はじめに
モチベーション
技術の時系列変化、例えば、AIとかコンテナとかの流行が見えるか見てみたかった。とはいえ、前回、トピック分類に若干失敗していたので、期待半分。
対象文書
前回の記事と同じくqiitaの記事です。
使ったライブラリ
Dynamic Topic Modelsもgensimで利用できるのでこれを使います。
https://radimrehurek.com/gensim/models/wrappers/dtmmodel.html
参考記事
DTMについて
gensimの利用方法について
- https://markroxor.github.io/gensim/static/notebooks/dtm_example.html
- https://markroxor.github.io/gensim/static/notebooks/ldaseqmodel.html
gensimにはldaseqmodelもあるようですが、違いは調べきれてません。LDAもDTMも提案したDavid M. Blei氏のlabの同じ実装をどっちも参考にしているようです。
qiita記事のクロール
最新の記事を取得するのではなく、一定期間ごとに一定量の記事を取得します。qiitaの検索では、created:>2015-05-01 created:<2015-05-31のようなクエリを使って、作成日で絞り込むことができます。例えば、こんな感じ。前回の実装を元に、queryをパラメータに加え、max_pageを10程度に抑え、月ごとに1000ページ程度収集するようにしました。
2014/10〜2018/09中に作成された記事を利用します。
from dateutil.rrule import MONTHLY, rrule
from datetime import date
from dateutil.relativedelta import relativedelta
# (中略)
def start_requests(self):
start_url = "https://qiita.com/api/v2/items/?page={}&per_page={}&query=created:>{} created:<{}"
headers = {'Authorization' : "Bearer {}".format(QiitaSpider.authorization_token) }
for month in rrule(MONTHLY, dtstart=self.dtstart, until=self.until):
next_month = month + relativedelta(months=1)
month_last_date = next_month - relativedelta(days=1)
for i in range(1, 1 + self.max_page):
url = start_url.format(i, self.per_page, month.strftime('%Y-%m-%d'), month_last_date.strftime('%Y-%m-%d'))
yield scrapy.Request(url = url, callback=self.parse, headers=headers)
前処理
前処理もほぼ一緒。ですが、DTMにはtime_slicesが必要なので、予めitemsをcreated_atで昇順にsortしておきます。time_seriesの指定は、ちょっと特殊で、同一のtimeとみなす文書の数を頭から並べるようです。
例えば、文書の作成年月が
文書1: 2018/01
文書2: 2018/01
文書3: 2018/01
文書4: 2018/02
文書5: 2018/02
とあるとき、time_slices = [3, 2]というように指定します。
今回は月で分け、こんな感じで作りました。
import collections
times = [item['created_at'].strftime("%Y%m") for item in items]
counter = collections.Counter( times )
# 個数を元にtime_slicesを構成
time_slices = [counter[key] for key in sorted(counter.keys())]
# 以下、可視化時に利用
# YYYYMM -> index
time_slice_dict = { key:index for index, key in enumerate(sorted(counter.keys()))}
# index -> YYYYMM
time_slice_keys = [ key for key in sorted(counter.keys())]
# アイテムごとのindex
time_slice_of_items = [ time_slice_dict[time] for time in times]
time_slices はこんな感じ。5いいね以上の記事を対象にしていますが、今回queryで制約かけてないので年々減ってますね…
time_slices = [695, 640, 615, 614, 544, 564, 569, 564, 564, 544, 548, 577, 518, 508, 560, 582, 556, 519, 513, 498, 498, 433, 417, 445, 439, 351, 348, 392, 387, 352, 309, 352, 341, 297, 338, 310, 302, 352, 295, 244, 260, 220, 226, 183, 161, 160, 140, 102]
DTM
DTMのInstallationに従って、dtmのバイナリを入れておきます。
from gensim.models.wrappers import DtmModel
num_of_topics = 10
path_to_dtm_binary = "./dtm-linux64"
dtm_model = DtmModel(
path_to_dtm_binary, corpus = corpus, id2word = dictionary,rng_seed=2,
num_topics=num_of_topics, time_slices = time_slices
)
文書数も多いので、実行時間は3時間近くかかりました。dtm_model.saveしておきましょう。
まずは、以下のようなコードでtimeごとのトピックを見てみます。
数が多いので、2014/10(time=0), 2018/02(time=40)のみを抜粋します。
for time,_ in enumerate(time_slices):
print(" ========= time", time, "month:", time_slice_keys[time] )
for topic_id in range(0, 10):
print("topic_id" , topic_id)
print(dtm_model.print_topic(topic_id, time))
2014/10
========= time 0 month: 201410
topic_id 0
0.039*js + 0.026*html + 0.019*javascript + 0.013*ファイル + 0.012*css + 0.011*タグ + 0.010*jquery + 0.010*http:// + 0.009*react + 0.009*ブラウザ
topic_id 1
0.015*アプリ + 0.012*api + 0.010*人 + 0.009*画面 + 0.009*hubot + 0.008*情報 + 0.007*自分 + 0.007*記事 + 0.007*google + 0.006*アプリケーション
topic_id 2
0.027*関数 + 0.020*コード + 0.018*クラス + 0.018*引数 + 0.018*メソッド + 0.015*値 + 0.014*文字列 + 0.014*変数 + 0.012*型 + 0.011*オブジェクト
topic_id 3
0.028*ファイル + 0.020*コマンド + 0.012*インストール + 0.010*go + 0.009*ディレクトリ + 0.008*mac + 0.007*windows + 0.007*vim + 0.007*環境 + 0.007*パッケージ
topic_id 4
0.034*php + 0.020*rails + 0.017*ruby + 0.010*rb + 0.010*url + 0.009*ファイル + 0.008*api + 0.008*app + 0.008*id + 0.007*データ
topic_id 5
0.042*インストール + 0.017*docker + 0.015*環境 + 0.013*コマンド + 0.011*vagrant + 0.011*ruby + 0.010*centos + 0.009*コンテナ + 0.009*ssh + 0.009*heroku
topic_id 6
0.023*android + 0.015*ios + 0.013*xcode + 0.012*swift + 0.011*アプリ + 0.010*the + 0.010*to + 0.008*gradle + 0.007*java + 0.007*プロジェクト
topic_id 7
0.014*aws + 0.014*http:// + 0.012*データ + 0.010*インスタンス + 0.008*ruboty + 0.008*コマンド + 0.007*サーバー + 0.007*ec2 + 0.007*テーブル + 0.007*java
topic_id 8
0.012*ボックス + 0.012*unity + 0.012*イベント + 0.011*状態 + 0.009*オブジェクト + 0.008*プロセス + 0.008*パラメータ + 0.008*view + 0.007*メソッド + 0.007*クラス
topic_id 9
0.020*データ + 0.015*画像 + 0.011*http:// + 0.009*e3 + 0.009*ロボット + 0.009*動画 + 0.008*シェーダ + 0.006*色 + 0.006*python + 0.005*記事
2018/02
========= time 40 month: 201802
topic_id 0
0.044*js + 0.018*javascript + 0.016*react + 0.016*vue + 0.015*html + 0.015*css + 0.012*ファイル + 0.009*node.js + 0.008*json + 0.008*コンポーネント
topic_id 1
0.010*自分 + 0.010*人 + 0.010*google + 0.009*記事 + 0.007*api + 0.007*アプリ + 0.007*コード + 0.007*情報 + 0.006*ユーザー + 0.006*アカウント
topic_id 2
0.030*関数 + 0.019*メソッド + 0.018*コード + 0.017*変数 + 0.015*クラス + 0.015*型 + 0.013*値 + 0.012*引数 + 0.009*例 + 0.009*要素
topic_id 3
0.016*ファイル + 0.014*コマンド + 0.013*インストール + 0.011*windows + 0.007*方法 + 0.007*linux + 0.006*emacs + 0.006*環境 + 0.005*キー + 0.005*カーネル
topic_id 4
0.033*php + 0.017*api + 0.013*id + 0.011*json + 0.010*laravel + 0.010*ファイル + 0.009*app + 0.009*情報 + 0.008*データ + 0.008*url
topic_id 5
0.027*docker + 0.026*インストール + 0.024*環境 + 0.017*コマンド + 0.016*python + 0.012*git + 0.012*コンテナ + 0.012*ファイル + 0.008*yml + 0.008*ディレクトリ
topic_id 6
0.016*android + 0.014*to + 0.014*the + 0.013*アプリ + 0.011*ios + 0.009*in + 0.008*github + 0.007*for + 0.007*swift + 0.006*on
topic_id 7
0.023*aws + 0.014*cloud + 0.011*api + 0.010*lambda + 0.009*インスタンス + 0.008*情報 + 0.007*azure + 0.006*サーバー + 0.006*データ + 0.006*java
topic_id 8
0.012*unity + 0.012*イベント + 0.011*データ + 0.008*コード + 0.007*オブジェクト + 0.007*状態 + 0.007*アドレス + 0.006*メソッド + 0.006*記事 + 0.006*view
topic_id 9
0.027*データ + 0.015*画像 + 0.010*python + 0.009*モデル + 0.007*関数 + 0.006*値 + 0.006*記事 + 0.005*グラフ + 0.005*機械学習 + 0.005*方法
topic:0はjs関連、2は言語、3は開発環境、5はWeb、5はコンテナ、6はモバイル7はクラウド?、8はunity?、9は機械学習っぽい。
次は、トピックごとの上位文書です。
import numpy as np
documents_topics = np.zeros([num_of_topics, len(corpus)])
for topic_id, probs in enumerate(dtm_model.gamma_.transpose()):
print("==============")
print("topic_id", topic_id, ":", dtm_model.print_topic(topic_id, time=0))
for doc_id in probs.argsort()[::-1][:5]:
print("\t", probs[doc_id], time_slice_of_items[doc_id],items[doc_id]['title'], items[doc_id]['url'] )
==============
topic_id 0 : 0.039*js + 0.026*html + 0.019*javascript + 0.013*ファイル + 0.012*css + 0.011*タグ + 0.010*jquery + 0.010*http:// + 0.009*react + 0.009*ブラウザ
0.9998105661965903 30 2017年4月版 jsライブラリ環境作成 https://qiita.com/darquro/items/32515c31ce56a9b92704
0.9997534921939195 36 シンプルだけどシッカリ働く最新のECMAScript開発環境 https://qiita.com/zprodev/items/9d611a482715fa64512b
0.9997407087294728 10 jspmを使ってシンプルな構成でES6アプリをつくる(ついでにElectron) https://qiita.com/yuki-takei/items/d38653945f2623facfd3
0.9997223079296514 37 React 入門 - webpack 導入編 https://qiita.com/jwhaco/items/2783495b1ac5c49c0f75
0.9997020854021847 26 WebpackってCSS周りのLoaderがいっぱいあって分かりにくいので整理してみる https://qiita.com/shuntksh/items/bb5cbea40a343e2e791a
==============
topic_id 1 : 0.015*アプリ + 0.012*api + 0.010*人 + 0.009*画面 + 0.009*hubot + 0.008*情報 + 0.007*自分 + 0.007*記事 + 0.007*google + 0.006*アプリケーション
0.9998809681259094 18 【噂】IT業界のウソ・ホント【闇】 https://qiita.com/netetahito/items/a317345b4e059267f879
0.999874319229158 24 Watson ConversationのTutorialを日本語でやってみた (後編) https://qiita.com/sukusuku_watson_editorial_room/items/e3111d2ccce996db7feb
0.999872358530705 43 DevOpsを知ったかぶりしていた私が、チームの人とつまづきながらカイゼン・ジャーニーしている話。 https://qiita.com/nh321/items/767bc09aa72b54807fe8
0.9998705222270178 44 片手間にはじめるUXデザイン - ノンUXデザイナーズUXデザイン - https://qiita.com/arowM/items/cda86ffba94834534732
0.9998602701443876 46 ソフトウェア開発に役立つ 心理学的現象、行動経済学の概念など 15題 https://qiita.com/arai-wa/items/4c7629276ced7e933235
==============
topic_id 2 : 0.027*関数 + 0.020*コード + 0.018*クラス + 0.018*引数 + 0.018*メソッド + 0.015*値 + 0.014*文字列 + 0.014*変数 + 0.012*型 + 0.011*オブジェクト
0.9999078906969605 32 【Haskell や圏論が出てこない】Scala で型クラスを完全に理解した話 https://qiita.com/Biacco/items/9b7ec9c1050b851617a5
0.999874143476437 34 Java Collections Frameworkのおさらいメモ https://qiita.com/rubytomato@github/items/554095ae21a2c36f131a
0.999873257287706 35 Rubyのtrueとfalseの話 https://qiita.com/rotelstift/items/70461f35c0d691e7b246
0.9998652896273015 47 部分列 DP --- 文字列の部分文字列を重複なく走査する DP の特集 https://qiita.com/drken/items/a207e5ae3ea2cf17f4bd
0.9998562529947294 31 インタフェースと型クラス、どちらでもできること・どちらかでしかできないこと https://qiita.com/koher/items/ee31222b7f9b0ead3de7
==============
topic_id 3 : 0.028*ファイル + 0.020*コマンド + 0.012*インストール + 0.010*go + 0.009*ディレクトリ + 0.008*mac + 0.007*windows + 0.007*vim + 0.007*環境 + 0.007*パッケージ
0.9998652896273015 37 vim色に染まれ.機能紹介のついでにbashをvi仕様に. https://qiita.com/Pseudonym/items/2cb442ff257a2f9f9d70
0.9998524831994756 33 Linux Kernel 4.10 でのFPGAのサポート事情 https://qiita.com/ikwzm/items/2ff7d5429da8ace7c0bd
0.9997514498757251 14 Atomに三度目のチャレンジ https://qiita.com/kiyodori/items/b3f479b33cdaa828441d
0.999723162103968 1 MSYS2でWindowsにzsh環境を導入する https://qiita.com/magichan/items/7702d7865deaaca2ad44
0.9997116308875361 15 MSYS2 にてコマンドライン環境をつくる: セットアップ編 https://qiita.com/remyroez/items/757b7b769e9c5a2c4ae7
==============
topic_id 4 : 0.034*php + 0.020*rails + 0.017*ruby + 0.010*rb + 0.010*url + 0.009*ファイル + 0.008*api + 0.008*app + 0.008*id + 0.007*データ
0.9999509830619248 19 OAuth & OpenID Connect 関連仕様まとめ https://qiita.com/TakahikoKawasaki/items/185d34814eb9f7ac7ef3
0.9998429593439192 27 【Rails】いいねボタンを作ろう part1/2 https://qiita.com/mohira/items/9ae35773e6209adbf0a0
0.9998211091234348 28 Rails 初期データ投入(rake db:seed)について(Rails 4.2, Faker, Gimei, Enumerize, activerecord-import) https://qiita.com/17number/items/c500d469a8851d879737
0.9997926744989635 27 【Rails】いいねボタンを作ろう part2/2 https://qiita.com/mohira/items/148c0f6ef89e8f62df72
0.9997847404927052 28 Authlogic + Railsで認証の仕組みをシンプルに作る https://qiita.com/zaru/items/a451de2b165a9e422d62
==============
topic_id 5 : 0.042*インストール + 0.017*docker + 0.015*環境 + 0.013*コマンド + 0.011*vagrant + 0.011*ruby + 0.010*centos + 0.009*コンテナ + 0.009*ssh + 0.009*heroku
0.9998085513720486 41 Docker for Mac の NFS Volume sharing のベンチマーク結果(2018-03-29現在) https://qiita.com/kunit/items/36d9e5fa710ad26f8010
0.999806493227263 11 Docker Compose で PHP 7.0 の開発環境を構築する https://qiita.com/masakielastic/items/9fdc52b47cc7e3850b9f
0.9998013683513574 6 NetworkManager-wait-online.serviceはどのような場合にenableにすれば良いか、を理詰めで考える https://qiita.com/yunano/items/8636a6dd6becad84920d
0.9997968855788761 36 RancherでKubernetesでHelmでDockerでJenkinsを動かす方法 https://qiita.com/cvusk/items/e79cf0efb2454a195f07
0.9997710506232511 7 vagrant-cloudstack v1.0.0 の新機能紹介 https://qiita.com/atsaki/items/992d9b442c9f7caee608
==============
topic_id 6 : 0.023*android + 0.015*ios + 0.013*xcode + 0.012*swift + 0.011*アプリ + 0.010*the + 0.010*to + 0.008*gradle + 0.007*java + 0.007*プロジェクト
0.9999493556918576 27 マテリアルデザインのTextAppearanceがどのサイズでどの色かまとめ メモ https://qiita.com/takahirom/items/2def92ddeb408e7e28e9
0.9999127991473695 25 How to exchange Realm data between watchOS and iOS https://qiita.com/hsylife/items/26629e65bf66d79cd311
0.9999093746853288 16 Making Augmented Reality app easily with Scenekit + Vuforia (in English) https://qiita.com/akira108/items/a743138fca532ee193fe
0.9998512642538425 16 Tesseract OCR for Swift https://qiita.com/JasonChen/items/962e421bd305f080918c
0.999717070103741 23 Apple様からアプリへの死の宣告はどうやってくるのか?(2016年QualityAppsの件) https://qiita.com/caffezom/items/9f85c4ac372f142b702c
==============
topic_id 7 : 0.014*aws + 0.014*http:// + 0.012*データ + 0.010*インスタンス + 0.008*ruboty + 0.008*コマンド + 0.007*サーバー + 0.007*ec2 + 0.007*テーブル + 0.007*java
0.9999005634736494 28 AWS 各種サービス料金早見表 https://qiita.com/saitotak/items/cdbbdb1be80912f8bb18
0.9998557923409711 1 [JAWS-UG CLI] VPC:#1 VPC作成 https://qiita.com/tcsh/items/41e1aa3c77c469c92e84
0.9998125390543637 1 【メモ】SSL通信と電子署名と認証局と証明書について(随時修正・更新) https://qiita.com/sksmnagisa/items/4523b554298e94e10777
0.9997800048887803 15 S3+CloudFront+ACM(AWS Certificate Manager)でHTTPS静的サイトを作ってみた https://qiita.com/toshihirock/items/914f408cd565b66fe9f9
0.9997794658172017 36 Route53へのDNSとドメインの移行 https://qiita.com/gomi_ningen/items/aa6a7892cd6c1c1c3059
==============
topic_id 8 : 0.012*ボックス + 0.012*unity + 0.012*イベント + 0.011*状態 + 0.009*オブジェクト + 0.008*プロセス + 0.008*パラメータ + 0.008*view + 0.007*メソッド + 0.007*クラス
0.9998918399230862 35 ライブラリを使わずにMV*の話(iOS)〜MVC, MVP, MVVM〜 https://qiita.com/yokoyas000/items/8f4db2b3c5f622690d14
0.9998682476943346 35 ライブラリを使わずにMV*の話(iOS)~ViewとModelの役割〜 https://qiita.com/yokoyas000/items/5aeff895233f9c1af9d4
0.9997528151606702 38 WinMRで始めるMixed Reality Toolkit - Unity ~モーションコントローラ操作で発生するイベントについて https://qiita.com/miyaura/items/6419d554daeb4f366511
0.9997256933861628 4 Livetで始めるWPF(ざっくり)入門 その6 https://qiita.com/Kokudori/items/0b6a49373e64d9b6b0dd
0.9997010959814017 21 すごいErlangゆかいに学んだメモ 第14章 OTPの紹介 https://qiita.com/zenwerk/items/f61a54d603d2013d15b6
==============
topic_id 9 : 0.020*データ + 0.015*画像 + 0.011*http:// + 0.009*e3 + 0.009*ロボット + 0.009*動画 + 0.008*シェーダ + 0.006*色 + 0.006*python + 0.005*記事
0.9999399239036113 18 ニコニコ超会議2016でコメント生成AIコンテストに出てきた https://qiita.com/hidesuke/items/0342f899440394002708
0.9999326397724722 39 ディープラーニングを実装から学ぶ(6-1)学習手法(正則化) https://qiita.com/Nezura/items/f7416ad17d79ccd1eab6
0.9999118597590834 10 誤差逆伝播法のノート https://qiita.com/Ugo-Nama/items/04814a13c9ea84978a4c
0.999894254494184 45 Tomasi-Kanade法による3次元復元 https://qiita.com/IshitaTakeshi/items/297331b3878e72c65276
0.9998758791890773 7 Quaternionによる3次元の回転変換 https://qiita.com/kenjihiranabe/items/945232fbde58fab45681
なんとなく、LDAよりもうまく分かれているような…?
最後に、適当な単語で、単語のトピック別の時系列変化を見てみます。
%matplotlib inline
import matplotlib.pyplot as plt
target_terms = [dictionary.token2id[term] for term in ["vue", "react", "jquery", "kubernetes", "vagrant", "docker"]]
x = time_slice_keys
plt.figure(figsize=(13, 7))
plt.xticks(rotation=90)
for topic_id, term_topics in enumerate(dtm_model.lambda_):
for token_id, time_topics in enumerate(term_topics):
if not token_id in target_terms:
continue
token = dictionary.id2token[token_id]
y = np.exp(time_topics)
if np.max(y) < 0.003:
continue
plt.plot(x, y, label="topic:{} {}".format(topic_id, token))
plt.legend(loc = 'upper right')
plt.show()
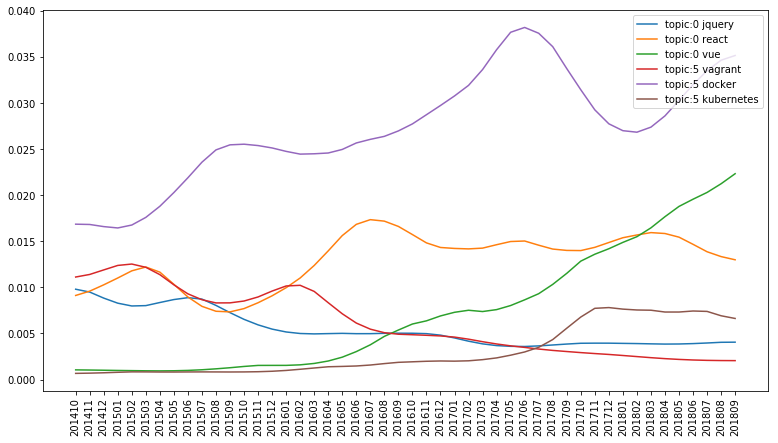
jquery->react->vueとか、vagrant->docker->kubernetesというように、技術の推移がなんとなく見えます。
考えたこと
- やっぱりソフトウェアエンジニアリングと狭い分野で適用するとトピックが分かれにくくて解釈が大変
- 上述の問題もあり、適用しどころ難しい。技術トレンド見たければ単純にいいね数の推移とかでもいいわけで。
- トピックをまたいで変化する単語を見つけたかった。これを分析しないとあまり意味ないと思う。が、そういう単語は技術分野一般に利用されることが多く、特定の複数のトピックにしか現れにくい単語はなかなかないような。