はじめに
こんにちは!!
ノベルワークスでアルバイトしているザワッチ(@zawatti)です。
今回は、音声・画像・テキストに対応したマルチモーダルモデルPhi-4-multimodalを用いて、音声ファイルからテキスト生成させた結果をまとめます。
背景
-
Phi-4-multimodalは音声からテキストを生成するSpeechToTextに対応しているということで、どれくらいの精度・速度で出力するのかが気になった
-
音声入力~テキスト生成可能なマルチモーダルAIの物珍しさ
Phi-4-multimodalについて
「Phi-4-multimodal」はMicrosoftが2025年2月26日に発表したオープンソースLLMシリーズ「Phi」ファミリーの最新モデルです。
また、小規模言語モデル(SLM)として開発された音声・画像・テキストに対応したマルチモーダルAIでもあります。
アーキテクチャ
5.6Bのパラメータを持つマルチモーダル変換モデルであり、バックボーンとなる言語モデルには学習済みのPhi-4-Mini-Instructと、視覚と音声の高度なエンコーダとLoRAアダプタを持っています。
※ちなみに、Phi-4-Mini-Instructだけで3.8Bのパラメータ数
事前学習段階では、まだPhi4-mini-instructだけで言語モデルだけにとどまりますが、
事後学習(ファインチューニング)で音声・視覚情報も処理できるように、「Mixture of LoRA」を実装しています。
Mixture of LoRA(MoL)という手法によって、LoRAファインチューニングしたアダプタ層をExpertとしてみなして、どの層に振り分けるべきかを学習し、推論時には振り分けられたアダプタ層のみを活性化させることで実計算コストを減らしています。
ここでのLoRA層の役割は、言語デコーダ(文章生成するところ)の計算部分に、最適なLoRAアダプタを統合することで、言語デコーダが音声・視覚情報を加味した多種多様なタスクにも比較的低パラメータで対応できるところにあります。
ちなみにdeepseekのバックボーンにはMixture of Experts(MoE)が使われています
公式ブログ:
技術レポート:
実行手順
HuggingFaceのPhi-4-multimodalのページを参考に、まず動かしてみます。
上記の手順を詳しく説明していきます。
筆者のGoogle Colabは課金済みです。
1. 実行環境の構築
Google Colabのノートブック上で以下のライブラリをインストールしておきます。
!pip install flash_attn==2.7.4.post1 torch==2.6.0 transformers==4.48.2 accelerate==1.3.0 soundfile==0.13.1 pillow==11.1.0 scipy==1.15.2 torchvision==0.21.0 backoff==2.2.1 peft==0.13.2
!pip install flash_attn==2.7.4.post1 --no-build-isolation
2. モデル読み込み
import requests
import torch
import os
import io
from PIL import Image
import soundfile as sf
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from urllib.request import urlopen
# Define model path
model_path = "microsoft/Phi-4-multimodal-instruct"
# Load model and processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
attn_implementation='flash_attention_2',
).cuda()
3. 推論
サンプルコードのプロンプトを変えて、実行します。
# Load generation config
generation_config = GenerationConfig.from_pretrained(model_path)
# Define prompt structure
user_prompt = '<|user|>'
assistant_prompt = '<|assistant|>'
prompt_suffix = '<|end|>'
# Part 2: Audio Processing
print("\n--- AUDIO PROCESSING ---")
audio_url = "https://upload.wikimedia.org/wikipedia/commons/b/b0/Barbara_Sahakian_BBC_Radio4_The_Life_Scientific_29_May_2012_b01j5j24.flac"
speech_prompt = "文字おこしして、概要と論点を述べてください。"
prompt = f'{user_prompt}<|audio_1|>{speech_prompt}{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
# Downlowd and open audio file
audio, samplerate = sf.read(io.BytesIO(urlopen(audio_url).read()))
# Process with the model
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to('cuda:0')
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
L4 GPUの12.7GB消費していました。
以下は、実行結果です。
実行結果
>>> Response
要約:学生は、認知を高める薬を使用して勉強と試験のために使用することについて議論し、他の学生はこれを不正行為と見なし、長期的な健康と安全の研究がないことに懸念を表明しています。
論点:学生の薬物使用に関する議論と、長期的な健康と安全の研究の欠如に対する懸念
ここで私が思ったのは、
-
ストリーミングとまではいかないけど、録音した音声アップロードして対話できるようなインターフェースを作りたい
→ ・推論サーバの構築
・音声入力インターフェースの構築 -
実行時間は、10秒から11秒かかるので、もう少し早くしたい
→ 推論最適化
この3つのポイントをさらに突き詰めていきます。
推論サーバを構築する
私の環境では、Google ColabでないとGPUの使用量的に難しく、ローカルでは動かせません。
また、クラウドのAIモデルのホスティングサービスを使用するのも金銭的に渋いです。
そのため、ngrokを使用して、Google Colabで簡易的な推論サーバを構築します。
以下のソースコードを実行することで、FastAPIサーバをngrokを使用してインターネット上に一時的に公開します。
出力されたURLを使用することで、推論サーバに対しリクエストを投げることができます。
公開されたURLは、だれでもアクセスできるため不特定多数に漏らさないこと、開発・テストでの用途にとどめてください。
追加ライブラリをインストール
!pip install -q fastapi nest-asyncio uvicorn pyngrok
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
import nest_asyncio
from pyngrok import ngrok
import uvicorn
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)
# Define model path
model_path = "microsoft/Phi-4-multimodal-instruct"
# Load model and processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
attn_implementation='flash_attention_2',
).cuda()
model = torch.compile(model)
# Load generation config
generation_config = GenerationConfig.from_pretrained(model_path)
# Define prompt structure
user_prompt = '<|user|>'
assistant_prompt = '<|assistant|>'
prompt_suffix = '<|end|>'
@app.post('/inference/audio')
async def inference(audio_file: UploadFile = File(...)):
# Audio Processing
print("\n--- AUDIO PROCESSING ---")
speech_prompt = "文字おこしして、概要と論点を述べてください。"
prompt = f'{user_prompt}<|audio_1|>{speech_prompt}{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
# Read audio file from request
audio_bytes = await audio_file.read()
audio, samplerate = sf.read(io.BytesIO(audio_bytes))
# Process with the model
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to('cuda:0')
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
return {
"text": response
}
ngrok.set_auth_token(">>ngrokのアクセストークンを入れる<<")
ngrok_tunnel=ngrok.connect(8000)
print('url:',ngrok_tunnel.public_url)
nest_asyncio.apply()
uvicorn.run(app,port=8000)
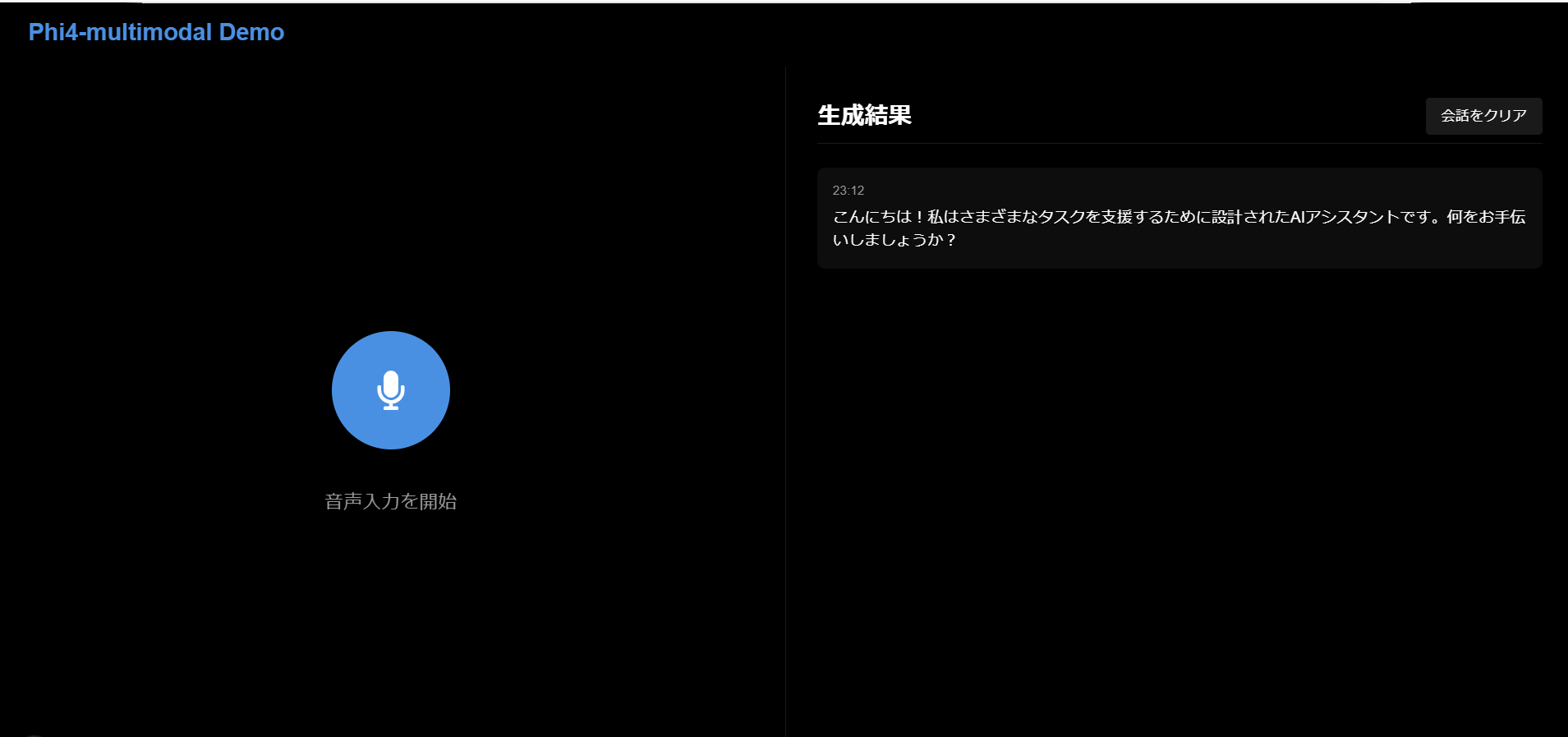
音声インターフェースの構築
React/CSSで簡単にがわだけ作りました。
流れとしては、
- 録音ボタンを押して、おしゃべりする
- おしゃべりが終わったら、もう一回録音ボタンを押す
- AIの推論が終わるまで待機する
- 推論結果とその時間を表示する
※必要に応じて、会話履歴を削除できる
推論最適化
本モデルは内部実装がかなり特殊なので、よくあるような8bit,4bit量子化や、モデルが生成しながら送信するようなストリーミングに対応していないため、今回は以下の少ない労力で最適化できるアプローチのみに絞りました。
- torch.compileで事前にモデルをコンパイル
- モデルのウォームアップ
...
# Load model and processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype=torch.float16,
trust_remote_code=True,
attn_implementation='flash_attention_2',
).cuda()
model.eval()
model = torch.compile(model, mode="reduce-overhead")
# Load generation config
generation_config = GenerationConfig.from_pretrained(model_path)
...
デモ

たまに文字起こしをそのまま出してくるときがあるので、プロンプトの調節次第では、文字起こし+推論結果を出力させることもできるかもしれないです。
推論時間自体は早くなった気はしますが、ストリーミング出力にも対応してなさそうなので、待っている時間=テキストが全部生成されるまでの時間になっていて、もどかしいです。
おわりに
Phi-4-multimodal思ったより、ポテンシャルが高いなと思いました。
しっかりと音声入力でも人間との対話形式を想定した学習が行われていることを感じました。
眼鏡にカメラとマイクつけて、画像と音声を垂れ流しでずっと推論リクエスト送り続けるとかさせてみると、めちゃくちゃ面白そう。
ここまでくると、やっぱり音声出力までさせたいですね。