythonのMeCabで化合物の辞書が使えるように実装してみました。
環境
Windows10 64bit 言語:日本語
R 3.5.2 64bit
RStudio 1.1.463
MeCab 0.996-32bit
RMeCab 1.00
Python 3.6.8(anaconda3 5.3.0) 64bit
フォルダ構成
こちらのMeCabのフォルダ構成は以下の通りです。()内はショート形式の記載。
異なる場合はコードを適宜書き換えてください。
MeCab.exe
C:\Program Files (x86)\MeCab\bin\mecab.exe
(C:\PROGRA~2\MeCab\bin\mecab.exe)
IPA辞書フォルダ-SHIFT-JIS形式
C:\Program Files (x86)\MeCab\dic\ipadic
(C:\PROGRA~2\MeCab\dic\ipadic)
IPA辞書フォルダ-UTF-8形式
C:\Program Files (x86)\MeCab\dic\ipadic-UTF8
(C:\PROGRA~2\MeCab\dic\IPADIC~1)
導入方法
mecab_nikkaji.csvファイルの準備
csv辞書ファイルの入手
生命科学系データベースアーカイブの科学技術用語形態素解析辞書
https://dbarchive.biosciencedbc.jp/jp/mecab/desc.html
この中の日化辞辞書
https://dbarchive.biosciencedbc.jp/jp/mecab/data-3.html
より圧縮されたcsvフォーマットファイル(mecab_nikkaji.zip)をダウンロード。
zipファイルを展開しcsvファイルを作業フォルダに移動
mecab_nikkaji.zipを展開して出来た mecab_nikkaji.csvファイルを"C:"に置きます。
SHIFT-JISのシステム(RMeCab、Windows等)に実装
SHIFTーJIS辞書の作成
コマンドプロンプトを**管理者として(←ここ大事)**起動します。
以下のコマンドで
Cドライブにおいたmecab_nikkaji.csvファイルからSHIFT-JIS形式のNikkaji.dicファイルを作成し、
dicファイルを辞書フォルダ(C:\Program Files\MeCab\dic\ipadic)に移動します。
cd "C:\Program Files (x86)\MeCab\bin"
mecab-dict-index.exe -d "C:\Program Files (x86)\MeCab\dic\ipadic" -u Nikkaji.dic -f shift-jis -t shift-jis C:\mecab_nikkaji.csv
move Nikkaji.dic "C:\Program Files (x86)\MeCab\dic\ipadic"
ユーザー辞書の指定
C:\Program Files (x86)\MeCab\etcのmecabrcをエディタで開き以下を追加します。
userdic=C:\Program Files (x86)\MeCab\dic\ipadic\Nikkaji.dic
UTF-8のシステム(Python等)に実装する場合
UTF-8辞書の作成
PythonからMeCabを使われている方は以下の手順でUTF-8の辞書を作成も行います。
以下のコードでCドライブにおいたmecab_nikkaji.csvファイルからUTF-8形式のNikkaji-u.dicファイルを作成し、
dicファイルをUTF-8辞書フォルダ(C:\Program Files\MeCab\dic\ipadic-UTF8)に移動します。
cd "C:\Program Files (x86)\MeCab\bin"
mecab-dict-index.exe -d "C:\Program Files (x86)\MeCab\dic\ipadic-UTF8" -u Nikkaji-u.dic -f shift-jis -t UTF-8 C:\mecab_nikkaji.csv
move Nikkaji-u.dic "C:\Program Files (x86)\MeCab\dic\ipadic-UTF8"
動作確認
SHIFT-JIS辞書の確認
コマンドプロンプトから
以下のコマンドをコマンドプロンプトで実施して確認します。
cd "C:\Program Files\MeCab\bin"
mecab
(アミノメチレン)ビスホスホン酸を合成することとなった。
出力結果
RStudioから
一応RStudioでもうまく行く事を確認しておきます。
library(RMeCab)
unlist(RMeCabC("(アミノメチレン)ビスホスホン酸を合成することとなった。"))
出力結果

UTF-8辞書の確認
以下のコードでPythonを用い確認を行います。
import MeCab
m=MeCab.Tagger("-d C:/PROGRA~2/MeCab/dic/ipadic~1 -u C:/PROGRA~2/MeCab/dic/ipadic~1/Nikkaji-u.dic")
print(m.parse ("(アミノメチレン)ビスホスホン酸を合成することとなった。"))
出力結果
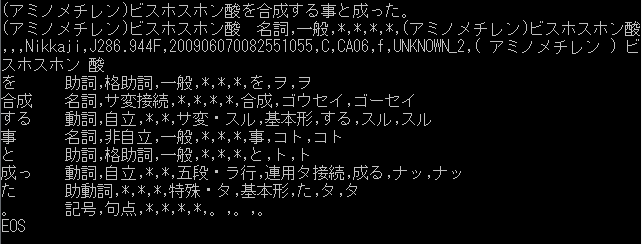
(アミノメチレン)ビスホスホン酸
名詞,一般,,,,,(アミノメチレン)ビスホスホン酸,,,Nikkaji,J286.944F,200906070082551055,C,CA06,0,UNKNOWN_2,(
アミノメチレン ) ビスホスホン 酸
を 助詞,格助詞,一般,,,,を,ヲ,ヲ
合成 名詞,サ変接続,,,,,合成,ゴウセイ,ゴーセイ
する 動詞,自立,,,サ変・スル,基本形,する,スル,スル
こと 名詞,非自立,一般,,,,こと,コト,コト
と 助詞,格助詞,一般,,,,と,ト,ト
なっ 動詞,自立,,,五段・ラ行,連用タ接続,なる,ナッ,ナッ
た 助動詞,,,,特殊・タ,基本形,た,タ,タ
。 記号,句点,,,,,。,。,。
EOS
UTF-8辞書を-rオプションでmecabrcファイルで指定する方法(2019/1/27追記)
MeCab.Taggerに-rオプションでmecabrcファイルを指定できることが分かりました。
この場合以下のように指定します。
"C:\Program Files (x86)\MeCab\etc"にUTF-8用IPA辞書, Nikkaji辞書を以下のように指定したmecabrc-uファイルを作成。
dicdir = C:\Program Files (x86)\MeCab\dic\ipadic-UTF8
userdic=C:\Program Files (x86)\MeCab\dic\ipadic-UTF8\Nikkaji.dic
MeCabrc-uファイルを指定してMeCabを呼び出し形態素解析。
この場合のフォルダの区切りは"/"ではなく""で。
import MeCab
m=MeCab.Tagger("-r C:\progra~2\MeCab\etc\mecabrc-u")
print(m.parse ("(アミノメチレン)ビスホスホン酸を合成することとなった。"))
PythonでのMeCabの実装は先の以下投稿をご覧ください。
https://qiita.com/zincjp/items/55960801d99e55c9f2a6
おまけ
研究会内から品詞2が"一般"となっているのが残念との声が出てきました。
確かに、他の名詞と同じ"一般"だと形態素解析して化学物質だけ取り出すことが難しくなります。
辞書作成元のcsvファイルの"POS subcategory 1"列(Excelで開くとF列)の
"一般"を"化合物"に置換してから辞書を作成する事で、
品詞詳細が"化合物"になり後の解析で便利になりそう。
→自分はこの方式で辞書を作成しています。
謝辞
本検討はアジア特許情報研究会の活動の一環で行いました。
http://www.geocities.jp/patentsearch2006/asia-research.html