概要
自作した辞書APIとLINEBotを連携して、言葉の意味を教えてくれるBotを作ったので、その作り方を紹介します。スクリプトや中間生成物はgithub:Intelli-fuga-botに置きました。
はじめに
涼しいから寒いに変わり、面倒で後回しにしてた布団の衣替えしました。秋ですね。
秋といえば、○○の秋といって何かを始める 季節でもあります。私の場合はリベンジの秋です。以前作成した、fugaしか答えない残念Botに。辞書を持たせてなんでも物知りインテリBotに改造します!
(Googleあれば物知りBotいらないとか、そーいうことは聞こえない)
できたもの
知りたい言葉をメッセージすると意味を教えてくれるLINE Botになりました。レスポンスも上々です。
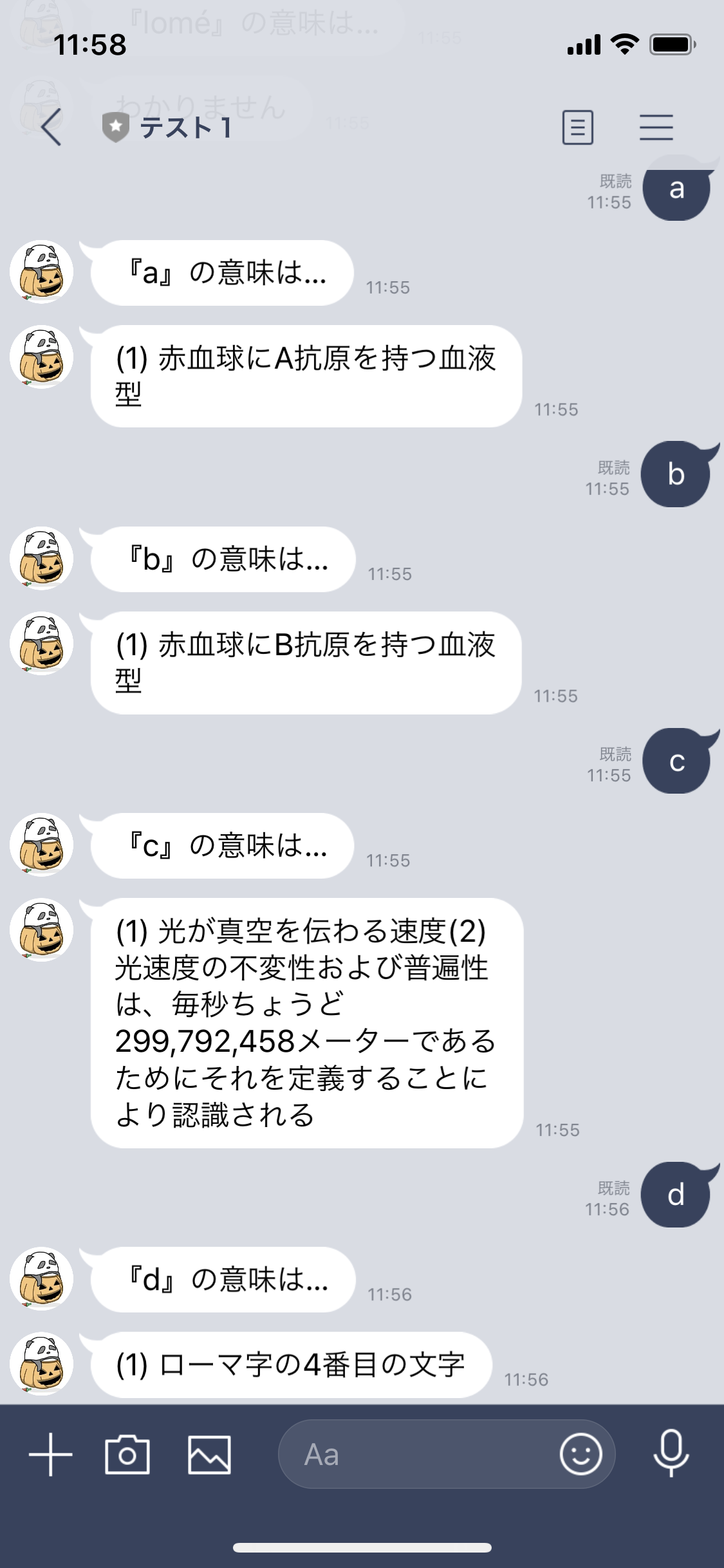
a,bの意味は血液型で、cは小難しい説明で、dは適当な説明と、面白い?返事をするようになりました。これは、約8万語の辞書情報を持つ辞書APIと連動することで実現できました。
辞書APIは、AWSのAPI Gateway + Lambda + DynamoDBでAPIで作り。辞書のデータは日本語WordNetの情報をDynamoDBにインポートしました。そして、データのインポートには、AWS Data Pipelineを使いました。
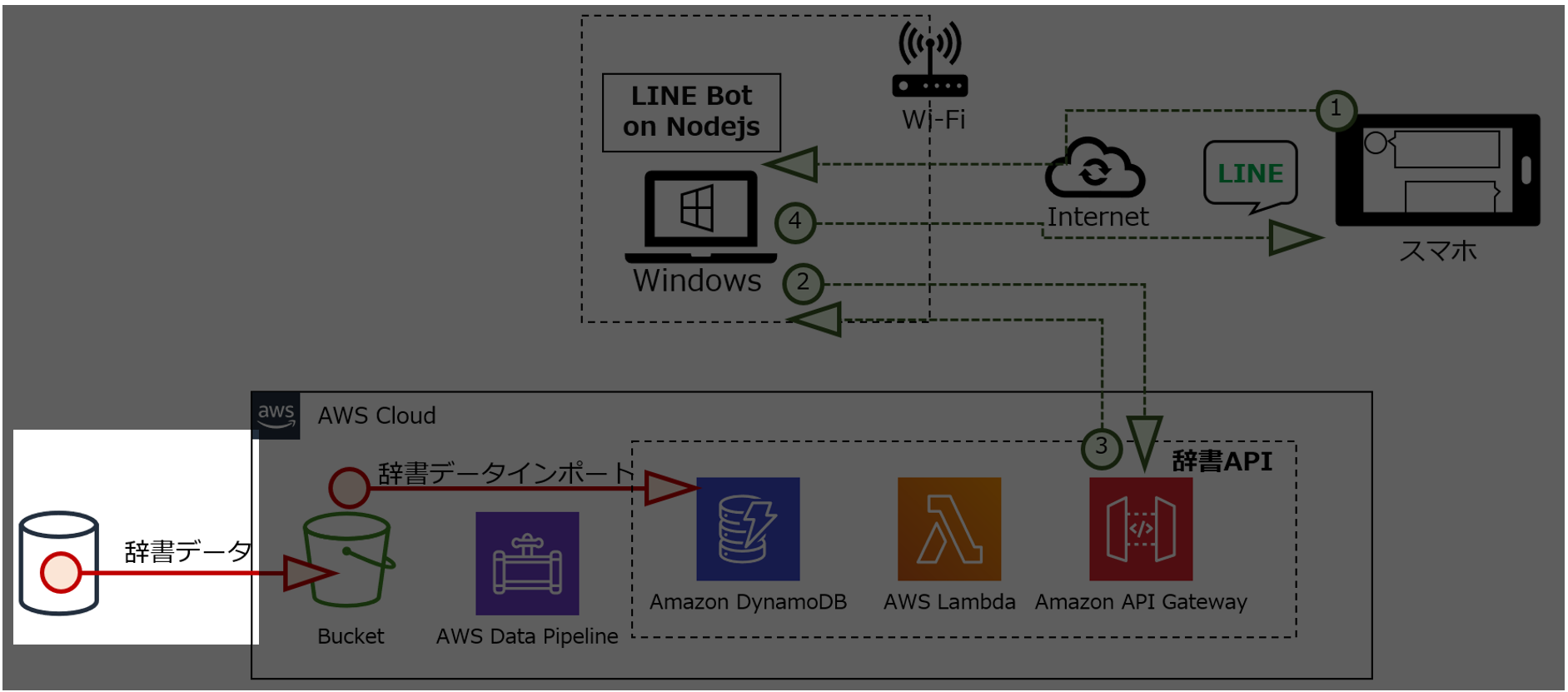
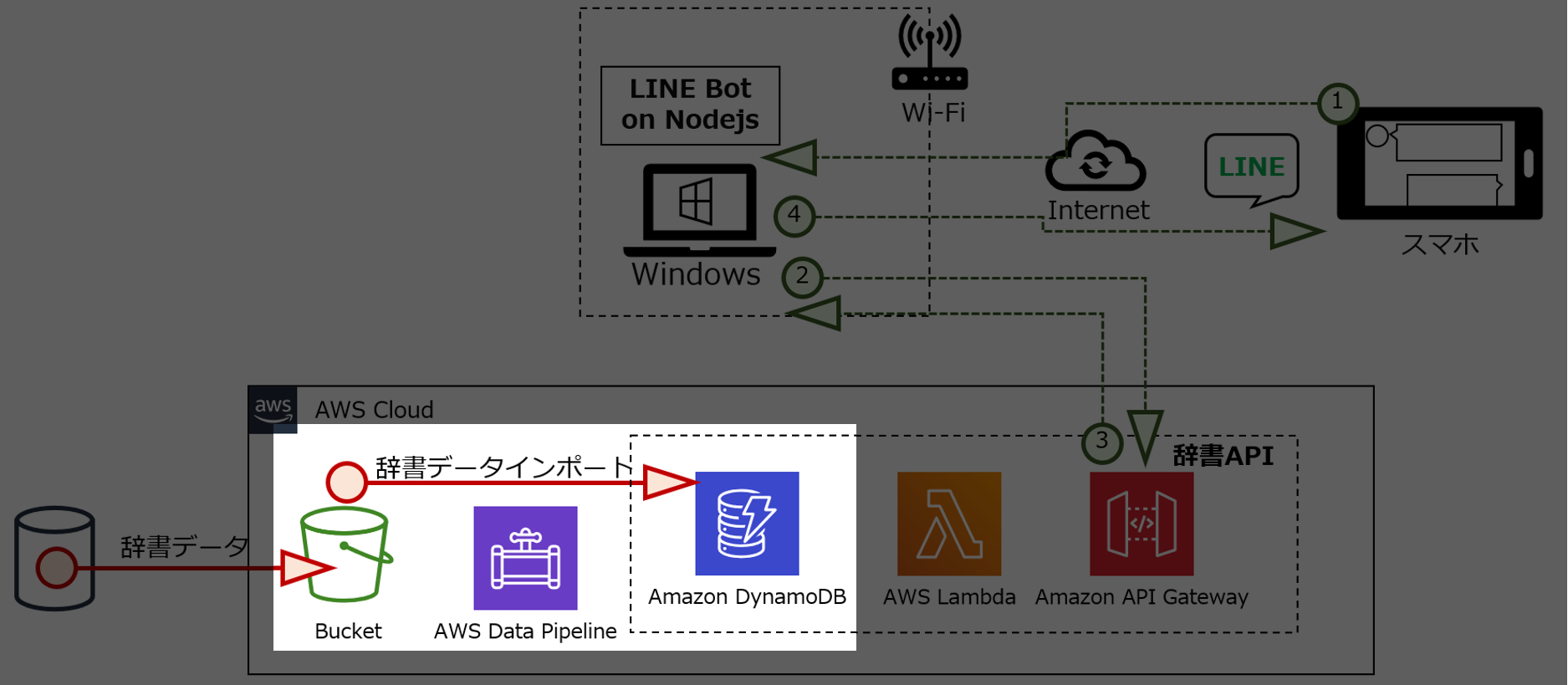
構成図
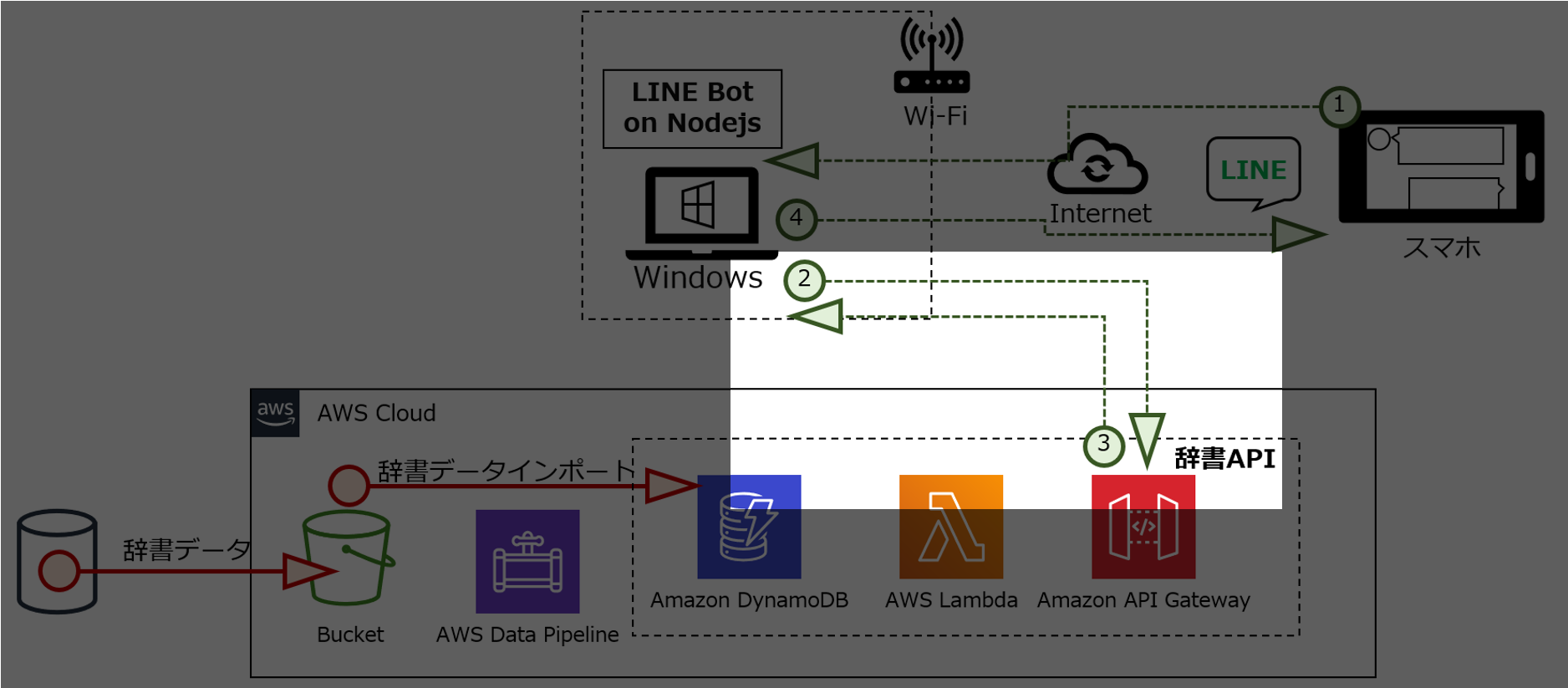
インテリに生まれ変わったLINE Botの構成図です。
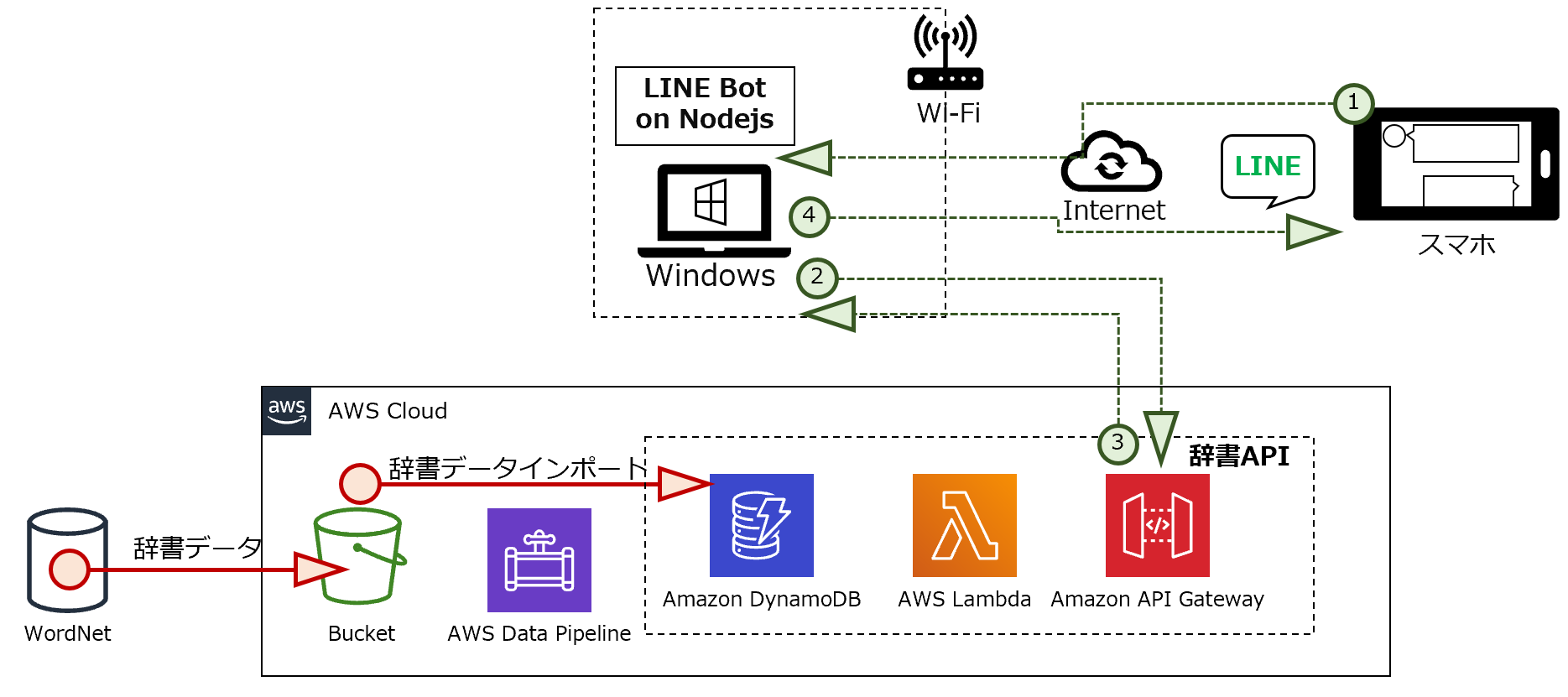
処理の流れ
① LINEチャネルから、ユーザがメッセージを送ります。
② LINE Botが受信したメッセージを辞書APIに送ります。
③ 辞書APIが受信したメッセージに該当する情報をデータベース(DynamoDB)から取り出し、LINE Botに送ります。
④ LINE Botが辞書APIから受信した情報をメッセージとして送ります。
参考情報
こちらのサイトを参考にしました。
-
1時間でLINE BOTを作るハンズオン (資料+レポート) in Node学園祭2017
- LINE Botの作り方を参考にさせて頂きました。
-
API Gateway + Lambda + DynamoDB
- AWSでAPIを作る方法について参考にさせて頂きました。
-
日本語WordNet
- 辞書データを利用させていただきました。
では、インテリBotの作り方を紹介します。
1.APIと連動するLINE Botを作ろう
はじめに、1時間でLINE BOTを作るハンズオン (資料+レポート) in Node学園祭2017の補足資料その2を作り、天気APIと連動したLINE Botを作ります。その後、server.jsを以下のように変更し、辞書APIと連動するようにします。(※辞書APIはまだ作ってないのでダミーのURLを設定します)
'use strict';
const express = require('express');
const line = require('@line/bot-sdk');
const axios = require('axios');
const PORT = process.env.PORT || 3000;
const config = {
channelSecret: '',
channelAccessToken: ''
};
const app = express();
app.post('/webhook', line.middleware(config), (req, res) => {
console.log(req.body.events);
Promise
.all(req.body.events.map(handleEvent))
.then((result) => res.json(result));
});
const client = new line.Client(config);
function handleEvent(event) {
if (event.type !== 'message' || event.message.type !== 'text') {
return Promise.resolve(null);
}
let mes = ''
mes = '『' + event.message.text + '』の意味は…'
getNodeVer(event.source.userId , event.message.text);
return client.replyMessage(event.replyToken, {
type: 'text',
text: mes
});
}
const getNodeVer = async (userId, argKey) => {
//辞書API
let apiUrl = 'https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/demo?test_id='+ argKey;
apiUrl = encodeURI(apiUrl); // URLエンコード
const res = await axios.get( apiUrl );
console.log(res.data.name);
await client.pushMessage(userId, {
type: 'text',
text: res.data.name,
});
}
app.listen(PORT);
console.log(`Server running at ${PORT}`);
2.API Gateway + Lambda + DynamoDBで辞書APIを作ろう
辞書機能を持つAPIをAWS(API Gateway + Lambda + DynamoDB)で作成します。
2-1.DynamoDBのテーブルを作ろう
AWSコンソールでDynamoDBを開き、[テーブル]→[テーブルの作成]ボタンからテーブルを新規に作成します。
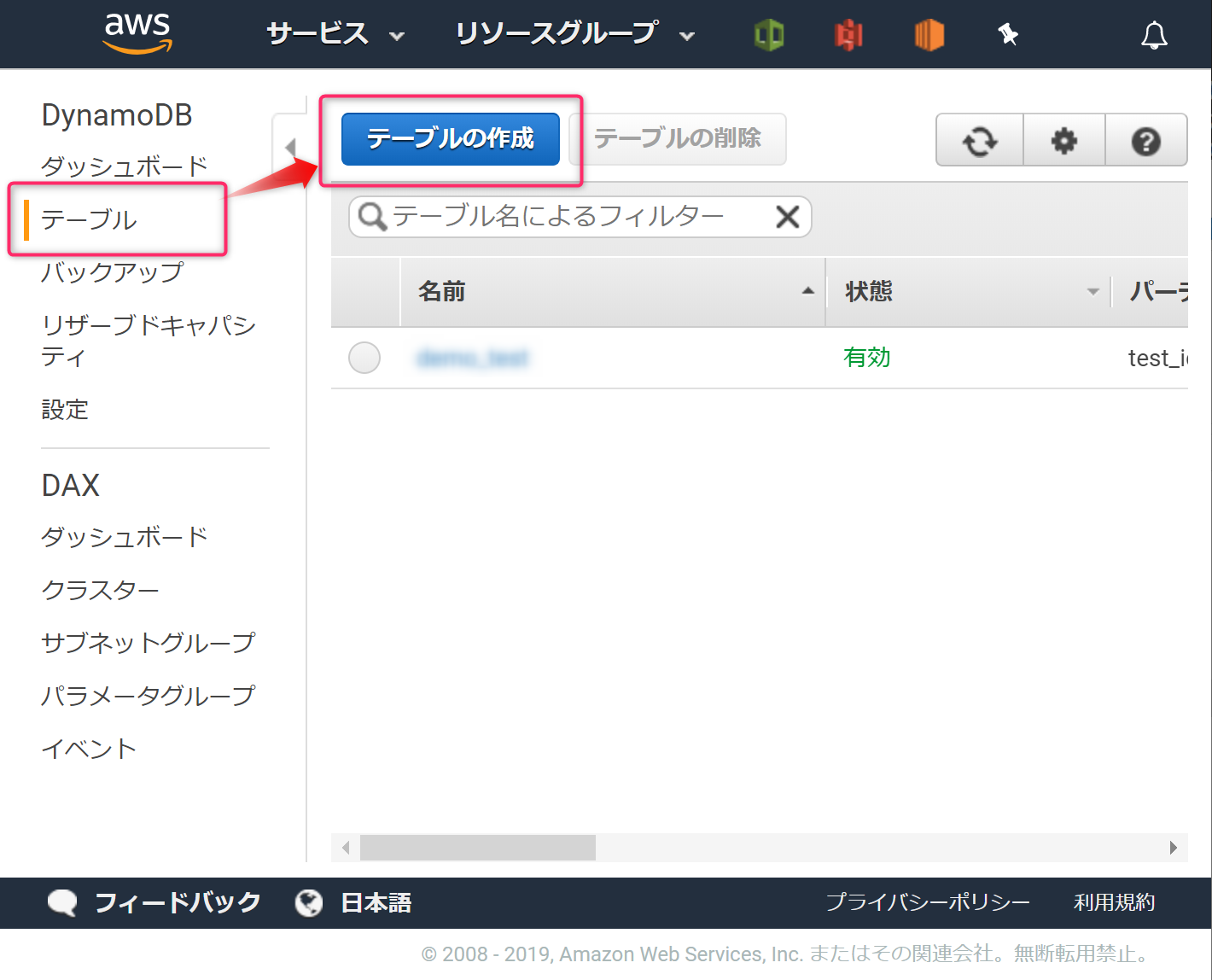
[テーブル名]に 「demo_test」を[プライマリキー]に「test_id」と入力し、作成ボタンをクリックします。
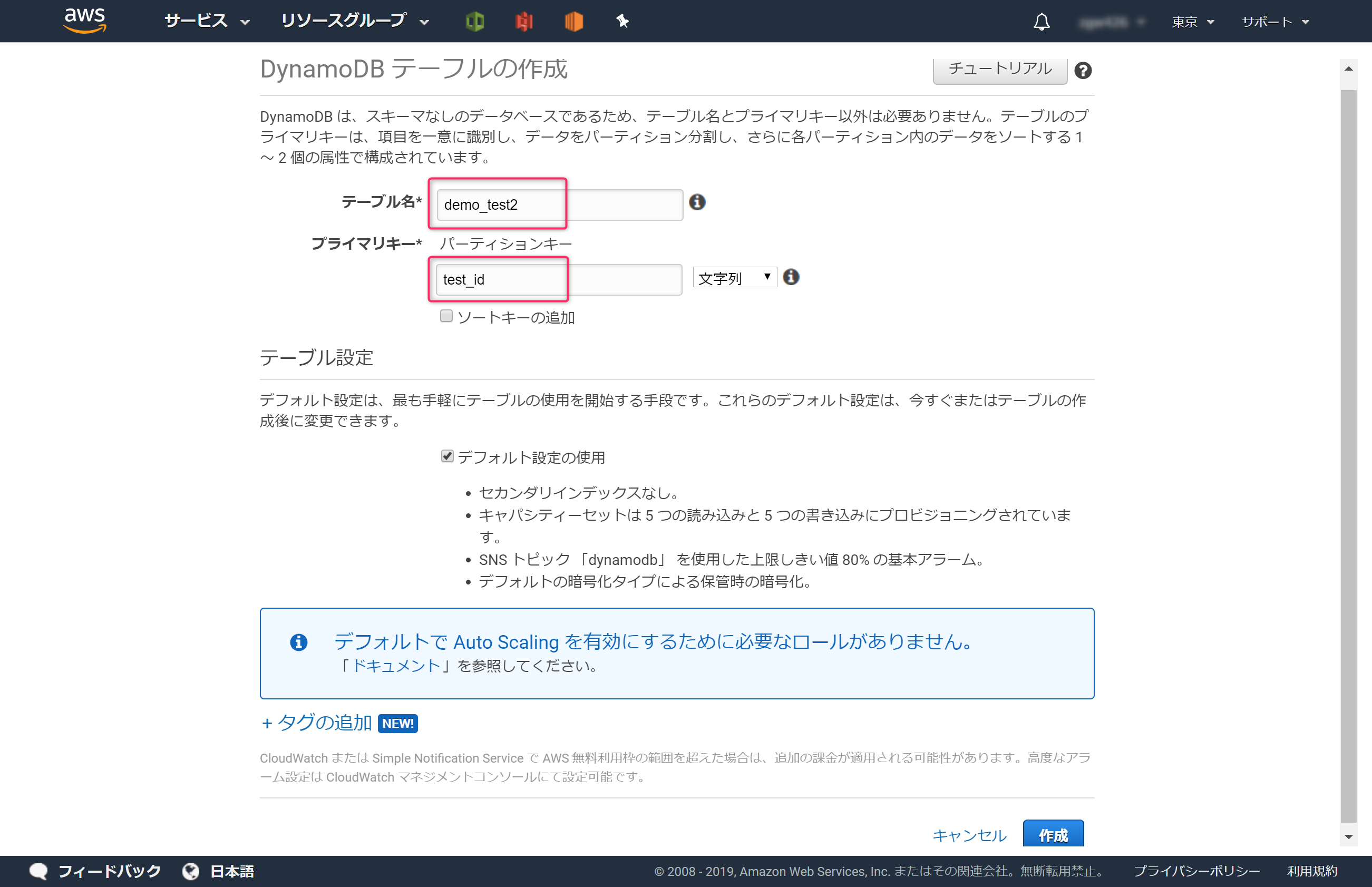
テーブルにデータを登録するため、作成したテーブルの[項目]タブにある[項目の作成]ボタンをクリックします。
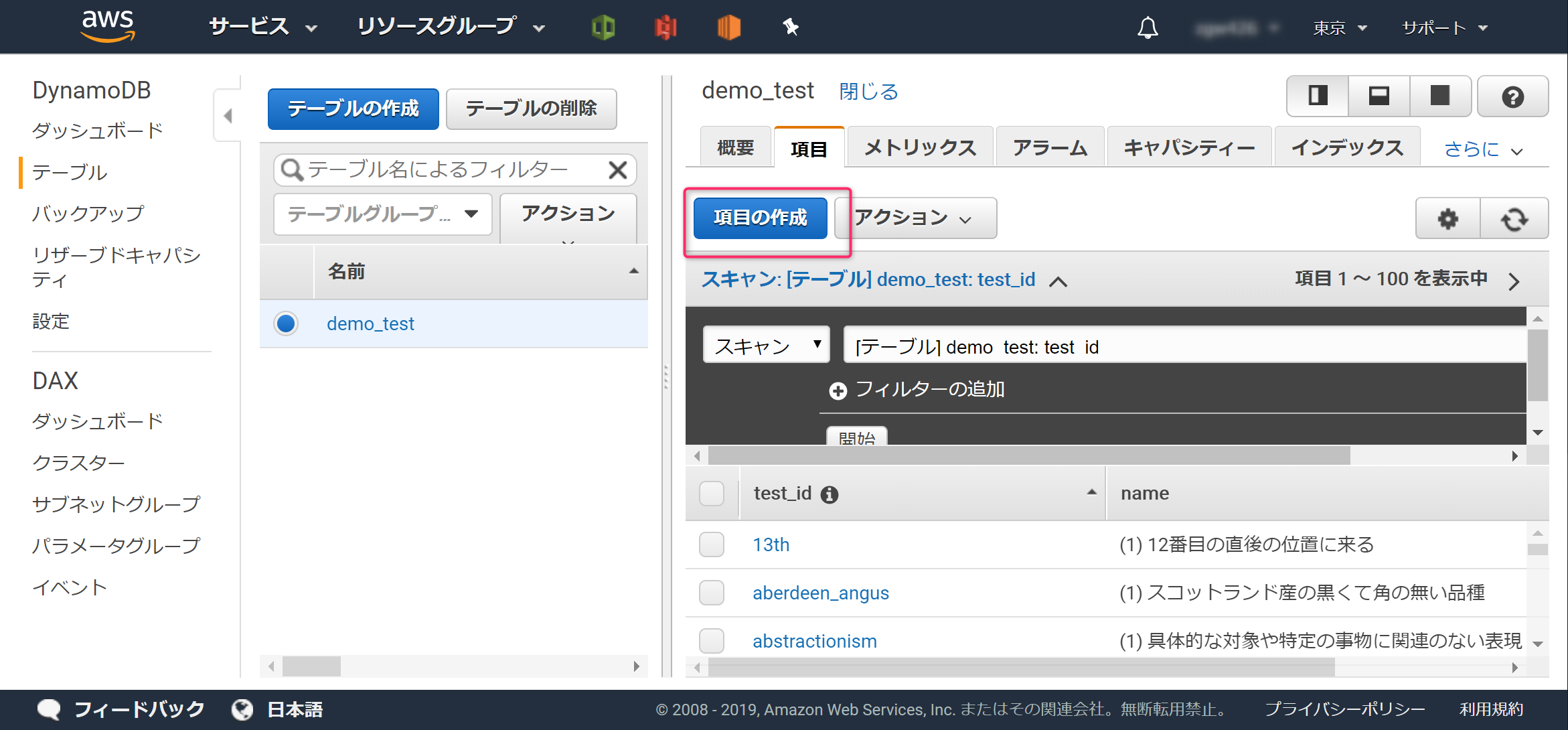
[test_id]に「?」を登録します。更に、+(プラス)をクリックし、[Append]→[String]をクリックします。
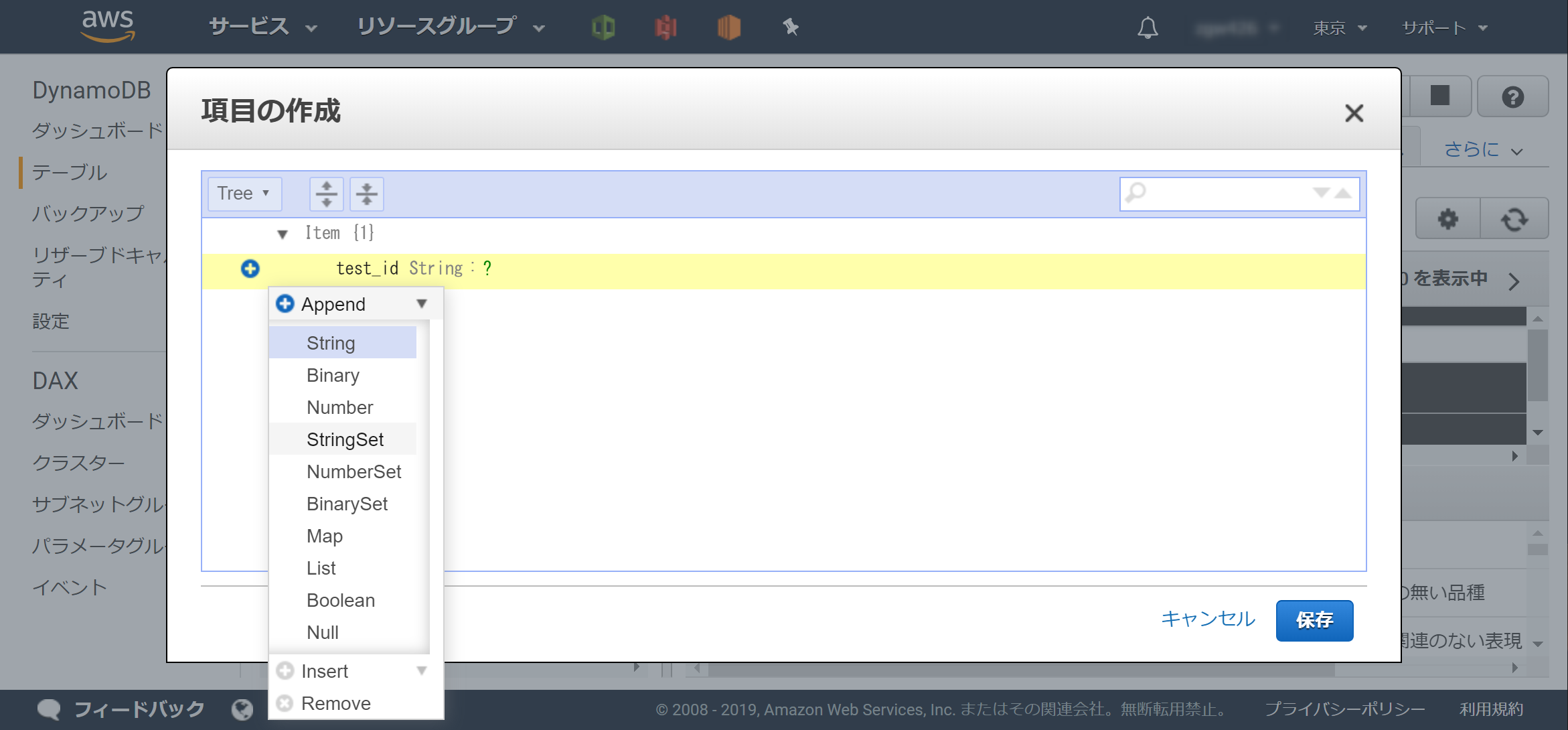
以下のように「name」「わかりません」と登録し、保存ボタンをクリックします。
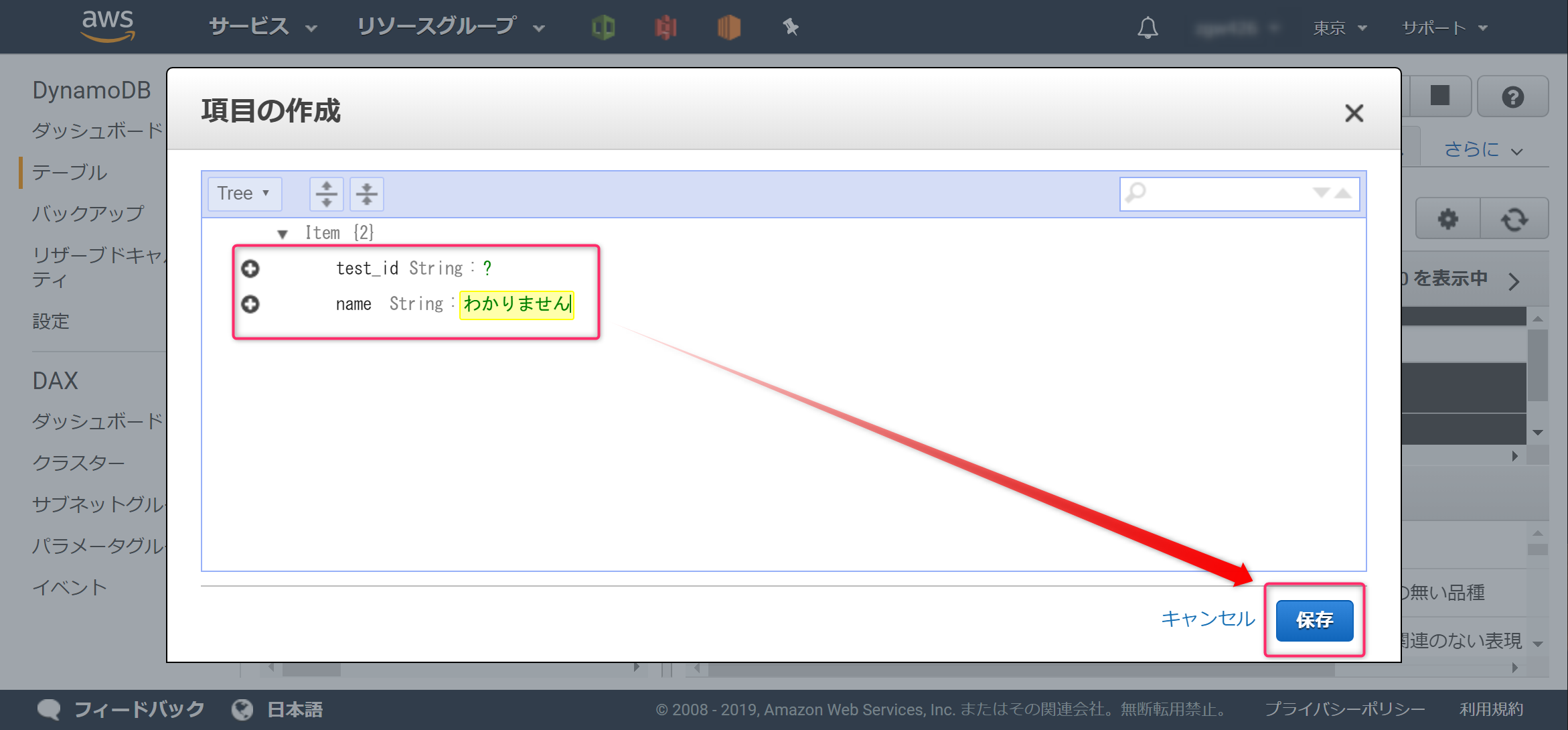
このように登録されたら成功です。
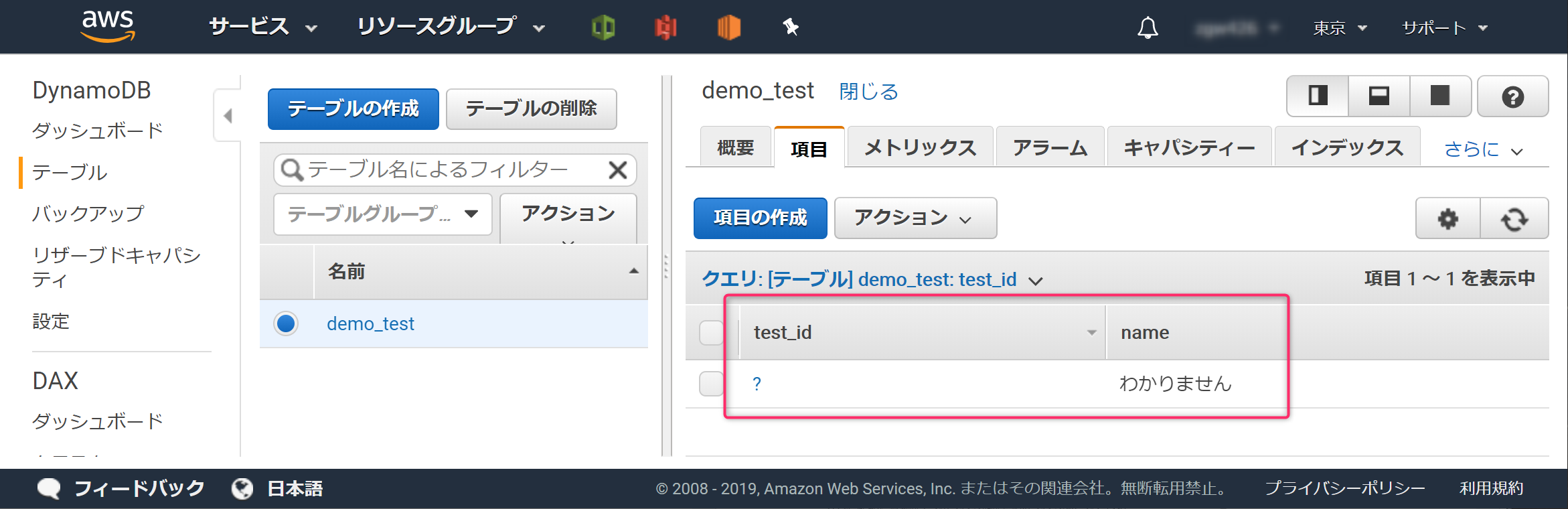
後で検証するため、同様の手順でいくつか登録します。

2-2.Lambda関数を作成しよう
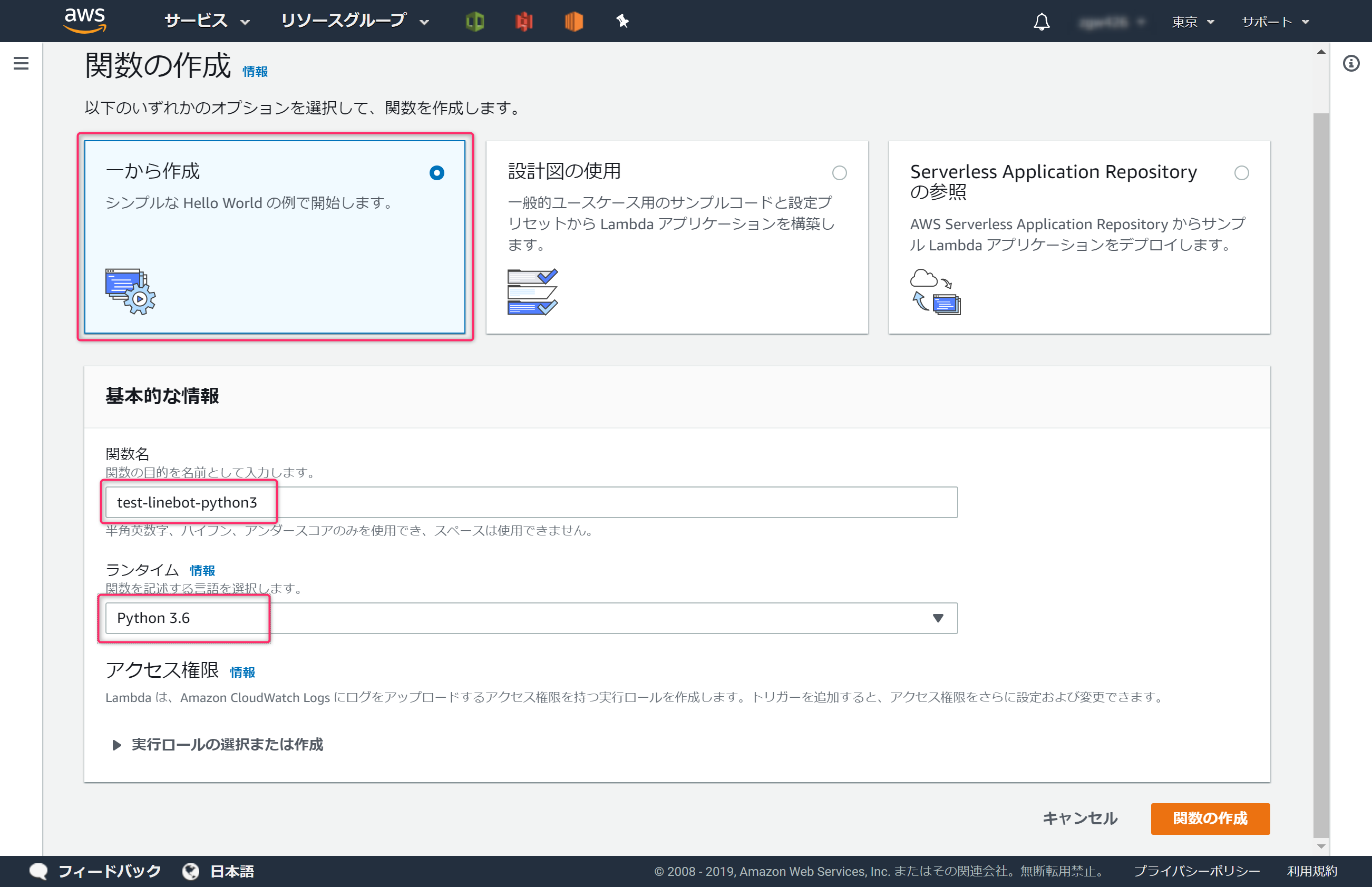
DynamoDBから特定の情報を取り出すLambda関数を作ります。今回はPython3.6を使用します。AWSコンソールでLambdaを開き、[関数の作成]ボタンをクリックします。

以下のように情報を登録し、[関数の作成]ボタンをクリックします。
コードを以下のように編集します。
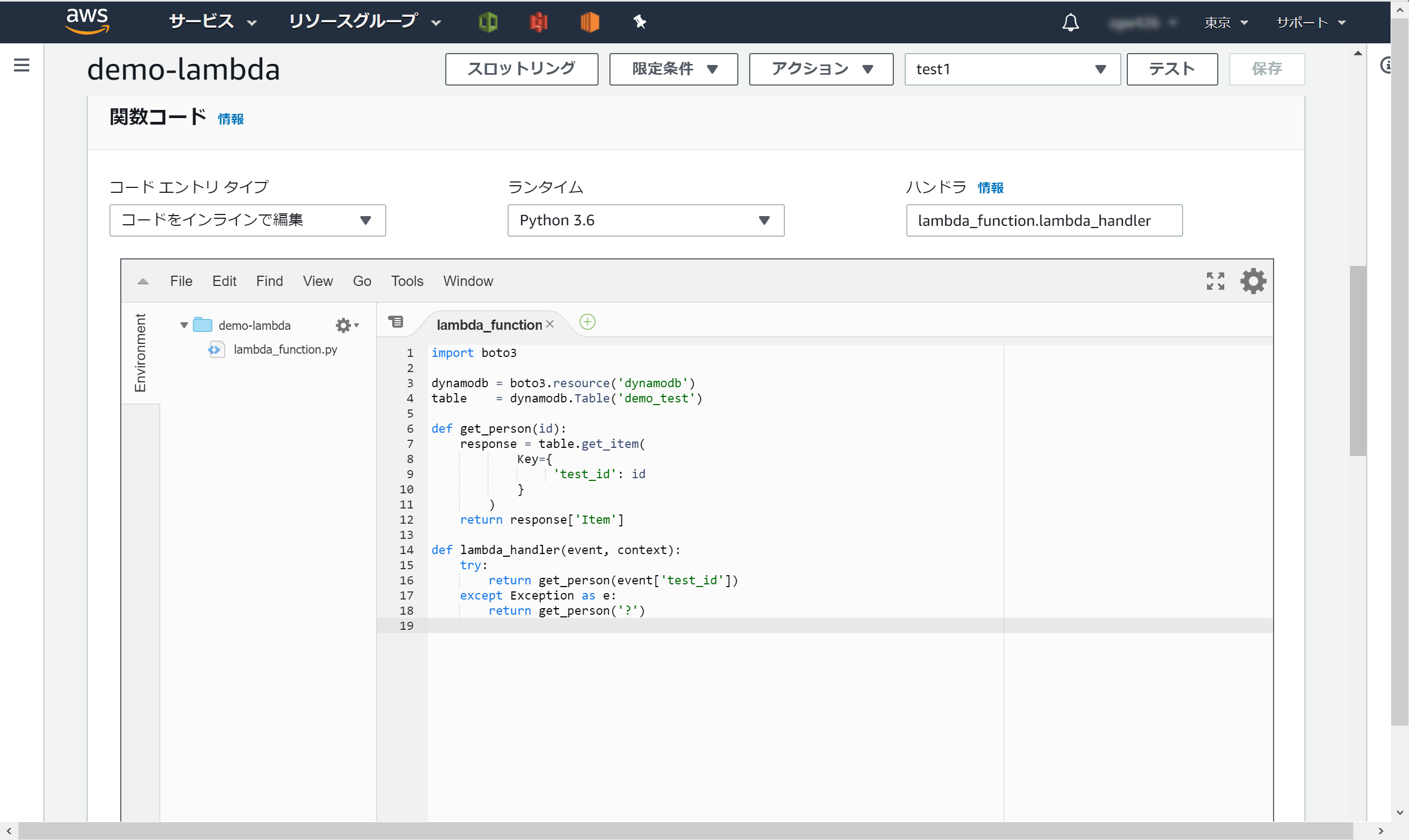
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('demo_test')
def get_person(id):
response = table.get_item(
Key={
'test_id': id
}
)
return response['Item']
def lambda_handler(event, context):
try:
return get_person(event['test_id'])
except Exception as e:
return get_person('?')
スクリプトは、辞書データにない言葉を受信した場合は、データベースの test_idが ? の情報を返します。
Lambdaの動きを確認します。
[テストイベントの設定]を開きます
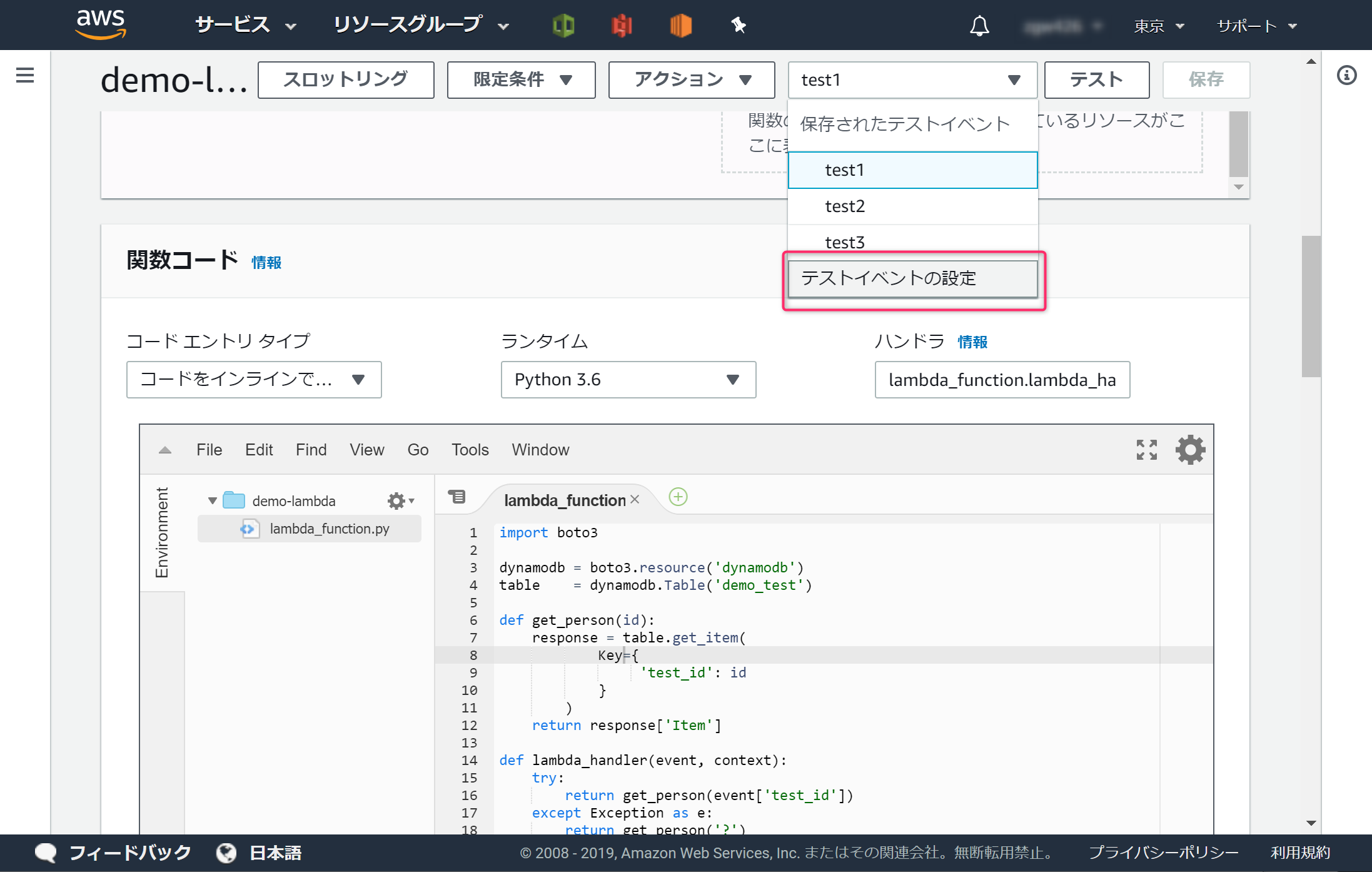
test1, test2, test3 の3つのテストを用意します。
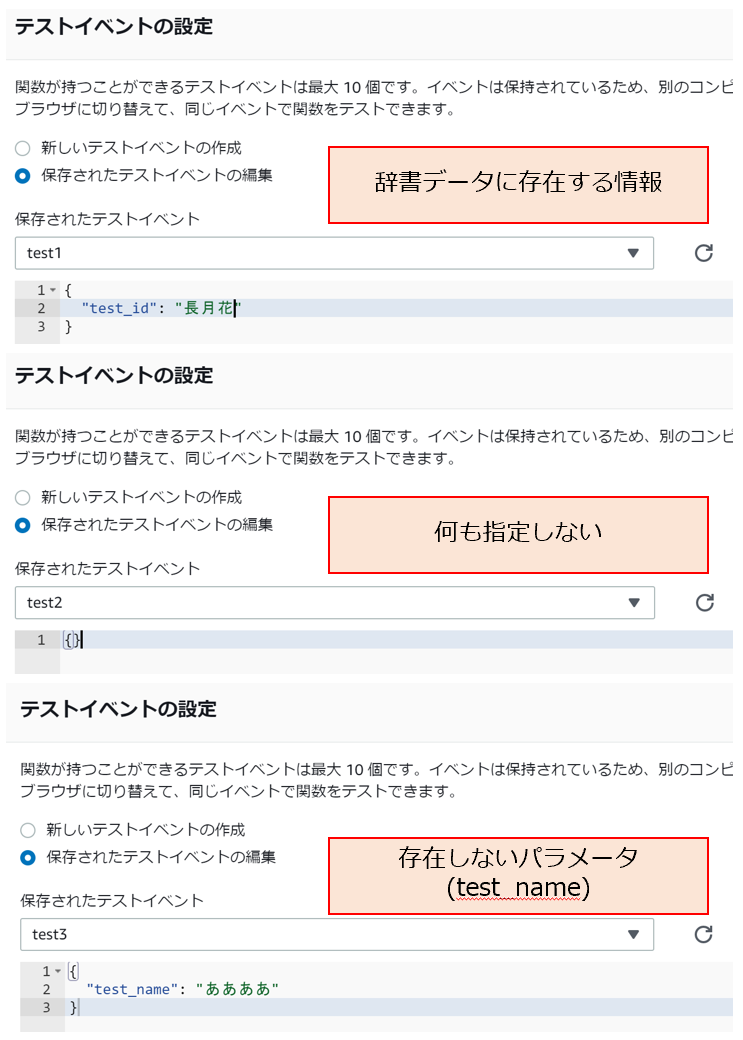
# test1
{
"test_id": "長月花"
}
# test2
{}
# test3
{
"test_name": "ああああ"
}
ではLambdaをテストします。
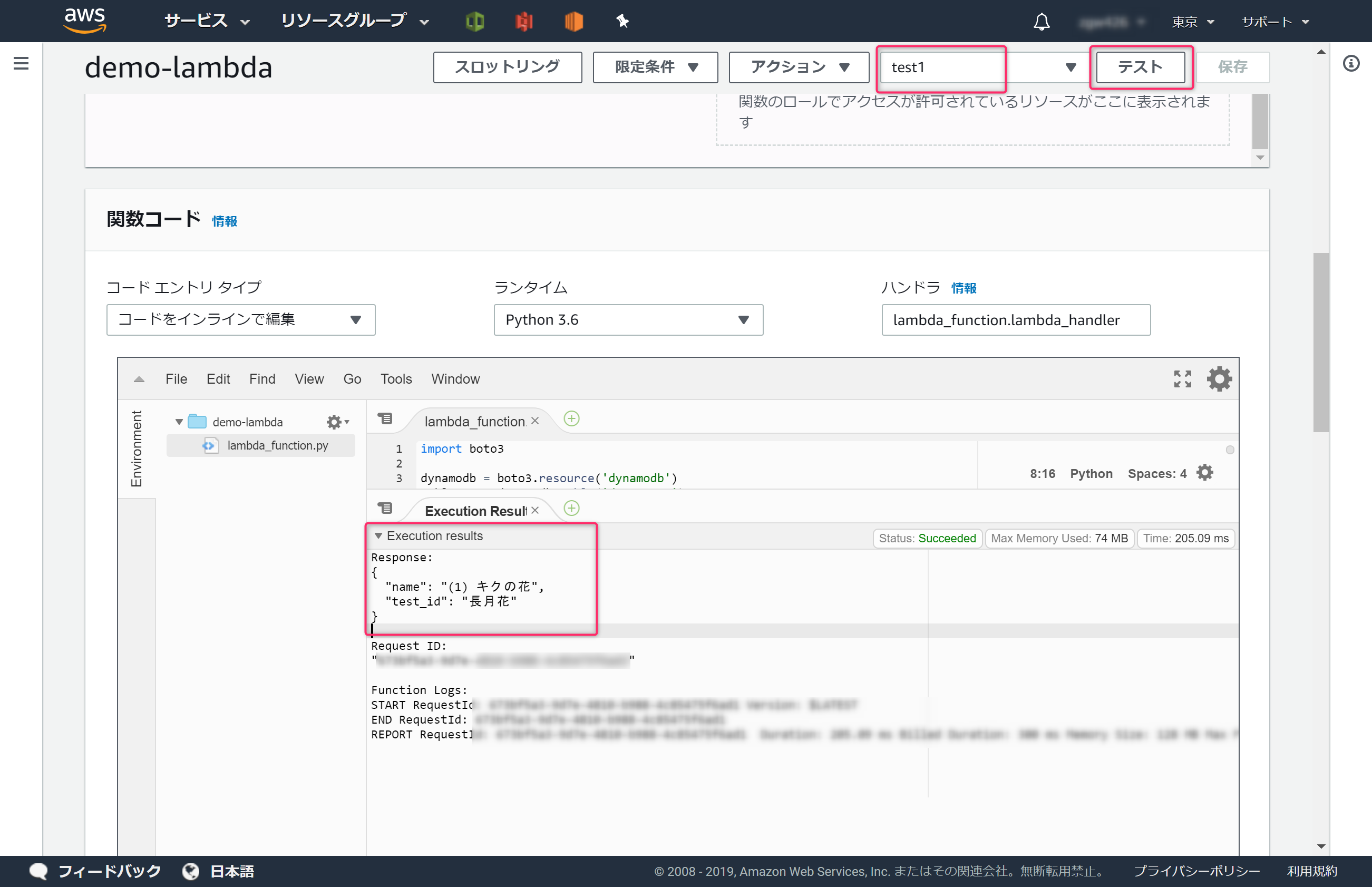
[test1]を設定し、[テスト]ボタンをクリックします。[Excecution Result]に、DynamoDBに登録した、[長月花]の情報が表示されれば成功です。
[test2]を設定し、[テスト]ボタンをクリックします。DynamoDBに登録した、? の情報が表示されれば成功です。
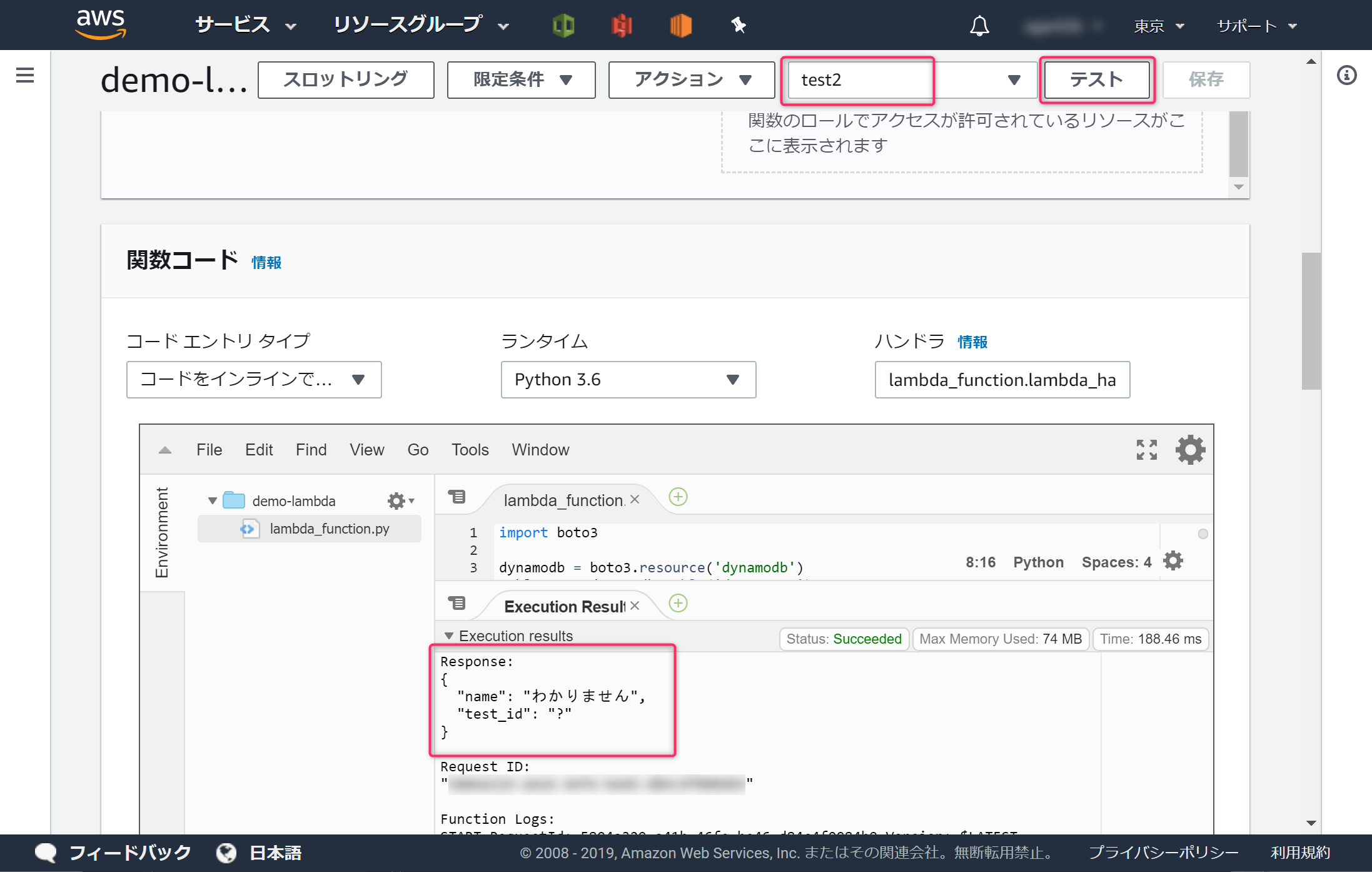
[test3]も[test2]と同様の結果になれば成功です。
2-3.API Gatewayを作成しよう
test_idを指定したらその値が返ってくるようにします。AWSコンソールでAPI Gatewayを開き、[API 名]に「demo-api」と入力し「APIの作成」ボタンをクリックします。
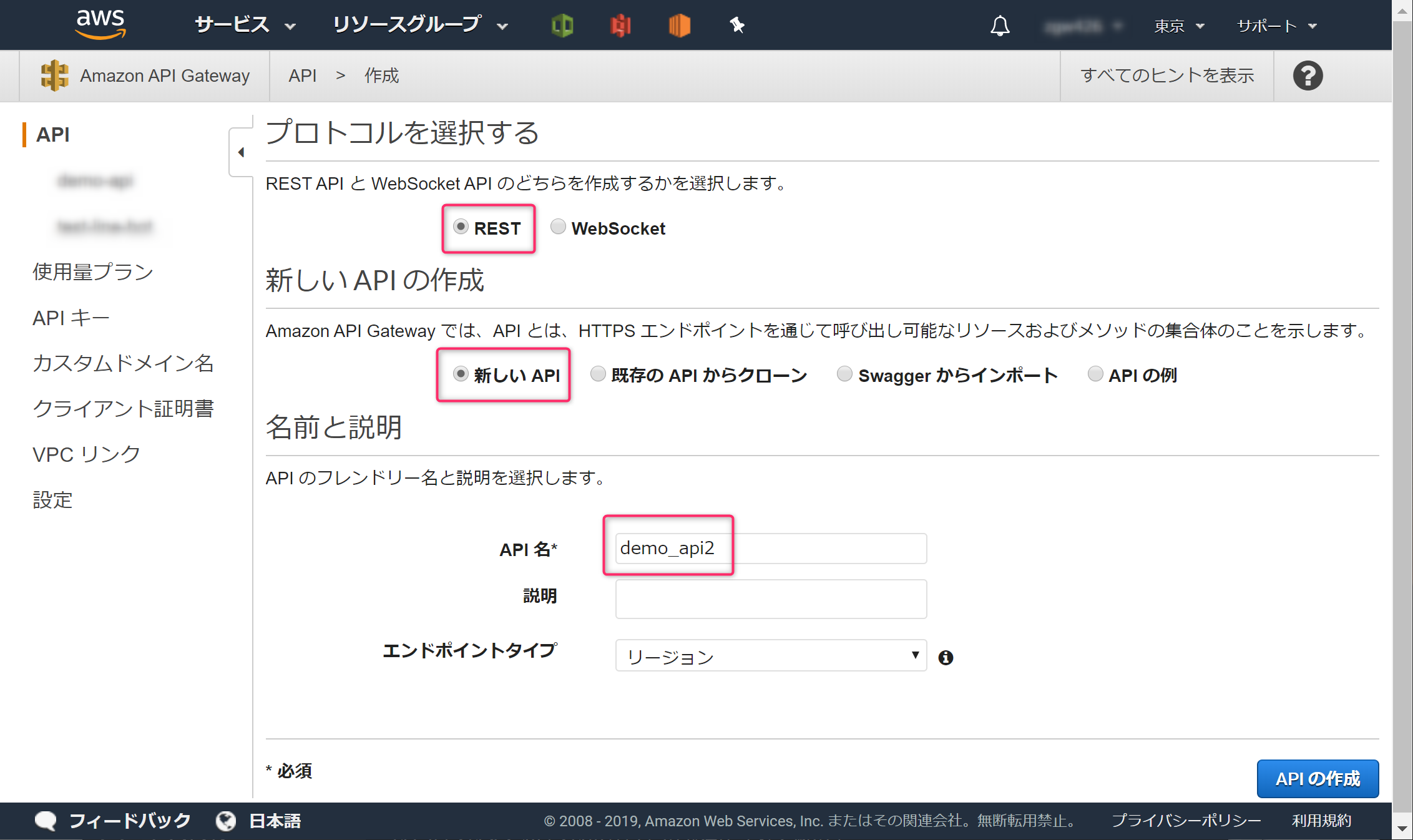
[アクション]→[メソッドの作成]をクリックします。
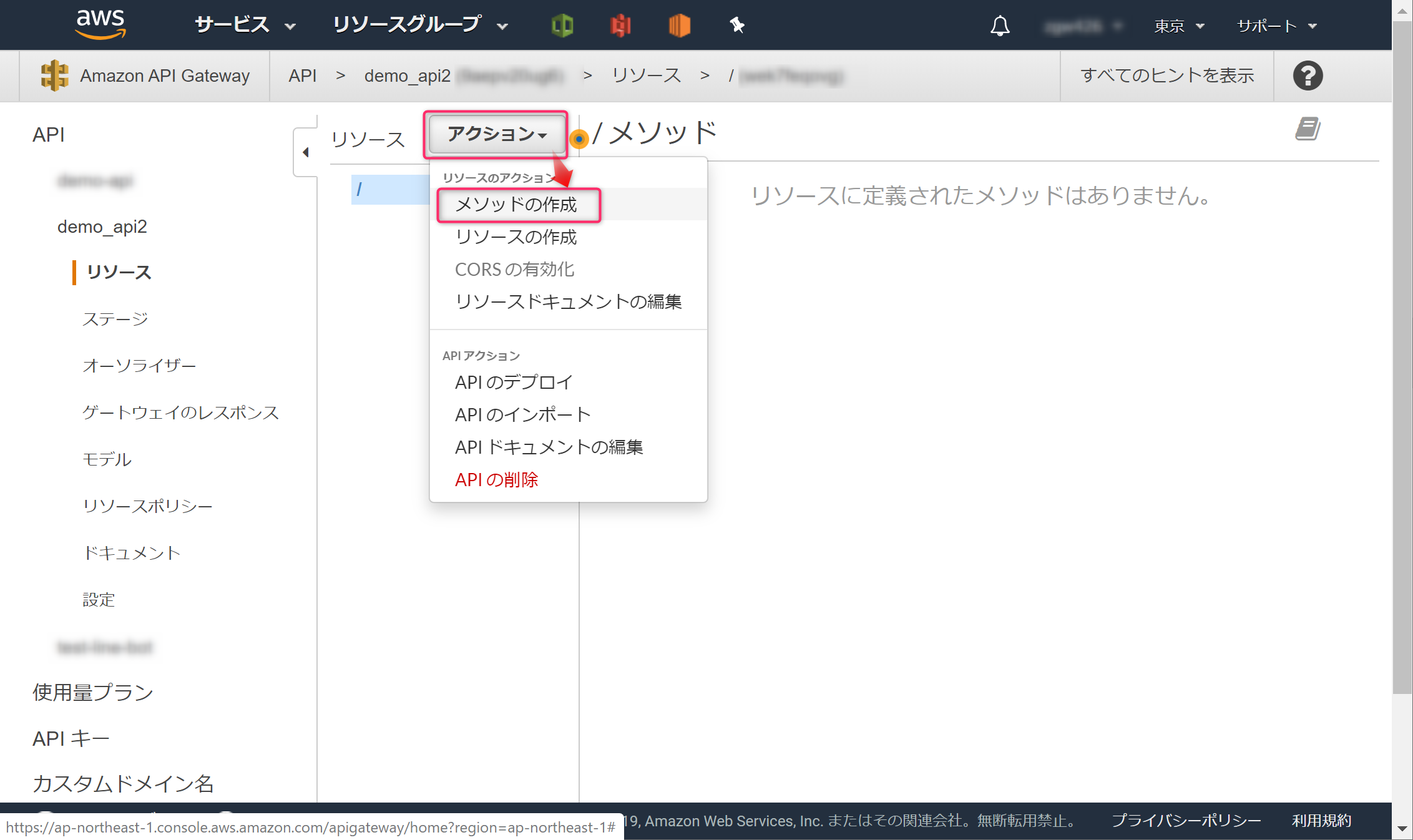
「GET」を選択し、チェックマークをクリックします。
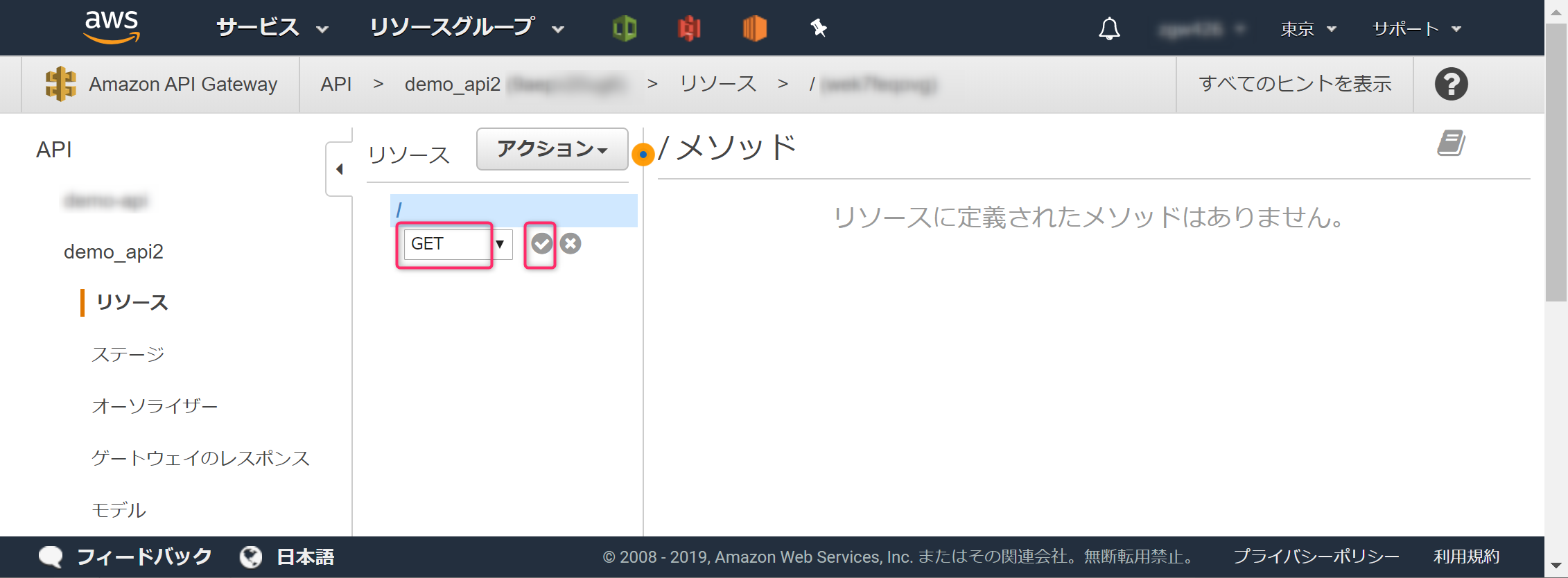
先ほど作成したLambda関数を指定し、[保存]ボタンをクリックします。
API Gatewayに権限を渡す必要があるので[OK]ボタンをクリックします。
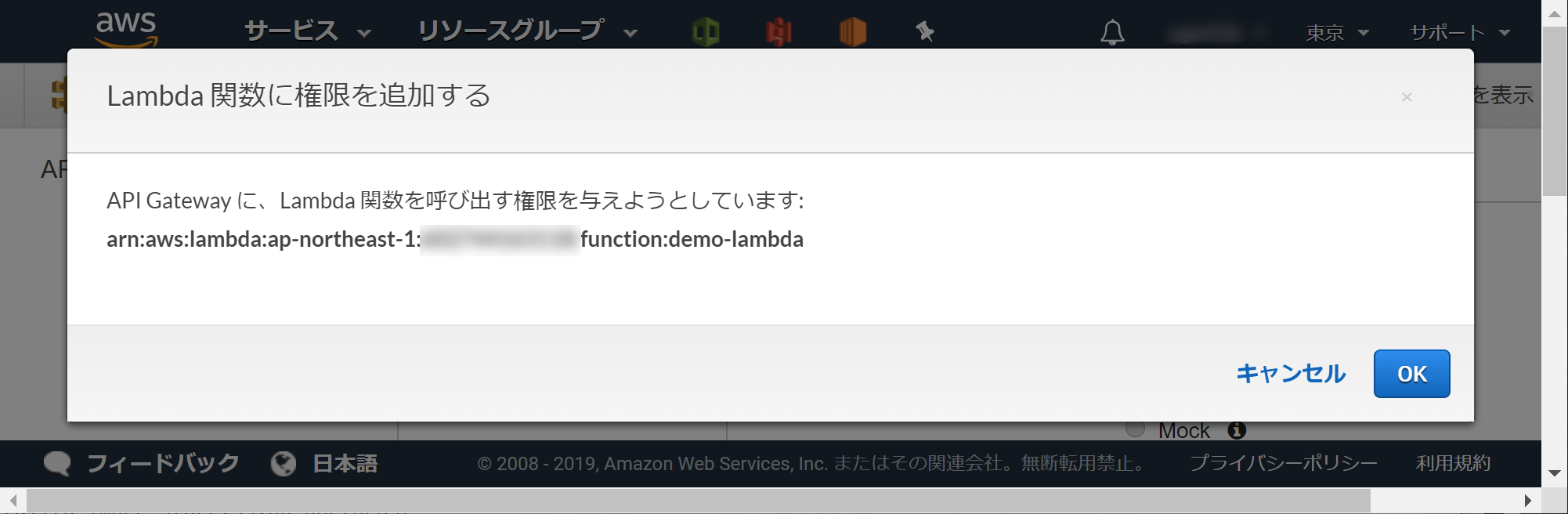
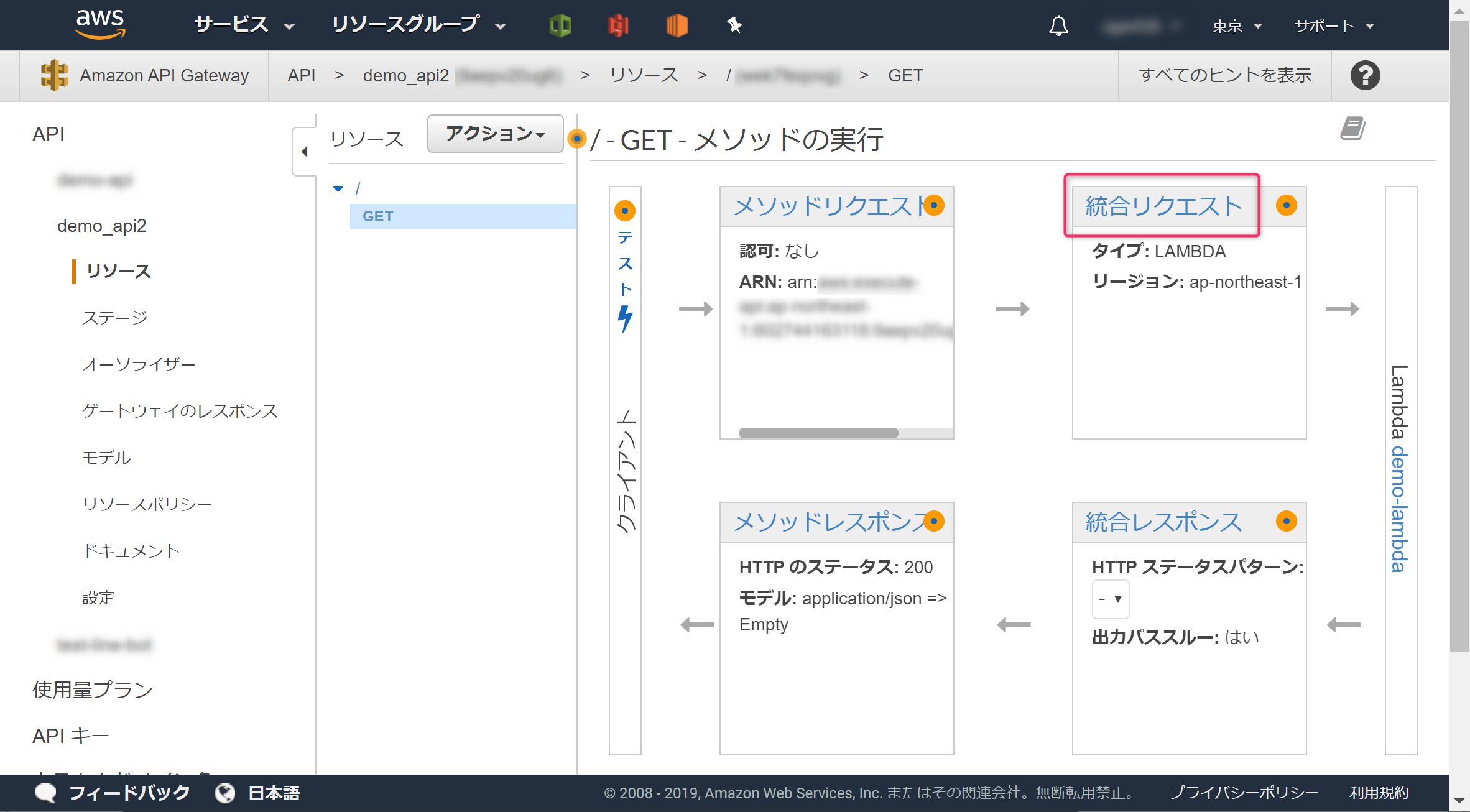
[統合リクエスト]をクリックします。
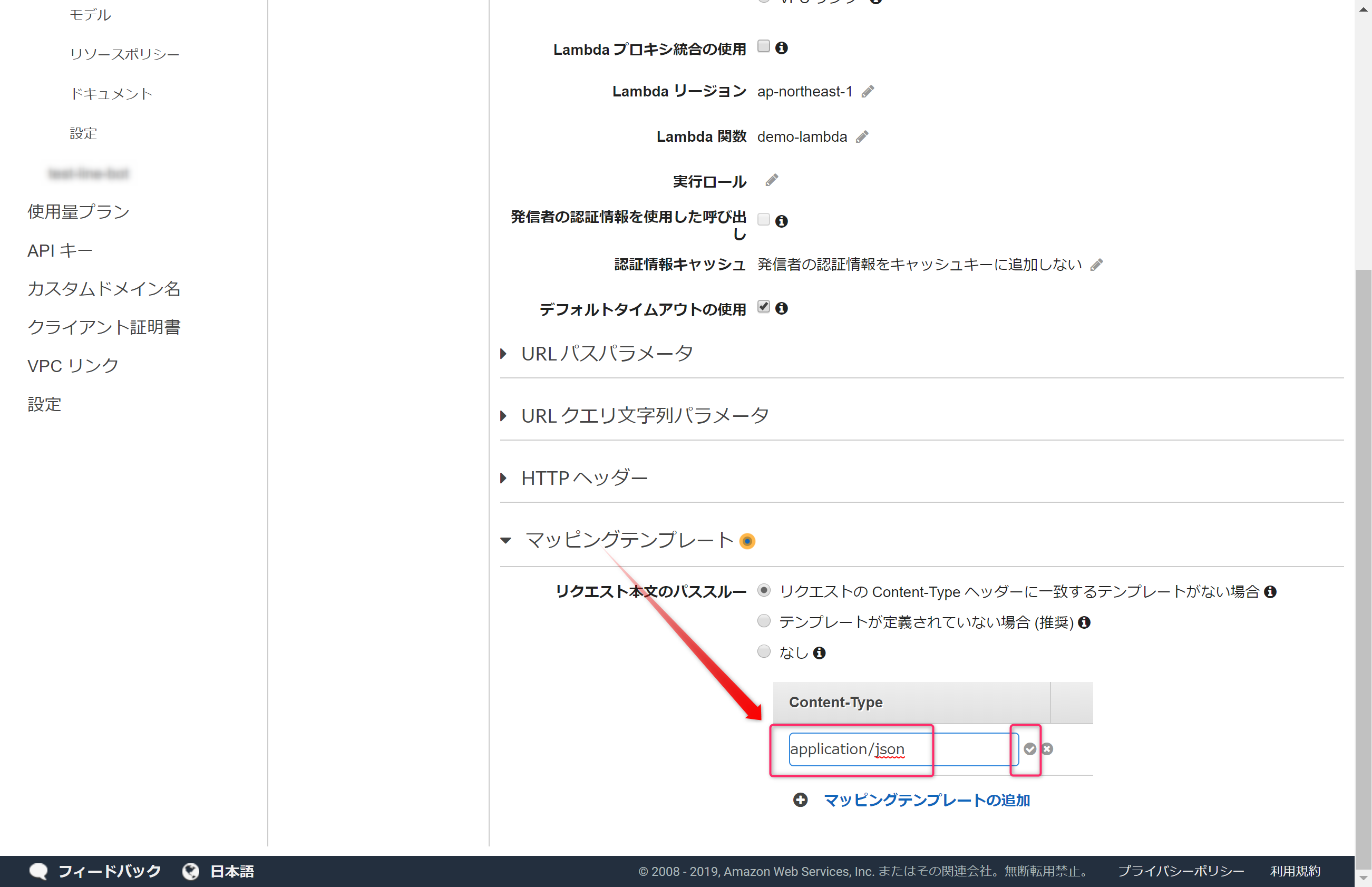
「マッピングテンプレートの追加」をクリックし、「application/json」と追加します。
テンプレートの以下の内容を入力し「保存」ボタンをクリックします。
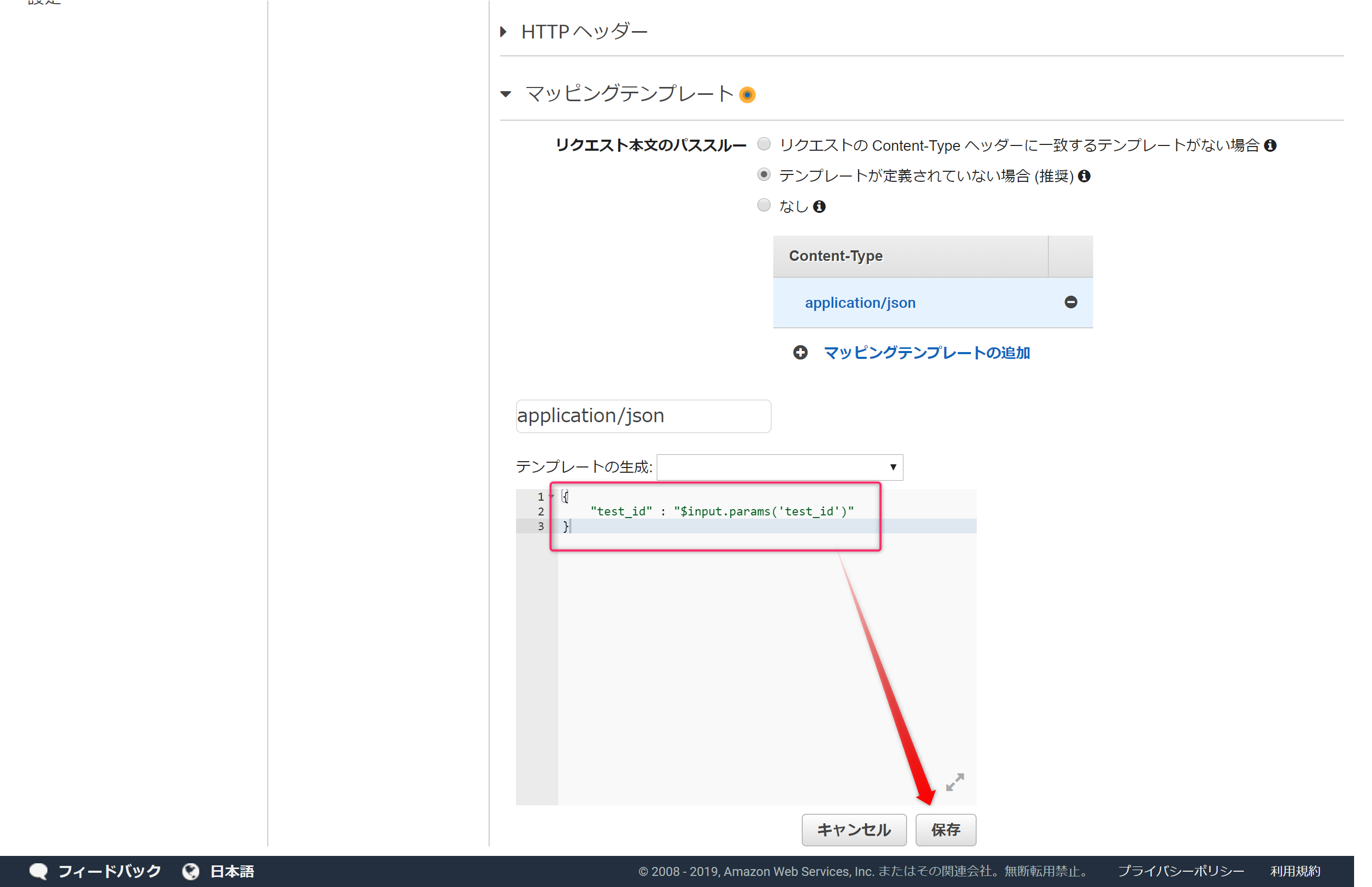
{
"test_id" : "$input.params('test_id')"
}
APIをインターネットに公開するため、「アクション」より「APIのデプロイ」をクリックします。
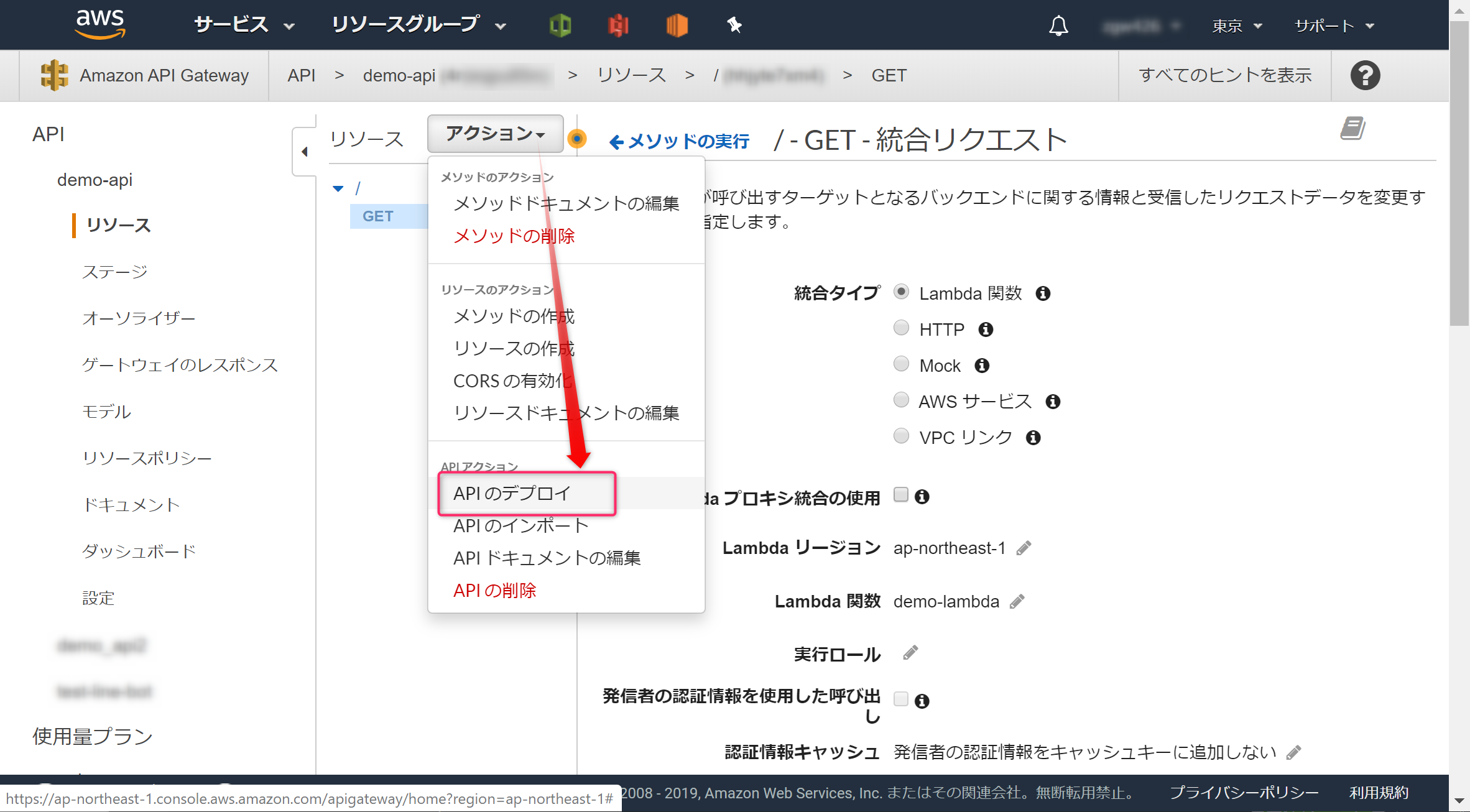
[ステージ名]を入力し(demoと入力)「デプロイ」ボタンをクリックします。

これで、インターネットからアクセスできるAPIができました。[URLの呼び出し]のURLがアクセスするためのURLになります。
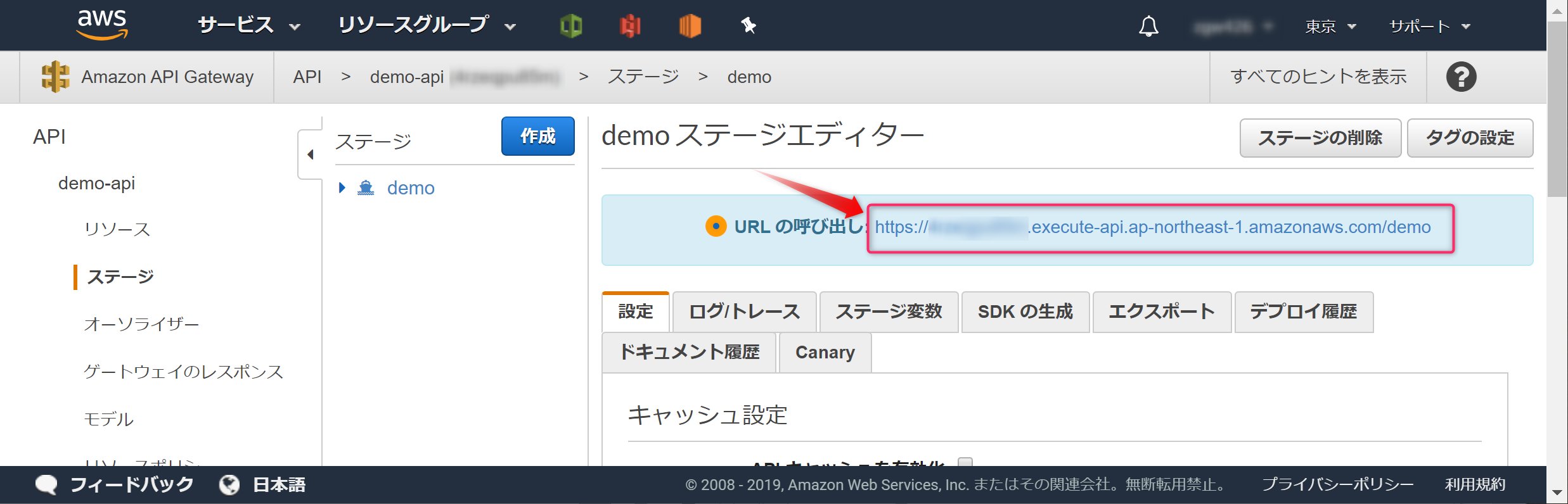
APIの動作を確認します。[URLの呼び出し]のURLの末尾に?test_id=長月花を追加しブラウザで開きます。
https://xxxxx.execute-api.ap-northeast-1.amazonaws.com/demo?test_id=長月花
このように情報が表示されれば成功です。

データベースに登録されていない言葉を指定した場合、?の情報が表示されれば成功です。
https://xxxxx.execute-api.ap-northeast-1.amazonaws.com/demo?test_id=ああああああ

※日本語がエンコードされていて読み難い場合は、URLエンコード・デコードなどでデコードします。
これで、辞書用のAPIができました。ですが、データベースにはほとんど情報が入っていません。辞書APIらしく、大量の情報を持たせていきます。
3.辞書データを作ろう
辞書データを作るため、日本語 WordNetのデータを加工して、言葉とその言葉の意味をまとめたcsvファイルを作成します。さらにそのデータをDynamoDBにインポートできる形式に変換します。
3-1.WordNetのデータを取得しよう
http://compling.hss.ntu.edu.sg/wnja/index.ja.htmlから、wnjpn.db.gzをダウンロードし解凍してwnjpn.dbを取得します。
※wnjpn.dbは、SQLite形式のデータベースです。
3-2.WordNetのデータwnjpn.dbから辞書データ(csvデータ)を作ろう
wnjpn.dbには類似語など様々情報があります。今回は辞書データを作りたいので、言葉(カラム名 test_id)と言葉の意味(カラム名 name)のcsvファイルを作成します。
AnacondaでPythonスクリプトを使いwnjpn.dbの情報を操作します。
import sqlite3
conn = sqlite3.connect("wnjpn.db")
def SearchSimilarWords2(wordid):
cur = conn.execute("select wordid,lemma from word where wordid='%s'" % wordid)
for row in cur:
word_id = row[0]
word = row[1]
if word != "":
cur = conn.execute("select synset from sense where wordid='%s'" % word_id)
synsets = []
for row in cur:
synsets.append(row[0])
no = 1
for synset in synsets:
cur2 = conn.execute("select def from synset_def where (synset='%s' and lang='jpn')" % synset)
sub_no = 1
tmpStr = ""
for row2 in cur2:
tmpStr += "("+ str(sub_no) + ") " + row2[0] + "";
sub_no += 1
outStr = ""
outStr = "\"" + word + "\"" + "," + "\"" + tmpStr + "\"" + "\n"
return(outStr)
path_w = 'qiita-dictionalyFromWordnet000.csv'
with open(path_w, mode='w', encoding="utf_8") as f:
# 全ての wordid を取得
wdid = conn.execute("select wordid from word")
debugMax = 9999999
debugNo = 0
f.write("\"test_id\",\"name\"\n")
for row in wdid:
if debugNo >= debugMax:
print("break")
break
else:
debugNo += 1
word_id = row[0]
f.write( SearchSimilarWords2(word_id) )
実行すると、qiita-dictionalyFromWordnet000.csvというcsvファイルが出力されます。中身は↓こんな感じです。

3-3.csvファイルを加工しよう
作ったqiita-dictionalyFromWordnet000.csvを更に加工して、新たなcsvファイルを作成します。言葉(カラム test_id)は、重複するとDynamoDBにインポートする際にエラーになるので、言葉(test_id)が重複する場合は、削除しておきます(ほんとは結合した方がいいけど、まぁいいや)
import pandas as pd
csvFile = "qiita-dictionalyFromWordnet000.csv"
hoge = pd.read_csv(csvFile,
parse_dates=[1], # 対象のカラムインデックス
names=['test_id', 'name'],
dtype={2: str} # カラムインデックスと型の dict
)
# 重複を削除するために先にソート
sorted_hoge = hoge.sort_values(['test_id', 'name'], # カラム名
ascending=[1, 0]) # desc か asc か
# 重複削除
no_duplicated_hoge = sorted_hoge.drop_duplicates('test_id', # このカラムで重複していると、
keep='first') # 最初を残すようにする
# csv 出力
no_duplicated_hoge.to_csv("qiita-dictionalyFromWordnet001_s.csv", index=False,columns=['test_id','name'])
スクリプトを実行すると、qiita-dictionalyFromWordnet001_s.csvが出力されます。この時点で、約24万語の言葉の意味のcsvデータが完成しました。
3-4.'(シングルクォーテーション)を削除しよう
qiita-dictionalyFromWordnet001_s.csvをテキストエディタで開き、'(シングルクォーテーション)を全て削除します。'(シングルクォーテーション)があると、DynamoDBへインポートするときにエラーが発生しました。
※ '(シングルクォーテーション)削除もPythonスクリプトで実施したかったのですが、やり方がわかりませんでした。
3-5.DynamoDBにインポートできる形式に加工しよう
DynamoDBに大量にデータをインポートする場合は、AWS Data Pipeline(以後 DataPipeline)を使用します。1行1JSONの形式にすることで、DataPiplelineに対応したファイルになります。
import pandas as pd
csvFile = "qiita-dictionalyFromWordnet001_s.csv"
hoge = pd.read_csv(csvFile,
parse_dates=[1], # 対象のカラムインデックス
names=['test_id', 'name'],
dtype={2: str} # カラムインデックスと型のdict
)
path_w = 'qiita-dictionalyFromWordnet004_s.json'
with open(path_w, mode='w', encoding="utf_8") as f:
debugMax = 599999999999
debugNo = 0
item00 = ""
item01 = ""
tmpStr = ""
for index,item in hoge.iterrows():
if debugNo == debugMax:
break
else:
debugNo += 1
if debugNo == 1:
item00 = item['test_id']
item01 = item['name']
else:
tmpStr+= "{"
tmpStr+= "\"" + item01 + "\":{\"s\":\"" + str(item['name']) + "\"}"
tmpStr+= ","
tmpStr+= "\"" + item00 + "\":{\"s\":\"" + str(item['test_id']) + "\"}"
tmpStr+= "}\n"
#print( tmpStr )
f.write( tmpStr )
tmpStr = ""
スクリプトを実行するとqiita-dictionalyFromWordnet004_s.jsonが出力されます。また、出力ファイルの文字コードは、UTF-8(BOMなし)にします。
qiita-dictionalyFromWordnet004_s.jsonの中身はこんな感じです。

{"name":{"s":"(1) 牛を育てる(あるいは世話をする)人"},"test_id":{"s":"beef_man"}}
{"name":{"s":"(1) 1979年から1990年までニカラグアの反革命的なゲリラ部隊(2) 左翼政府に対抗するのに、米国の援助を受けた"},"test_id":{"s":"contras"}}
{"name":{"s":"(1) 誰かが暮らしている住宅"},"test_id":{"s":"dwelling"}}
{"name":{"s":"(1) 文や韻文の行に加えられる、独立した意味を持たない語やフレーズ"},"test_id":{"s":"expletive"}}
{"name":{"s":"(1) 発疹のあとに目立った赤い斑点が出来る、非常に感染力の強いウィルス性の急性の病気(2) 小児に多く見られる"},"test_id":{"s":"measles"}}
これで、DataPipelineで、辞書データをインポートする準備ができました。
4.AWS DataPipelineで辞書データをDynamoDBにインポートしよう
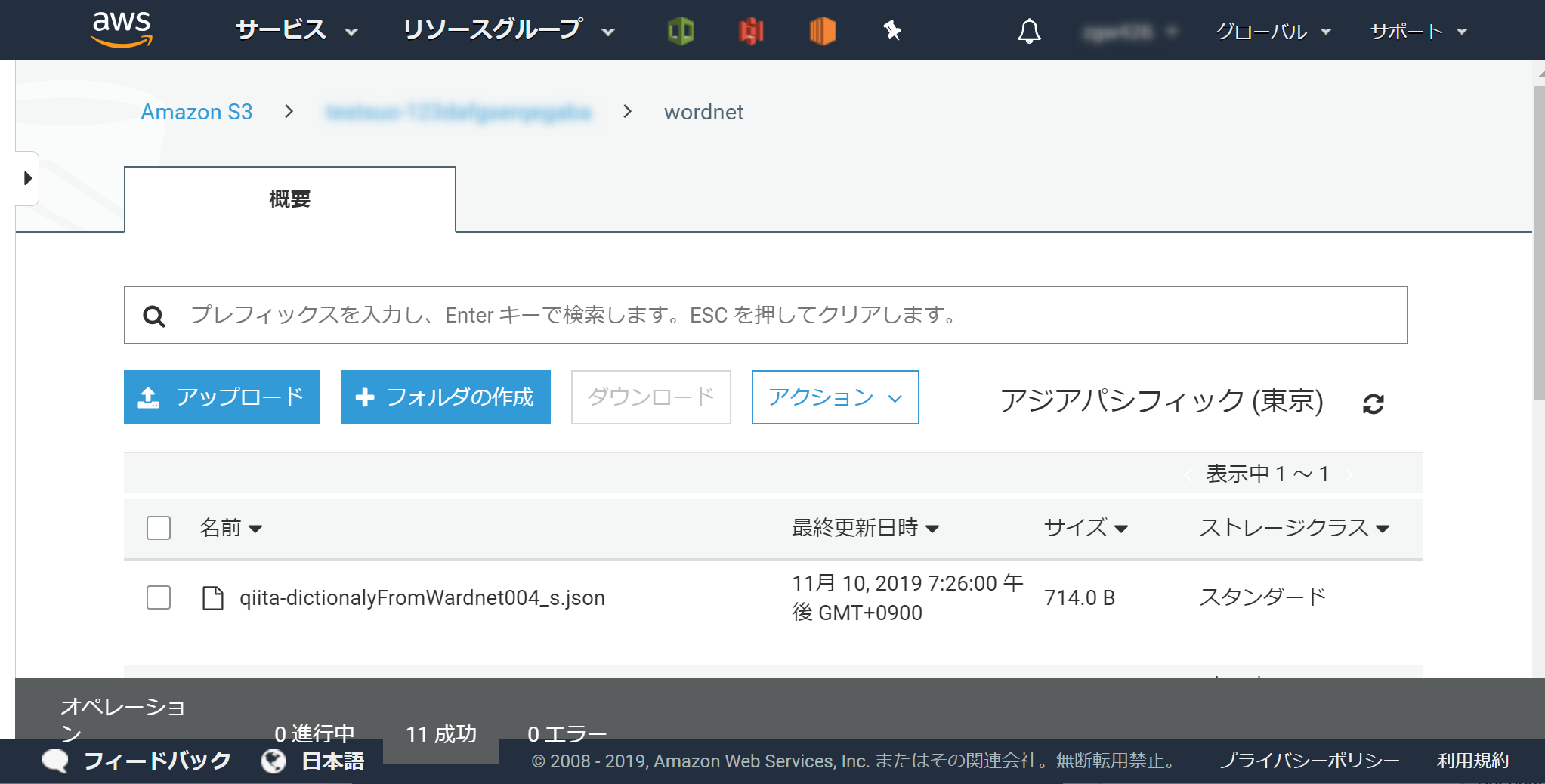
qiita-dictionalyFromWordnet004_s.jsonをS3バケットに格納します。
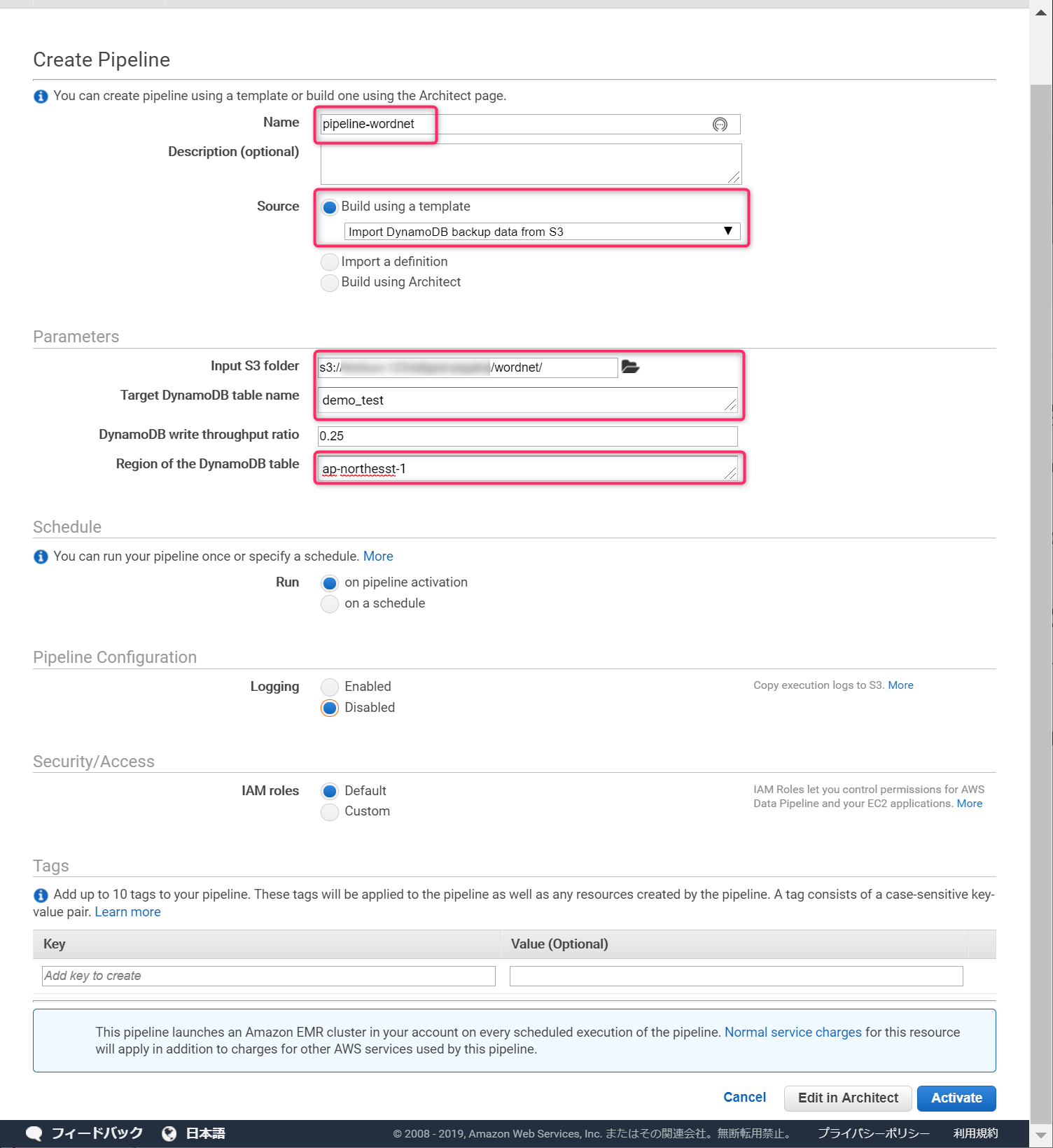
AWSコンソールから、DataPipelineを開き、Get Start nowボタンをクリックします。

nameは適当に入力します。Sourceは、Import DynamoDB backup from S3にし、DynamoDBのテーブル名などを入力します。Input S3 folderは、格納したファイルではなく、格納したファイルのあるフォルダーを指定します。
[Activate]ボタンをクリックすると、インポートの準備が開始されます。
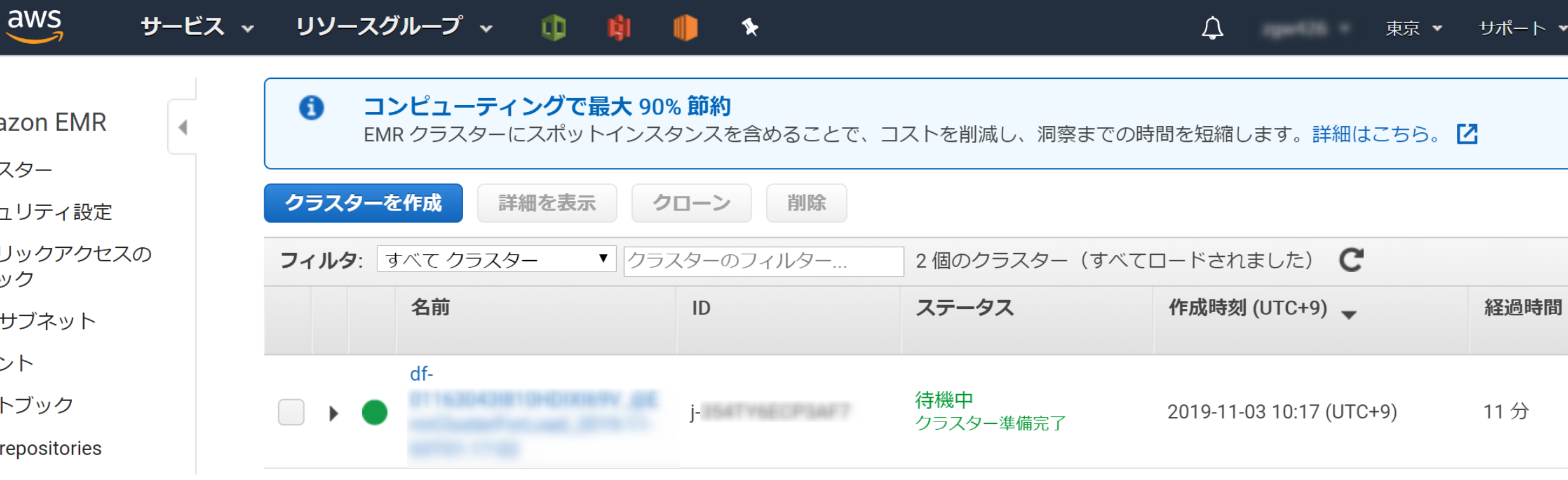
インポート処理が開始されてから、DynamoDBテーブルを確認し、データが追加されていれば成功です。(EMRの構築などで時間かかるので気長に待ちます)
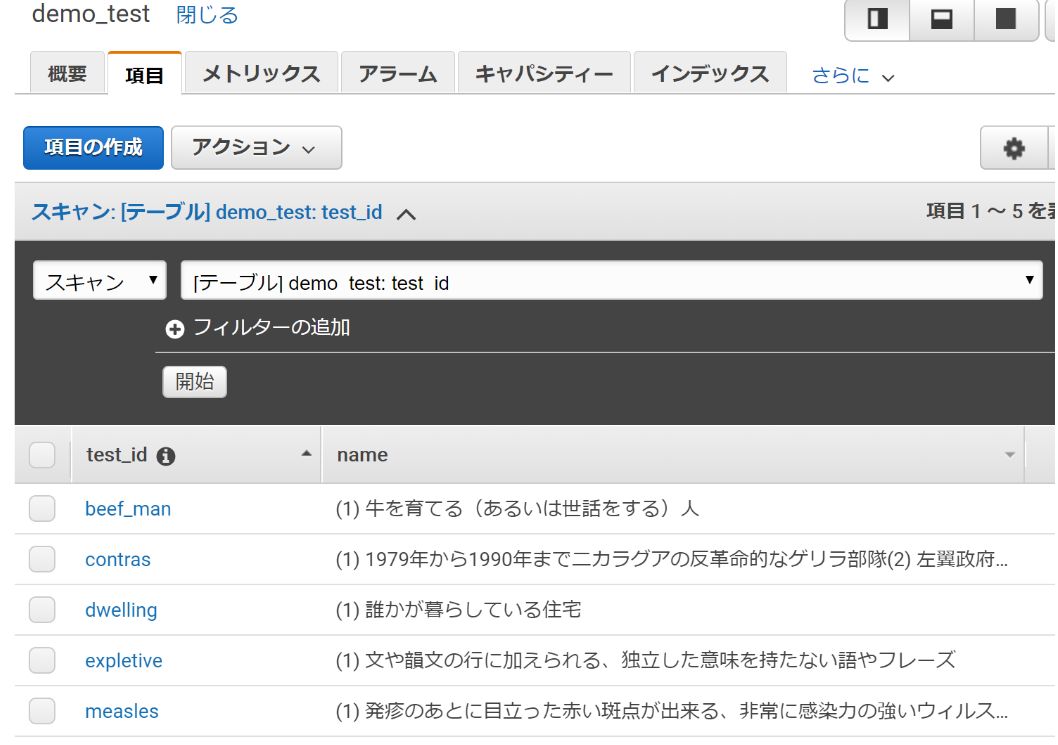
※辞書データ24万語の全てを登録するには70時間くらいかかるので8万語で止めました。
DynamoDBにデータをインポートしたら辞書APIの完成です。
※注意事項※ AWS Data Pipelineの利用料について
DataPipelineは、EMRを使ってインポート処理を行います。今回は、デフォルト設定を使ったので、マスターに、m3.xlargeインスタンスを1つ、コアにm3.xlargeインスタンスを1つ起動しました。この設定だと、8.5時間で約3万語をインポートできました。つまり、24万語すべてをとうろくするには68時間くらい必要になります。お金も時間もそれなりに使うので、今回は8万語でインポートを止めました。8万語の登録でAWS利用料は2000円くらいかかったと思います。
5.辞書APIをLINE Botと連携しよう
APIと連動するLINE Botに辞書APIのURLを設定すれば完了です。
const getNodeVer = async (userId, argKey) => {
//辞書API
let apiUrl = 'https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/demo?test_id='+ argKey; // ←ここに辞書APIのURLを設定します。
apiUrl = encodeURI(apiUrl); // URLエンコード
const res = await axios.get( apiUrl );
console.log(res.data.name);
await client.pushMessage(userId, {
type: 'text',
text: res.data.name,
});
}
これで、8万語の辞書データを持つインテリBotが完成しました。
インテリBotを使おう
インテリに生まれ変わったLINE Botに言葉の意味を聞いてみます。
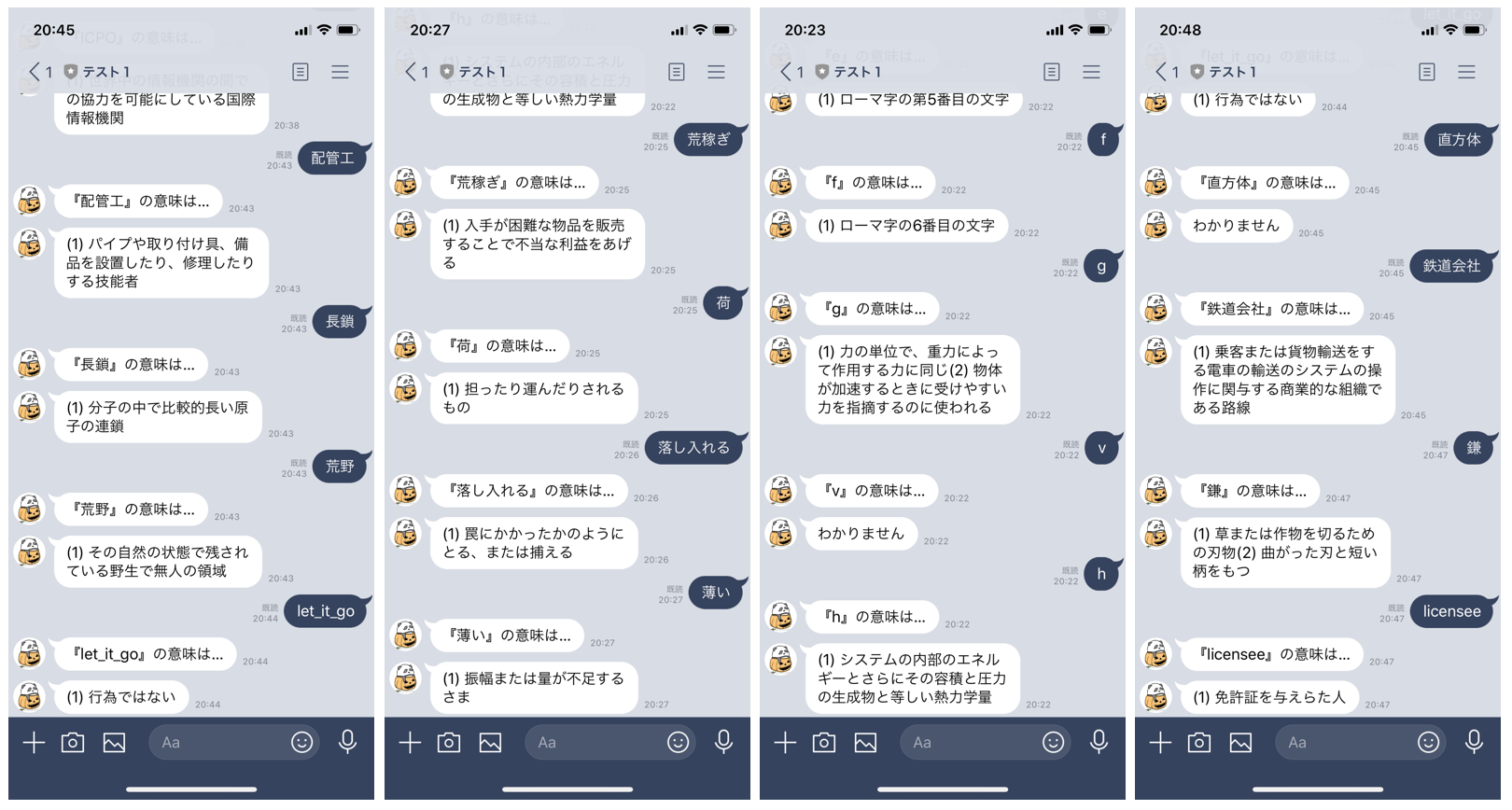
おぉー、ちゃんとデータベースから言葉の意味を取り出してくれました。リベンジ達成です!ブラボー!!
他にも言葉の意味を聞いたのですが、個人的に気に入ったのが、$ の意味でした。
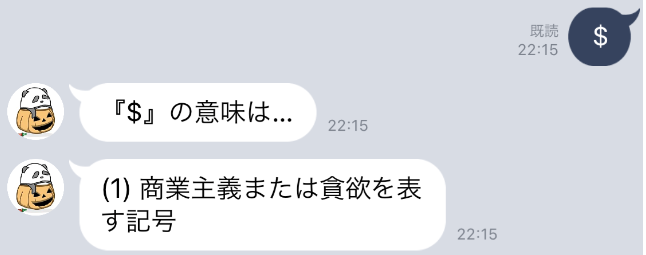
貪欲を表す記号?・・・こーいうことかっ!

参考情報とかトラブルシュートとか
インテリBotを作る過程でわかったこととか紹介します。
ホントはIAMロールでアクセス権の設定も必要
API Gatewayを作る際、IAMロールで必要最低限の権限のみ付与した方がセキュリティ的に安全です。
API Gatewayのアクセス制御もした方がいい
今回、API Gatewayで作成したAPIのURLは、インターネット上のどこからでもアクセスできる状況です。API Gatewayは実行した回数などで使用料が発生するので、嫌がらせ(何回もアクセスされる)によって利用料が高額になる可能性があるので注意が必要です。
API Gatewayのリソースポリシーなどでアクセス制限するなどの対策が必要と思います。
100程度の情報をDynamoDBに登録するならaws cliの方が速いし安い
DynamoDBへのデータインポートにAWS Data Pipelineを使いましたが、100程度であれば aws cliの方が速いし安いと思います。ただし、aws cliで一度に登録できるのは25程度なので、JSONファイルを分割しないと、以下のエラーが発生します。
com.amazonaws.dynamodb.v20120810.WriteRequest@99999999, com.amazonaws.dynamodb.v20120810.WriteRequest@99999999, com.amazonaws.dynamodb.v20120810.WriteRequest@99999999, com.amazonaws.dynamodb.v20120810.WriteRequest@99999999, com.amazonaws.dynamodb.v20120810.WriteRequest@99999999, com.amazonaws.dynamodb.v20120810.WriteRequest@99999999]}' at 'requestItems' failed to satisfy constraint: Map value must satisfy constraint: [Member must have length less than or equal to 25, Member must have length greater than or equal to 1]
aws cliでインポートする場合は、辞書の情報をJSON形式で作成しdictionalyFromWordnet.jsonとします。JSONファイルの文字コードは、Shift-JISにしてください。
aws dynamodb batch-write-item --request-items file://dictionalyFromWordnet.json
json:dictionalyFromWordnet.json内のdemo_testはDynamoDBのテーブル名です。
{
"demo_test": [
{
"PutRequest": {
"Item": {
"test_id": {"S":"単語"},
"name": {"S":"単語の意味"}
}
}
},
{
"PutRequest": {
"Item": {
"test_id": {"S":"Amazon DynamoDB"},
"name": {"S":"Amazon Web Services"}
}
}
},
]
}

aws cli実行時に以下のエラーが発生した場合は、JSONファイルの形式が UTF-8 , UTF-8(BOMなし)のいずれかの可能性があります。私の場合は、JSONファイルをShift-JISに変換するとエラー回避できました。
PS C:\Users\hoge\fugabot> aws dynamodb batch-write-item --request-items file://dictionalyFromWordnet.json
Error parsing parameter '--request-items': Unable to load paramfile (dictionalyFromWordnet.json), text contents could not be decoded. If this is a binary file, please use the fileb:// prefix instead of the file:// prefix.
DynamoDBへのインポートファイルのフォーマットを確認する方法
インポート用のファイルのフォーマットが不明な場合は、Datapipelineを使いDynamoDBのデータをインポートすると確認できます。
インポートで出力されたファイルと同じフォーマットにすれば、インポート用のファイルが作れます。ファイルの文字コードは UTF-8 (BOMなし) にします。
Datapipeline実行時に以下のようなエラーがでたら、JSONファイルに何か問題がある可能性があります。
| Stdout* | Stderr*
Caused by: com.amazonaws.services.dynamodbv2.model.AmazonDynamoDBException: Supplied AttributeValue is empty, must contain exactly one of the supported datatypes
考えられる問題
- 文字列に '(シングルクォーテーション)が含まれている
- JSONファイルの文字コードがUTF-8(BOMなし)以外である
- フォーマットに誤りがある
(→本記事の『DynamoDBへのインポートファイルのフォーマットを確認する方法』が参考になるかも)
DynamoDBへのデータ登録
DynamoDBにデータを登録する2つの方法(aws cli と Data Pipeline)の違いをまとめてみました。
| aws cli | Data Pipeline | |
|---|---|---|
| 文字コード | Shift-JIS | UTF-8(BOMなし) |
| フォーマット | JSON | 1行1JSON |
| 1回あたりの登録数 | 1-25 | 数万とか余裕 |
| 時間 | 1分かからない | EMR環境構築に10分くらい、その後からインポート開始 |
おわりに
一度は挫折した辞書APIを今回は作ることができました。リベンジ成功です。
WordNetには、類義語の情報などもあり、機械学習の研究に利用されることもあるそうです。辞書APIを進化させて、自動で文章を作成するとか、人間っぽい文章を作成するとか、そーいうことも挑戦しようかと思います。