前書き
時間方向にコンシステントな物体認識方法を考えている時に見つけて面白そうだったので,要点整理しつつZMに実装してみました.オリジナル文献はこちらです.
- Bernd Fritzke, A Growing Neural Gas Learns Topology, in Proceedings of the 7th International Conference on Neural Information Processing Systems, pp. 625--632, 1994.
本記事で紹介しているアルゴリズムは,上記文献に示されているものよりも少しだけ効率が良くなっています.
Neural Gasが表現するもの
Neural Gasとは不思議な名前ですが,一般的なニューラルネットと違いネットワークを構成するノードやエッジが計算過程で拡大・揮発するため,このように名付けられているようです.
ある未知のシステムを観測したとき,なんらかの確率分布に従って標本群$\mathcal{X}=\{\boldsymbol{x}_{i}\}$($i=1,\cdots,N$)が得られるとします.たとえば床に箱が幾つか置かれたシーンを3次元計測した際,箱や床の表面付近の点が高確率で観測されるような状況です.この標本群からシステムがどのような形状をしているか推定したい,しかも単なる点群としてではなく,システムの位相構造(トポロジー,上記の例では箱の隣接関係)も知りたいという場合に使えるよう考えられたのがGrowing Neural Gasです.
$\mathcal{X}$が(最初から揃ってはおらず)逐次取得される場合にも適用できるので,オンライン処理に向いています.
基本的な処理は,初期標本(二つで十分)に基づいて作成した小規模ネットワークを追加標本に基づいて移動・成長させつつ,一方で一定の寿命を迎えたネットワーク構成要素を削除し規模の爆発を抑制する,という流れになります.
ネットワーク構造が位相構造を表現します.ただし,マクロな位相構造(上記の例では何個の箱がどのように重なっているかなど)を直接表現するものではないので,その点は注意が必要です.
Neural Gasのデータ構造
ネットワークは,ユニットとエッジから成る無向グラフの形態をとります.
$i$番目ユニットを$\mathrm{s}_{i}$,二つのユニット$\mathrm{s}_{i}$および$\mathrm{s}_{j}$を結ぶエッジを$E_{i,j}$とそれぞれ表すことにします.ユニット$\mathrm{s}_{i}$は座標$\boldsymbol{v}_{i}$,累積誤差$e_{i}$,自分を起点とするエッジ群$\mathcal{E}_{i}$の三者をメンバーに持ちます.
\mathrm{s}_{i}=\left(\boldsymbol{v}_{i}, e_{i}, \mathcal{E}_{i}\right)
また,エッジ$E_{i,j}$は両端ユニットのほかに齢$a_{i,j}$をメンバーに持ちます.
E_{i,j}=\left(\mathrm{s}_{i}, \mathrm{s}_{j}, a_{i,j}\right)
エッジは方向を持たないものとします.したがって$E_{i,j}\equiv E_{j,i}$です.累積誤差と齢については,アルゴリズムの中で説明します.
全てのユニットの集合を$\mathcal{S}$,全てのエッジの集合を$\mathcal{E}$と表すことにしましょう.念のため,どちらの集合も要素の重複を許さないものとします.つまり,$E_{i,j}\in\mathcal{E}$ならば$E_{j,i}\notin\mathcal{E}$です.
アルゴリズム
観測によって標本を一つ得る関数Sampling$(P)$を用意します.$P$はシステムの確率分布です.これを用いて二つのユニット$\mathrm{s}_{1}$,$\mathrm{s}_{2}$を座標が重複しないように作成し,結合して初期ネットワークを作成します.両ユニットの累積誤差はともに0とします.

Connect$\left(\mathrm{s}_{i}, \mathrm{s}_{j};\mathcal{E}\right)$は$\mathrm{s}_{i}$,$\mathrm{s}_{j}$を結合する操作です.全てのエッジ集合$\mathcal{E}$とともに,個々のユニットが持つエッジ群$\mathcal{E}_{i}$,$\mathcal{E}_{j}$も更新します.新たに作成されたエッジの齢は0です.

標本$\boldsymbol{v}$が与えられたとき,ネットワークはいきなりユニットを増やすのではなく,まずは既存のユニット配置を修正します.具体的には,$\boldsymbol{v}$に最も近い座標を持つユニット$\mathrm{s}_{f}$および二番目に近い座標を持つユニット$\mathrm{s}_{s}$を見つけ,
- $\|\boldsymbol{v}-\boldsymbol{v}_{f}\|^{2}$を累積誤差$e_{f}$に足し込む
- $\boldsymbol{v}_{f}$を$\boldsymbol{v}$に向かって微小距離延ばす
- $\mathcal{E}_{f}$の全ての要素(エッジ)$E_{f,j}$について,
- $\boldsymbol{v}_{j}$を$\boldsymbol{v}$に向かって延ばす
- $j=s$ならば齢$a_{f,s}$を0にする.さもなければ$a_{f,j}$を1増やす
- $\mathrm{s}_{f}$と$\mathrm{s}_{s}$が結合されていなければこれらを結合する
という処理を行います.

この処理の結果,齢が一定値$a_{\mathrm{max}}$を超えたエッジは削除します.また,それによりエッジが無くなったユニットも削除します.


これら二つの処理を$\lambda$回繰り返し,累積誤差が最大となったユニット$\mathrm{s}_{p}$と,その$\mathrm{s}_{p}$に隣接する中で累積誤差が最大のユニット$\mathrm{s}_{n}$を選んで,両者の間に新たにユニットを挿入します.


上記のMetabolizeNetwork$(\mathcal{S},\mathcal{E})$を1サイクルとして,これを反復するのがGrowing Neural Gasです.反復の終了判定の規範は明示されておらず,オンライン処理の場合は延々と継続することになります.
処理全体の働きは次のように説明できます.AdaptNetworkは,ネットワーク全体を観測された標本に適応させる効果を持っています.累積誤差が大きいことは,そのユニットが観測された標本群を説明するのにあまり貢献していないということを意味するので,GrowNetworkによってその近辺に積極的に新たなユニットを発生させるわけです.これは逐次添加法による誘導Delaunay三角形分割に近い働きを持ちます.RemoveAgedNetworkは,移動が盛んなユニットを三角形分割の対象から除外するために必要です.
幾つかハイパーパラメータがありますが,オリジナル論文では$\lambda=100$,$\varepsilon_{1}=0.2$,$\varepsilon_{2}=0.006$,$\alpha=0.5$,$a_{\mathrm{max}}=50$,$\beta=0.995$が採用されています.
試験と所感
Growing Neural GasをZMのzm_gng.cに実装し,試してみました.テストコードはexample/mca/gng_test.cにあります.サンプルデータは$x$-$y$平面上の(0,0)-(10,10)の範囲で乱数的に3点とり,それぞれを中心に半径1.5程度の円の内部に乱数的に500点配置することで作成しました.関数Sample$(P)$は,単純にこれらの点のうち一つを一様乱数で選択し返すものとしました.ハイパーパラメータは$\lambda$のみ10とし,それ以外はオリジナル論文で採用されている値と同じにしました.
トータルで1500個の点があるので,MetabolizeNetworkを1500回反復し,その計算過程を可視化してみたものが下の図です.
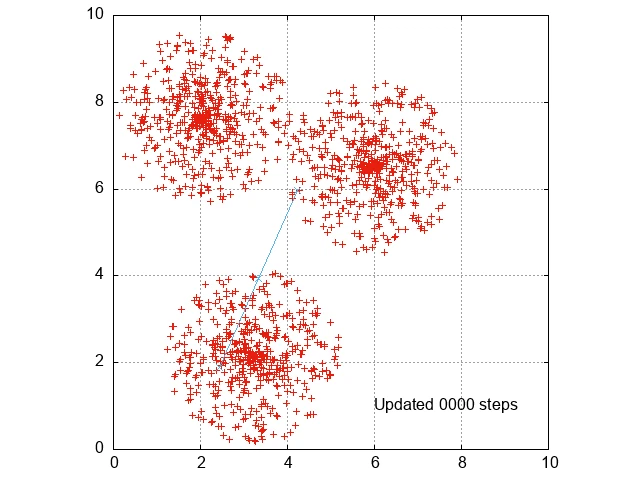
500回目くらいまでは良い感じにネットワークがクラスタを覆っていきますが,段々とオーバーフィッティングしていっています.クラスタ間を結ぶ橋のようなエッジが発生するかどうかは割と確率的で,完全に切れてしまう場合もそこそこあります.クラスタが明確に分離している場合,一度切れた橋が復活することはほとんど無いようです.
計算過程でのユニット数およびエッジ数の変化もプロットしてみました.
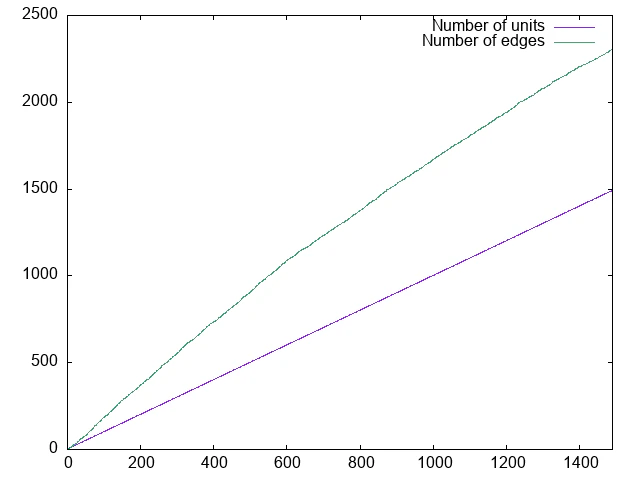
ユニット数はほとんど直線的に増加しているように見えます.Sample$(P)$が単純な設計なので,孤立したユニットが発生しないことが恐らくの原因です.エッジ数の増え方は一定ではありませんが,やはり単調に増加しています.ネットワーク爆発を防ぐためには,全ユニット数を一定値に抑えるなど積極的な対策を講じなければならなそうです.
動的クラスタリングは別の機会に改めて試してみたいと思います.