今後仕事でCloud Dataprocを使うことが出てきそうなので、個人的に概要をまとめます。
今年はProfessional Cloud Architect(CA)を取得する予定なので、その勉強も兼ねてます。
Cloud Dataprocとは
「Dataproc は、Apache Spark および Apache Hadoop クラスタを簡単かつコスト効率の高い方法で実行するための高速で使いやすいフルマネージド クラウド サービスです。」
とあります。
HadoopとSparkの話が出てきたので簡単にまとめておきます。
Apache Hadoopとは
RDBMSで苦手とする「大量のデータ処理」を効率的に処理するために作られた「分散処理」用のフレームワーク。
Googleが2004年に発表した分散処理フレームワークMapReduceを元に作られているらしいです。
特徴としては2つあり、
1つはサーバをスケールアウトさせることで処理能力を高められる「高い拡張性」。
2つ目は複数台のサーバのうち1台が壊れても処理を続けられる「高い安定性」。
Apache Sparkとは
Sparkは分散処理用のプラットフォームであり、Hadoopの弱点であるリアルタイム処理が得意。(ストリーミングデータの分散処理が可能)
またデータの格納場所をHDD・SSDだけでなく、メモリに格納できることから処理速度も高くできる。
ただしSparkがHadoopの完全上位互換というわけでなく、SparkがHDFS(Hadoopの分散ファイルシステム)を使ったり、データがメモリに乗り切るか否かで変わってくる。
つまり
つまり、分散処理ツールであるHadoop/Sparkの実行環境をクラウド上で提供してくれるのがDataprocということです。
※あとで知りましたが、SparkR, PySpark, Hive, SparkSql, Pig, Prestoも選べます。
チュートリアル
チュートリアルがあるのでそれに従って使ってみます。
1. クラスタ作成
指示に従いクラスタの設定をし、作成ボタンを押下。
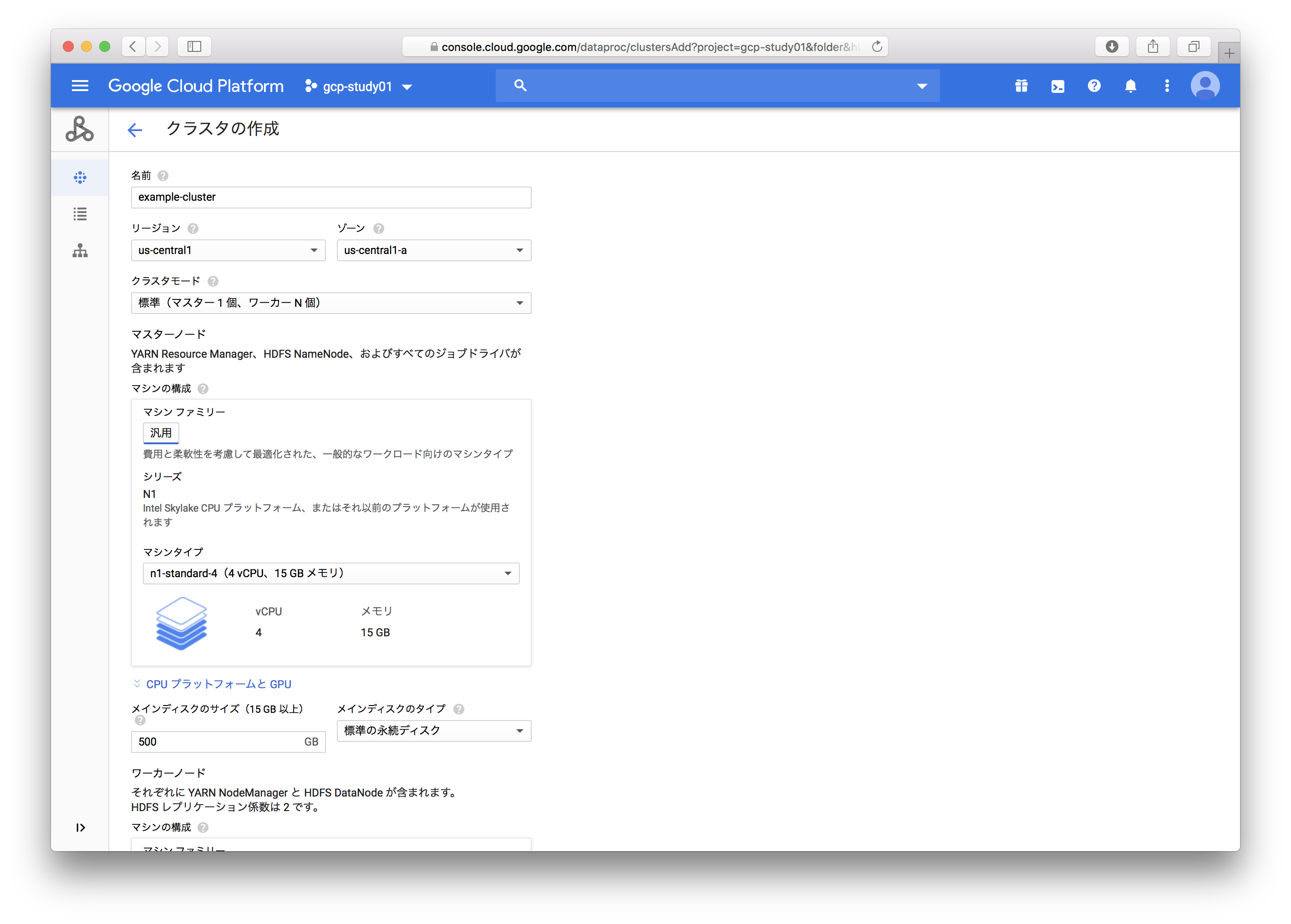
しかしエラーに!

▼エラー内容
Multiple validation errors: - Insufficient 'CPUS' quota. Requested 12.0, available 6.0. - Insufficient 'CPUS_ALL_REGIONS' quota. Requested 12.0, available 10.0. - This request exceeds CPU quota. Some things to try: request fewer workers (a minimum of 2 is required), use smaller master and/or worker machine types (such as n1-standard-2).
どうやら割り当て上限に引っかかったみたいです。
じゃあ上限上げてみるかと思いきや、GCP無料枠では上限を増やせないとのこと。
しょうがなく作成するクラスタスペックを下げてみることに。
n1-standard-2を推奨されたのでそれを使ってみたら作成できました!
(割り当ての設定画面はこちら。)
▼選べる分散処理基盤の種類。いろいろ使えます。

2. ジョブ送信
クラスタを作成したので、次は作ったクラスタでPi計算のジョブを流してみます。
(ジョブ実行じゃなくジョブ送信なんですね。なんか日本語に違和感。)
▼ジョブ設定画面
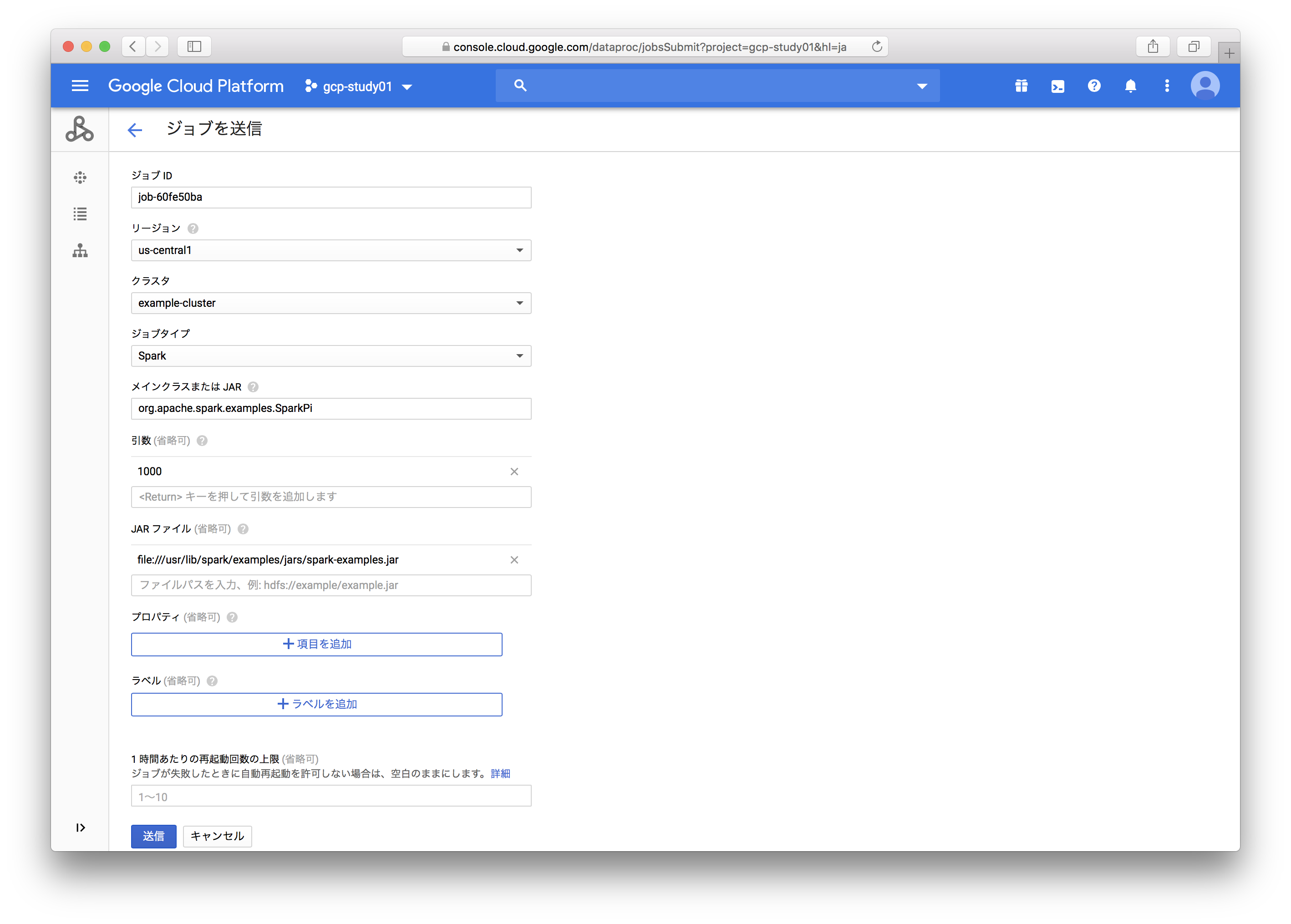
ジョブタイプはいくつか選べるのですが、今回はSparkを使ってみます。
ここで予め用意されているPi計算用のJarを指定します。
▼実行結果

ちゃんと実行されてますね。
3. ワーカーノードの変更
そしたら次はワーカーノード数を変えて実行してみようと思ったのですが、変更画面でエラーに。

▼エラー内容
Multiple validation errors: - Insufficient 'CPUS' quota. Requested 6.0, available 0.0. - Insufficient 'CPUS_ALL_REGIONS' quota. Requested 6.0, available 4.0. - Insufficient 'DISKS_TOTAL_GB' quota. Requested 1500.0, available 528.0. - This request exceeds CPU quota. Some things to try: request fewer workers (a minimum of 2 is required), use smaller master and/or worker machine types (such as n1-standard-2).
今の割り当て設定ではワーカーノード数を引き上げられないらしいです。
ちなみにワーカーノードは最低2つ以上必要なので、減らすことも増やすこともできず、変更を試せませんでした。
力及ばず申し訳ないです。
4. お片付け
使う前より美しく!
使ったものは消しときましょう。
▼クラスタ削除

▼ジョブ削除

▼GCS上に残ったゴミ(Jarファイルやメタデータなど)も削除

まとめ
ざっくりDataprocクラスタ作成からジョブ実行まで試してみました。
大きな流れは分かったので、今度は中身の実装にも手を出していきたいと思います。
ここまで読んで頂きありがとうございました!