株式会社バンダイナムコ研究所のlaiです。先月の言語処理学会年次大会のワークショップとして開催されていた、「AI王 〜クイズAI日本一決定戦〜」に参加しました。本記事で私の取り組みの共有と振り返りをしたいと思います。
コンペ概要

日本語クイズを題材とした質問応答データセットJAQKET[鈴木ら 2020]を用いて、開発したAIシステムの正答率を競うライブコンペティションです。
事前に配布された1000問を解いた結果がリーダーボードに表示されますが、
ライブコンペ当日では新たに未公開のクイズ1000問が配布され、
事前構築したシステムを用いて制限時間内で解いた結果で競います。
コンペ結果
ライブコンペでは1000問中925問正解で11チーム中1位を取れました。NLP分野での初優勝となりますので本当にうれしいです。

データ
配布データ
- 訓練データ: 13061問
- 開発用データ1: 995問
- 開発用データ2: 997問
- 評価データ(リーダーボード):1000問
- 正解エンティティ候補リスト: 約92万件(訓練データ・開発データ・評価データ(未公開)のすべての問題において、この候補リストのいずれかが正解になります)
- 日本語Wikipedia記事の本文をまとめたデータ
クイズ問題は以下のように配布されます:
{
"qid": "QA20QBIK-0002",
"question": "童謡『たなばたさま』の歌詞で、「さらさら」と歌われる植物は何の葉?",
"answer_entity": "ササ",
"answer_candidates": [
"ササ", "ススキ", "ミヤマキンバイ", "リョウブ", "タムシバ",
"ミツガシワ", "ハクサンフウロ", "ウラジロナナカマド",
"イタヤカエデ", "チシマザサ", "タテヤマウツボグサ",
"トウゴクミツバツツジ", "ミズメ", "イワイチョウ",
"ネズミモチ", "ヤシオツツジ", "ショウジョウバカマ",
"ムラサキヤシオツツジ", "ヤクシマシャクナゲ", "クマザサ"
],
"original_question": "童謡『たなばたさま』の歌詞で、「さらさら」と歌われる植物は何の葉?"
}
1問に対して20件の選択肢が与え、その中から正解となる1つを選んで"answer_entity"に記入する形式となります。
ちなみに、配布データセットではベンチマークを容易にするために、答えが必ずWikipedia記事名(によって指される実世界の実体)に正規化されています。
その他利用可能なデータ
利用可能なデータは一般公開されているもののみとしますが、独自に作成したデータであっても、無償で一般公開すれば利用可能となります。
他の組織でも結果を再現できるかというのが一つの目安となります。当然ながら解答時に外部のリソース(インターネット検索など)を利用するのは禁止です。
解法
方針
このコンペが最初に公開された頃(2020年4月)には
最終報告会当日のテストデータ公開後、規定時間(30分を予定)以内に解答が投稿されなければ時間切れと判定します。
というルールがあったため、手持ちのリソースで30分以内でアンサンブルするのが厳しかったので、
最初から推論速度重視のシングルモデルという方針で決めました。
(その後3時間に延長するアナウンスがありましたが、ちょうどいろいろ忙しい時期でしたので気付いた時はもう手遅れでした。)
モデル
使用したモデルはDense Passage Retriever (DPR) [Vladimir Karpukhin+ 2020]です。
去年FacebookAIが発表しオープンドメイン質問応答に関する手法で、
元論文のリンクはこちらです:https://www.aclweb.org/anthology/2020.emnlp-main.550/
実は去年12月まで運営が公開したBERTのNextSentencePredictionの解法を使っていましたが、
NeurIPS 2020のEfficient QAコンペの上位チームがほとんどDPRを採用していたことを見て、
自分もモチベーションを持ち始めてこちらで実装しました。
システム構成は以下になります:
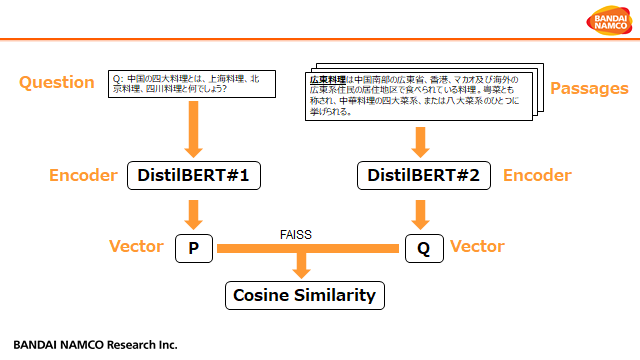
元論文を踏襲したポイント
- 質問文(クイズ)と資料文(Wikipedia記事)を2つの事前学習済み言語モデルを用いてベクトル表現にエンコードする
- 質問文に対して、正解選択肢の資料文を正例、それ以外を負例とする
- 訓練では質問文ベクトルと資料文ベクトルの内積を使ったCrossEntropy損失を用いる
- 推論では資料文(Wikipedia記事)を予めベクトルに変換し、質問文のベクトルをクエリとした近傍探索として解く
- 基本実装はHuggingfaceのTransformersライブラリを参考(https://huggingface.co/transformers/model_doc/dpr.html)
- 大規模の高速ベクトル近似度計算はFaissライブラリを使用(https://github.com/facebookresearch/faiss)
元論文から変更したポイント
- エンコーダについて元論文ではBERTを使用しているが、推論速度重視のためFine-tuningしたDistilBERTを使用(https://github.com/BandaiNamcoResearchInc/DistilBERT-base-jp)
- 運営ベースラインである東北大学が公開したBERTとNICTが公開したBERTでベンチマークを行いましたが、結論として次元数が同じ場合での性能差が見られなかった
- 元論文ではBERTの[CLS]トークンを文章のベクトル表現を使用しているが、Reimersらの論文を参考にし各トークンベクトルの平均に変更
- PointerNetworkで抽出したキーワードを質問文と連結して入力
- 最大入力系列長(256)を上回ったWikipedia記事文に対して、テンセントAIチームが提案したスライドウィンドウの手法を用いて複数シーケンスの内容を結合
- 出力は最終層ではなく各隠れ層のWeighted Sumに変更
- 元論文では負例作成のため様々な手法を提案しているが、今回は正解以外の選択肢がそのまま負例として利用できるためかなり省略できた
追加訓練データ
開発データ1&2
一時期使用不可ですが最終的に使用可能になりました。
自作クイズデータ
配布されたWikipedia記事データを使用して、構文解析と固有表現抽出を用いて自作クイズ集を作成しました。
[解答可能性付き読解データセット] (http://www.cl.ecei.tohoku.ac.jp/rcqa/)
こちらのデータセットでは正解以外の候補が用意されていなかったため、コサイン類似度の高い同義語でダミー選択肢を作成しました。
前処理
事前学習モデルのボキャブラリーに含まれない難読漢字は[UNK]として入力されるため、入力問題は正規化前の"original_question"を使用
例:以下の問題では「霹靂」がDistilBERTのvocabに含まれないため、「へきれき」が併記される正規化前の質問を使用します。
{"question": "思いがけない突発的な事柄をいう「青天の霹靂」、さてこの「霹靂」とはどんな自然現象のことでしょう?",
"answer_entity": "雷",
"answer_candidates": ["雷", "風塵", "積乱雲", "雹", "氷雨", "風雨", "砂嵐", "快晴", "海鳴り", "雨", "雪", "驟雪", "細氷", "凍雨", "霧", "乱層雲", "熱雷", "吹雪", "風", "嵐"],
"original_question": "思いがけない突発的な事柄をいう「青天の霹靂(せいてんのへきれき)」、さてこの「霹靂」とはどんな自然現象のことでしょう?"}
解答に特定の文字列や条件を指定した問題に関して、条件を満足しない選択肢を排除する
例:以下の問題では「村」を含まない選択肢を候補から外します。
{"question": "1957年8月に日本で初めて「原子の火」がともった、日本原子力研究所がある茨城県の村はどこでしょう?",
"answer_entity": "東海村",
"answer_candidates": ["東海村", "大洗町", "龍ケ崎市", "土浦市", "北茨城市", "筑西市", "日立市", "鹿嶋市", "行方市", "鉾田市", "下妻市", "那珂市", "潮来市",
"かすみがうら市", "水戸市", "ひたちなか市", "笠間市", "神栖市", "高萩市", "石岡市"],
"original_question": "1957年8月に日本で初めて「原子の火」がともった、日本原子力研究所がある茨城県の村はどこでしょう?"}
例:以下の問題では3文字以外の選択肢を候補から外します。
{"question": "地位や身分の上下を気にせずに楽しむ宴会のことを、漢字三文字で何というでしょう?"
"answer_entity": "無礼講"
"answer_candidates": ["善知識", "永宣旨", "一献", "退院", "挙哀", "朝覲", "門徒物知らず", "無礼講", "策命", "直廬", "大歌", "遥拝勤行", "枕経", "束脩", "年男", "矢開き", "解除 (行事)", "奏事不実", "三証", "随方毘尼"],
"original_question": "地位や身分の上下を気にせずに楽しむ宴会のことを、漢字三文字で何というでしょう?"}
「どっち」系の質問に対して質問文に含まれない選択肢を排除し、それ以外は質問文に含まれる選択肢を排除する
例:以下の「どっち」系問題では正解が「黄河」と「揚子江」しかありえないため、それ以外の選択肢を候補から外します。
{"question": "中国大陸を流れる黄河と揚子江のうち、より北にあるのはどっちでしょう?",
"answer_entity": "黄河",
"answer_candidates": ["黄河", "汾河", "大凌河", "洛河", "泗河", "赤水河", "鬱江", "青弋江", "桑乾河", "ショウ河", "衛河", "シラムレン川", "コ沱河", "淮河", "漢江 (中国)", "ラン河", "長江", "湘江", "済水", "渭水"],
"original_question": "中国大陸を流れる黄河と揚子江のうち、より北にあるのはどっちでしょう?"}
例:以下の問題の質問に含まれる「皐月賞」や「菊花賞」は明らかに正解ではありませんが、候補選択肢に含まれるため、近似度計算の際では引っかかりやすいので外します。
{"question": "別名を「日本ダービー」という、皐月賞・菊花賞とともに中央競馬クラシック三冠を構成する重賞競走は何でしょう?",
"answer_entity": "東京優駿",
"answer_candidates": ["朝日杯フューチュリティステークス", "安田記念", "宝塚記念", "京都新聞杯", "天皇賞", "阪神大賞典", "スプリングステークス", "弥生賞", "優駿牝馬", "東京優駿", "大阪杯", "有馬記念", "スプリンターズステークス", "毎日王冠", "阪神ジュベナイルフィリーズ", "エリザベス女王杯", "マイルチャンピオンシップ", "皐月賞", "桜花賞", "菊花賞"],
"original_question": "別名を「日本ダービー」という、皐月賞・菊花賞とともに中央競馬クラシック三冠を構成する重賞競走は何でしょう?"}
「ですが」系質問は「、」で区切って「ですが」に含まれるノイズにあたる部分を排除する
例:以下の問題で「「性善説」を唱えたのは孟子ですが」はノイズに当たるため、質問文のこの部分を除去してから入力します。
{"question": "中国の思想家で、「性善説」を唱えたのは孟子ですが、「性悪説」を唱えたのは誰でしょう?",
"answer_entity": "荀子",
"answer_candidates": ["子思", "何休", "王弼 (三国)", "服虔", "曾子", "王充", "劉向", "孔子", "楊朱", "揚雄", "朱熹", "墨子", "荀子", "韓非", "鄭玄", "孟子", "王念孫", "老子", "荘子", "謝良佐"],
"original_question": "中国の思想家で、「性善説」を唱えたのは孟子ですが、「性悪説」を唱えたのは誰でしょう?"}
おわりに
- リーダーボードの上位チームのスコアが0.95以上に対して、自分では僅か0.928で正直優勝を諦めかけていましたが、ライブコンペでも同じ0.92台のスコアを取れて良かったです。
- 他の上位チームの方が公開した解法を見て前処理の重要性を再確認できました。「NLPは機械学習と言語学の総合格闘技」であることを改めて感じました。
- 言葉遊び系の問題は最後まで解けませんでしたが、逆にどんな手法なら解けるかをとても気になりました。
- NLPコンペのデータセットにノイズが混ざっていることもあり、参加するには苦労することが多いですが、今回は高品質のデータセットのおかげで最後まで楽しむことができました。JAQKETデータセットを作成いただいた運営とのコンペを盛り上がっていただいた日本語NLPコミュニティの皆様に大変感謝します。