はじめに
地震の加速度波形を利用して、何か地学的な情報を推測することはできないか。
ということで、今回はLSTMを利用した地震波形の学習とマグニチュードの一の位を予測する方法について解説します。
今後はより多くの説明変数を地学的視点で探っていき、他の機械学習モデルなども組み合わせて精度を高めていくことを検討しています。
最終的には気象庁のデータを組み合わせて津波の遡上高を推測することが目標です。
また、今回は一連の実装方法の解説と動作確認がメインのため、深層学習において必要な細かい概念については別の記事で紹介します。
開発環境
Google Colabを使用します。
データ作成
防災科学研究所の強振観測網k-netのデータを使用します。
-
データをダウンロードするには以下からユーザ登録が必要です。
https://hinetwww11.bosai.go.jp/nied/registration/?LANG=ja -
ユーザ登録が完了したら、
以下のページに移動
https://www.kyoshin.bosai.go.jp/kyoshin
→「ダウンロード」タブをホバーする
→「簡易ダウンロード」をクリック
→ログインしていない状態の場合はユーザ名とパスワードを求められるので入力
→データを選択
→「K-NETダウンロード」ボタンをクリック
と進んでください。 -
ダウンロードが完了したら、knt.tar.gz拡張子の圧縮ファイルを展開します。
knt拡張子のフォルダ内には様々な種類のファイルがありますが、今回学習で使用するのはUD拡張子、EW拡張子、NS拡張子のファイルです。
とりあえず上下動のデータ(UD拡張子)のみを扱うことにします。
まず、UDファイルをColabの「ファイル」の最上階に一つアップロードします。
ちなみに1ファイル1データです。
今回は結果を求めるわけではなく一連の実装方法の解説と動作確認がメインなので1データを量産して学習コードを動作させることに専念します。(過学習of過学習になりますが。)
まず、glob関数でアップロードしたファイルを取得します。
# 筆者はノートブック形式の場合はインポートを必要なタイミングで行う派です
import glob
files=glob.glob("./*.UD")
次に、ファイルごとにfor文で周してマグニチュード(float)と地震加速度(intのリスト)をリストに格納します。
(※「for x in range(50):」でデータを量産しています。結果を求めて作業をする場合は必ず外しましょう。なお、たくさんのUDファイルをアップロードするわけにはいかないので(日が暮れるので)Jupyter環境を作成してローカルで作業することをお勧めします。)
acc_seq_list = []
mag_list = []
for x in range(50):
for file in files:
acc_seq = []
f=open(file,'r')
while True:
row = f.readline()
if 'Lat.' in row:
epi_lat = float(row[19-1:30])
elif 'Long.' in row:
epi_lon = float(row[19-1:30])
elif 'Mag.' in row:
mag = float(row[19-1:30])
mag_list.append(mag)
elif 'Memo.' in row:
while True:
memo_row = f.readline()
if memo_row == '':
break
acc_list = memo_row.split()
for acc in acc_list:
acc_seq.append(acc)
acc_seq_list.append(acc_seq)
break
print("データ数:", len(acc_seq_list))
print("マグニチュードリスト:", mag_list)
print("地震加速度リスト:", acc_seq_list)
[出力]
データ数: 50
マグニチュードリスト: [4.0, 4.0, 4.0, 4.0, 4.0, 4.0, 4.0, 4.0, 4.0, 4.0, 4.0, ...略
地震加速度リスト: [['3466', '3418', '3329', '3257', '3242', '3267', '3311', ...略
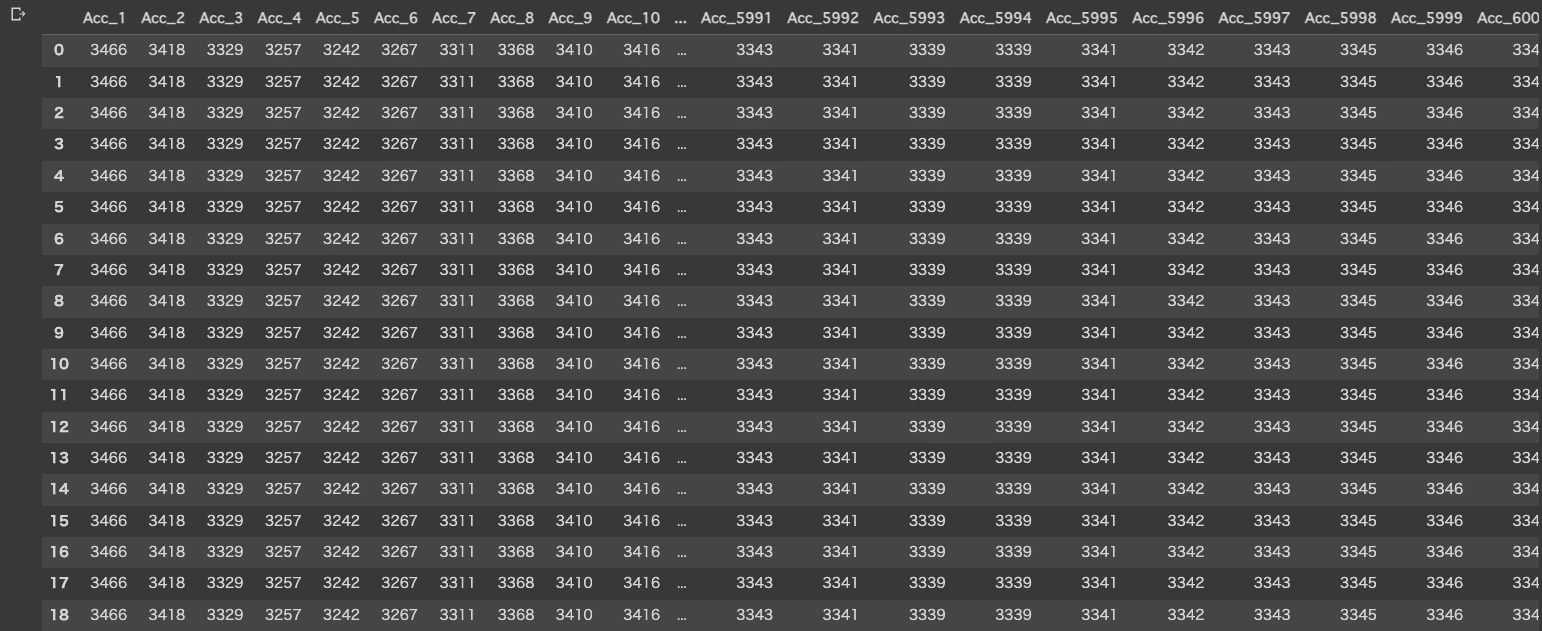
次に、入力データとなる地震加速度リストをデータフレームに変換します。
import pandas as pd
columns = []
for i in range(len(acc_seq_list[0])):
columns.append(f"Acc_{i+1}")
df_X = pd.DataFrame(acc_seq_list, columns=columns)
df_X
[出力(スクリーンショット)]
次に、ラベルとなるマグニチュードリストをデータフレームに変換します。
df_y = pd.DataFrame(mag_list, columns=["Mag"])
df_y
[出力(スクリーンショット)]

最後に、2つのデータフレームを結合してCSVファイルとして出力します。
df = pd.concat([df_y, df_X], axis=1)
df.to_csv("./k-net.csv")
これで次回以降に同じデータを使用てモデル開発をしたい場合は
次章「データ読み込み」から行うことができます。
データ読み込み
※筆者は先ほどのcolabとは別のノートブックを作成して作業していますが、
同じノートブックで作業を続行してもOKです。
先ほど保存したk-net.csvをColabの「ファイル」の最上階にアップロードします。
アップロードが完了したら、データフレームとして読み込みます。
import pandas as pd
df = pd.read_csv("./k-net.csv")
前処理
ここからはデータの前処理を行います。
今回は欠損値がないため補完作業は行いません。
まず、学習データ:検証データ=8:2でホールドアウト検証するためにデータフレームを分割します。
from sklearn.model_selection import train_test_split
train_df, val_df = train_test_split(df, test_size=0.2, shuffle=False)
train_df
次に学習・検証データそれぞれの入力データをNumPy配列として取得します。
なお、Unnamed: 0の列とマグニチュードの列をドロップすることで入力データとしています。
import numpy as np
x_train = train_df.drop(['Unnamed: 0','Mag'], axis=1).values
x_val = val_df.drop(['Unnamed: 0','Mag'], axis=1).values
print('x_train:', x_train)
print('\nx_val:', x_val)
次に、データを標準化します。
標準化にはscikit-learnのStandardScalerを使用します。
from sklearn.preprocessing import StandardScaler
sscaler = StandardScaler()
scaled_x_train = sscaler.fit_transform(x_train.T).T
scaled_x_val = sscaler.fit_transform(x_val.T).T
print('scaled_x_train:', scaled_x_train)
print('\nscaled_x_val:', scaled_x_val)
出力
scaled_x_train: [[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]
[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]
[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]
...
[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]
[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]
[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]]
scaled_x_val: [[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]
[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]
[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]
...
[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]
[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]
[ 2.91130523 1.76771247 -0.3526991 ... 0.02849849 0.05232334
0.05232334]]
次にマグニチュードデータをNumPy配列として取得します。
y_train = train_df['Mag'].astype(int).values
y_val = val_df['Mag'].astype(int).values
print('y_train:', y_train)
print('\ny_val:', y_val)
最後に、NumPy配列をPyTorchのTensor型に変換します。
import torch
x_train_tensor = torch.from_numpy(scaled_x_train).float()
x_val_tensor = torch.from_numpy(scaled_x_val).float()
y_train_tensor = torch.from_numpy(y_train).long()
y_val_tensor = torch.from_numpy(y_val).long()
print('x_train_tensor:', x_train)
print('\nx_val_tensor:', x_val_tensor)
print('\ny_train_tensor:', y_train_tensor)
print('\ny_val_tensor:', y_val_tensor)
学習
まず、モデルを定義します。
import torch.nn as nn
class Classifier(nn.Module):
def __init__(self, embedding_dim, hidden_dim, tagset_size):
super(Classifier, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(embedding_dim, hidden_dim) # 隠れ層
self.hidden2tag = nn.Linear(hidden_dim, tagset_size) # 線形変換してsoftmaxへ
self.softmax = nn.LogSoftmax(dim=1) # dim=1なので行方向を確率変換を行う
def forward(self, sentence):
_, lstm_out = self.lstm(sentence.view(1, -1, self.embedding_dim))
tag_space = self.hidden2tag(lstm_out[0].view(-1, self.hidden_dim))
tag_scores = self.softmax(tag_space) # 確率を出す
return tag_scores
次に、ハイパーパラメータ・損失関数・最適化手法を定義、モデルのインスタンス化をします。
import torch.optim as optim
EMBEDDING_DIM = 6000 # 埋め込み層の次元数
HIDDEN_DIM = 128 # 隠れ層の次元数
TAG_SIZE = 10 # カテゴリ数
model = Classifier(EMBEDDING_DIM, HIDDEN_DIM, TAG_SIZE)
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
学習を実行します。(スケジューラは使用しません。)
num_epochs = 100
dataloaders_dict = {
'train': train_dataloader,
'val': val_dataloader
}
for epoch in range(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}')
for phase in ['train', 'val']:
if phase == 'train':
model.train() # モデルを訓練モードに
else:
model.eval() # モデルを検証モードに
# 損失和
epoch_loss = 0.0
# 正解数
epoch_corrects = 0
# ミニバッチ学習
for inputs, labels in dataloaders_dict[phase]:
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = loss_function(outputs, labels)
# 推論
_, preds = torch.max(outputs, 1)
# 訓練モードのときのみ逆伝播
if phase == 'train':
loss.backward()
# 重み更新
optimizer.step()
# [損失の平均×データ数]を損失和に加算
epoch_loss += loss.item() * inputs.size(0)
# 正解数を加算。accuracyの計算に使用する。
epoch_corrects += torch.sum(preds == labels.data)
# エポックごとの損失
epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset)
# エポックごとのaccuracy
epoch_acc = epoch_corrects.double() / len(dataloaders_dict[phase].dataset)
print(f'{phase} Loss: {epoch_loss} Acc: {epoch_acc}')
50データ全て同じ内容なので、かなり低い損失になっていることでしょう。(過剰にも程がある過剰適合)
損失は低ければ良いというものではありません。
(「バイアス」「バリアンス」〜「過学習を防ぐ様々な工夫」などについて今後記事にする予定です)
また、本気で取り組みたい方は最低でも100個ほどのUD,EW,NSファイルでCSVを作成してモデルを開発してみてください。
精度の良いモデルができたら必ず以下のコードで保存しましょう。
torch.save(model.state_dict(), 'model_weight.pth')
保存したモデルを使用する場合は以下のコードでロードするだけで再利用できます。
推論サーバにデプロイするときは保存したモデルをサーバに設置し、サーバサイドスクリプト(FastAPI,DRF,Flask等)でロードします。
model = torch.load('model_weight.pth')
推論
先ほど紹介したデータ作成のコードを使用して、テスト用データを作成します。
未知のデータに対するテストなので、学習と検証に使用していないUD,EW,NSファイルを使用してください。
- 作成するデータはk-net-test.csvというファイル名で保存し、colabにアップロードします。
- アップロードが完了したら、上記で見覚えのある以下のコードでテストデータを作成します。
test_df = pd.read_csv("./k-net-test.csv")
x_test = test_df.drop(['Unnamed: 0','Mag'], axis=1).values
y_test = test_df['Mag'].astype(int).values
scaled_x_test = sscaler.fit_transform(x_test.T).T
x_test_tensor = torch.from_numpy(scaled_x_test).float()
y_test_tensor = torch.from_numpy(y_test).long()
推論を実行します。
classes = [0,1,2,3,4,5,6,7,8,9]
model.eval() # モデルを検証モードに
for input, label in zip(x_test_tensor, y_test_tensor):
with torch.no_grad():
# 推論
pred = model(input)
predicted = classes[pred[0].argmax(0)]
actual = classes[label]
print(f'予測Mag: "{predicted}", 正解Mag: "{actual}"')
最後に
今回はとりあえず動作だけする形でのデータを使用しましたが、それでもエポックごとに損失が減少していく様子は見ていて気持ちの良いものかと思います。
興味のある方は適切な学習データと検証データの組み合わせや割合、適切なハイパーパラメータなどを探ってみると面白いです。
ただし、闇雲に手探りするのには限界があります。
先ほども触れた通り、モデル開発において重要な概念である「バイアス」「バリアンス」〜「過学習を防ぐ様々な工夫」などについて今後解説する予定です。
以上、ご拝読いただきありがとうございました。
参考