0. はじめに
前回の投稿から間が空いてしまいましたが、今回はOracle Databaseの「実行計画」についてお話ししたいと思います。例のとおり、今回もわかりやすさ追求のため、詳細を省略しているところがある点ご了承願います。
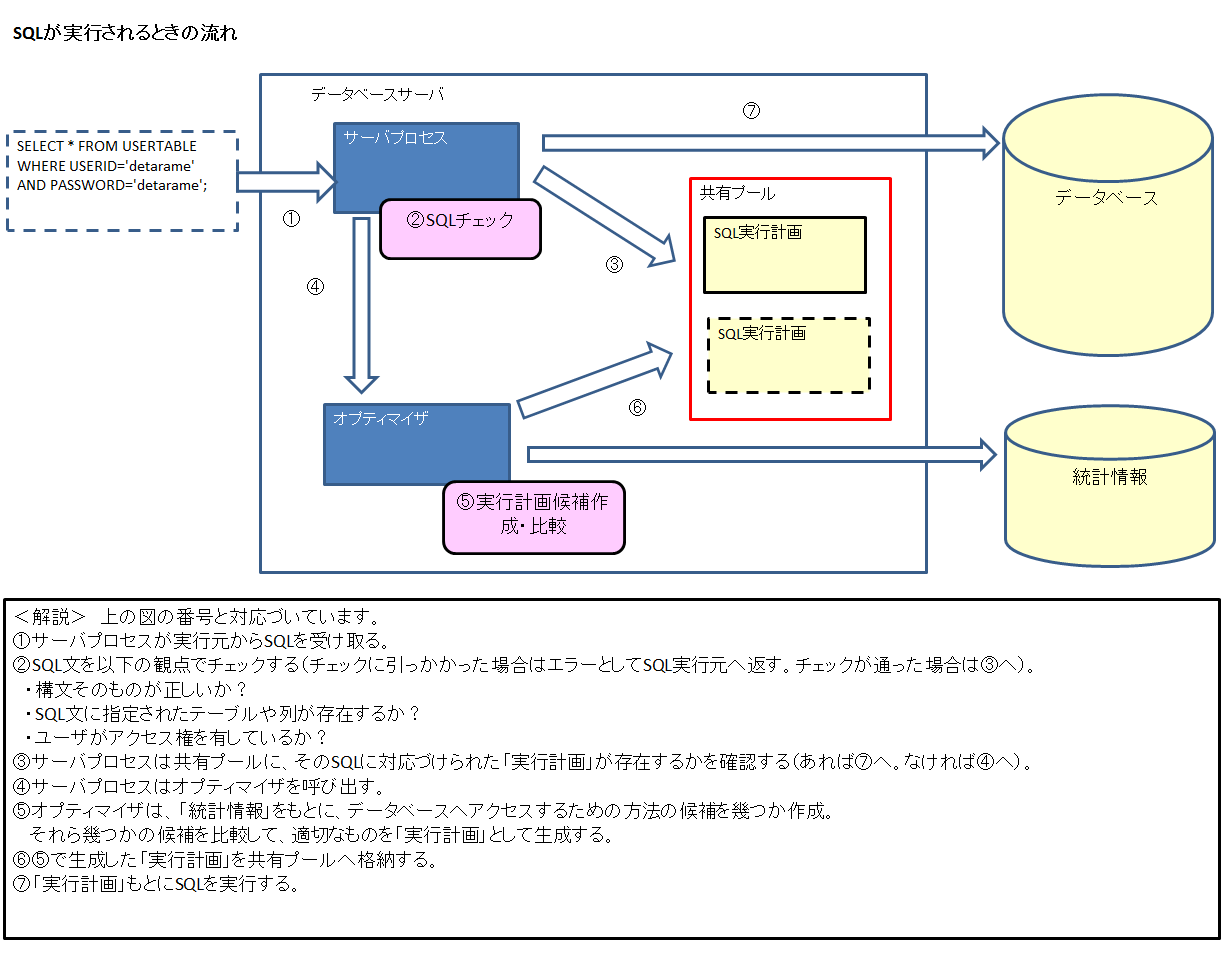
1. SQLが実行されるときの仕組み
Oracle Databaseの「実行計画」について話す前に、まずはSQLが実行されるときの仕組み(流れ)について触れる必要があります。以下に簡単なイメージ(解説つき)を添付しましたので、それをもとに理解を深めてもらえればと思います。(※1)
SQLが投げられている先のデータベースのテーブルの中身はこちらです。ユーザが10件登録されています。
| userid | passwrod | username | |
|---|---|---|---|
| 0000001 | ********* | 坂田銀時 | hundsome-sakka@gintama.co.jp |
| 0000002 | ********* | ルフィー | chopperlovesluffy@pirates.com |
| ・・・ | |||
| 0000009 | ********* | 桜木花道 | sakurahana@vvvyyy.go.jp |
| 0000010 | ********* | 浦飯幽助 | urameshi@toguro-brothers.gov |
上のイメージにお気づきになったかもしれませんが、SQLを実行するにあたって「実行計画」が重要な役割を果たしているのがわかるかと思います。この例はSELECT文であり、INSERT、UPDATE、DELETE文になるともう少し複雑になってきますが(※2)、本質は変わりません。
2. 実行計画
Oracle Databaseの「実行計画」とは、文字どおり「SQLを実行するための計画」と言えばそれまでなのですが、言い換えると、どうしたらより短い時間でSQLを実行できるか、計算して導き出された、具体的な方法を「計画」としてまとめたものと言えます。実行計画の典型的な例として、上のイメージを挙げます。
ここでは、
SELECT * FROM USERTABLE WHERE USERID='detarame' AND PASSWORD='detarame';
のSELECT文を実行しているわけですが、
これを実行するのに、USERIDとPASSWORDの値がヒットするまでUSERTABLEの全行を見る(フルスキャンする)のか、あるいはUSERTABLEのUSERIDに対応づけられたINDEXを参照するのか、具体的な方法を示したものが実行計画というわけです。
上述のとおり、オプティマイザは実行計画の候補を幾つか作成し、どうしたら最短で実行できるか、これらの候補を比較した結果、より適切な実行計画が1つ選ばれ共有プールへ格納されるというわけです。その実行計画を作成するために基となる情報が「統計情報」になります。
3. 統計情報
「統計情報」の定義については、以下に紹介した引用・参考資料に記載されているため多くは触れませんが、主に表統計、列統計、索引統計、システム統計から構成されています。これらの統計情報は、実際のデータベース上にある表や列、索引等の実態から得ているわけですが、どうやって、どのタイミングで反映しているのでしょうか?以下の3種類の方法があります。
①自動的に取得
Oracleの機能により自動的に取得。平日であれば夜間、土日であれば朝~夜にかけて実施。
収集する日、時間帯を変更することも可能。
ただし、初期化パラメータの指定によって同機能が無効になる。
②手動で取得
Oracleが用意したプロシージャ(スクリプト)を任意のタイミングで実行することで取得。
③SQL実行時に取得
「動的サンプリング」と呼ばれている。
SQL実行計画を作成する際、統計情報が古いまたはそもそもない場合にサンプリングして取得。
実行計画を作る都度サンプリングするためシステムのパフォーマンスに影響する一方で、
データの質・量の変化が大きい場合に推奨されている。
上記方法により取得された統計情報はSQL実行計画の作成に大きな影響を及ぼします。
4. 実行計画、統計情報、データベースの実態との整合性
SQLの実行計画は統計情報をベースに作成されています。統計情報はデータベースの実態を反映します。そうなると、SQLが最適なパフォーマンスで実行されるためには、実行計画、統計情報、データベースの実態の3者の整合性が取れている必要があります。逆に3者の整合が取れていない、例えば統計情報はデータベースの実態を反映しているが、実行計画には反映されていない場合、SQL実行時のパフォーマンスに影響する可能性があります。
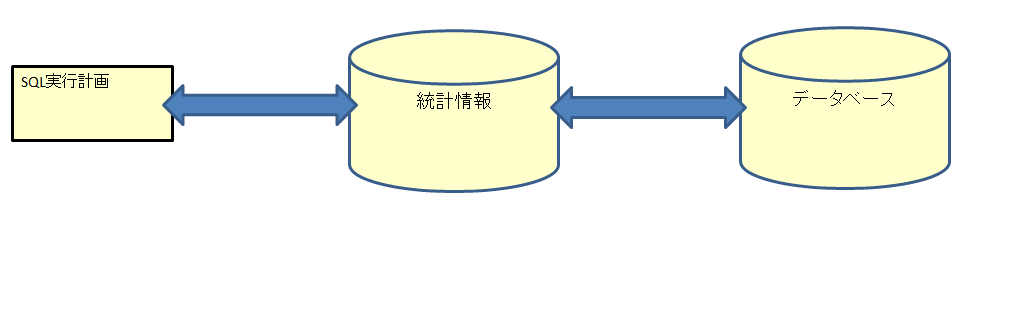
もう一度、下のSQLをもとに、例として考えてみます。
SELECT * FROM USERTABLE WHERE USERID='detarame' AND PASSWORD='detarame';
ある日の朝、あるユーザがSQLを実行したことに伴い実行計画がされました。このときUSERTABLEにあるデータは10件(10行)で、実行計画は索引を見るのではなく、当該テーブル全行見るように指示されていました。この日の夜に、別のユーザによる夜間処理でUSERTABLEに100万件のデータが挿入されました。テーブルの中身はこのようになりますね。
| userid | passwrod | username | |
|---|---|---|---|
| 0000001 | ********* | 坂田銀時 | hundsome-sakka@gintama.co.jp |
| 0000002 | ********* | ルフィー | chopperlovesluffy@pirates.com |
| ・・・ | |||
| 0000009 | ********* | 桜木花道 | sakurahana@vvvyyy.go.jp |
| 0000010 | ********* | 浦飯幽助 | urameshi@toguro-brothers.gov |
| 0000011 | ********* | きんにくすぐる | oreha@muscleman.net |
| 0000012 | ********* | ペガサス聖矢 | moeyo-cosmo@pegasus-sanctuary.com |
| ・・・ | |||
| 0999999 | ********* | 両津勘吉 | kanchan_ryotsu@kameari.or.jp |
| 1000000 | ********* | 剣桃太郎 | momo_tsurugi@jump.otoko.co.jp |
この後、統計情報へは反映せず翌朝を迎え、再度このSQLを実行しようとします。さてどうなるでしょうか?
もうわかりますよね?全行見るという実行計画は変わらないので、最大100万行見るという最悪の結果に陥ってしまいます。そして、どうするのが正しかったのでしょうか?これもわかりますよね?100万件のデータが挿入された後で、統計情報へ反映するべきであったのです。それにより実行計画が新しく作り替わり、索引を見るように変更されるというわけです(※3)。
上述の、テーブルのデータ件数が急激に増えた例のように、表や列、索引等の実態情報は適切なタイミングで統計情報へ反映し、実行計画へ反映する必要があります。統計情報の収集を自動にするか、手動で任意のタイミングにするか、SQL実行時にするかはシステムの特性に依存しますが、重要なのは3者間で整合が取れるようにすることです。
ここまで読んでくださりありがとうございました。
脚注
(※1)SQL実行の仕組みについては、以下引用・参考資料の1.、2.、3.にて詳しく解説されています。なお、今回のイメージ作成に当たっては、引用・参考資料の4.をベースにしました。
(※2)DBバッファキャッシュ、REDOログバッファ、UNDOデータが登場するとともに、COMMITの処理も加わります。
(※3)引用・参考資料の2.に説明のとおり、共有プール上にある実行計画をキャッシュアウトさせる前提で、統計情報の再収集後にOracle Databaseは新しい統計情報をもとに実行計画を作り直します。
引用・参考資料
2.門外不出のOracle現場ワザ 第4章 Oracleデータベースの頭脳 「オプティマイザ」徹底研究