はじめに
Pythonで利用できるKotaro Kinoshita氏開発のOCRライブラリ,「YomiToku」が公開されていたので軽く触りつつ使い方をまとめてみます.
YomiTokuとは
簡単な説明
- 日本語の文書画像解析に特化したPyhonのOCRライブラリ
- ローカルサーバーでPDFや文書画像の解析・表の構造解析・レイアウト解析が可能
- 解析結果はHTML・CSV・JSON・Markdownといった形式でエクスポート可能
- 2024年12月3日現在,非商用での個人利用・研究目的の利用は自由(商用利用は別ライセンスのため要相談)
GitHubリポジトリ
実際に使ってみる
Google Colabで実行します
YomiTokuのインストール
!pip install yomitoku
文書画像の準備
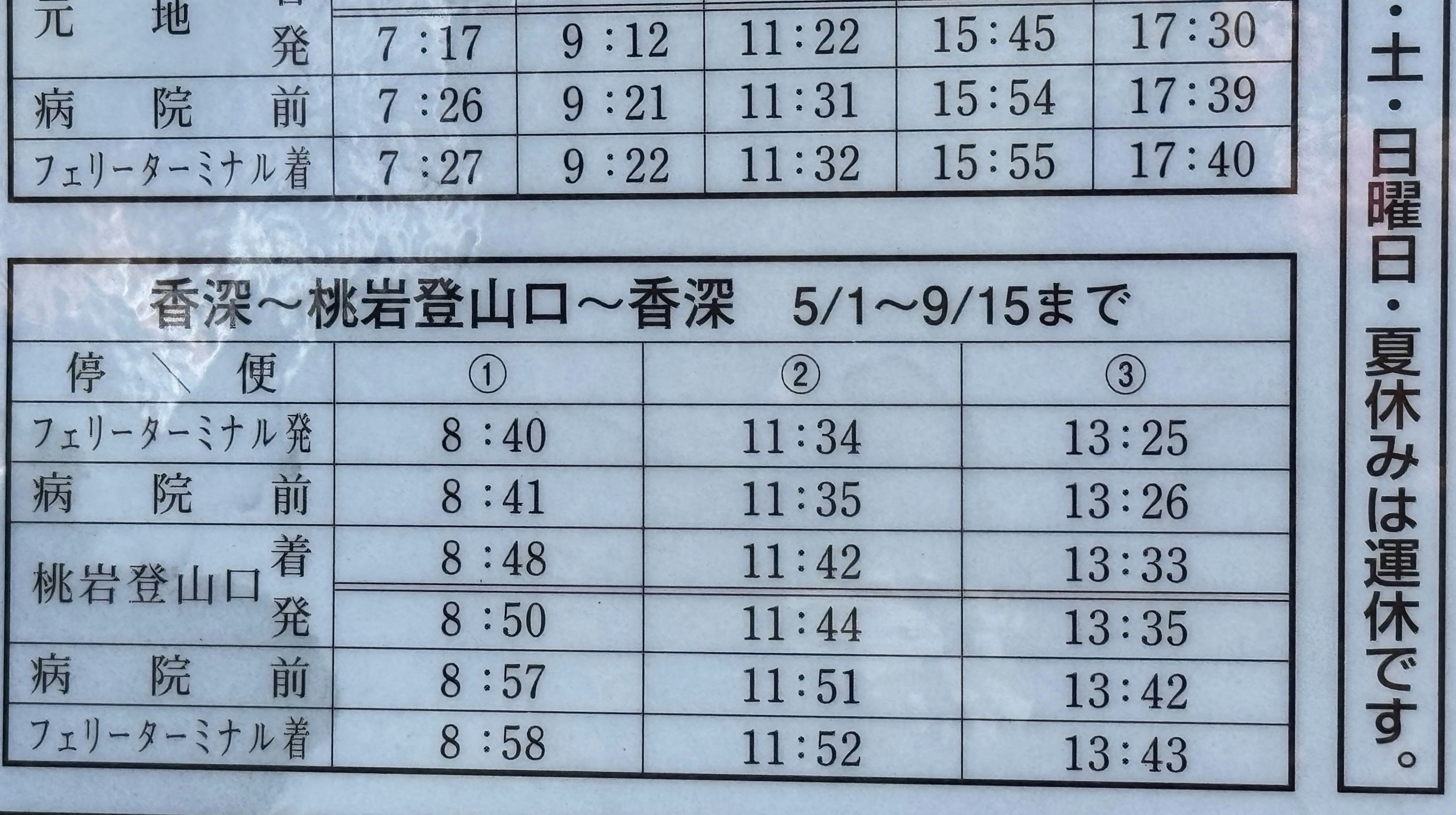
適当な文書画像を準備し,sample.jpgという名前でGoogle Colabにアップロードします.
-
sample.jpg
実行方法
公式ドキュメントによると,以下のコマンドで実行できるようです.
yomitoku ${path_data} -f md -o results -v --figure
-
${path_data}解析対象の画像が含まれたディレクトリか画像ファイルのパスを指定. -
-f,--format出力形式のファイルフォーマットを指定.(対応フォーマット:json・csv・html・md) -
-o,--outdir出力先のディレクトリ名を指定.存在しない場合は新規で作成される. -
-v,--vis解析結果を可視化した画像を出力. -
-d,--deviceモデルを実行するためのデバイスを指定.gpu が利用できない場合は cpu で推論が実行される.(デフォルト:cuda) -
--ignore_line_break画像の改行位置を無視し,段落内の文章を連結して返す.(デフォルト:画像通りの改行位置位置で改行) -
--figure_letter検出した図表に含まれる文字も出力ファイルにエクスポート. -
--figure検出した図・画像を出力ファイルにエクスポート.(html と markdown のみ)
OCRの実行
今回はMarkDownファイルで出力してみます.
!yomitoku /content/sample.jpg -f md -o results -v --figure
2024-12-03 03:14:55,710 - yomitoku.base - INFO - Initialize TextDetector
2024-12-03 03:14:56,470 - yomitoku.base - WARNING - CUDA is not available. Use CPU instead.
・
・
・
2024-12-03 03:16:19,539 - yomitoku.cli.main - INFO - Output file: results/content_sample_p1.md
2024-12-03 03:16:19,541 - yomitoku.cli.main - INFO - Total Processing time: 79.42 sec
大体80秒ほどかかりました.
実行結果
-
content_sample_p1.md
·土·日曜日·夏休みは遅休です。 |元 地|||||||||| |-|-|-|-|-|-|-|-|-|-| |||7:17||9:12|11:22|||15:45|17:30| |病院 前||7:26||9:21|11:31|||15:54|17:39| |フェリーターミナル着||7:27||9:22|11:32|||15:55|17:40| |香深~桃岩登山口~香深 5/1~9/15まで|||| |-|-|-|-| |停\便|1|2|3| |フェリーターミナル発|8:40|11:34|13:25| |病 院 前|8:41|11:35|13:26| |着発<br>桃岩登山口|8:48|11:42|13:33| ||8:50|11:44|13:35| |病院 前|8:57|11:51|13:42| |フェリーターミナル着|8:58|11:52|13:43|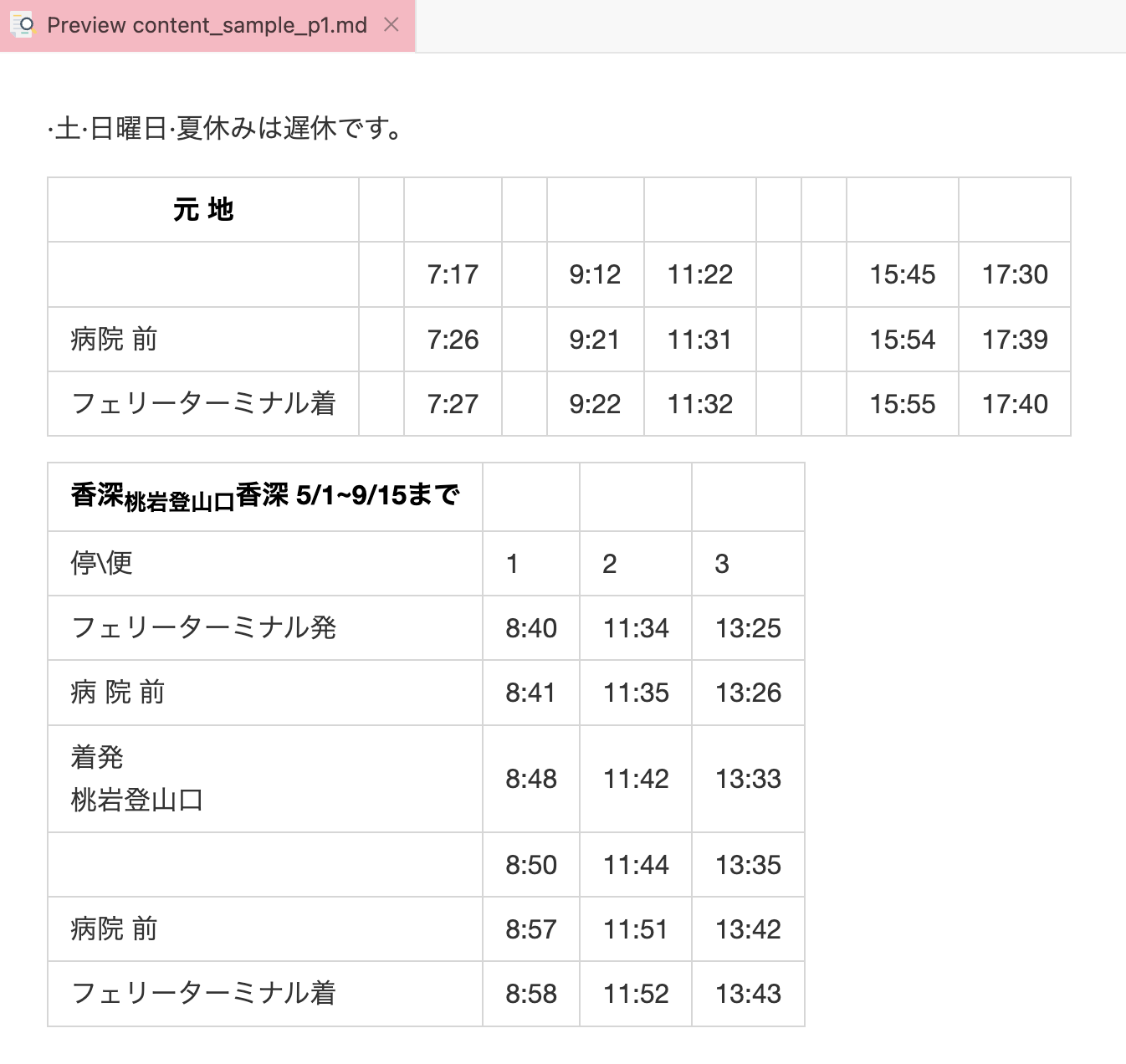
-
content_sample_p1_layout.jpg
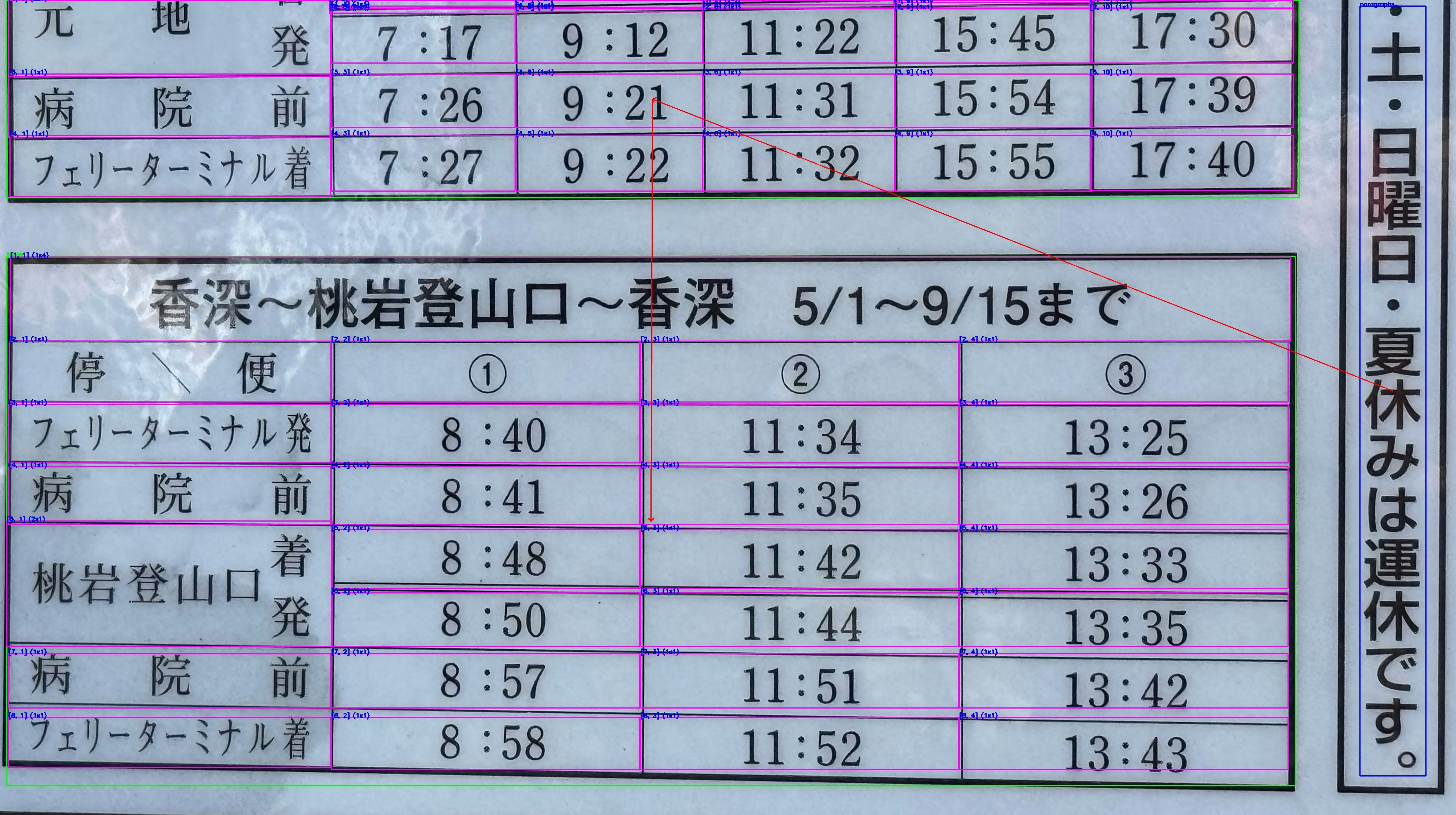
-
content_sample_p1_ocr.jpg
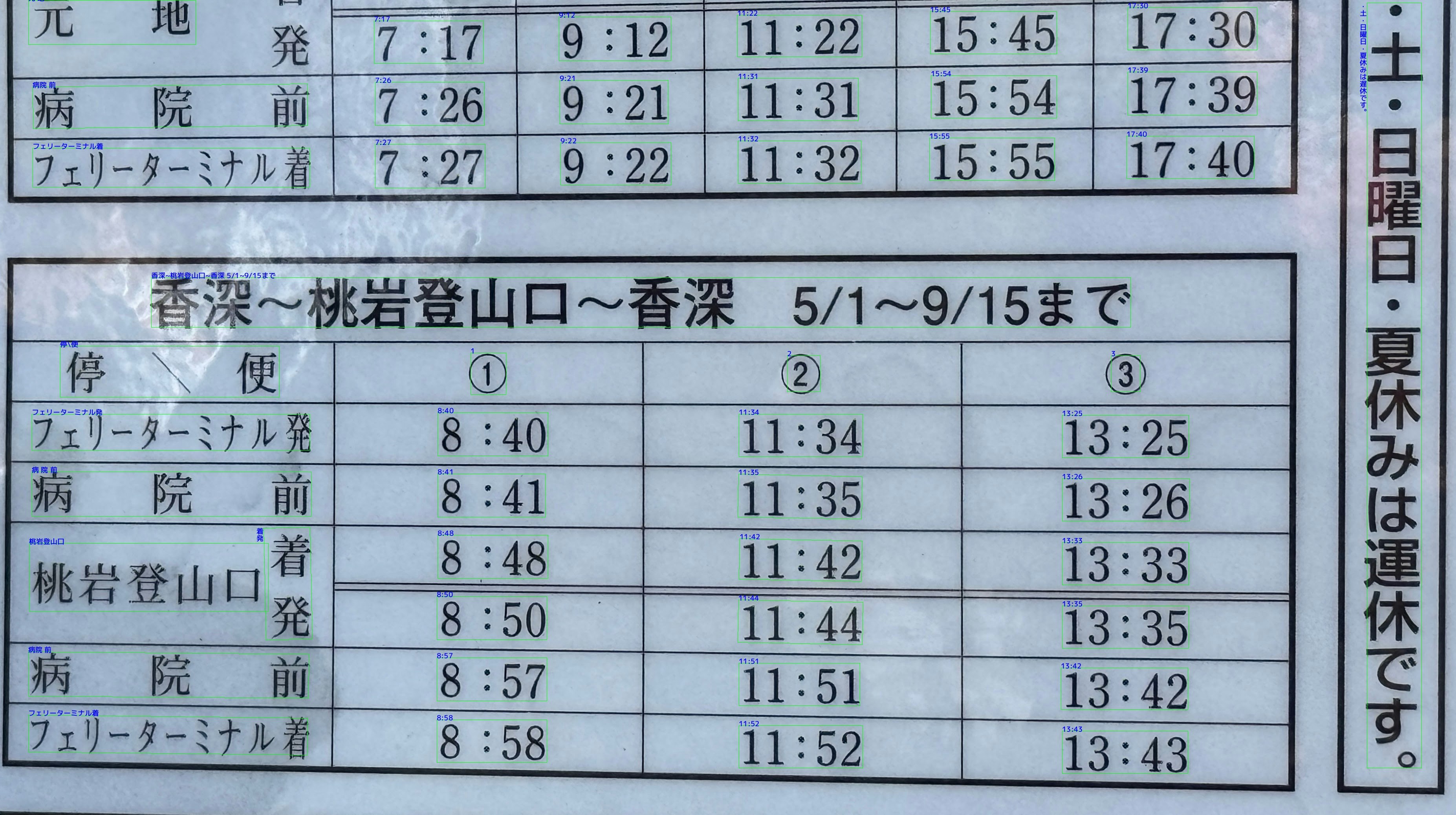
「香深〜桃岩登山口〜香深」の「〜」を半角チルダと認識したことでマークダウンのレイアウトが若干崩れてしまっていますが,かなり高い精度で文字の認識ができています.
特に「フェリーターミナル」は半角に近いサイズの文字であるにもかかわらず問題なく認識できています.すごい.
おわりに
今回そこそこトリッキーなレイアウトの文書の解析を行いましたが,かなり精度良く文字の認識ができていました.今後はPDF出力された文書ファイルのレイアウト解析なんかで積極的に使ってみようと思います.