1. はじめに
1.1. 機械学習と材料設計
材料特性は、相の種類や体積分率、粒径、分布、界面、転位、積層欠陥...などの様々な因子が複雑に絡みあって発現します。トレードオフの関係にある材料特性を両立させなければならないケースも多く、従来の材料開発では、非常に高度な知識や経験が必要になります。近年では機械学習を活用し、短い開発期間でより優れた材料の開発が期待されています。
1.2. 鋼の組織と特性
添加元素の種類や製造プロセスによって、鋼は高機械強度や耐食性などの多彩な特性を持ちます。このような鋼の特性は組織によって特徴づけられており、フェライト組織やマルテンサイト組織などがあります。
今回は鋼組織の走査型電子顕微鏡(SEM)像から得た構造の特徴と室温引張特性の関係を可視化したこちらの文献 [1]を参考に、ニューラルネットワークを使って、鋼の組織と特性の関係を調べてみます。
2. 畳み込みオートエンコーダ
オートエンコーダ(Auto Encoder, AE)とは、ニューラルネットワークを利用した教師なし機械学習の手法の一つです。入力データの次元を下げて、再び入力データを復元するような構造になっています。次元削減や特徴抽出として使われることが多いです。
畳み込み層により画像の持つ特徴をうまく扱えるようにしたのが畳み込みオートエンコーダ(Convolutional Auto Encoder, CAE)です。
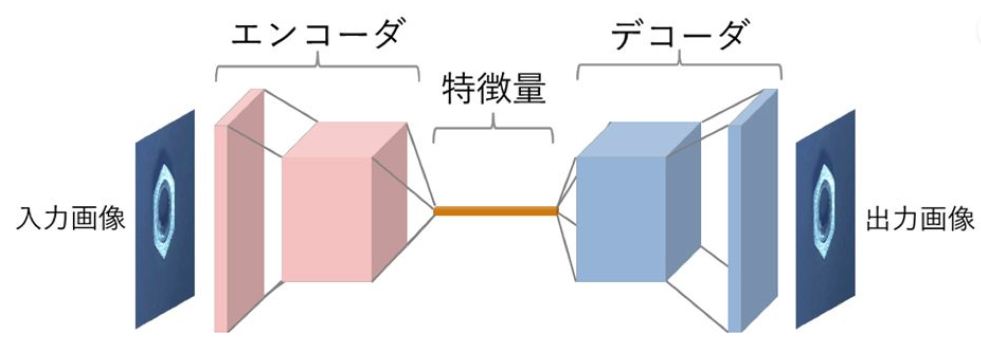
CAEの模式図、MathWorks『オートエンコーダ(自己符号化器)とは』より
AEに限らず、ディープラーニングにおいて、アーキテクチャの設計は入力データの特性を考慮します。例えばConv2D層のみの場合と、Conv2D層とpooling層と組み合わせた場合でどちらが性能が良いかは(多分)自明ではないと思います。次のような観点から考えてみます。
- pooling層は入力の空間次元を小さくするため、パラメータと計算の量を減らし、オーバーフィッティングを防ぐのに役立つ
- pooling層はローカルな特徴をよりグローバルなレベルに集約できる
- 反対に、詳細な情報を必要とするタスクを扱う場合、プーリング操作によって重要な情報が失われる可能性がある
- シーンの理解やセマンティック・セグメンテーションなど、グローバルなコンテキストの理解が必要な問題には、pooling層を入れた方が良いかも
- テクスチャ分類のような局所的な特徴に依存する問題では、局所的な情報を保持するためにpooling層はあまり使わない方がいいかも
今回はグローバルな特徴ではなく局所的な情報を保持したいので、pooling層を使わない方が良さそうな気がします。
また、元論文ではVariational Auto Encoder(VAE)を使っていますが、今回のタスクでは潜在空間からデータを生成しないので、AEを使います。
3. データセット
データはこちらにあったものを使います。
データセットは次のようなファイルで構成されています。
- 11種のHR鋼、18種のCRJ鋼、4種のP92合金の電子顕微鏡像
- 合金組成と機械特性がまとめられたcsv


4. 機械学習
4.1. 前処理
各合金の画像(630x592)からランダムに10か所、128x128のサイズを切り出します。その後cv2.equalizeHistでコントラストを調整しました。
import os
import cv2
import glob
import numpy as np
path = "path/to/img"
# 切り出しサイズ
crop_size = (128, 128)
# 鋼の種類 取得
alloys = os.listdir(f"{path}/")
for i, alloy in enumerate(alloys):
# 条件取得
conditions = os.listdir(f"{path}/{alloy}/")
for j, condition in enumerate(conditions):
os.makedirs(f"{path}/preprocessing/{alloy}/{condition}/", exist_ok=True)
imgs = glob.glob(f"{path}/{alloy}/{condition}/*.bmp")
for k, f in enumerate(imgs):
img = cv2.imread(f,0)
crop = img[21:571, 0:630]
equ = cv2.equalizeHist(crop)
# List to store cropped images
cropped_images = []
for _ in range(10): # ランダムに10箇所切り出し
# ランダムに10個座標を生成
x = np.random.randint(0, equ.shape[1] - crop_size[0]) # Note the order: (rows/height, cols/width)
y = np.random.randint(0, equ.shape[0] - crop_size[1])
# 切り出し
cropped_img = equ[y:y + crop_size[1], x:x + crop_size[0]]
cropped_images.append(cropped_img)
# 保存
for i, cropped_img in enumerate(cropped_images):
cv2.imwrite(f"{path}/preprocessing_eql/{alloy}/{condition}/{str(k).zfill(2)}_{str(i).zfill(3)}.bmp", cropped_img)

切り出した画像の例
4.2. Auto Encoder
Pooling層は使わず、Conv2D層、BatchNormalization層、Dropout層で構成しました。潜在空間の次元は100にしました。カーネルサイズやpooling層、潜在空間の次元を最適化したいので、もう少し調整してみます。
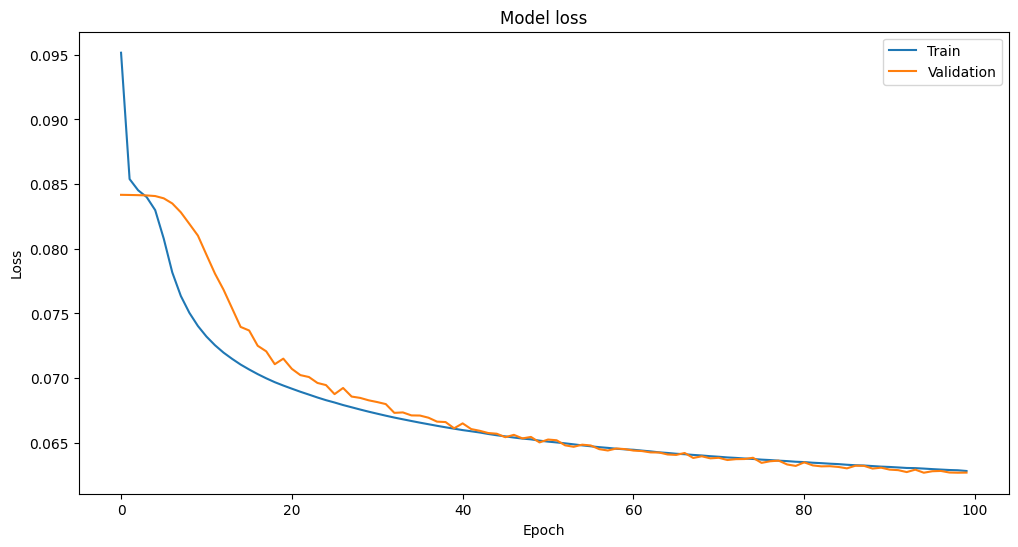
学習の結果です。ある程度は学習できていそうです。
4.3. 潜在変数空間
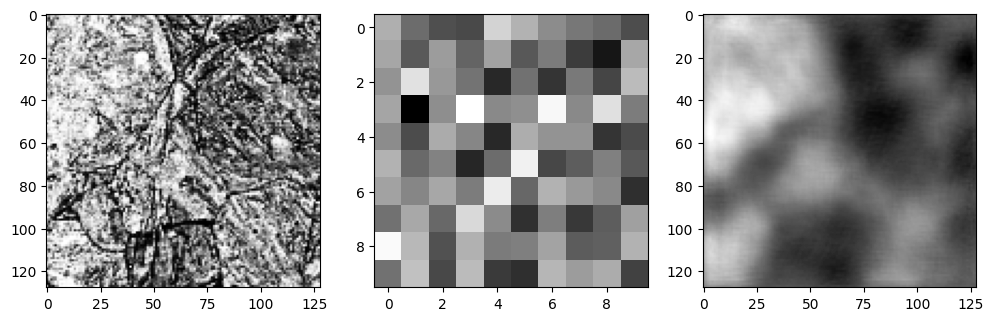
学習に使わなかったテスト画像を使って、エンコーダ/デコーダを確認してみます。
CPJ鋼
HR鋼
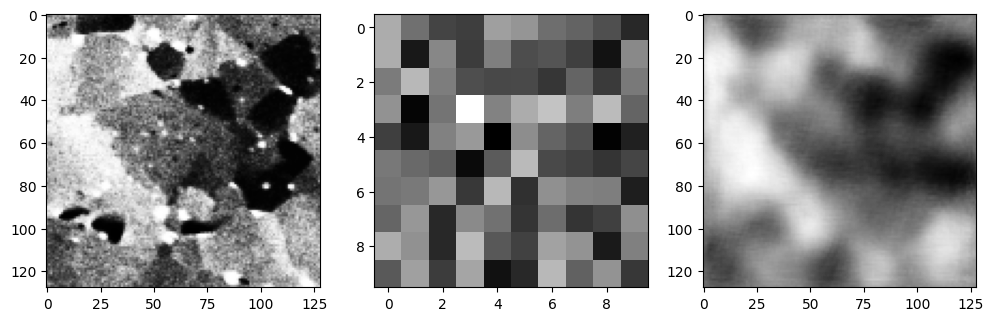
HR鋼の再構成像は比較的、元の画像を復元できているように見えますが、CPJ鋼の微細な組織はあまりうまく再構成できていないようです。やはりネットワークの構造を調整した方がよさそうですね。ひとまずこのまま進めます。
4.4. 構造と機械強度
構造の特徴をある程度保持したまま、100次元の潜在空間に落とし込めました。これを使って構造と特性の関係を確認してみます。100次元のベクトルを主成分分析(Principal Component Analysis, PCA)で2次元まで次元削減します。
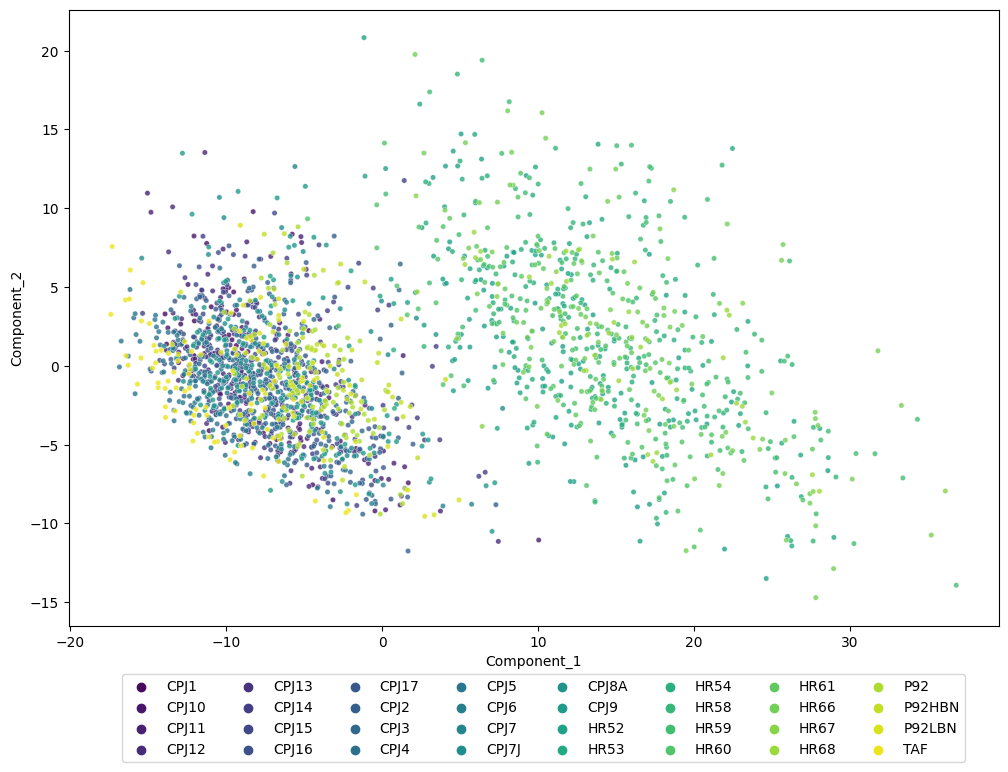
大きく分けて2つのクラスタがあり、左のクラスタにCPJ鋼とP92鋼、右のクラスタにHR鋼が分布していることが確認できます。4.3.で確認したように、復元画像はそれほどの精度ではないものの、微細組織の構造のみで合金をうまく分離できているようです。
機械強度と構造の関係を確認してみます。順に降伏応力 [MPa]、極限引張応力 [MPa]、引張伸び [%]となっています。ただし、機械特性は室温における値を採用しています。
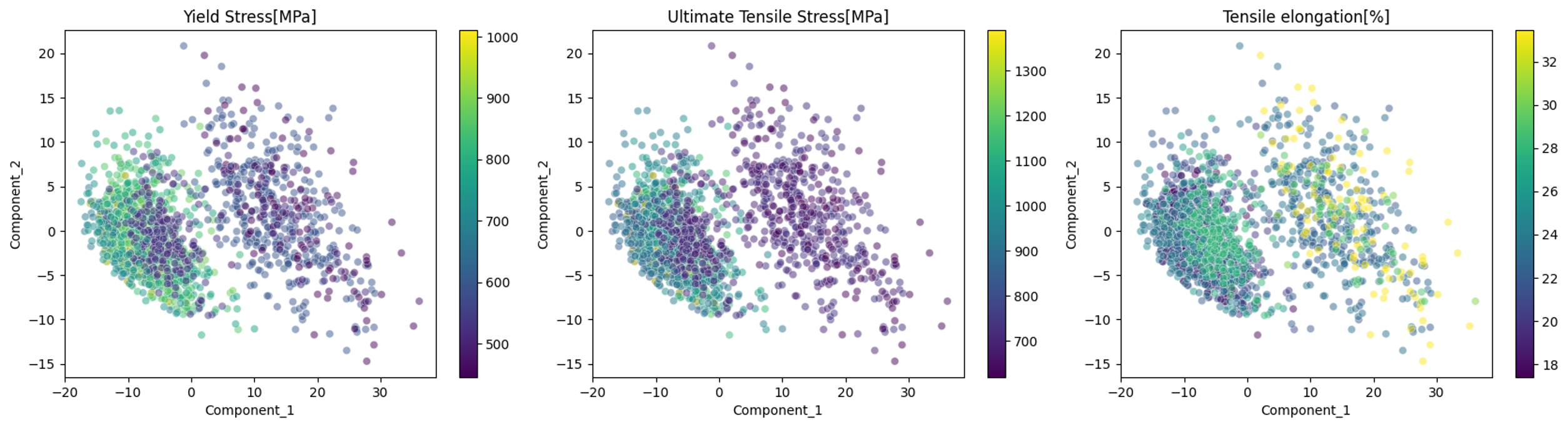
CPJ鋼はHR鋼より降伏応力や引張応力が優れていますが、HR鋼は延性が高いようです。微細組織の構造をある程度ベクトル化できているので、この潜在変数空間で探索を行えば、より機械特性の優れた微細組織を設計することができそうです。VAEを用いれば、より優れた機械特性を持つ微細組織像を生成することも可能です。
4.5. 添加元素の分布
添加元素は、微量でも微細組織と機械的特性に大きな影響を与えることが知られています。いくつかの元素の影響を確認してみます。
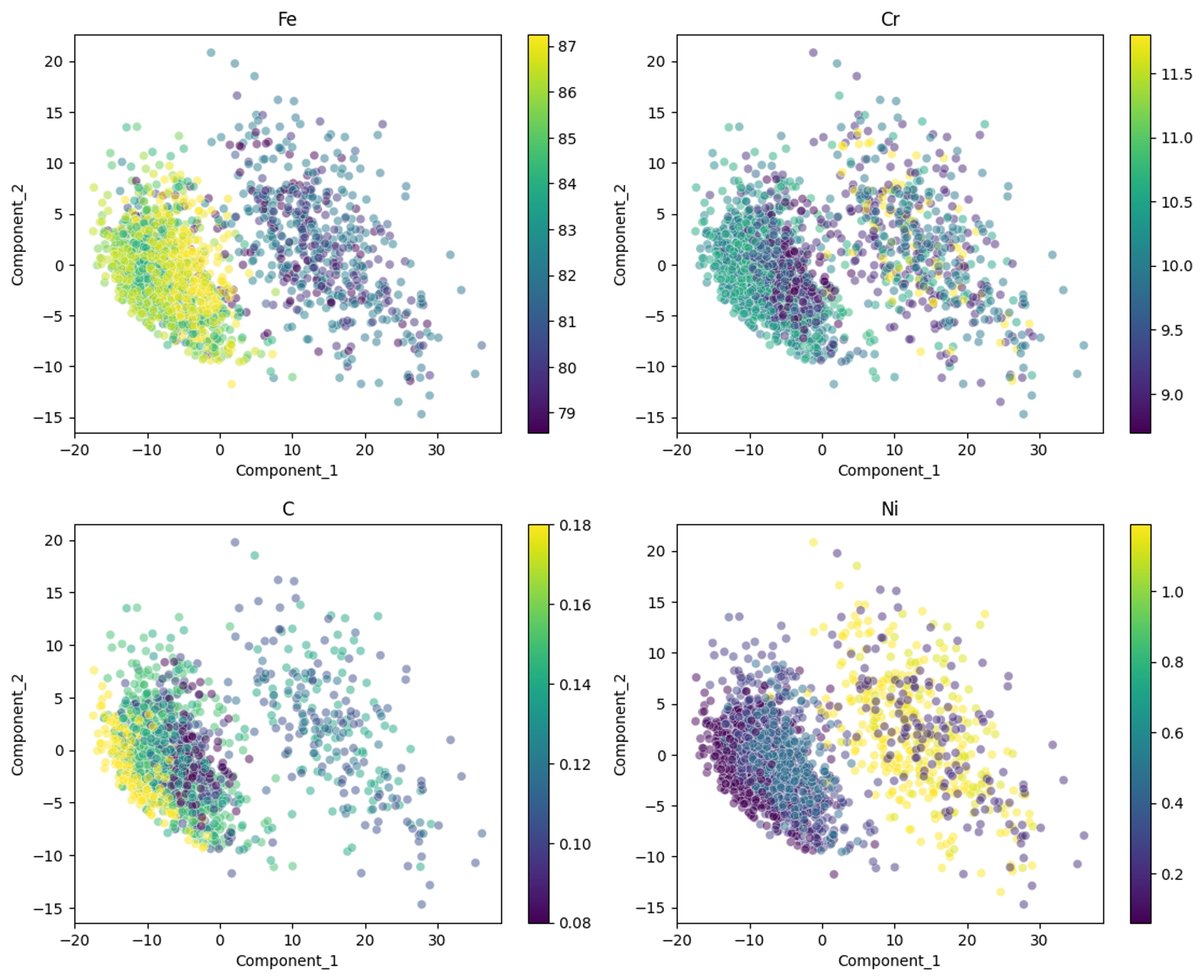
HR鋼はFe濃度が<84wt%であるのに対し、CPJ鋼は比較的Fe濃度が高いです。また、その他の元素についても同様に合金種と微細組織と機械特性の関係を確認することができます。ただし、CPJ鋼はプロットが重なりすぎていて、クラスタ内での分布が確認しにくいです。データを工夫して学習するか、潜在変数と各機械特性で部分的最小二乗回帰(Partial Least Squares Regression, PLS)などをするとよい気がします。
5. まとめ
材料の分野ではミクロな組織や構造がマクロな特性と相関している系が多くあります。今回は9%Cr鋼の微細組織と機械特性の関係をAEを用いて確認しました。
素人ながら、鉄鋼材料は研究されつくされているような印象がありますが、今回のような手法は他の材料においても有用です。本来であれば材料開発には高度な知識や経験が必要ですが、機械学習により効率的な材料設計が可能です。
6. 参考文献
[1] Pei, Zongrui, et al. "Machine‐Learning Microstructure for Inverse Material Design." Advanced Science 8.23 (2021): 2101207.
[2] Rozman, Kyle A., et al. "Dataset for machine learning of microstructures for 9% Cr steels." Data in Brief 45 (2022): 108714.