はじめに
特許はその独特な文体から、私のような一般人には非常に読みにくいものです。
特許の請求項の構造解析などは先行研究が多々ありますが、今回は簡単に特許の調査をPythonでやってみました。
特許情報の取得
J-PlatPatから特許を調べました。今回は
- 出願人に"トヨタ自動車株式会社"を指定し
- 公知日/発行日が2022年1月1日から12月31日の1年間
の特許の情報をcsvで集めました。スクレイピングで取得することは禁じられているので、手動で行いました。
ただし、
- 要約までは取得できるものの、請求項は取得できない
- 取得できる件数が500件まで
であることに留意してください。

日付指定とcsv出力の例
図のように日付範囲を指定することで500件以下のcsvが取得できます。このように検索を何回かに分け、合計で5725件のデータを得ました。
また、特許は「審査請求がなされているかどうか」が重要ですが、今回の手法では経過情報を取得できないことに注意してください。
csvの確認
csvをpandasでとりこみ、結合させます。
from glob import glob
import pandas as pd
files = glob('./csv/*.csv')
# データフレームを格納する空のリスト
dataframes = []
# csvを読み込んでリストに追加
for file in files:
df_tmp = pd.read_csv(file)
dataframes.append(df_tmp)
# dfを縦方向に連結
df = pd.concat(dataframes, axis=0, ignore_index=True)
dfの一部を抜粋したものがこちらです。
| 文献番号 | 出願番号 | 出願日 | 公知日 | 発明の名称 | 要約 |
|---|---|---|---|---|---|
| 特開2022-176984 | 特願2022-132192 | 2022/08/23 | 2022/11/30 | 制動力制御装置 | (57)【要約】\r\n【課題】車両の惰行状態において好適な減速感を得つつ ショックを... |
| 特開2022-176936 | 特願2022-125242 | 2022/08/05 | 2022/11/30 | 水素供給システム | (57)【要約】\r\n【課題】配管を敷設するための大規模な工事を行うこと なく移動体... |
| ... |
"要約"のセルに改行の<br>や不要な記号が含まれているので、整形しておきます。
import neologdn
import re
pattern = r'\(.*?\)|【.*?】|\r\n|<BR>'
def preprocessing_text(text):
# アルファベットやアラビア数字などを半角に統一
normalized_text = neologdn.normalize(text)
# 不要な記号などを削除
sub_text = re.sub(pattern, '', normalized_text)
return sub_text
# '要約'の列に適用
df['要約'] = df['要約'].apply(preprocessing_text)
df['要約'][0]
で結果を確認してみます。
'車両の惰行状態において好適な減速感を得つつショックを抑制できる制動力制御装置を提供する。制動力制御装置は、ディファレンシャルギヤを介して車輪に力を伝達して車両に制動力を発生させる第1アクチュエータ部と、ディファレンシャルギヤを介さず車輪に力を伝達して車両に制動力を発生させる第2アクチュエータ部とを含み、制動力を得るために発生させる、車両進行方向を正の向きとしたときに負となる目標ジャークを算出する算出部と、第1アクチュエータ部によって発生させる所定のジャークである第1ジャークを算出する算出部と、第2アクチュエータ部によって発生させることが可能な最小のジャークである第2ジャークを算出する算出部と、目標ジャーク、第1ジャーク、および第2ジャークに基づいて、第1アクチュエータ部および第2アクチュエータ部にジャークを発生させる制御を行う制御部と、を備える。図3'
うまく整形ができているようです。
形態素解析 -> Doc2Vec
どのような分野にどれだけの特許があるか確認してみます。
Doc2Vecは、任意の長さの文章を、ある長さのベクトルに変換する技術です。Doc2Vecには、分散表現を得るための手法として、DBoW (Distributed Bag-of-words) とdmpv (Distributed Memory)があり、
- DBoWは、Bag-of-wordsと同じような単語の順序を考慮しないシンプルなモデル
- dmpvの方が精度が優れる
といった特徴があります。
「日本語WIKIPEDIAで学習したDOC2VECモデル」にすでに学習したモデルがありましたので、任意のディレクトリにダウンロードして解凍します。今回はdmpv300dを利用します。
英語などと異なり、日本語の場合はDoc2Vecの前に形態素解析をする必要があります。形態素解析ができるライブラリとして、MeCab, janomeなどがありますが、今回はMeCab + ipadic-NEologdを用います。
import MeCab
from gensim.models.doc2vec import Doc2Vec # gensim==3.8.3
# 形態素解析とDoc2Vecの関数を定義しておく
def tokenize(text): # 形態素解析
return tagger.parse(text).strip().split()
def get_sentence_vector(wakati): # ベクトル化
return model.infer_vector(wakati)
# MeCabで形態素解析
tagger = MeCab.Tagger('-Owakati -d "path/to/dic/NEologd.dic"') # NEologd辞書の指定
df['wakati'] = df['要約'].apply(tokenize)
# 学習済み日本語モデルを読み込んでDoc2Vec
model_path = 'Path/to/Doc2Vec/model' # モデルのパス
model = Doc2Vec.load(f'{model_path}/jawiki.doc2vec.dmpv300d.model')
df['vector'] = df['wakati'].apply(get_sentence_vector)
# 得られたベクトルをndarrayとして取得
doc_vectors = np.array(df['vector'].tolist()) # doc_vectors.shape=(5725, 300)
それぞれの特許を表現する300次元のベクトルが得られました。
なお、MeCabの辞書とDoc2Vecモデルのパスは自分の環境に合わせて適当にしてください。
また、gensimのバージョンによっては、モデルのloadで以下のエラーが生じる可能性があります。バージョンが新しいとこのようになるらしいです。私は3.8.3で行いました。
AttributeError: 'Doc2Vec' object has no attribute 'dv’
可視化
次元削減手法として、PCA (Principal Component Analysis) とt-SNE (t-Distributed Stochastic Neighbor Embedding) を試しました。
線形であるPCAに対し、t-SNE (t-Distributed Stochastic Neighbor Embedding) は、近くのデータは低次元空間でもできるだけ近くに、遠くのデータは低次元空間でも遠くになるようにする非線形手法です。t-SNEのハイパーパラメータに関しては「How to Use t-SNE Effectively」を参考に調整しました。
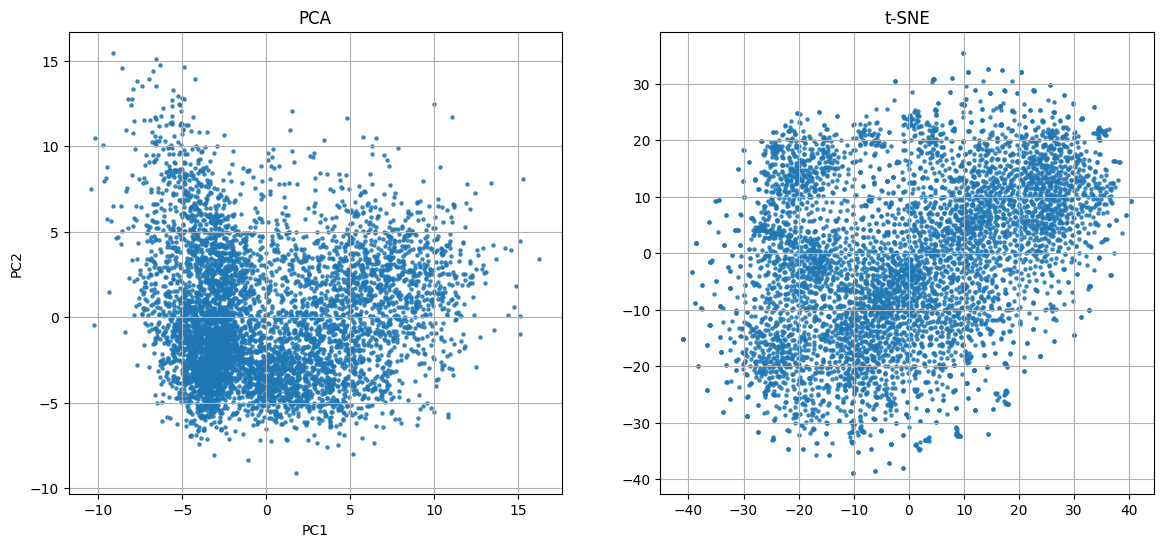
PCAとt-SNEの結果
あまりきれいには分かれていませんね。PCAも第一主成分と第二主成分の寄与率がそれぞれ0.074と0.048なので、かなりの情報を失っているようです。
クラスタリング
実際に特許を確認すると、
- 車両に関するもの
- 情報処理に関するもの
- 電池に関するもの
- ...
となっていますが、車両に関するものの中でもテーマが
- 制御方法
- 構造
- 駆動方法
- ...
のように分かれているので、階層的クラスタリングが良さそうです。
今回はward法による階層的クラスタリングを行いました。
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import linkage
skelearnかscipyを利用するのが簡単だと思います。今回はscipyを利用しました。
こちらがクラスタリング結果です。
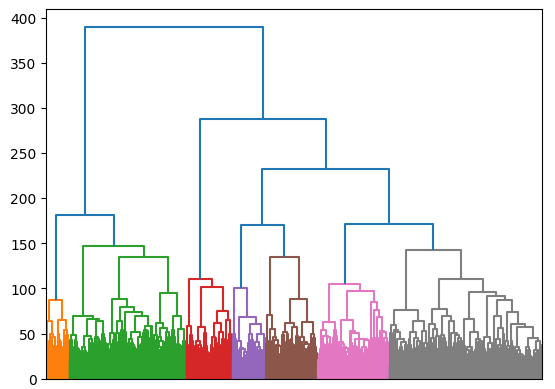
適当な閾値でクラスタリングしたデンドログラム
ほどほどにクラスタリングできているんじゃないでしょうか。合計で7個のクラスタになりましたが、緑とグレーのクラスタはもう少し細分化してもよいかもしれません。
各クラスタのラベル付け
このままだと、各クラスタがどのような技術分野かわからないので、TF-IDF (term frequency–inverse document frequency) で各クラスタにおける代表的な単語を抽出し、人為的にラベル付けしようと思います。
TF-IDFによって、ある単語の重要度を、頻出度やレア度から求めることができます。
ライブラリはskelearnを用いました。
from sklearn.feature_extraction.text import TfidfVectorizer
| クラス | 代表的な単語 | ラベル |
|---|---|---|
| 1 | 車両、情報、システム | 車両システム |
| 2 | 車両、部材、装置 | 構造体 |
| 3 | 燃料電池、触媒、車両 | 燃料電池 |
| 4 | 全個体電池、正極、負極 | 全個体電池 |
| 5 | 部材、接続、配置 | 構造配置 |
| 6 | エンジン、駆動、モータ | 駆動系 |
| 7 | 画像、取得、判定 | 制御システム |
各ラベルの件数と分布を確認してみます。
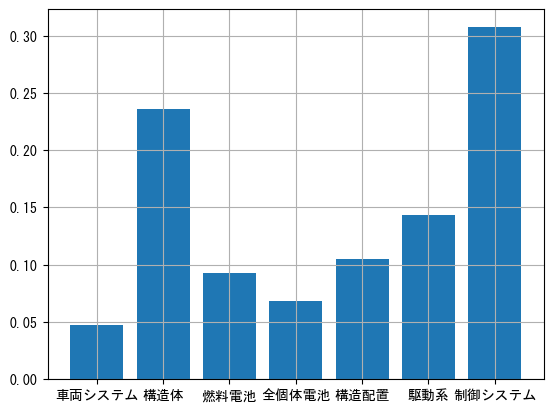
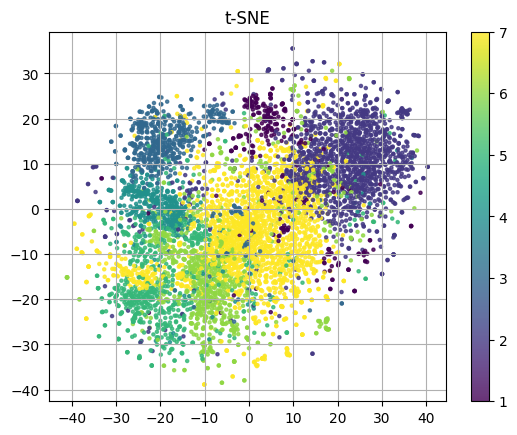
かなり大雑把な分類ですが、およその分類ができていそうです。
おわりに
今回の手法はいろんな文章に適応できると思います。Doc2Vecでは、学習データより長い文章を扱うと、固定長のベクトルに情報を詰め込めきれなくて情報の損失が起きるようです。
Attention機構であればこの問題を解決でき、BERTの方が精度が高くなるようですので、今度はそちらも試してみたいと思います。
今回は特許のクラスタリングを行いましたが、(実は)特許にはFIと呼ばれる、技術分野を示すラベルがついており、その内訳は特許庁のテーマコード一覧から確認できます。
全テーマコードの表
技術分野を分類するだけであれば、このテーマコードと特許についてるFIを照らし合わせる方が良さそうです。