こんにちは!
食べログでデータエンジニアをしております爲岡です。
今年度付でデータサイエンスチームに異動しまして、データ基盤や機械学習基盤の構築、運用を担当させていただいています。
本記事では、食べログで利用している機械学習基盤についてのご紹介と、利用しているソフトウェアの導入経緯についてのご説明をさせていただきます。
機械学習基盤について
システム全貌
食べログの機械学習基盤の全貌を図で表すと、このようになっています。

概要説明
上記の図を参考に、機械学習基盤の概要についてざっくり説明します。
機械学習基盤について
- 現在は、機械学習基盤ではバッチ処理のみを行っており、オンラインサービスは external なものは存在しません。
- バッチ処理は Kubernetes (以降 K8s と略します) の CronJob を利用しています。
- 機械学習処理が必要な Pod に関しては Node Selector で GPU サーバを指定しておき、nvidia-docker をベースイメージにして、ホストの GPU を参照できるようにしています。
- 各ワーカーノードにマウントしている NFS を Docker コンテナ内にもマウントしており、そこに推定結果などのアウトプットを吐くようにしています。
食べログシステムへのデータの連携方法
- NFS は食べログシステムのサービスのホストにもマウントされており、機械学習基盤の Docker コンテナから push した推定結果は食べログシステムからも参照できるようになっています。
- 連携したファイルを pull してもらい、それを DB や KVS に write して、サービスで利用していただいています。
各ソフトウェアの導入経緯
各ソフトウェアを導入するに際してどのような課題があり、それをソフトウェアの導入によってどう解決したかを説明します。
説明のわかりやすさのために画像を利用しますが、本セクションで利用している画像は全てイメージです。
Docker
課題
機械学習基盤においては、当初は複数の機械学習アプリケーションを1つのホスト上で管理する想定でしたが、下記のような状況で問題が発生することがわかりました。
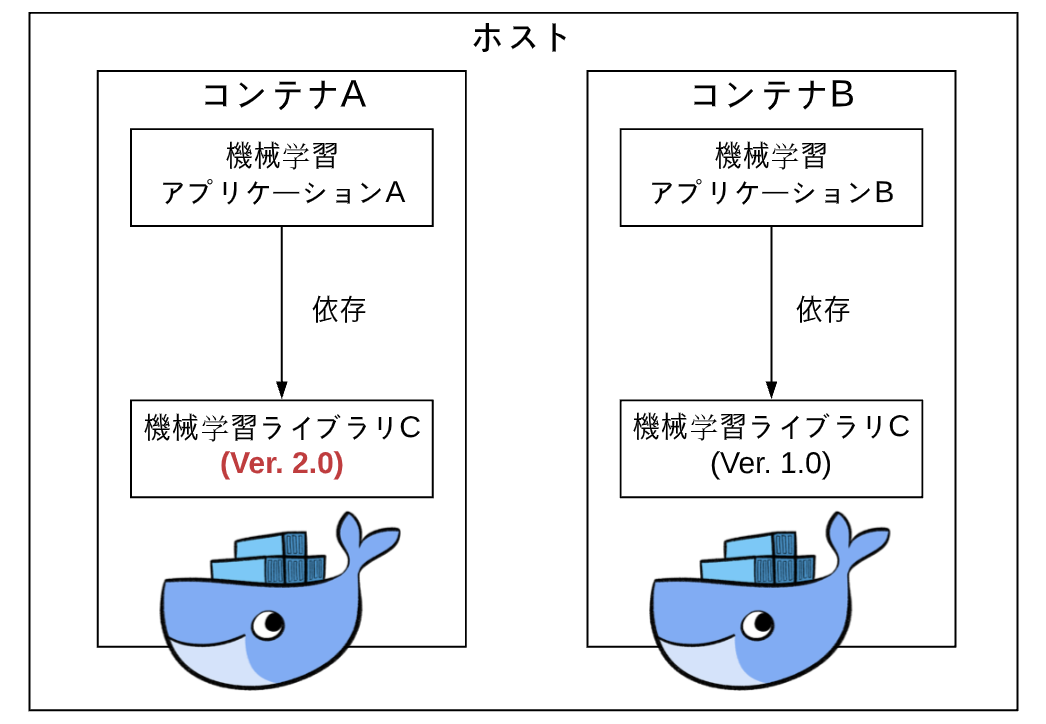
同一のホスト内で、ある機械学習アプリケーション A と、別の機械学習アプリケーション B が動作しているとします。
また、アプリケーション A と B は、同じ機械学習ライブラリ C (Ver. 1.0) を利用しているとします。

このような状況下で、アプリケーション A の機能開発時に、ライブラリ C (Ver. 2.0) の新機能を利用したい、となった場合、ライブラリ C のバージョンを上げることになるかと思いますが、その際に、同じくライブラリ C を参照しているアプリケーション B も、変更の影響を受けることになります。
要するに、アプリケーション A の変更に起因する参照先ライブラリの変更が、A とは無関係なアプリケーション B に影響してしまう状態になってしまっています。
解決方法
この問題を解決するために、Docker を利用して、各機械学習アプリケーションの実行環境を分離することで、アプリケーションをまたいで利用していたライブラリを個々のコンテナ内で別々に利用できるようにしました。
こうすることによって、1つのアプリケーションに対するソフトウェアのバージョンアップなどの変更が、別のアプリケーションに影響しなくなり、課題が解決しました。
K8s
課題
Docker コンテナを本番環境で管理、運用する際には、下記のような機構を用意する必要がありますが、これらの機能は、コンテナオーケストレーションツールと呼ばれる、コンテナ管理用のツールを用いなければ非常に困難です。
- コンテナに何らかの障害が発生した場合の自動復旧機構
- デプロイ時のアップデートや、障害発生時のロールバック機構
- 各コンテナのログの管理
解決方法
コンテナオーケストレーションツールのデファクトスタンダードである K8s を導入し、コンテナの管理、運用を行うこととしました。
Rancher
課題
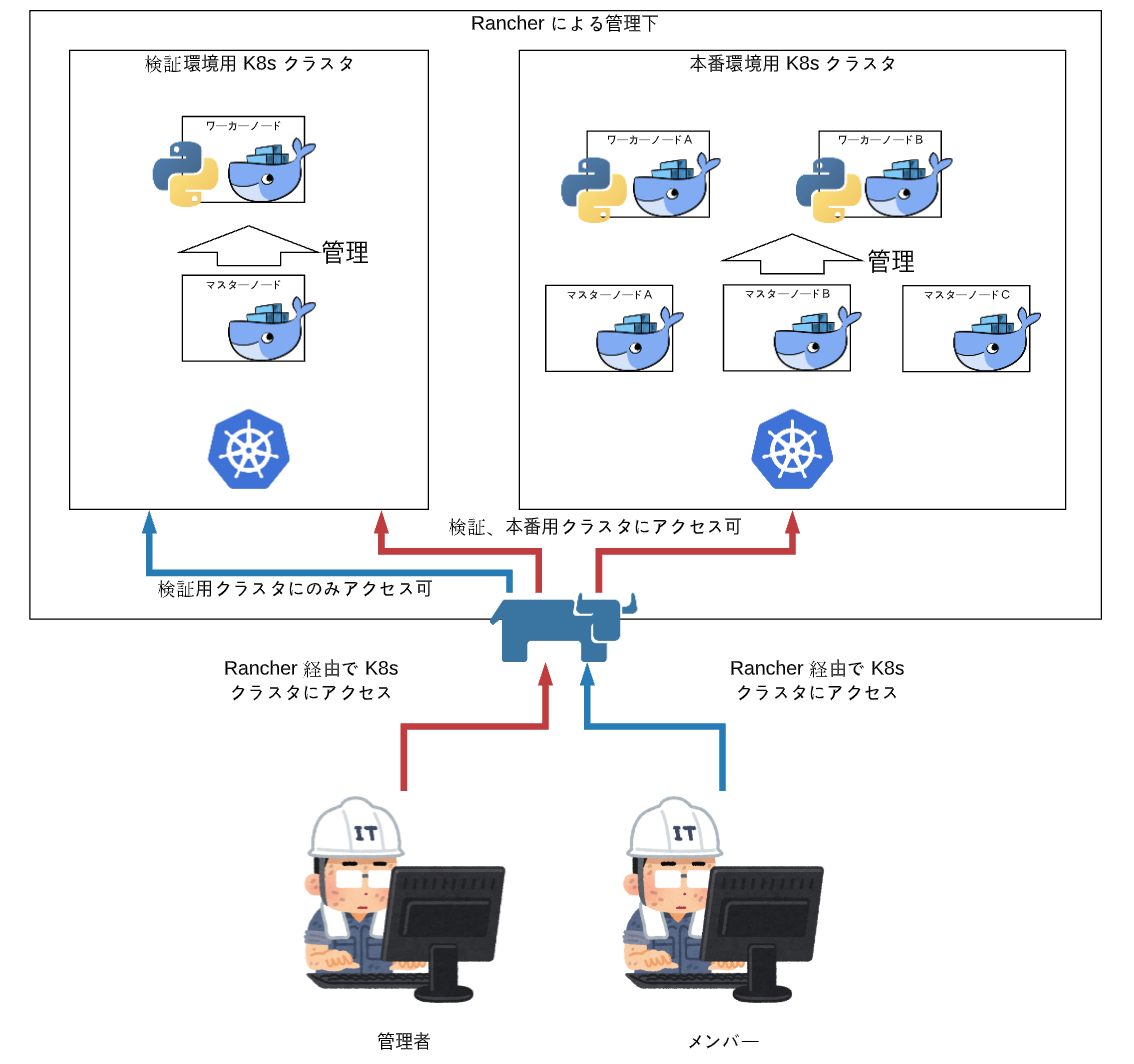
前提として、K8s にはクラスタという、複数のホストをまとめる概念があり、用途に応じてクラスタを切り分けて利用します。
例えば、下記のように検証用環境と本番環境で別々の K8s クラスタを作るようなユースケースもあります。

機械学習基盤で K8s を採用することが決まった当初、食べログシステムにおいても、いずれはコンテナを利用したサービス運用に移行していき、その際には K8s クラスタを立てることになるだろう、という展望がありました。
システム全貌にて記載したとおり、機械学習基盤と食べログシステムは NFS の1点で繋がっている疎結合なシステムであるため、K8s クラスタを別にする、というのは自然な発想に思えました。
しかし、運用に必要な下記のような要素を統一的に管理する機構が存在していなかったため、もし食べログシステムにおいて K8s クラスタを立てる場合、複数の K8s クラスタを管理することになり、系全体の運用が困難になる可能性がありました。
- マルチクラスタの一元管理
- ユーザの権限管理 (あるクラスタに関しては、あるユーザは操作できないようにする、など)
解決方法
複数の K8s クラスタを統一的に管理できる Rancher を導入することで、K8s クラスタの管理、運用を行うこととしました。
ユーザ、権限管理に関しては、各 K8s クラスタへのアクセスを全て Rancher 経由で行うよう設定することによって解決しました。
今後の展望
K8s を含むデータ系のジョブのスケジュールを一元管理したい
- 食べログ本体のバッチ処理や機械学習基盤、 DMP 上のワークフローなど、プラットフォームごとに散らばっているジョブを一元管理できるようにしたいです。
- 今のところシビアなスケジュールのジョブは存在しないので、シーケンスなジョブネットワークはジョブの完了見込み時刻で制御してますが、イケてないと思っています。
- Airflow の導入を検討中です。
Rancher, K8s クラスタの Timezone をコントロールしたい
- Rancher を利用して K8s クラスタを管理する場合は、K8s 用のプロセス (例えば kube-apiserver など) は各ホスト上で Rancher の管理する Docker コンテナの中で実行されます。
- つまり、Timezone を管理する場合は、K8s クラスタに所属しているホストごとに Timezone を設定する、ではなく、Rancher 側で Timezone を一元管理できる機構がなければなりません。
- しかし issue は挙がっているが対応されていない模様です。
- Rancher の対応を待つか、もしくは issue を立てて Pull Request を投げるしかないか?
- もし何らかの解決方法がございましたらご教授くださいmm
以上、食べログの機械学習基盤についてのご紹介と、利用しているソフトウェアの導入経緯についてのご説明をさせていただきました。
まだまだ不完全な部分も多いですが、今後も課題に対して適切な解決方法を探して、運用しやすいシステムを実現していきたいと思います。
次回は @maguhiro さんの「RxSwiftのbind関数をCombineで実装してみた」です。
お楽しみに!!