1.はじめに
Sonyとレッジが企画するAI開発コンテスト「Neural Network Console Challenge」に挑戦。3つあるテーマの一つの『人物画像をNNCで学習させ新しいオノマトペ(擬音語/擬声語/擬態語)の画像カテゴリ分類を作り出す』に挑んでみました。
【更新】受賞ならず!しかも、ツイッターライブであった表彰式で「受賞作以外の興味深いアウトプット」の一つとして取り上げられるという、逆に悔しい結果となりました><。。。クソー笑
2.実験環境&データ
・Google Colaboratory(GPU,python3)
・Neural Network Console(NVIDIA_Tesla_V100、K80(クラウド)&ローカル版)
・学習用データ提供:PIXTA
3.オノマトペ(擬音語/擬声語/擬態語)とは
グーグルによると、
自然界の音・声、物事の状態や動きなどを音(おん)で象徴的に表した語
らしいです。ここではこのHPを参考に、様々な情景を連想させる6つの擬態語に関する画像分類を試みます。採用した単語は以下の通りです。
・にこにこ(「笑う」、「微笑む」といったキーワード)
・わいわい(「元気」、「楽しい」 〃 )
・きらきら(「光る」、「明るい」 〃 )
・のんびり(「ゆるい」、「怠ける」 〃 )
・ふんわり(「弱い」、「柔らかい」 〃 )
・じろじろ(「見る」、「眺める」 〃 )
4.学習データ
コンテストでは、PIXTA社が提供する人物画像1万枚が学習データとなります。問題は、データにアノテーション(タグ付け)する工程。タスクの拡張性も踏まえ、手作業でのタグ付け作業を減らすための手法も検討し、「擬音と画像のヒストグラムが結びつけられれば、アノテーションの自動化ができるのでは?」と思い至りました。そこで今回は、以下の方法でデータを作っていきます。
手順① 分類したい擬音語を連想させる画像を目視で抽出
まず、以下の画像セットを作りました。
1.にこにこ

2.わいわい

3.きらきら

4.のんびり

5.ふんわり
 !
!
6.じろじろ
手順② 残りのPIXTA画像から学習データを量産
opencvを用い①で抽出した画像のヒストグラムを計算。残りのPIXTA画像のヒストグラムも求め、各抽出画像との類似度を算出していき、値が近い画像が属するカテゴリーに分類していきます。Google Colaboratory上で以下のプログラムを用いて処理しました。
import requests
import json
import numpy as np
import csv
import cv2
import matplotlib.pyplot as plt
import os
import shutil
# 分類元フォルダー
image_dir = "./image_dir"
image_arr = os.listdir(image_dir)
# 親ディレクトリー
train_dir_arr = os.listdir("./onomatope")
result_arr = []
for img_name in image_arr:
#分類元の画像ヒストグラム
target_img_path = image_dir + "/" + img_name
img = cv2.imread(target_img_path)
target_hist = cv2.calcHist([img], [2], None, [256], [0, 256])
max_value = 0
for train_dir in train_dir_arr:
train_img_arr = os.listdir("./onomatope/" + train_dir)
for train_img in train_img_arr:
try:
target_img_path_2 = "./onomatope/" + train_dir + "/" + train_img
img_2 = cv2.imread(target_img_path_2)
comparing_hist = cv2.calcHist([img_2], [2], None, [256], [0, 256])
#最近傍を計算
#ヒストグラムを比較する
result = cv2.compareHist(target_hist, comparing_hist, 0)
if result > max_value:
max_value = result
max_category = train_dir
except:
import traceback
traceback.print_exc()
#カテゴリーフォルダーにコピー
if max_value > 0.7:
shutil.copy(target_img_path, "./drive/NNCC/onomatope/" + max_category)
この処理を通して、計4341枚の学習データを準備しました。
5.ニューラルネットワークで機械学習
準備した学習データを使い、画像分類するためのネットワークを構築します。ローカルのNNCで、6クラスある1281283の入力画像をリサイズして作成し、80%を学習データに、残りの20%を検証用データに分けてクラウド版NNCにアップロード。サンプルプログラムの一つの「ResNet-50」を元に1000エポックの学習を実施しました。
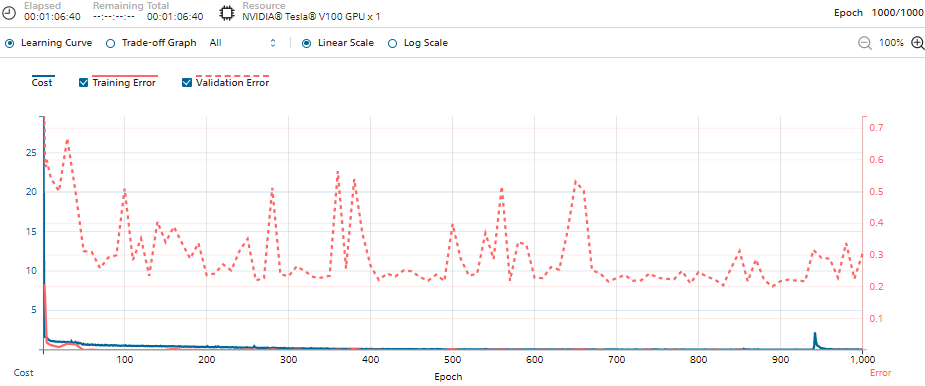
要した学習時間は、NVIDIA_Tesla_V100を使って約66分でした。全データでの比較はしていませんが、小規模データでの実測値だとCPUと比較し10分の1ほどの時間で学習を完了させることができました。
6.精度評価
評価データの分類結果は以下図の通りとなりました。Accuracy:0.7894、Avg.Precision:0.8045と8割近い精度をあげることができました。各ラベルはそれぞれ、
- label=0 --- ふんわり
- label=1 --- じろじろ
- label=2 --- きらきら
- label=3 --- にこにこ
- label=4 --- のんびり
- label=5 --- わいわい
となります。
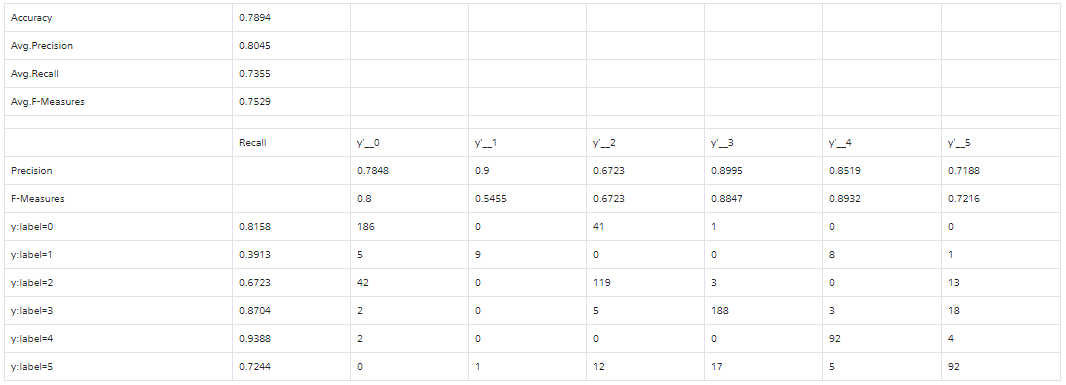
label=4(のんびり)は、Recall,Precision共に数値が高く0.9を上回り、うまく分類ができているといえそうです。学習元となる画像が赤色によった画像なため、高い精度が上げられたと考えられます。
興味深かったのは、見た目の色合いが近いにも関わらずlabel=3(わいわい)、label=5(わいわい)で高い分類精度を残せた点。色合いだけでなく、機械学習で特徴量をうまく抽出できた結果だと思われます。
一方で精度の低かったlabel=1(じろじろ)は、他に比べ学習元となる画像数が1割未満と少なかったため、精度が上げられませんでした。
評価画像の分類結果の一部は以下の通り(分類に失敗している画像も含みます)。
- label=0 (ふんわり)
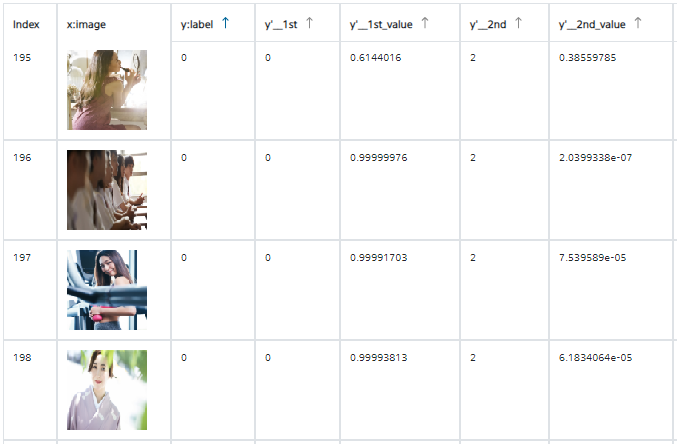
- label=1 (じろじろ)
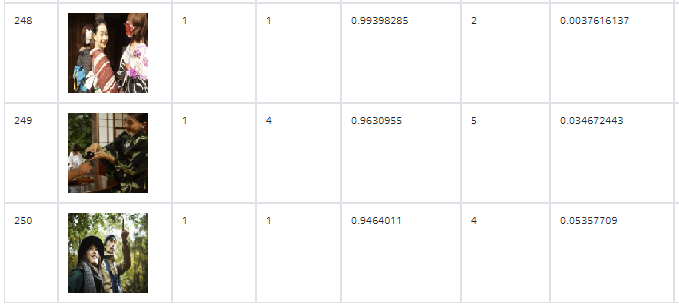
- label=2 (きらきら)

- label=3 (にこにこ)
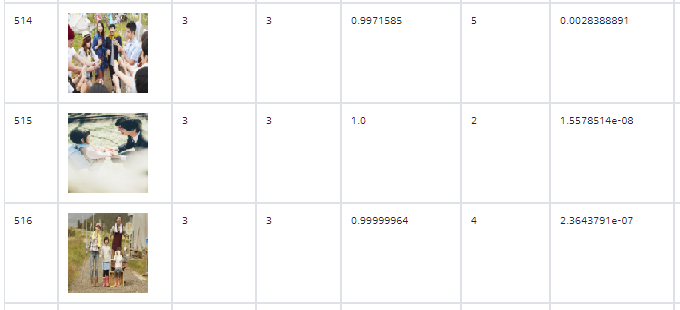
- label=4 (のんびり)
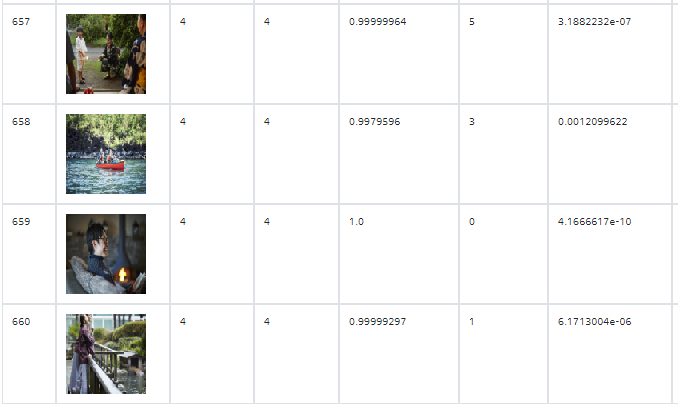
- label=5 (わいわい)
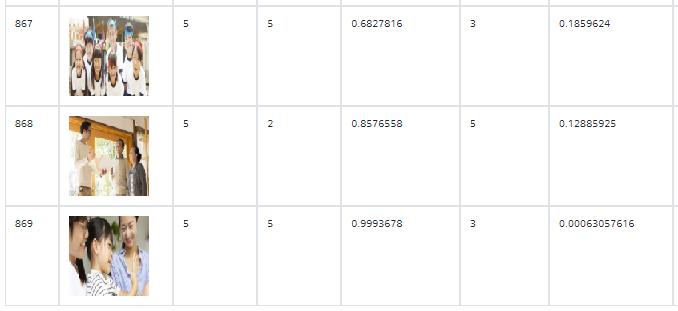
7.まとめと考察
- 画像のヒストグラムを元にした、様々なシーンを想起させる6種の擬音を分類可能なモデルをResNetを活用し構築した
- 80%近い分類性能を達成
- 学習データ作りのためのタグ付けの作業負荷を軽減するスキーマーも併せて考案できた
今回は実験期間とリソースが限られるため、小規模での学習に留まりヒストグラムもRGBの中の赤色のみしか考慮できませんでした。これらを踏まえ、本手法は他のオノマトペ画像の分類も考慮した、より高精度の新たなモデルが比較的容易に作成できる可能性も残していると思われます。