CloudNative Days Tokyo 2019 / OpenStack Days Tokyo 2019、行ってきました。
スライドと、簡易版レポートというよりメモ
https://cloudnativedays.jp/cndt2019/
スライドリンク(整理中)
見つけ次第更新します。
公式でまとまるとは思うけど…
Day1
- [1AL] Datadogで実現するこれからのコンテナ監視
- [1EL] Kubernetes Ingress Controllerにセキュリティを実装してみた
- [1FL]-1 今からでも遅くない!アプリケーションエンジニアが知っておきたい、Dockerコンテナの基礎知識
- [1FL]-2 理想的なマイクロサービスアーキテクチャを目指す継続的改善
- [1GL]-1 kubernetesを運用したことで学んだアンチパターン
- [1GL]-2 コンテナ化に向けたクラウドベンダー比較選定のイロハ
- [1HL] Kubernetesクラスタのポータビリティを保つための8原則
- [1A1] Kubernetesクラスタの自動管理システムのつくりかた
- [1B1] Kubernetesを拡張して日々のオペレーションを自動化する
- [1C1] Argoによる機械学習実行基盤の構築・運用からみえてきたこと
- [1D1] OpenStack コミュニティの現在と今後
- [1E1] How Kata protects containers
- [1F1] Bifrost standalone Ironic を使ったGPU基盤構築運用への適用について
- [1G1]-1 Rancherで始めるCloudNative!! Session編
- [1G1]-2 Rancherで始めるCloudNative!! Hands-on編
-
[1H1] TripleO Deep Dive
- OpenStackユーザ会で発表された更新版: TripleO Deep Dive 1.1
- [1A2] オンプレとパブリッククラウドの両方でKubernetesを一元管理できる唯一の方法
- [1B2]-1 Kubernetes拡張を利用した自作Autoscalerで実現するストレスフリーな運用の世界
- [1B2]-2 adtech studioにおける CRD 〜抽象化したGPUaaSによる段階移行計画 & AKE Ingress v2~
- [1C2] エンタープライズが求めるサービスメッシュとは?
- [1D2] CircleCI 2.0を支える2つの コンテナクラスターとSRE
- [1E2] オイラ大地のECサイトのマイクロサービス化をVA Linuxが性能分析してみた
- [1F2] OpenStackオンプレクラウド開発に必要だったこと -アジャイルを邪魔しないインフラ-(仮)
- [1H2] k8s上のアプリケーション向け Secure Service MeshをA10でつくる
- [1A3] 機械学習を用いたIoTシステムの実現 -データ収集からエッジデバイスでの推論まで-
- [1B3] Cloud Native Storageが拓くDatabase on Kubernetesの未来
- [1C3] 今さら聞けないOpenStack 〜クラウド基盤って何が嬉しいのかを再確認
- [1D3] KubernetesでJVMアプリを動かすための実践的ノウハウ集
- [1E3] Knativeで実現するKubernetes上のサーバーレスアーキテクチャ
- [1F3]-1 PTLのお仕事とOpenStackリリースパイプラインの裏側
- [1F3]-2 OpenStackアップストリーム活動実践(中級)
- [1G3] Operatorでどう変わる?これからのデータベース運用
- [1H3] TungstenFabricでk8sとOpenStackのラクラクNW統合
- [1A4] LINEにおけるOpenStackの運用とUpstreamへの取り組み
- [1B4] OCIv2?!軽量高速なイケてる次世代イメージ仕様の最新動向を抑えよう!
[1C4] RELEASE FAST OR DIE: DevOpsを加速させる Universal Artifact "JFrog Artifactory Platform"のご紹介- [1D4] Kubernetesとアプリをつないだ可視化を実現しよう!-クラウドネイティブアプリの最新運用管理術
- ここかなぁ。ユーザ登録が必要そう。
- [1E4] ヤフーのクラウドネイティブへの取り組みとそれを支えるシステム開発
- [1F4] クラウド基盤を支えるスーパーマイクロのResource Savingアーキテクチャ
- [1G4] Actor Model meets the Kubernetes
- [1H4] Mackerelチームのコンテナエージェント開発における戦略とこれから
- [1B5] メルペイのマイクロサービスの構築と運用
- [1C5] Prometheus setup with long term storage
- [1D5] 失敗しない!Kubernetes向けストレージ選び5つのポイント
- [1E5] k3sで作る!軽量k8sエッジコンピューティング環境
- [1F5]-1 Zuul と OpenStack で作る気の利いた CI 環境
- [1F5]-2 OpenStack QA tooling & How to use it for Production Cloud testing
- 日付は違うけど、ここにスライド(PowrPoint)がある
- [1G5] Ansibleから学ぶOpenStack Python SDK活用法
- [1H5] HCI+OpenStackを用いたプライベートクラウド基盤の導入
Day2
- [K2]-2 決済システムの内製化への旅
- [2AL] あなたにKubernetesは必要ですか? Kubernetesのこれからについて話し合おう。
- [2EL]CNCF サンドボックスプロダクト15本ノック!
- [2FL]100行のコードでDockerの基本を実現せよ!
- [2GL]そのコンテナ、もっと「賢く」置けますよ?
- [2HL] Deep Environment Parity
- [2D1] 転職したら Kubernetes だった件
- [2A1] オペレーターパネル 〜インフラどうなってますか?〜
- [2B1] 実録!CloudNativeを目指した230日
- [2C1] A deep dive into service mesh and Istio
- [2D1] Kubernetes The Heartful Way ~手作りにこだわる職人たちの想い~
- [2E1] OpenStack Tackerで止まらないサービスを
- [2F1] OpenLab: Testing Kubernetes on OpenStack
- [2G1]いつもニコニコあなたの隣に這い寄るカオスエンジニアリング!
- [2H1] Spinnakerで実現する、クラウド開発者のためのデプロイパターン入門
- [2A2] Sysdig クラウドネイティブ インテリジェンス プラットフォームのご紹介
- [2B2] IBM が描くハイブリッド・マルチクラウドの未来、そしてその先に
- [2C2] DX時代のアプリケーション基盤を支えるNEC(仮)
- [2D2] DX実現に向けたプロセスを効率化するLumada Solution Hubでのコンテナ技術適用事例
- [2E2] CI/CDつーるのエラビカタ
- [2F2] Ceph on ARM – Cephストレージをより使いやすくするために
- [2G2] SODA - The Open Autonomous Data Platform For Cloud Native
- [2H2] Rancherで実現するKubernetes Everywhere
- [2A3]-1 Kubernetes CNI プラグイン結局どれを選べばいいのか
- [2A3]-2 最近のDockerの新機能
- [2B3] 〈みずほ〉におけるAWS・Kubernetesを活用したリアルタイム為替予測のアプリケーション開発 ※PDF
- [2C3] クラウドネイティブ技術を創る技術
- [2D3] Understanding Envoy
- [2E3] OpenStack CyborgでFPGA管理を簡単に
- [2F3]歴史から紐解くLinuxカーネルのコンテナ機能
- [2G3] Terraform/PulumiによるOpenStack構築自動化に向けた開発
- [2H3] Cluster APIで簡単Kubernetes on OpenStack
- [2A4]ZOZOTOWN の Cloud Native Journey
- [2B4] Microservices を支える Infrastructure as Software
- [2C4] エンタープライズエッジのビジネスの可能性と運用課題
- [2D4] サーバレス・ネイティブ が お伝えする、フルサーバレス開発の魅力
- [2E4] あなたのk8sは大丈夫?k8sでできるセキュリティ対策
- [2F4] OpenStackを搭載した分散型GPUクラスタの実現について
- [2G4] Challenging Secure Introduction with SPIFFE
- [2H4]Kubernetes に Audit log を求めるのは間違っているだろうか?
- [2A5] マイクロサービスにおける 最高のDXを目指して
- [2B5]Kubernetes Logging入門
- [2C5]クラウドネイティブ時代のセキュリティの考え方とIstioによる実装
- [2D5] スタートアップサービスでもやれる!Kubernetesを使ったセキュアWebアプリの構築と運用
- [2E5] OpenStackにおけるプリエンプティブインスタンス
- [2F5] How cgroup-v2 and PSI Impacts Cloud Native?
- [2G5] [ライブコーディング] Custom Resource と Controller を作ろう
- [2H5] OpenStackとIngress Controllerで作るContainer Nativeロードバランシング
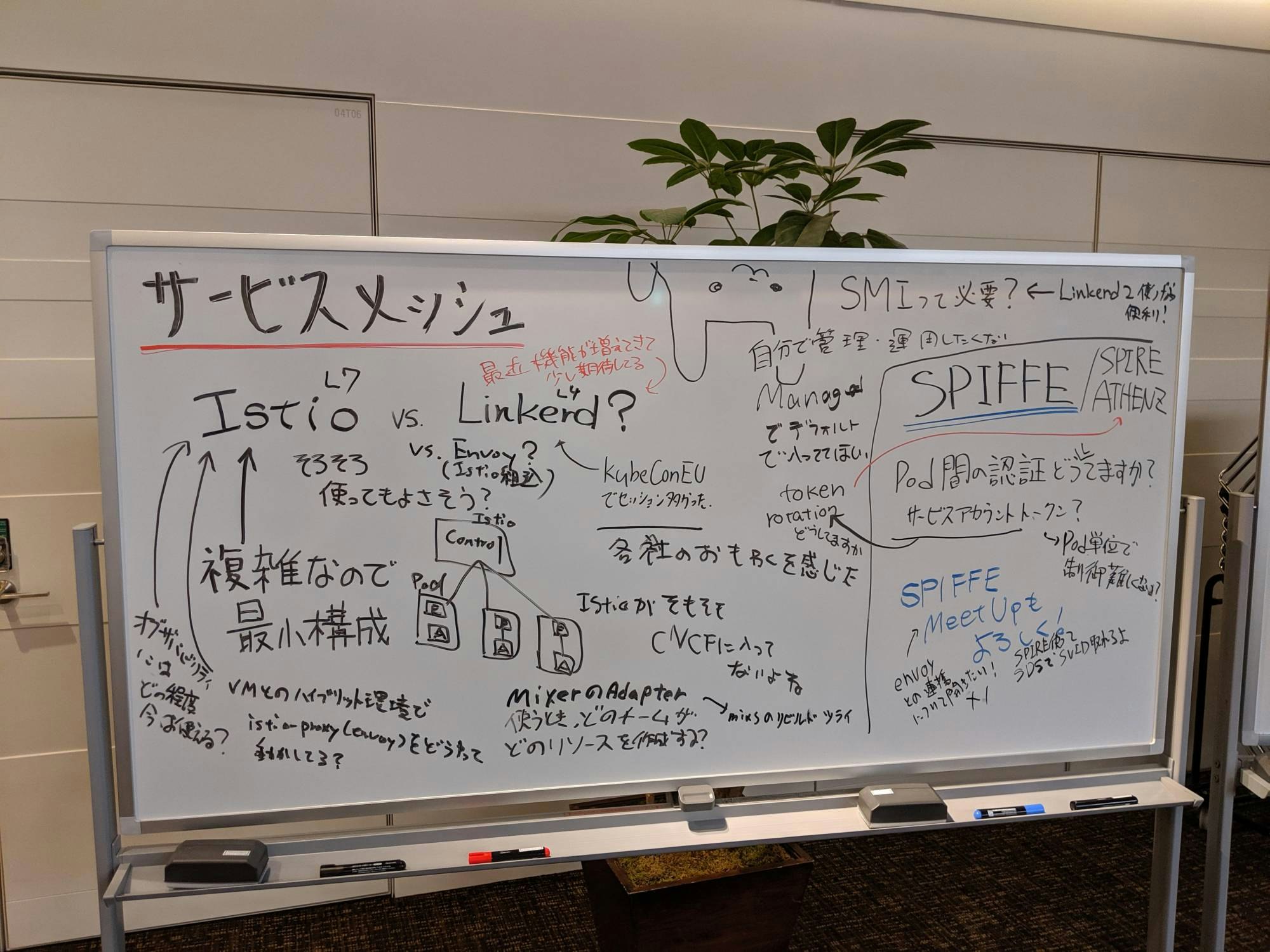
Cloud Native Deep Dive (ホワイトボードディスカッション)
見てたわけではなく、帰り際に撮影したものです。





動画
CloudNative DaysのYouTubeチャンネルから。
https://www.youtube.com/channel/UCMBw1Z3fmhe-2l-iq2p4rNw/videos
登壇振り返りや参加レポートなど
- 【#CNDT2019 登壇記録】Cloud Native Stoageが拓くDatabase on Kubernetesの未来 - Qiita
- みずほ情報総研 : CloudNative Days Tokyo 2019 OpenStack Days Tokyo 2019 講演報告
- 「Knativeで実現するKubernetes上のサーバーレスアーキテクチャ」の文字起こし #CNTD2019 - Qiita
- CloudNative Days Tokyo 2019で『Knativeで実現するKubernetes上のサーバーレスアーキテクチャ』を話してきました #CNDT2019 – DoorLog
- CloudNative Days Tokyo 2019 登壇こぼれ話 #CNDT2019 - チェシャ猫の消滅定理
- CloudNative Days Tokyo 2019 / OpenStack Days Tokyo 2019 拝聴講演に関するまとめ - Qiita
- 「あなたにKubernetesは必要ですか?」を、Kubernetes Meetup Tokyoのコアメンバーが議論:OpenStack Days Tokyo/CloudNative Days Tokyo 2019 - @ IT
- CloudNative Days Tokyo 2019/OpenStack Days Tokyo 2019参加レポート 〜「+Native」へ〜 | PR Blog
- CloudNative Days Tokyo 2019 に登壇してきました - Sansan Builders Box
- Kubernetes Operatorなどさまざまなブレークアウトセッションを紹介、OpenStackの誕生パーティも - クラウド Watch
- メルペイが語る「マイクロサービス開発・運用で気を付けていること」 - クラウド Watch
- AirbnbやKnative、楽天モバイルなどが登壇、Canonicalは「オープンソースとつきあう10のルール」を披露 - クラウド Watch ~OpenStack Days Tokyo 2019 / CloudNative Days Tokyo 2019基調講演レポート~
- SBペイメントサービス、ワイジェイFXの導入事例を紹介 - クラウド Watch
- 写真で見るCloudNative Days Tokyo 2019 | Think IT(シンクイット)
振り返りイベント
- 【増枠!】CloudNative Days Tokyo 2019振り返りNight - connpass
-
日本OpenStackユーザ会 第43回勉強会
-
TripleO Deep Dive 1.1
- CNDT/OSDT2019で登壇したときの資料のバージョンアップ版
-
TripleO Deep Dive 1.1
以下、受講メモ (いわゆる蛇足)
■ day1
[K1] Keynote

Opening
動画: 【CNDT-OSDT2019】Opening Act by Akihiro Hasegawa - YouTube
「クラウドを使いましょう」→「クラウドからクラウドネイティブへ」
+Native
CNCF: Cloud Native Trail Map
アンケート(母数1354の時点):
来場者の+46%がすでに本番環境でクラウドネイティブ技術を活用している。
CNCF企業別commit数(直近180日)
ダントツはやはりGoogle
ほかにはMSMも
その他統計
使用しているサービス。まだAWSが多いのとGCPが意外と多い。
- AWS (577)
- GCP (335)
- Azure (163)
- etc: 194
- オンプレ(OpenStack): 250
- オンプレ(VMware): 149
CNCF Just Now
動画: 【CNDT-OSDT2019】CNCF Just Now by Noriaki Fukuyasu, The Linux Foundation - YouTube
(Graduatedに)CoreDNSというものがあった。しらなかった。
https://qiita.com/kanga/items/e74038f25d1f53ca6ade
CNCF Landscape
1000を超えるアイコン…3年前はもうちょっと見やすかったのだが。
k8s certification: 日本語での受講もできるようになった
Collaboration Without Boundaries(OpenStack Foundation)
動画: 【CNDT-OSDT2019】Collaboration Without Boundaries by Mark Collier, OpenStack Foundation - YouTube
日本に根付いてる。
9年目の誕生日を迎える。
OpenStack,最初はNTTからたくさんきてくれてた。
日本でカラオケ&ネクタイを頭に巻きましたw
「国境を越えたコラボレーションは可能である」
木と木は根を通して通信してるらしい。OpenStachも同じ。
OpenStachはOSSのTop3に入る(他はLinux/Chronium)
クラウドのシェア
- internal private
- hosted private
- public private
だいたい3割ずつ。
Performing Infrastructure Migrations at Scale(Airbnb)
動画 (コメント欄で教えていただきました!ありがとうございます)
Performing Infrastructure Migrations at Scale - Melanie Cebula, Airbnb - YouTube
こちらはKubeCon China 2019のものとのこと。(コメント欄にて指摘)
動画: 【CNDT-OSDT2019】Performing Infrastructure Migrations at Scale by Melanie Cebula, Airbnb - YouTube
Airbnb、70%以上がk8s
400以上がクリティカルサービス…?(聞きそびれた)
tech debt
「マイグレーション」によって効率を見直す
マイグレーションをうまくやっていくには
- マイグレーションをタイプ別に分類(コンポーネント・システム:CI/CDを変更するとか・インフラ:k8sに移行する)
- マイグレーションの順序・依存性
:
:
10まである
- cascading migration
non-cloud -> k8s
いろんな依存性がでてくる
段階を踏んでmigrationしていく。
-
riskの低いmigrationsからやっていく。
依存関係のないものを独立でやることで効率があげられる。 -
優先順位をつける。
IaCから。
最初の7,8割はうまくいっても残りはうまくいかないことも。
うまいことコントロールしよう。
The 10 new rules of open source infrastructure(Canonical)
参考資料: (コメント欄で教えていただきました!ありがとうございます)
The 10 new rules of open source infrastructure
- Consume unmodified upstream
修正されていないコードを使う
- Infrastructure-is-a-Product
インフラは製品
IaaSでも初期費が一番高くなる。
- Automate for day 1826
1826: 5年
5年後を完全に予測することはできない。
Livepatch(DeAN)稼働させたままカーネルのパッチをあてられるものがある。
- Run at capacity on-prem. Use public cloud for overflow.
きちんと設計してただしいH/Wを手に入れよう。
パブリック・プライベートクラウドの使い分け。
- Upgrade, don't backport
バックポートはしちゃだめ。
バックポートしようとすると手作りのインフラになる。それはプロダクトじゃない。
- Workload placemnent matters
何が起きているか、その時に知りたい。
アプリ層で起きてること・インフラ層で起きてること、その間のことを把握する。
- Plan for transition.
Edge
- Security should not be special
セキュリティは特別なことじゃない。
セキュリティを後付けするな。
最初から作りこむこと。ほかの非機能要件と同じ。
- Embrace shiny objects
新しくキラキラしたものを取り入れよう
- Be edgy, go Micro
$ snap install microstack --beta --classic
$ snap install microk8s --classic
Demand Less Choices!(IBM)
動画: 【CNDT-OSDT2019】Demand Less Choices! by Doug Davis, IBM - YouTube
Serverless
scale to 0まで落とせる。
PaaSだとそこが難しい
Knative
(demo)
1コマンドでpod/svcなど一気に作ってくれる。
kn service create myapp --image duglin/helloworld
[1HL] Kubernetes クラスタのポータビリティを保つための8原則

ポータビリティを保つための原則
検討中もおおいけど、本番導入してる人結構いる。
「ポータビリティとは」
クラスタ管理者にとってのポータビリティ。
なぜポータビリティが必要なのか。
クラスタ再作成の必要性に耐えられる。ベンダロックインもある程度避けられる。
ポータビリティの対象は。。
- サービス
- クラスタ管理
- クラスタの仕様
インフラとしては、サービスのリソースは気にしない(アプリケーションエンジニアに任せる)
※アプリエンジニアがインフラをいじれることを前提
etcdのバージョンアップ
in-placeのアップグレードはリスクが高い→行わない
クラスタを再作成してそちらに引っ越すという手順を採用
しかし、40超えユーザ・300超えnamespaceで非現実
目指す世界
いつでも本番k8sクラスタを捨てられるようにする。
※ 必ずしもすべてのk8sクラスタが持つべき原則というわけではない(Wantedlyでは、という話)
コードベース
依存宣言
バージョンを固定する。「このバージョンを使う!」ということ。
新しくクラスタを作ったときにバージョンが異なると同じ動作ができるとは限らないため。
単一方向ビルド
コードベースの変更なしにクラスタを変えない。
非名前管理
podのsuffixのように、「この名前に依存したらマズそう」という名前を付ける。
DNSの場合は、CNAMEをつけて名前解決する。
キーを直接参照せずにワンクッション挟む。
重複欠損管理
これから作る場合は、jobの冪等性を保つなど、create and deleteで問題ない作りにしましょう。
教訓
複数管理することを想定しておくこと。
大規模になってから考えるのは難しい。
[1A1] Kubernetesクラスタの自動管理システムのつくりかた
インフラ刷新プロジェクトNeco
- クラウドネイティブ技術をつかってサイボウズのインフラを刷新するPJ
- 自社DCの1000台規模のサーバ上にk8sクラスタを構築
最高のインフラ
- 高可用性
- 信頼性
- 高性能
- セキュア
- 安価
構成
- GitHub
- Quay
課題を解決するためのツールを作成
「CKE」
Cybozu Container Engine
なぜKなのにContainerなのだ笑
- 構築だけでなく運用まで自動化
- Declarative COnfigurationz
- バックエンドはetcdとVaultを使用
- Goで実装
既存ツールとの比較
k8s構築はいろいろあるが、運用の自動化までは対応してなかった。
Rancherは一部要件にマッチしなかった。
Secretリソースの暗号化など。
ツールの自作によってK8sクラスタの運用ノウハウ蓄積も狙い
CKE基本動作
管理サーバ: Vault + etcd
CoreOSで構築
workerは1000台規模
APIサーバのロードバランス
軽量TCPリバースプロキシ rivers を作成。
各ノード上にriversを稼働し、各ノード上からのapiサーバアクセスはlocalhostへの接続という構成
etcd接続問題:
ノードから「先頭の」etcdへのアクセスに失敗すると、なぜか接続できなくなる問題がある。
riversをかますことで、riversが落ちているetcdを回避して接続できるので問題回避できる。
運用の自動化
期待するクラスタの状態を宣言しておくことで、気体の状態と一致するように自律的にオペレーションを実施する。
秘密情報の管理
守るべき秘密
- ssh鍵
- CA証明書の秘密鍵
- k8sのsecretリソース
- 外部サービスアクセス用の鍵
HashiCorp社の秘密情報管理ソフトウェアのVault
Vaultの認証・認可
- 多様な認証方式に対応
- SSO, AppRole, K8s連携
k8sのEncrypting Secret Data at Rest
このDEKを暗号化するための鍵暗号化鍵(KEK)をどこに保存するかが課題。
cybozuではValtを使用。
クラスタ管理自身の冗長化
管理システムも冗長化しないと単一障害点になってしまう。
Vaultはetcdをバックエンドにし、HAモードを有効化する
CKEはいずれか1つのプロセスがリーダーとして実行
分散システム構築のおともにetcd
強い一貫性モデルの分散キーバリューストア
まとめ
つくるのはやはり大変。1年くらいかかった。
が、k8sにはかなり詳しくなれる。
k8sの自前で運用するのは非常に大変。
普通はやっぱりマネージドサービスの利用がお勧め
公開情報
[1B2]-1 Kubernetes拡張を利用した自作Autoscalerで実現するストレスフリーな運用の世界

k8s拡張のCRD/Custom Resourceを使用した事例。
CyberagentではGCP利用しているので、GCP前提の内容になっている。
- Cloud Pub/Sub
- GCPで提供されているメッセージングサービス
- Cloud Bigtable
- GCPのストレージサービスでスケーラブル・高いスループットのKVS
- Autoscale機能はない
これらを組み合わせたアーキテクチャになっている。
Bigtableの遅延に対するスケールを手動運用してた。
遅延が解消したあとのスケールインも手動。
プログラムからscaleする機能はもともとあったが、Autoscaleはできなかった。
また、CPU/メモリ負荷だけでなく、リクエスト数などでスケールしたい。
これまではHPA(Human Pod Autoscaler)で対応。
そこで自作。
Gemini
k8sのCRDを利用したCustom Autoscaler
メトリクスの時系列データ、Stackdriver Monitoringと連携
Custom ControllerはkubebuilderなどのSDKは使わずにフルスクラッチ
(当時は情報が少なかったため)
deployment更新はkubernetes/client-go
なぜCustom MetricsでなくCRDを使ったか
- Bigtableのノードのスケールにも対応させたかった(podのスケールトリガーだけでは不足)
- 単純にCRDを使ってみたかった
Autoscalerの自作によってロジックやトリガーに柔軟性をもたせられるが、運用レベルになるまでの調整が大変。
[1B2]-2 adtech studioにおける CRD 〜抽象化したGPUaaSによる段階移行計画 & AKE Ingress v2~

スライド: https://speakerdeck.com/masayaaoyama/cndt2019-ca-k8s-gpuaas
コンテナ・アプリケーション実行基盤としてのk8s
X as a Service基盤としてのk8s
k8sは小さなクラウドに近い。
分散システムフレームワークとしてのk8s
期待する状態を記述しておくことで、あるべき状態に収束するように動作する
MLエンジニアが複雑なマニフェストを書くのは厳しい
MLTask CustomResource for GPUaaS abstraction(仮称)
Controller化することで、キャッシュを効かせたりいい感じにしてくれる。
[1G3] Operatorでどう変わる?これからのデータベース運用

k8s operatorを使うとどんなことができるのか・どんな点がうれしいのか
AmebaのオンプレK8sクラスタ:OpenStack上に構築。Kubespraydeデプロイ
DBはk8sクラスタ外にVMで構築
今ならDBをk8s上に乗せることもできる?
どんな方法がある?
コンテナでステートフルなアプリを動かすには
永続データをどうするか
アプリ固有の運用ナレッジをどうするか
の2点を考慮する
webのようなステートレスなものはスケールが簡単。ポータビリティも高い。回復力が高く、k8sと相性が良い
DBや分散システム、状態を持つアプリケーション
永続データ・名前の問題ふくめ、statefulsetを使って解決できる。k8s組み込みのリソース。
statefulsetによって、永続データの扱いは解決できる。
ではアプリ固有のナレッジは??
k8s Operatorとは
運用上のナレッジがソフトウェアとして実装されている。
Operator自体もk8sでコンテナ化されている
ユーザはk8s独自のResourceとControllerで拡張できる。Operatorはこの仕組みを活用
実例 MySQL Operatorを動かしてみよう
oracle/mysql-operator を使用した、MySQL InnoDB Clusterのk8s環境へのデプロイ
お、これはcndjpのRDB特集でも扱っていたやつだ!
Oracle MySQL Operator 検証してみた
バックアップとリストア
- kind: Backupリソースを使って作成。
- mysqldumpを実行してくれる。
- BackupScheduleで定期実行もできる
- リストアも同様にkind: Restoreで行う。
障害発生時はどう?
primaryのpodが落ちた場合はクラスタから切り離され、secoundaryがprimaryに昇格する。
k8sが新しいpodを立ち上げ直し、データ同期が行われる。
nodeが落ちた場合、StatefulSetのpodは自動で再スケジューリングされない。
podのステータスはUnknownになる。
sprit-drainによる障害防止のため、再作成は行われない。
K8s Operatorのこれから
- presslabs/mysql-operator
- Vitess
その他にも、Operatorが存在するDBはいろいろある。
-
https://github.com/operator-framework/awesome-operators
- 公開されているOperatoarをアプリごとにまとめたリスト
-
https://operatorhub.io/
- RHが公開してるポータルサイト
k8s operatorでNoOpsを実現?
システム運用保守で「嬉しくないもの」を取り除く活動
- self healing
障害が発生してもサービス無影響+自己修復 - in-flight renewing
- Adaptive Scale
自動化されたシステムはブラックボックスになりがち。
きちんと知識を持ったエンジニアは必要。
障害発生時に手がかりを残すための仕組みは必要(ロギング・モニタリング)
自動化が失敗した場合の手段は用意しておく。
最後の手段はやっぱり人手。
AWS Service Operatorなど、クラウド上のマネージドサービスを操作するOperatorもある。
全体的にわかりやすく説明されていて理解しやすかった。
恐るることなかれ! Cloud NativeリレーショナルDB特集!! - cndjp第12回に参加していて前知識が少しあった影響はあると思う。
[1C5] Prometheus setup with long term storage

スライド90ページくらいあるのであとで見返してください!
背景
メトリクスの必要性:
ユーザ環境のリソース利用状況はサービス側で監視。
時系列データベース
- Head Block
- Block
- デフォルトでは2時間程度でストレージに保存
それぞれのBlockは完全に独立した時系列DBとして振る舞う。
meta.json内で重要なのは、minTime/maxTimeの「いつからいつまでのデータなのか」。
■ day2
[k2] キーノート

keynote (day2)
撮影時のシャッター音絶対NG!
楽天モバイル 完全仮想化クラウド型モバイルネットワーク
完全自動化されたOS
Rakuten Cloud Platform
試験環境・CI/CD
ベンダーのラボとつながっており、そこでテストしたものが商用ネットワークへリリースされる構成になっている。
草間さん、つなぎのトーク
CloudNative、コンテナつかえばクラウドネイティブってわけじゃないよね。
クラウドからクラウドネイティブって何が違うの。
クラウドを使っても、手作業でOSつくったりするとそれはプラットフォームがかわっただけ。
自動化・SRE
1箇所でも手作業が入れば、そこがボトルネックになる。
自分でぽちぽちプロビジョニングすると数分でも時間かかる。
そういったボトルネックをいかになくしていくのがクラウドネイティブでは重要
決済システムの内製化への旅
SB Payment Service
今回の資料じゃないけど、別の発表でのスライドあった
https://www.slideshare.net/makingx/springpcf-jsug-sfh1
今回のもアップされてた
https://www.slideshare.net/JunyaSuzuki1/springpcf-cndt2019-osdt2019-keynote
Springと
決済代行のお話
内製化に至る道
以前はほぼベンダ任せ。
運用の手作業も多かった。
→支援ツールの内製
- Spring Boot
- Selenium/Selenide
使用ツール
- GitHub Enterprise
- slack,Confluence,Jira など
サービス監視の質を高めるため、ElasticStackの導入。
監視用ダッシュボードを作成。
- Elasticsearch
- Kibana
- Logstash
開発プロジェクトの支援
古いアーキテクチャが使われており、開発/リリースともに高コスト。システム監視も困難。
アーキテクチャをSpringベースに
- Spring Boot
- Spring Cloud
導入したもの
※CIをきちんと回す支援
- Jenkins
- Nexus
- sonarqube
新システムに求めるもの
・スピード感の開発・リリース
・継続的な改善のサイクル
・監視が用意で障害に強い
これまではすべて開発ベンダに頼り切り。スピード感もでない
Pivotal Cloud Foundryを選んだ理由
プラットフォームに求めるもの
- リリースの改善
- クラウドのフル活用
- スケーリングやオートヒーリング
k8s or PaaS
学習コストや少人数の体制など、k8sはなかなか厳しい
すでに確立されたプラットフォームがほしい→PaaSを採用
Public Paas or Private PaaS
決済サービスのエンタープライズ領域など、privateを採用
Pivotal Cloud Foundryを使用。
Java/Springアプリの親和性
cf pushコマンドによるアプリリリース
Buildpackという仕組みでソースコードからコンテナイメージを作成してくれる。Dockerfileを書く必要もなし
プラットフォーム運用とアプリケーション開発者の責任分界もPivotal Cloud Foundryはきっちりしてる。
それぞれの作業に集中できる。
開発者は12Factor appに沿って開発。ベンダーロックインもない。
手に入れた開発/運用のカタチ
Circuit Brakerにより対象外性にすぐれた構成
CI/CDパイプライン
Concourse CI
Observability
参考:Metrics, tracing, and logging
- Metrics: Graphana Prometheusなど
- Logging: Elastisearchなど
- Tracing Zipkin (初めて聞いた)
以前はログから可視化していたメトリクスについては
開発者はPrometheusを意識することなく、アプリをリリスすると自動で監視できる仕組みができる。
アクセスログ・アプリケーションログはKibanaで表示
開発者はElastic Stackを意識することなく、STDOUTへログを出せばOK
キーワード監視でSlack通知など
Zipkin
複数のサーバにまたがる処理でも、どこの通信やSQLかひと目でわかるようになる
サービス目線のモニタリングが大事
外注にたよりきった開発を積み重ねてもプラットフォームは構築できない。
金融領域におけるOpenStack導入事例の紹介
YJFX (Yahoo Group)
システム構成
Front system・Analyze SystemにOpenStackを導入(客から見るとバックエンド)基幹系
なぜ導入したか
本番・STG・開発、パブリッククラウド使っていた。
- コストの問題
- 金融系はやりたいことが増えるだけで、必要リソースは増えるばかり。
- デリバリの問題
- アプリのリリース、インフラTに依頼して構築、オーバーヘッドがあった
- 使用前に申請的なこともあり、クラウドの意味とは・・・
導入時のGood Point
※ペットから家畜
- Ansibleの活用
- 100台のサーバを30分で構築
逆に、Ansible活用できていないレガシーシステムの以降は苦労する。
- import/export
- device mapping
- Network Configuration
トラブルシューティング
RHのサポートが待てない・・・
- ドキュメントの戦い
- ドキュメントが間違っている
- ソースコードこそがすべて
OpenStackの導入によって、Red Hat Summit 2019の登壇の機会
→ レガシー派のメンバや経営層からの評価がかわった。
真のCloud Nativeになる
単にクラウドを使っている状況からの脱却
どうクラウドにするか。用途に合わせたマルチクラウド設計
クラウド前提としたアプリケーション含めたアーキテクチャ設計
コンテナ・運用自動化・オーケストレーション
レガシーシステムのモダナイゼーション
すべての技術負債をすぐにどうこうすることはできない。(いま作ってるものが、将来技術負債といわれることも)
システムは経営の問題を解決するものである。
経営の課題ってなんだっけ?それを解決するには?
こういうことに取り組む。
エンジニアリングだけ成功してもだめ。
経営・サービス企画の意識改革も必要。
Change the game, Change the world
RedHat北山さん
k8sはプラットフォームを作るためのプラットフォーム、と最近言われるようになった。
プラットフォームとは・・・
企業やユーザが提供する製品・サービス・情報と一体になって初めて価値を持つ製品やサービス
プラットフォームを利用するコストよりも得られる価値が大きくなければ使われない。
- Velocity(迅速性)
- Self-Healing(自己回復性)
- Abstraction(インフラの抽象化)
k8sの利用によって、クラウドリソースが抽象化され、運用工数を下げられる可能性はある
ただし、技術力や情報が少なくても利用できる、というものではない
+Native
運用工数を下げるためのポイントが、既存すステム運用とは大きく変わるという意識改革
・クラウドに使われるのではなく、クラウドの運用方法に自らを変えていく
Operator
運用の知見をコード化し、アプリケーションの運用を自動化する
- OpenShift4はOperatorHubと連携
- OpenShiftで見えるOperatorはRH認定
Operator Framework: Operatorsと呼ばれるk8sネイティブアプリケーションを効果的に開発できる
OperatorSDK
OpenShiftのドキュメントにも載ってた
- 第40章 Operator Framework (テクノロジープレビュー) のインストール - Red Hat Customer Portal (OpenShift 3.11)
- 第9章 Operator SDK - Red Hat Customer Portal (OpenShift 4.1)
- 2.1.2. Operator Framework
Couchbase Operator
OperatorをOperatorで管理する
OpenStackを用いたパブリッククラウドの国内事例と課題
お名前.com レンタルサーバもOpenStack
2019年にリリースしたクラウドサービスはOpenStacではない独自基盤
[2B1] 実録!CloudNativeを目指した230日

230日とは…JKD v18.12からの日数
-
Beremetal Era
- サーバ投入のリードタイムがボトルネックだった。
- サーバのサイジング
- 作業するエンジニアのアサインやキャパシティプランニングが難しい
- サーバ投入のリードタイムがボトルネックだった。
-
Cloud Era
- OpenStackを用いたプライベートクラウドへ
- 物理サーバの管理を集約することで効率UP
仮想化されているとはいえ、設計・構築は時間はかかる。
普段アプリ系の人間であればやはり難しい。
-
クラウド化しても、存在する課題
- 人が介入するとやはりボトルネックになる
- 自動化されてない箇所はオペレーションが必要
-
解決するには?
- IaaSのまま自動化をすすめる(OpenStack Heatなど)
- IaaSを隠蔽するようなプラットフォームを導入(CaaS/PaaSなど。ただし管理するレイヤーが増える)
そこでk8sを導入
「k8sって、運用大変なんでしょ?」
導入できても運用で疲弊すると、本質的な課題解決にはならないのでは?
→もし力尽きても全くの無駄にはならない
コンテナ化による技術の蓄積
ポータビリティ性により、マネージドサービスへ移行もできる
なぜ共用クラスタから始めたのか
IaaSとk8sでは考え方がかなり違う。やはり学習して慣れていくしかない。
minikube、kindなどいまはいろいろある。
興味を持ったときに、すぐ触れるクラスタがあるべき
minneへのk8s導入
問題発生時にすぐに切り戻せる体制で導入
Consul Kubernetes Integration
Consulのサービスとk8sのサービスを相互に同期
podが動いてるnodeのIPをnode
(んー、OpenShiftの外部LB+router podに近いかんじかな?)
既存システムにトラフィックも流せた。完了!
・・・とはいかず。
k8sへトラフィック増やしたら、特定podへの付加集中がたまに発生
- どうやって被疑個所を絞り込むか
- 絞り込んだ後の原因特定をどうするか
特定のpodに偏るということはLB周りがあやしい。
トラフィックを見てみよう。
Prometheus+Grafana
結果、ルーティングがやはり怪しい。
では、ルーティングの仕組みはどうなっているのかを調査。
balancer.balance()
- luaを使っている
- RoundRobin(default)とEWMAが使用可能
ingressのpod数が多いと発生すると可能性がある
nginx-ingressのpod数が多いと、Serviceのendpoint更新時に全ingressにアドレス一覧が反映されるが、それまでのRoundRobinの状態がリセットされ、トラフィックの負荷分散が初期値に戻る…なるほど
CloudNativeになれたか
まだ過度期である!
「手作業でできないことを自動化するのはとても難しい」
基盤サイドとしては「抽象化されたプラットフォームの提供・考え方の啓蒙」
k8sになると「1インスタンス1ロールでなくなるので問題児の原因特定が難しくなった」
可観測性・Observabilityの強化し、調査ポイントを絞り込めるようにすることが重要
[2H2] Rancherで実現するKubernetes Everywhere

Genericな話をします。
明日渋谷でRancher Dayやります。
k8s,k3sがホット
今から始める人はk3sから!
もともとRancher Linuxというディストリつくってた。
GUIの管理ツール
Lightweight Kubernetes
curl -sfL https://get.k3s.io | sh -
クラウドじゃないけどk8s使いたいとき。
Launcher一択という人はおおい。
k3s
Edge側にも入る。
Launcherは統合開発プラットフォーム
RancherのGitHubのStartは12000弱
Helmに近い
レガシーなものをコンテナ化する際にLauncherの選択肢
20年たってるものをコンテナ化…
ディズニーの映画配信はLauncher
さまざまなk8sを一元管理する、それがLauncher
- RKE(オンプレ)
- EKS
- GKE
- AKS
機械学習の基盤としてのk8s/Launcherの問い合わせがとてもおおい
Kagoyaのコンテナサービス。近日リリース予定。
他社クラウド・オンプレもノードとして追加可能
Rancher管理サーバ1台・ノード1台から開始可能
サポート
https://rancher.com
[2C3] クラウドネイティブ技術を創る技術

haconiwa
柔軟な設定・hookなど をrubyで記述できる。
- なぜk8sではないのか?
- k8sとマネージドクラウドの違う
UI/UX
マネージドサービスはバックエンドを意識する必要がない。
k8sはある程度は必要
API&Scheduler
CMDB: PostgreSQL+Peacemaker
Apache Kafka
高速処理が可能なメッセージングシステム
[2E4] あなたのk8sは大丈夫?k8sでできるセキュリティ対策

- セキュリティおさらい
- CIS Benchmark for k8s
- Secret管理
セキュリティおさらい
コンテナセキュリティのレイヤー
- 実行基盤
- ベースイメージ
- アプリのセキュリティ対策
実行基盤
- SELinux
- capability
- rootコンテナ
- 特権コンテナ
ベースイメージ
野良イメージに注意
- マルウェア入ってない?
- コインマイナー入りだったりしない?
アプリレイヤー
- アプリ・ライブラリに脆弱性ないですよね?
まとめ
リスクとアジリティのバランスをとる
コンテナセキュリティは3層で考える
CIS Benchmark for k8s
CIS Benchmarkとは:Cybersecurity Best Practices
パブクラやk8s、OSにおいて「ここはこうなっているべき」というプラクティス集
kube-bench
動かし方
k8sのホストマシンにバイナリ落として起動。--pid=hostオプションつけ/etc、/varをread-onlyでマウントしてコンテナ実行
k8sで強い権限がある場合: job-master.yamlとjob-node.yamlをapplyする
簡単に実行できるのでさくっとスキャンしてみるのはいかがでしょう?(すべて対応する必要はないが)
Secret管理のためのSealedSecret
・k8s secretはただのbase64
・最近はやりのGitOpsと相性悪い
というわけで、Secretを暗号化してCRD「SealedSecret]を作成。helmでインストール可能(1コマンドで入れられる)
SealedSecretの問題点
暗号化されてるとはいえGitに入れたくない場合
Secret管理できるツールない?
ということで、HashiCorpさんのVault
Vaultで解決できること
- 各種Secretの一元管理
- 期限付きキーの発行
- 暗号化APIの提供
- 暗号化キーのろーてーと
メリット
- Secret情報へのアクセスログの集約
考えること
- 可用性
- 性能
- Auditログ
構築で考えること
- Sealing
- Sealingするとアクセス不可に
- Storage
- HA-Storage
Valtでクラスタ: Active-standbyで、standbyへのアクセスはactiveへリダイレクトされる。
有料版はレプリカ機能もつくらしい。札束で殴れ。
Auditログ
出力先は3type
- File
- syslog
- socket
k8s上にvault立てる場合はsidecarなどで。
Vaultを使う目的を再確認
- k8s管理者はsecretを見れるべきではない
- Vaultを入れることでOpsがやりにくくなってほしくない
そこで、k8sのServiceAccountを使ってvaultにアクセスする。
Vaultアクセスライブラリ
- Official
- vault go client
- vault ruby client
[2G5] [ライブコーディング]Custom ResourceとControllerを作ろう

対象:
- k8s完全ガイドは読んで一通りk8sわかるひと
- CRDはまだの人
もくじ
- k8sのControllerとは
- CRDとCustom Controllerとは
- 本日作るCRDとCustom COntrollerの概要
k8sのControllerとは
k8sのドキュメントより。
現在の状態をみて、理想的な状態にいいかんじにする処理をループでまわす。
理想の状態に一致させる「なにか」
現実世界の例
エアコンのリモコン
ユーザが25度に設定すれば、エアコンがその設定を維持する
ユーザは宣言するだけ
「何か」 Control Loop
Act -> Observe -> diff ->
CRDについて
ReplicaSetやDeploymentみたいなリソースを自分で定義できるもの
CRD+Custom COntrollerを使って、k8s nativeなアプリ(Operator)の開発が可能
詳しくは @Ladicle先生のQiita記事
実際のk8sコントローラと同様のフローで開発しようと思うと、お作法がたくさんでくじけるw
便利なフレームワーク・SDKがある
kubebuilder
こんなの作るよ
apiversion:
metadata:
kind: WebServer
spec:
replicas: 3
content: Hello, CNDT!
port:
http: 8080
この1個前に、プロジェクトのinitialize
kubebuilder create api --group servers --version v1beta1 --kind WebServer
ひな型をビルドされる。
今回はサーバーグループ
お作法的にはαだけど、青山さんもv1beta1を指定とのこと。
きのう・一昨日くらいにbeta2が出たらしい
type WebServerSPce struct {
Replicas int32 `json:"replicas, omitempty"`
}
大元は↓にできてる。↑にSpecの構造を追加する
type WebServer struct {
:
:
}
んで、
$ make manifests
config/crds以下に定義が生成される。
webserver_controller.go
実際にコントロール処理を行う処理がここに実装される。
Reconcileメソッド。
この処理が、webサーバの情報がインスタンス変数をgetしてもってくる。
.Deploymentでdeploymentを処理。
本当はReconcileの中を作成していくが、DeploymentのPodTemplateSpecのなかを編集していく。
今回は、`/bin/sh -c echo で nginx/index.html にstaticなhtmlファイルを生成
DeepEqual(deploy.Spec, found.Spec)
デプロイが定義、foundが現在の状態。
差異があれば定義の状態になるように変更を書ける
make docker-build
make install
make deploy
port設定の追加
入れ子の構造体で定義
make manifest
Deploymentを作るコードはある(作った)ので、今度はServiceを作るコードを作ります。
SetControllerReferenceを使って関連付けを行う。
サポートに聞いたmetadataにあるReferenceのやつかー
特定のイベントが発生したとき
EventResourceを使って作れる
ライブコーディングの流れはGitHubに用意
https://github.com/cloudnativejp/webserver-operator
所感とか…
Custom Controller周り、過去のKubernetes Meetup #18ではControllerやCRDを全く知らずに参加して瀕死の重体になったりしたけど、何度か発表を聞いていたおかげで、何をやっているのかはついていけた。
が、meetupのあとに自分で手を動かして試したりすることを結局しなかったので、さすがにそろそろやってみたい。
あと、Go言語。
ライブコーディングも面白かったのでリポジトリをチェックしよう。
Operatorの話もかなり増えた。OpenShift Meetupなど各meetupでも盛んにOperatorの話が盛り上がっていたのを聞いていたので、やはり事前知識が少しあって助かった。MySQL ClusterなどはCloud Native Developers JPでも聞いていたので、とてもわかりやすかった。
昨年12月のJapan Container Days v18.12のときにくらべて「クラウドサービス提供しています」「社内にクラウドサービス構築して開発/運用やってます」が増えた印象。
(あとでよく考えたらイベント自体がOpenStackでもあるので当然ですね…)
あと、冬のJKDでノートPCのバッテリが終日イベントは持たないことはわかっていたので、Androidタブレット用のBluetoothキーボードを調達して持ち込んだら、ノートPC&タブで1日キーボードでメモ入力できて非常によかった。