こんにちは!本記事はKaggleのアドベントカレンダーですが、
Pythonのデータ可視化ライブラリ"Plotly"の散布図プロットが
Kaggleなどのコンペと相性が良いと思ったので紹介したいと思います。
まず具体例から見ていただきたいと思います。
具体例1
単語の分散表現を3次元に次元圧縮してプロット

具体例2
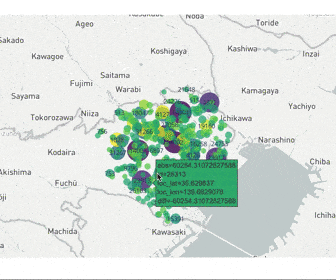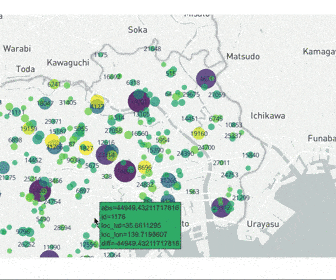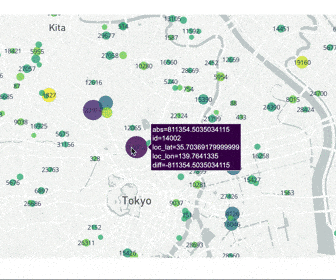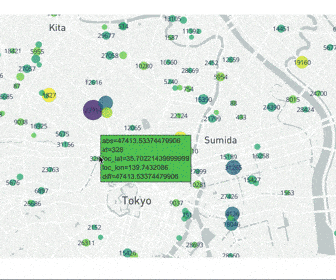
東京都23区の賃貸データを地図データにプロット
いかがでしょうか!
これらの情報量の多いプロットが数行でかけてしまうのが強みです。
Pythonの可視化ライブラリは数多くありますが、
Plotlyには以下のような他にはない特徴があるかと思います。
- 数行で書くことができる
- インタラクティブに使用できる
- ズームできるので細かいところまで確認できる
- サイズ,X,Y,Z,カラーで5変数の情報を一度に確認できる
- マウスポイントすると、その要素の情報を確認できる
- 共有することができる
では先ほどのプロットについて、記法など細かく見ていきましょう
環境
Python 3.7.4
plotly 4.1.0
具体例1
使用データセット
単語の分散表現を次元圧縮したものを用意しました。
今回はコーパスはtext8,学習はgensimのword2vecクラス、次元圧縮はt-sneを用いています。
準備をした分散表現と単語をpandasのDataFrameに格納します。

(text8についてはhttps://hironsan.hatenablog.com/entry/japanese-text8-corpus を参考にさせていただきました。)
コード
import plotly.express as px
fig = px.scatter_3d(df, x='x', y='y', z='z',text='word')
fig.show()
説明
たった3行で書くことができます。
データフレームと,x,y,z,textにそれぞれ列名を渡すと上記のような
プロットが可能になります。
具体例2
使用データセット
マイナビ × SIGNATE Student Cup 2019のデータを使用しました。
コンペについては自分のブログに詳しく記載しております。
http://zerebom.hatenablog.com/entry/2019/11/09/121233?_ga=2.241090371.157833494.1575468424-1743001014.1569899454
こちらのコンペティションは東京都23区の賃貸情報を用いて、各物件の賃料を予測するというものでした。
https://signate.jp/competitions/182
こちらのデータを整形し、以下のようなDataFrameを用意しました。
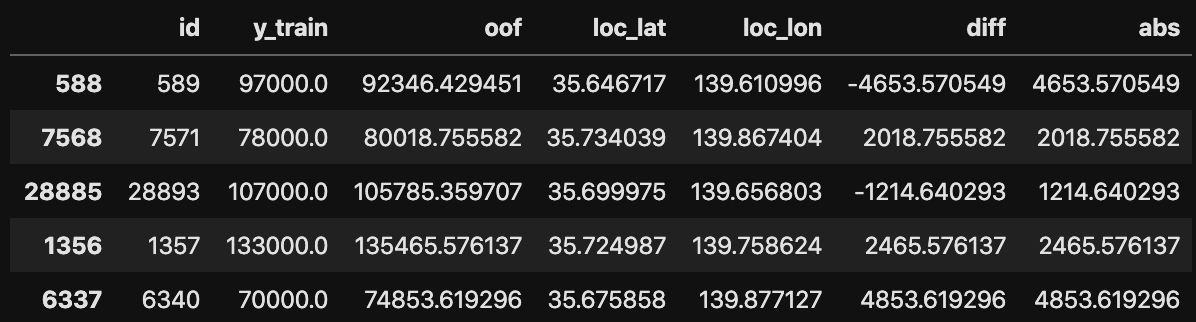
各列は以下の意味を持ちます
- id:通し番号
- y_train:賃料の正解データ
- oof:賃料の予測データ
- diff:予測値-正解値
- abs:予測値-正解値の絶対値
- loc_lat/loc_lon:緯度経度
コード
import plotly.express as px
px.set_mapbox_access_token('YOUR_API_KEY')
fig = px.scatter_mapbox(df, lat="loc_lat", lon="loc_lon", color="diff", size="abs",text='id',
color_continuous_scale=px.colors.sequential.Viridis, size_max=30, zoom=10)
fig.show()
説明
こちらのコードは実際にコンペでデータを学習をした後、予測誤差が大きい賃貸がどの地域に多いかを調べるために使用しました。
Plotlyで地図データと緯度経度をマッチさせるためには、事前にMapBoxというサービスに登録し、APIキーを取得する必要があります。
こちらのサイトから簡単に取得することができます。
(https://account.mapbox.com/)
地図上に表示するためには以下のように引数を指定する必要があります。
今回は
- color...予測値の誤差
- size...予測値の誤差の絶対値
- text(要素に重ねて表示される文字列)...物件idとしました
color="diff", size="abs",text='id'
カラーマップの選択、要素の大きさの最大値、地図のズーム具合は以下のように指定します。
color_continuous_scale=px.colors.sequential.Viridis, size_max=30, zoom=10
細かい設定
fig.update_layoutのなかに辞書型で設定を渡してあげると変更されます。
plotlyの公式サイトはExampleが多く、コードとプロットがセットになっているので、
自分の気になる設定があれば公式サイトを覗いていると良いかもしれません。
(https://plot.ly/python/text-and-annotations/#text-font-as-an-array--styling-each-text-element)
【例】:フォントを変えて、字を大きくしたい
fig.update_layout(
font={"family":"Open Sans",
"size":16})
おわりに
Plotlyはポテンシャルの割に使っている人が少ないと思ったので紹介させていただきました。
特に三次元データ、地図データと相性が良いので皆さんもぜひ使ってみてください!
参考
Word2Vecの学習済み日本語モデルを読み込んで使う
https://qiita.com/omuram/items/6570973c090c6f0cb060
日本語版text8コーパスを作って分散表現を学習する
https://hironsan.hatenablog.com/entry/japanese-text8-corpus
Macでキャプチャして作ったGifアニメーションをQiita記事に貼り付ける方法
https://qiita.com/ryosukes/items/b5dd0fac1a059caffbf0