TL;DR
NewRelic を導入することで、食べログのKubernetes移行でエンジニアが本質的な課題に取り組める時間を創出することができました。OSSで構成すればタダに思えますが、構築の手間はエンジニアの時間という形でコストになってしまうので、金銭的費用以上の価値をNewRelicから感じました、というお話です。
導入の経緯と効果
クラスタ可視化領域で発生した課題
食べログでは2020年からKubernetesへの移行に取り組んできました。2021年からようやく本腰を入れて取り組みができるようになり、いくつかの本番サービスを移行したのですが、Prometheus/Grafana を使ったクラスタ可視化の領域で、以下のような課題がありました。
- 複数のデータソースが存在し、ダッシュボードの管理が煩雑化
- Grafanaダッシュボードの作成が職人芸化
これらの複雑性は、アプリケーションをKubernetes の Manifest として書き起こす際にも、
- Manifest の記述が大変
- 動作確認にも手間がかかる
などの問題を引き起こしていました。
NewRelic を使うことのメリット
それに対して NewRelic では以下のようなメリットがありました。
- すでにあるプラクティスを導入することで、自前でゼロから考えるよりも、Kubernetesクラスタを可視化する手間を削減できる
- 導入が容易。Kubernetesインテグレーションを使うことで、数ステップで導入できる
- Prometheusよりも多くの情報が収集される(Deployment名などの情報を自動付与してくれる)
導入効果
Kuberntestクラスタの可視化にかかる手間を削減することができた
インフラ構成のシンプル化
それまで使用していたThanosと比べると、インフラ構成がシンプルになりました
Thanos 構成
Thanos では SideCar や、直近のデータを参照するための Query の運用をする必要があり、Manifest の記述や動作確認の手間などがありました。
また、保存先のGCS料金もかかるため、OSSで構築することのコスト的なメリットも薄れつつありました。
NewRelic 連携構成

NewRelic では Kuberntest のクラスタ情報を集めるのは Kubernetesインテグレーション を Manifest として設定するだけでOKです。
それ以外の独自メトリクスについては、Prometheus remote write integration という機能を使って、もともと動かしていたPrometheus から remote_write するだけで NewRelic に取り込めるので、移行の手間はほとんどかかりませんでした。
Prometheus の設定ファイルに remote_write のための数行を付け加えるだけで、NewRelic にデータを送ることができます。
remote_write:
- url: https://metric-api.newrelic.com/prometheus/v1/write?prometheus_server=my-cluster
authorization:
credentials_file: /etc/newrelic-secrets/NRIA_LICENSE_KEY
# 別途 Secret などのマウントも必要です
Kubernetes マニフェストのシンプル化
インフラ構成がシンプルになることで、Manifestの記述量を減らすこともできましたし、それに伴って動作確認の対象も少なくなりました。
ダッシュボード作成の手間を軽減
Grafana は とても優秀な 可視化のOSSですが、動的フィルターの設定をするためには↓の$host ようにPromQLに変数を指定しなくてはなりません。この設定をちゃんと動かすようにするために、他のグラフと整合を取ったりする必要があり、条件を増やす際にも全てのグラフのPromQLを変更しなくてはいけないなど、考慮事項がとても多く、ダッシュボードの作成が職人芸化している状況でしたが、
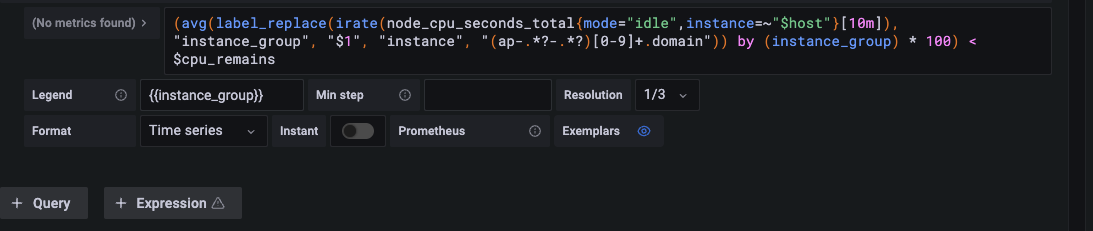
NewRelic では 基本的なグラフを書いておき、あとの条件の設定はダイアログから全てのグラフに適用できます。
このフィルター機能のおかげで、ダッシュボードの手間削減だけでなく、さまざまな切り口でクラスタを可視化することが可能になりました(Kibanaに近い操作性)。
NewRelic 運用を効率化するための工夫
Terraform による 設定のコード化
New Relic Provider を使うと、Terraform で NewRelic の アラート、ダッシュボード、Synthetics などの設定を管理することができるようになります。
設定ファイルをエディタで一気に修正することができるので、設定管理の効率化が可能でした。
これができないと、設定の変更対象が多い時の作業工数が半端じゃないので(画面見ながらひとつひとつポチポチしなくてはいけない)、Terraform が NewRelic に対応してるのは嬉しい特徴のひとつです。
ただ、NewRelic と Terraform の両方の学習コストがかかるので、慣れるまでが少し大変ですが、ある程度作ってしまえばあとは倣って設定を増やしていくだけなので、学習コストはすぐに回収できると思います。
(アラート2〜3個も設定すれば実感できると思います)
ダッシュボードURLの解析による リンク集の作成
NewRelic の ダッシュボード に使われているURLには、実は Base64 デコードできるパラメータが含まれており、これをいじることで任意の検索フィルターを初期表示させることができます。
https://one.newrelic.com/.....&pane=eyJuZXJkbGV0SWQiOiJk
↑ダッシュボードの pane パラメータの部分
食べログではこの仕様を使って、事前にさまざまな切り口でダッシュボードリンクを用意しておくことで、システム情報へのアクセス性を高める工夫をしています。
DROPルールの適用による運用費の最適化
NewRelic には drop filter rules という機能があり、NewRelicに送られてきたメトリクスから、不要なものを除外することができます。本来であれば送信側のPrometheus で不要なものを転送除外しないといけないのですが、Prometheus 側で relabel_configs を書くと、configファイルが読みづらくなってしまうので、NewRelic側に DROPルールの機能があることはユーザに優しく、とても素晴らしいと思います。
ただ、NewRelic 側であまり多くのDROPルールを設定すると、情報の反映速度に影響する可能性があるそうなので、不要なものはなるべく送らないようにするのが良さそうです。
いま取り組んでいること
Kubernetes 以外の メトリクスの運用
MySQLなどのデータストア
- スロークエリ
- レプリケーション遅延
- Performance Schema
などの情報を取り込むことによって、
データベース目線での改善にも取り組むことができるようになると期待しています。
NewRelic Alertの運用 & Opsgenie との連携
みなさんはアラートをどのように受け取っていますか?
メールでしょうか?Slackなどでしょうか?
メール通知のデメリット
①受け取ったアラートの状況が分からない
- この問題は今も継続しているのか?
- 誰か対応を開始しているのか?
②同じアラートが複数回来ると、他の情報が埋もれてしまう
- 大量のCPUアラートに埋もれて、ディスク枯渇を見落としてしまった
などのデメリットがあり
- 同じことを複数のエンジニアがやってしまった
- そもそも対応を忘れてしまう
などの問題につながることがあります。
これを NewRelic と Opsgenie を使うことによって、
- Policyベースでのアラートの集約
- 受け取る通知数を種類ごとに限定できる
- アラートの自動クローズ
ができるようになり、緊急のアラート以外は毎朝のミーティングで確認すれば良いようになりました。
(Slack などでもアラート対応の状況可視化はできると思います)
NewRelic つらいとこ
NRQLの集計に若干のクセがある
NewRelicは 複数のデータソースを扱うことを前提に作られているため、メトリクスによっては重複して集計されてしまうことがあるようです。正確な値を知ることが難しいケースがいくつかありました(そのような場合でも傾向の把握はできますし、取り方を工夫すれば正確な値を参照することもできるかもしれませんが、それはまた後日に)。
今後やりたいこと
デプロイマーカーの運用
エラーの発生やパフォーマンスの低下などは、デプロイを起因として起きることが多いです。デプロイマーカーを使ってデプロイのタイミングと一緒にモニタリングすることで、どのデプロイが起因となって問題が起きたのかが分かることにようになり、問題を起こしたロジックを早期に特定し、改善することができるようになりそうです。
Synthetics
サービス監視における SLI/SLO の可視化
現在食べログでは nagios による死活監視を行っていますが、NewRelic Synthetics を使うことで、レイテンシやエラーレートも時系列で見られるようになります。SLOの状況を長期間で振り返ってみることもできますし、Terraform と組み合わせることで、より多くのエンドポイントをモニタリングし、サービスの可用性をさらに観測できるようになりそうです。
NewRelic Minion を活用した内部インフラの観測
内部APIなどの外部に公開していないバックエンドサービスでも、個別にサービスレベルが低下していないかをモニタリングし、改善することによって、全体的なサービスのレベルも向上させられそうです。
APMによるパフォーマンス改善活動の実施
食べログは月間 13億PVにもなる高トラフィックなサービスです。そのため、アクセスの多いページを少しパフォーマンス改善するだけでも大きな改善効果が期待できます。APMは今となっては特別なものではないので、食べログでも導入を進めて、サービスのパフォーマンスを改善していきたいと考えています。
ただ、APMはデータがすぐに肥大化するので、OSSだと運用難易度が高いですし、SaaSでは料金がネックになりがちなので、これらの課題をうまく解決していく必要がありそうです。
まとめ
TL;DR 書いてからのさらにまとめですが、NewRelic は SaaS 本体だけでなく、Terraform などの周辺ツールも非常に充実しています。使いこなしていくのはなかなか大変ですし、料金も決して安いとは言えないですが、ちゃんと目的・目標を持って運用すれば、できることはたくさんあるし、効果的なツールだと思いました。
最後に
SREチームではエンジニアを募集しています! インフラやDevOpsの経験がない方でも、ソフトウェアエンジニアなら活躍できる環境です。
Cloud Nativeな領域でできることはまだまだたくさん残されているので、ご興味のある方はぜひご応募お願いします。
もちろん、まずはカジュアル面談で情報交換をしてみたいという方も大歓迎です。その場合はご応募いただくときに、フリーテキスト記入欄に「カジュアル面談希望」とご記載くださいね。
明日は@tsukasa_oishiの「食べログのCloud NativeなCI/CDパイプラインのお話」です。お楽しみに!