Designing A Good Event System API
At MeetsMore, we’ve recently decided to overhaul our old event system and build a better one.
Our old event system used an ‘in memory’ implementation, where you could dispatch events, but they would be processed on the machine that dispatched them.
We experimented with using SQS as a backing queue for this event system, but had issues in the past with exactly-once delivery semantics, so all of our systems were using the ‘in memory’ version (we called this local mode).
In this article, I’ll talk about how we designed the new event system, and how we designed the API to guide developers to making the right choices when using it.
This article is structured so that how the API evolved as we worked on it can be seen.
In this article, API refers to the interface and types that developers will use to interact with the event system.
Goals
Before we started, we had some specific goals for an event system.
- Easily distribute work to worker instances.
- Exactly-once delivery.
- TypeScript first.
- Observable, allowing us to detect issues easily.
- Allow us to retry failed jobs using some approach like exponential backoff.
Choosing A Backing Queue
Before we started, we needed to choose a backing queue that we’d build on top of.
We reviewed a few options, but settled on BullMQ.
- It’s written in TypeScript.
- It is designed with exactly-once delivery as a goal (at-least-once in worst case scenarios).
- There is an existing package for observing it easily (bull-monitor)
We looked at more traditional candidates, like Kafka, RabbitMQ, but concluded these were too heavy for our use case, and would require a lot more effort to maintain and manage than using BullMQ.
BullMQ is backed by Redis, which we already use.
Architecture
Before going any further, let’s show a simplified version of our old architecture, and point out some facts about it:
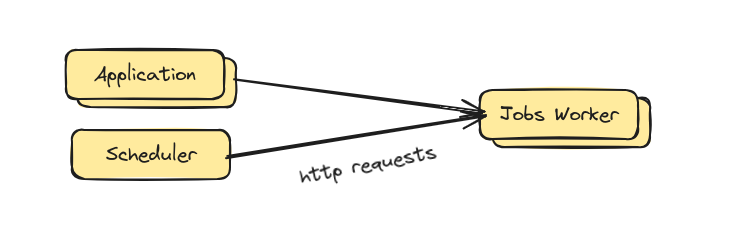
Our existing method of managing ‘scheduled jobs’, which are key to a lot of our systems, was to call API endpoints that jobs-worker instances exposed in order to tell them to do work.
These could either be called by the application directly, or in most cases, would be called by a ‘’scheduler’ service, which was basically just a node.js instance that made API calls on a bunch of crons.
Our application is monolithic, and we had many jobs-worker instances and application instances, the load-balancing was hence handled entirely by ALB load balancers (by routing the requests).
Our jobs-worker and application codebase is the same. They’re the same codebase + application, just configured differently.
A Problem
A big problem with this is that jobs are not well distributed through the system, and usually a scheduler would be triggering jobs like ‘process all of the requests that occurred in the past 30 minutes’.
If one of these jobs resulted in a lot of work to do, that instance would be chewing through them all alone.
We also had issues whereby we had to spread our cronjobs out manually, because if we triggered them at the same time, we would be at risk of causing performance spikes on the machines.
Starting From The Interface
Before we wrote any implementation code, we thought about the concepts in the system and wrote the TypeScript interface.
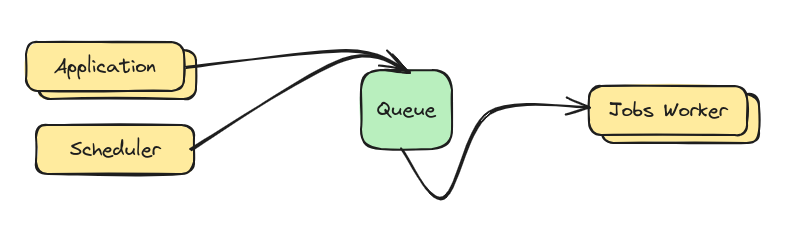
Fairly obvious, but we wanted our queue to sit between the application and the jobs-worker instances, so that events could be distributed across the workers equally.
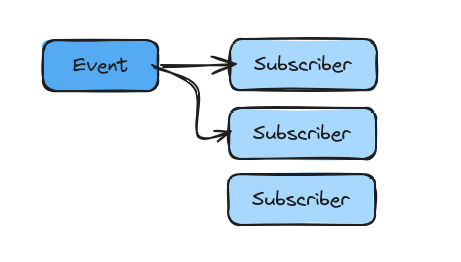
It’s also quickly clear that we have a 1-N relationship between events and subscribers, each event can have many subscribers.
A few needs can be derived from the above diagram.
- We need an ‘Event’ type.
- We need a ‘Subscriber’ type.
- We need some mapping between events and subscribers.
Let’s design our first iteration of the ideal types.
// An event in our system.
interface Event {
/** The payload of the event. */
data: unknown
}
// A subscriber takes an event and asynchronously works on it.
type Subscriber<E extends Event> = (E) => Promise<void>
// The subscriber map is a mapping of events to their subscribers.
type EventMap = [k: Event]: Subscriber<Event>[]
I did all of this in a TS Playground before ever going near our codebase, this let me think cleanly and abstractly about the problem, and get results nice and fast.
We’re not even trying to be correct yet, we’re working imagining what the absolute ideal scenario would be.
Note that I’ve started with
unknowntypes for now until I need to define them.
A few problems arise from the above code.
-
[k: Event]: Subscriber<Event>[]is not valid, we can’t use an Event as a key in our map. - The type of
dataisunknown, which wouldn’t be very useful within our subscriber.
Let’s solve those.
// -> An event in our system.
interface Event<T> {
/**
* The unique name of this event.
* Should follow the pattern `domain.action`.
* @example `user.created`
*/
key: string
/** The payload of the event. */
data: T
}
// -> A subscriber takes an event and asynchronously works on it.
type Subscriber<E extends Event> = (event: E) => Promise<void>
// -> The subscriber map is a mapping of events to their subscribers.
type EventMap = [k: Event['key']]: Subscriber<Event>[]
// -> A function used to send an event.
type DispatchFn = (event: Event) => Promise<void>
Why define Event['key'] instead of just using string since they’re equivalent?
It makes the code clearer as to the intention. We only intend event keys to be used for our map.
There are more type safe ways to do that, but lets continue for now.
Let’s try and use this interface, and see how it feels to use.
// -> Define an event to send.
const event: Event<unknown> = {
key: 'jobs.requests.process'
data: { requests: ['a','b','c'] }
}
// -> Define a subscriber to process the events.
const processRequestsSubscriber = async (event: Event<unknown>) => {
for (request in event.requests) {
console.log(request)
}
}
// -> Map the event keys to the subscribers.
const eventMap: EventMap = {
'jobs.requests.process': [processRequestsSubscriber]
}
// -> Mock 'dispatch' that just executes the subscribers.
const dispatch: DispatchFn = async (event) => {
for (subscriber in eventMap[event.key]) {
await subscriber(event)
}
}
We now have new problems:
- The type of
datais stillunknown. - Our subscribers don’t know what event they’ve received.
- We have to write the
keyof the event twice, in our event, and in our event map.
Let’s fix these issues, i’ll omit the parts that we didn’t change.
abstract class Event<D> {
static key: string
// -> Data is now generic.
data: D
}
class ProcessRequestsJobEvent extends Event {
static key = 'jobs.requests.process'
// -> We're using a nice TS feature here where we can inline a property
// to avoid having to explicitly set it in the constructor of our subclass.
// This also nicely infers the type of T!
constructor(public data: { requests: string[] }) { super() }
}
// -> Our subscriber now has a type to reference.
const processRequestsSubscriber = async (event: ProcessRequestsJobEvent) => {
for (request in event.requests) {
console.log(request)
}
}
const eventMap: EventMap = {
// -> Our key is now only defined once, and where we want to manage it most.
[ProcessRequestsJobEvent.key]: [processRequestsSubscriber]
}
It’s worth noting that along the way here we’ve acquired some complexity.
Namely, we now need to use classes. This is because static properties don’t exist on interfaces.
At this point, we should consider:
- Is the complexity of using classes necessary?
- Is there some other reason we might need to use classes in future anyway?
- Is the impact to our interface acceptable for our end users (other developers)?
Let’s answer these questions:
Is the complexity of using classes necessary?
No, there are other solutions. We don’t have to store the key on the event, but it means that we’d have to manage the key separately from the event, which adds a different kind of complexity.
Is there some other reason we might need to use classes in future anyway?
We may want to validate the events at runtime, e.g. when creating them from a JSON payload.
Is the impact to our interface acceptable for our end users (other developers)?
So far, yes, the impact is not so much, especially given that we can define the type of data inline in the constructor.
We should continue to ask these questions at every stage of our API prototyping.
We have a couple of new issues, however:
// -> We can't deal with `Event` as a concrete type anymore because it's generic.
// We need a 'type erased' Event type.
type EventMap = [k: Event['key']]: Subscriber<Event>[]
const dispatch: DispatchFn = async (event) => {
// -> We can't access `event.key` because it's static!
for (subscriber in eventMap[event.key]) {
await subscriber(event)
}
}
Let’s solve these:
type AnyRecord = Record<string, any>
// -> When dealing with a 'type-erased' event,
// we don't need to know anything about `data`.
abstract class Event<D = AnyRecord> {
static key: string
data: D
public get key(): EventKey {
// -> This allows us to access the `key` on instances.
return Object.getPrototypeOf(this).constructor.key
}
}
Adding features
Now that we’ve got a basic interface to build ontop of, let’s start thinking about some additional functionalities we want to provide.
- Retry failed event subscribers.
- Ensure all events are documented.
- Support ‘before / after’, for ‘change’ type events, as we have many of these.
- Support metadata for events that is useful for logging, but not required within the logic.
- Support our universal set of metadata we use across the company (e.g things like
correlation_id).
I’ll add all these in one go with comments to keep it concise.
I’ve omitted some code and documentation to improve readability, but all of our code has clear JSDocs.
type AnyRecord = Record<string, any>
/**
* A UUID string.
* @example 85f679bf-b786-4eb4-9999-d4b5354909cd
*/
// -> We define a type alias for this to make the code easier to understand.
// Aliases for strings can be useful to make code more readable.
// They also give you a place to centralize common documentation around things.
// e.g. Here we don't need to keep using @example everywhere we use a UUID.
type UUID = string
/**
* The unique name of an event.
* Should follow the pattern `domain.action`.
* @example `user.created`
*/
type EventKey == string
/**
* Universal metadata common to all events.
*/
// -> These use underscore naming for legacy reasons.
export interface UniversalMetadata {
/// timestamp indicating when the event occurred.
timestamp: Date
///event ID (UUID v4)
event_id: UUID
/// Correlation ID (UUID v4)
correlation_id: UUID | null
/// Device ID (UUID v4)
instance_id: UUID | null
/// MeetsMore User ID to be changed (ObjectID)
// -> We track what user an event is related to for debugging.
user_id: UserID | null
/// MeetsMore User ID of Admin (ObjectID)
// -> We track what admin initiated an event for audit and debugging.
admin_user_id: UserID | null
}
/**
* An event in MeetsMore that can be subscribed to.
*/
abstract class Event<D = AnyRecord, M = AnyRecord> {
static key: EventKey
// -> Defining our description here permits a few useful behaviours.
// It's required to implement it, and checked by TypeScript.
// You can see it when logging an event, no need to check code or docs.
// We never need to access it statically, so it can be a member.
abstract readonly description: string
// -> If the side-effects for this event are idempotent,
// and can be retried safely.
idempotent: boolean
data: D
// -> The state before this event occurred.
// Useful for comparing before/after in subscriber logic.
before: D?
// -> Metadata about this event,
// e.g: useful for logging / but not required by logic.
metadata: M
// -> Metadata that is applied universally to all events.
universal: UniversalMetadata
public get key(): EventKey {
// This allows us to access the `key` on instances.
return Object.getPrototypeOf(this).constructor.key
}
}
class ProcessRequestsJobEvent extends Event {
static key = 'jobs.requests.process'
description = 'Triggered when something wants requests to be processed.'
constructor(
public data: { requests: string[] }
public metadata: { triggeredBy: 'scheduler' | 'admin' }
) { super() }
}
‘Fanning Out’
An issue became apparent when we added our idempotent flag.
We’ve been working so far with an event that has one subscriber.
But what happens when we have multiple subscribers?
- If one subscriber fails, we can’t retry just that one.
- Subscribers are idempotent, not Events. An event could have a mix of subscribers.
- Events must have all their subscribers processed on the same machine.
A solution to this is to ‘fanout’ the event into a unique event per subscriber.
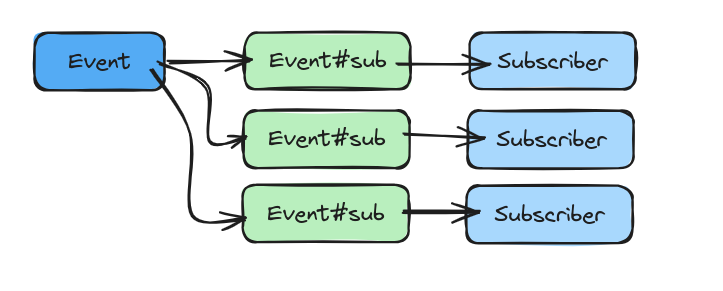
This adds load on the event backend, because now we have as many events as we have subscribers, but the benefits of doing so outweigh the potential cost.
It also makes it much easier to visualize our event load later in our observability platform.
Let’s do it.
/**
* An event in MeetsMore that can be subscribed to.
*/
abstract class Event<D = AnyRecord, M = AnyRecord> {
/**
* The target subscriber for this event.
* Events are fanned out on a 1:1 basis of subscribers.
* If `undefined`, this is a 'parent' event, and will be fanned out to all subscribers when enqueued.
*/
targetSubscriber?: string;
}
/**
* An event that has been fanned out into multiple events
* with `targetSubscriber` set.
*/
type Fanned<E extends Event> = E & {
// -> This is so that we can mark the `targetSubscriber` property as non-optional
// if it is set.
targetSubscriber: Required<E['targetSubscriber']>
}
/**
* Create a unique event for each subscriber registered for that event.
* Sets `targetSubscriber` on each created event.
*
* Note: Fanout is not performed when using the local queue, subscribers are immediately called with the original event.
*
* @param event The event to fan out.
* @returns The array of newly created events to enqueue.
*/
function fanoutEvent<E extends Event>(event: E): Fanned<E>[] {
const subscribers = eventMap[event.key]
return subscribers
.map(subscriber => {
const clone = cloneDeep(event)
clone.targetSubscriber = subscriber.name
return clone as Fanned<E>
})
.filter(Boolean) as Fanned<E>[]
}
Now let’s update our Subscriber type to move the idempotent functionality to it instead.
/**
* A subscriber to an event.
* Note that events are 'fanned out' on a 1:1 basis of subscribers.
* This means that for each subscriber, there is a distinct event created in the system, guaranteeing a 1:1 relationship between event and subscriber.
*/
export interface Subscriber<E extends Event, R = void> {
/**
* If this subscriber action is idempotent or not.
* > Idempotent: If the action can be repeated without changing the result.
*/
// -> `unknown` allows us to migrate events to this system without
// digging too hard to find out if they're idempotent or not,
// which would require a senior engineer in many cases.
idempotent: 'yes' | 'no' | 'unknown';
/**
* A name for the subscriber.
* This should be unique within the context of the event this subscriber subscribes to.
*/
// -> Having a name for the subscriber is needed so we can identify them later.
name: string;
/**
* A description of what this subscriber does.
*/
// -> Since we have a description for events, let's do it for subscribers!
description: string;
/**
* Execute the subscriber work.
* @param event The event to process.
* @returns A promise that resolves when the work is complete.
*/
callback: (event: E) => Promise<R>;
}
Final Implementation
The final implementation has quite a bit more code to glue bullmq together, do local mode fallbacks, etc.
I’ve left it out of this article to keep it simple.
Queue Backend
As we already discussed, we’re using bullmq, which uses Redis as a backing store for the queue.
However, there are some details worth mentioning that we encountered, so I’ll briefly mention them.
Redis is not persistent
This is a fairly obvious statement, but if Redis goes down, or we have to update it, reboot it, etc, we lose all the events in the queue.
This isn’t really acceptable for us, so we ended up using AWS MemoryDB, which is a resilient drop-in replacement for Redis.
BullMQ needs a specific Redis configuration
There are some specific Redis configuration settings that BullMQ needs, specifically, [maxmemory-policy must be set to noeviction.](https://docs.bullmq.io/guide/connections)
Observability
Given we’re building core infrastructure here, making this whole thing observable is very important.
By Observable, we mean we can monitor the system, check how it’s performing, and catch any problems with it quickly.
For us, that means DataDog, where we do all our observability and monitoring.
Before we get into the solution however, let’s decide what we want to monitor, and to do that, let’s imagine some failure cases that could happen.
- The
jobs-workerinstances cannot process events quick enough, and we have a backpressure problem. - There are any errors while processing events, either in the queue code or the subscribers themselves.
- No events are being queued.
- No events are being processed by workers.
- Redis is out of memory and cannot store any more events.
These are high level failure cases and not exhaustive, but they give us a good starting point, let’s map them to observability methods.
| Failure | Observable By |
|---|---|
| Backpressure | Number of jobs ‘waiting’ is increasing only. |
| Errors | Error logs and metrics. |
| No events queued. | Number of jobs ‘completed’. |
| No events processed. | Number of jobs ‘queued’. |
| Redis can’t store events. | Redis available resources. |
These are all quite easy to solve using bull-monitor.
bull-monitor
bull-monitor is a package that provides a dashboard for debugging events and monitoring a bullmq instance by monitoring Redis.
It also has, quite usefully for us, exposes Prometheus metrics using a conventional HTTP API endpoint.
| Metric | type | description |
|---|---|---|
| jobs_completed_total | gauge | Total number of completed jobs |
| jobs_failed_total | gauge | Total number of failed jobs |
| jobs_delayed_total | gauge | Total number of delayed jobs |
| jobs_active_total | gauge | Total number of active jobs |
| jobs_waiting_total | gauge | Total number of waiting jobs |
| jobs_active | counter | Jobs active |
| jobs_waiting | counter | Jobs waiting |
| jobs_stalled | counter | Jobs stalled |
| jobs_failed | counter | Jobs failed |
| jobs_completed | counter | Jobs completed |
| jobs_delayed | counter | Jobs delayed |
| job_duration | summary | Processing time for completed/failed jobs |
| job_wait_duration | summary | Durating spent waiting for job to start |
| job_attempts | summary | Number of attempts made before job completed/failed |
This will cover a lot of our observability requirements.
DataDog ****has functionality to collect Prometheus metrics, so let’s use that.
Here’s an extract of our container labels, because it took us a while to find out the correct way to define these and get it working:
const dockerLabels = {
'com.datadoghq.tags.env': isProd ? 'production' : 'staging',
'com.datadoghq.tags.service': 'bull-monitor',
// Exposes the /metrics endpoint for discovery by the datadog-agent.
// @see https://docs.datadoghq.com/containers/docker/prometheus/?tab=standard
'com.datadoghq.ad.check_names': ['openmetrics'],
'com.datadoghq.ad.init_configs': [{}],
'com.datadoghq.ad.instances': [
{
openmetrics_endpoint: 'http://localhost:3000/metrics',
namespace: 'bull',
metrics: ['jobs_*'],
},
],
}
Note: We’re using CDK-TF to define our infrastructure in TypeScript, the above is an extract only.
After getting this up and running, dd-agent is now collecting our bull-monitor metrics and reporting them.
Let’s build a Dashboard.
DataDog Dashboard
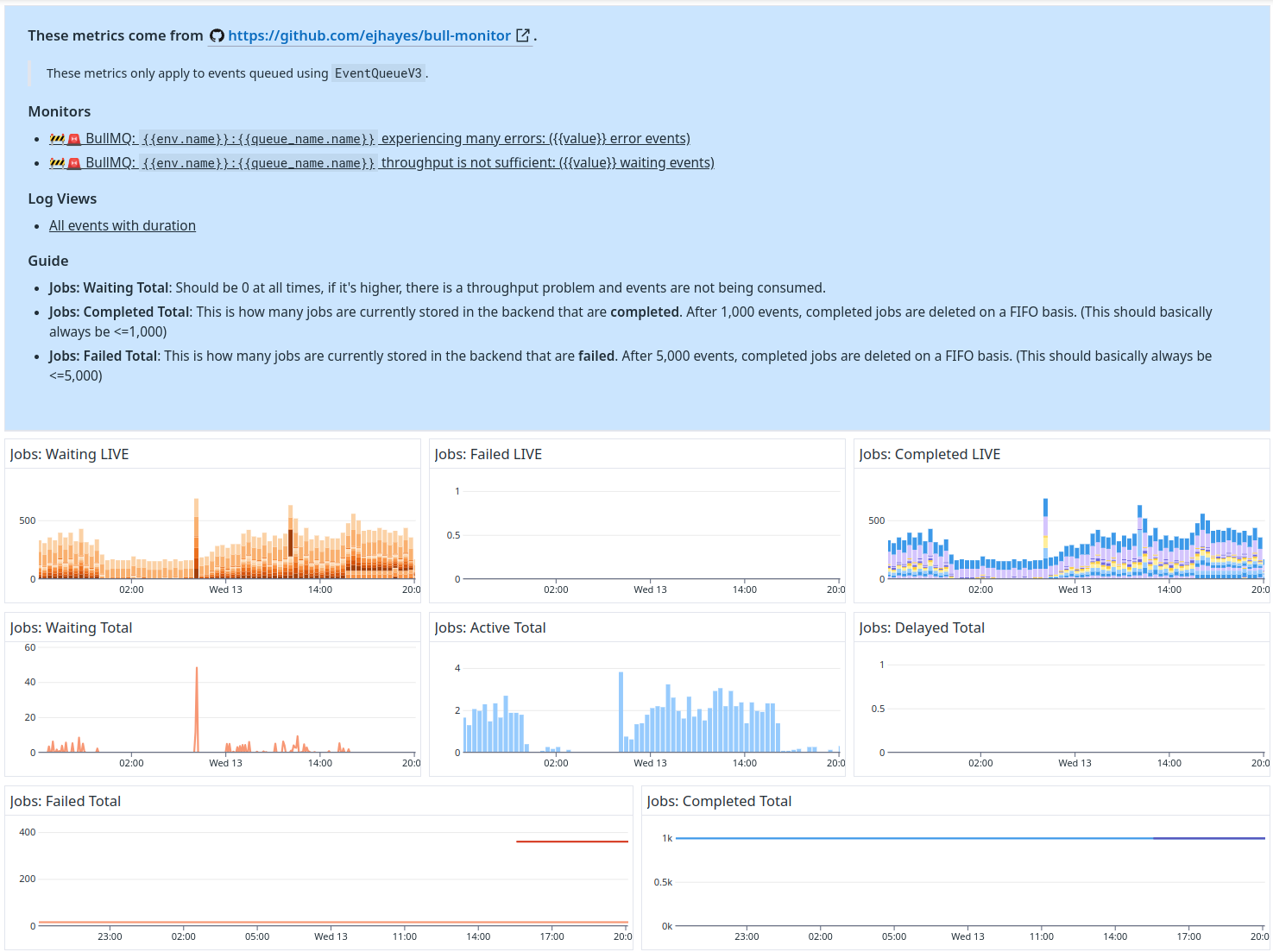
Let’s talk about our Dashboard a bit, how it’s structured, and why.
Documentation
All of our Dashboards have documentation which tells you how to use them.
This is critical, because dashboards are usually used by oncall members who may not be familiar with them yet.
We make sure to detail:
- What this Dashboard is.
- Link any related monitors and log views.
- Explain how to interpret the graphs and what normal values should be.
Graphs
- Graphs should be colored appropriately (use red for errors and ‘bad’ things, blue for neutral, green for ‘good’).
- Graphs are laid out in a logical manner in rows that group related things together.
- Graphs use ‘group by’ to show additional information (our jobs waiting/completed are grouped by job type).
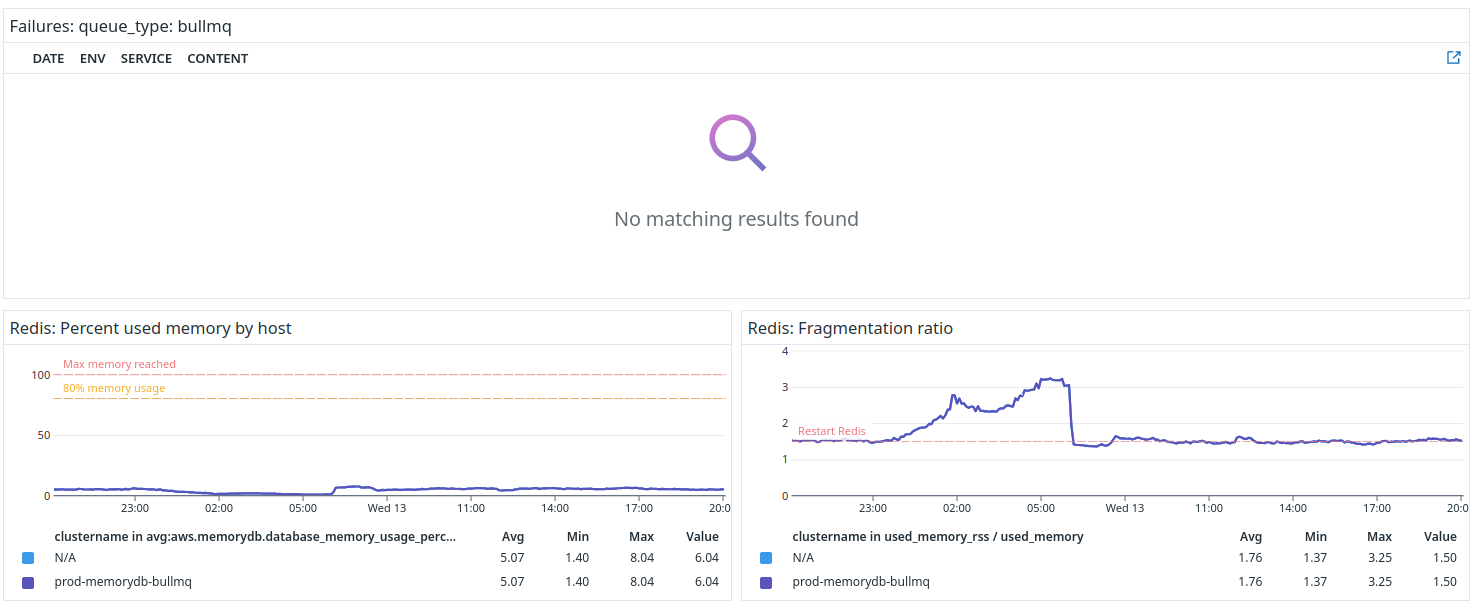
Log View
Our Dashboards often include an embedded log view showing the most important logs.
In this case, it’s any error logs relating to bullmq.
Conclusion
In this article, we’ve:
- Shown how we evolved the bones of an interface for an event system in TypeScript.
- Discussed
bullmqand our backing store a bit. - Demonstrated how to observe the event system in DataDog.
Some aspects we didn’t have time to go into:
- Our
sendEventfunction and its types and how it makes everything easy to use. - The internals of our
EventQueueclass, which handles dispatch and processing of events, and the plumbing for connecting tobullmq. - How we re-construct events from JSON data stored in
bullmq.