初めに
お盆休み期間にTaobaoを運営しているAlibaba会社2019年に発表したレコメンド技術の論文を読んで、論文中提出した「term embedding」からいくつかのインスピレーションを受けました。特にItemとqueryよりユーザー属性を表すの部分現在でも活用できそうを感じました。
記事内容大体自分の理解を踏まえたの翻訳が多い、一部感想も含めています。
(一部の翻訳はGPT-4より文脈チェックや修正を行っています。)
もし何か間違っている点があれば、また他に意見がございましたら、気軽にコメントしてください。
背景
近年、モバイルeコマースプラットフォームが急速に普及する中、ユーザーの購買意向を正確に予測し、パーソナライズされた推薦を提供することは、プラットフォームの成功において極めて重要である。従来の推薦システムでは、ユーザーの明示的な入力や単純な行動履歴に基づく推薦が主流であったが、これには限界がある。具体的には、ユーザーの多様な意図や複雑な行動パターンを捉えることが難しく、結果としてユーザー体験の向上に繋がりにくい。
そこでモバイルeコマースプラットフォームにおけるユーザーの意図を推薦する新しい手法として、「Metapath-guided Heterogeneous Graph Neural Network for Intent Recommendation(意図推薦のためのメタパス誘導型異種グラフニューラルネットワーク、MEIRec)」を提案し、下記のことが実現しました。
- ユーザーの行動履歴を基に、GNNに基づく新しいネットワークモデル「MEIRec」を提案し、パーソナライズされたレコメンダーシステムを実現しました
- itemパラメーター空間を削減ため、新たなUniform term embeddingを使用
- taobaoECサイトが2.66%の新規ユーザーを推奨クエリの検索に引き付けた
灰色の検索クエリは、おそらく今回の技術を用いて生成されたIntent Recommendation queryだと思います。
用途
1.モバイルでの検索queryの入力時間を短縮可能
2.何を検索すればよいのか不明な時にレコメンド機能として利用

論文本文
Intent Recommendationとは
- ユーザーが入力を行わずにアプリを開くと、ユーザーの過去の行動履歴に基づいて検索queryを生成
- メリット
- 検索queryの入力時間を短縮可能
- 何を検索すればよいのか不明な時にレコメンドとして利用
- メリット
- 本論文前にIntent Recommendationdよく使われているアプローチ
- ドメイン知識から手動で特徴エンジニアを行います。
- ユーザーとquery情報の統計情報しか使われていません、item情報を考慮していません。
- GBDT や XGBoostより分類器を学習させ。
- ドメイン知識から手動で特徴エンジニアを行います。
Metapath-guidedについて
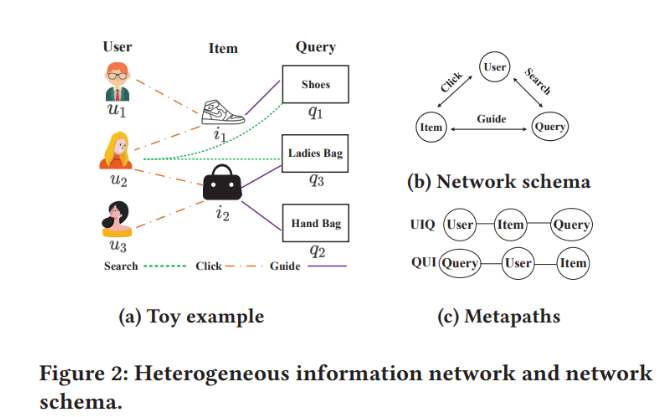
- Metapath-guided Neighbors
- 与えた特定なmetapath条件でguided可能なNeighborsの数
N_{UIQ}^{0}(u_2) = \{u_2 \},N_{UIQ}^{1}(u_2) = \{i_1,i_2 \},N_{UIQ}^{2}(u_2) = \{q_1,q_2,q_3 \}
N_{UIQ}(u_2) =\{ N_{UIQ}^0(u_2), N_{UIQ}^1(u_2),N_{UIQ}^2(u_2) \} = \{u_2,i_1,i_2,q_1,q_2,q_3 \}
N_{IQU}(i_1) = \{i_1,q_1,u_2,u_1 \}
上記の情報に基づいて「Q、U、I」の相互informationあらわせることが可能になります。
次にHeterogeneous graphによって上記の情報を用いてuserとquery embeddingの学習を行います。
Metapath-guided Neighborsのイメージ
- a):一方的な関連性しか表さない
- user (search) query
- user (click) item
- query (guide) item
- b):ネットワーク構造より相互関係性表せることができます
- user (search) query (guide) item
- c):任意の順番のMetapath作成できます
- user (click) item (by search) query (guide the) item
- etc.
Framework of MEIRec

Uniform Term Embeddingについて
従来の方法、例えばone-hot形で各ユーザーとクエリにunique embeddingを持たせると、パラメータが非常に巨大になります。
本論文ではqueryとitemを形態素解析 ? で解析し、term単位に分割して次の学習stepにtermのembeddingを学習行います。
Term イメージ
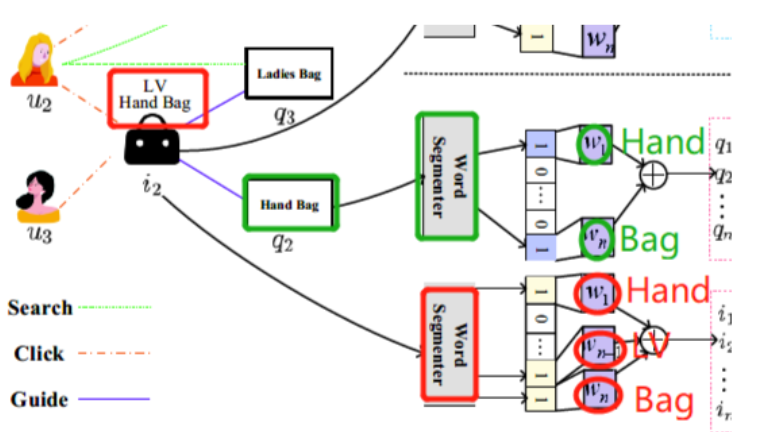
termに分割のあとに以下の図に示すように、multi-hot表現として使用することができます。
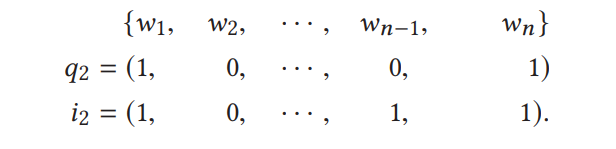
(term単語のembeddingどう作っているか不明ですが、恐らく当時はont-hotもしくはBERTやword2vecなどより作っているではないのか)
query embedding作成について
multi-hot表現に基づいて、本論文では以下の公式を用いて最終的な埋め込みを計算します:
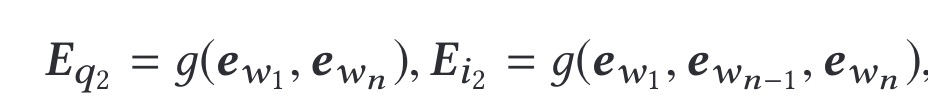
$e_{w_i}$は、term用語$w_i$のベクトル表現を示し、g(⋅) は融合関数でありTerm embeddingの結合には平均を使用されています。
これによりitemとqueryが同じ埋め込み表現空間で表示できるようになりました。
input層では検索やクリックの相互情報量を同じベクトル空間内に閉じ込めることが可能です。
Metapath-guided Heterogeneous Graph Neural Network
ここはMetapath情報を用いてembedding作成方法を紹介いたします。
あるobject(user,itme..)のembedding得られるため、今回の論文はまずmetapathに基づいて各nodeのNeighborsを計算し、最終に得られたmetapath-guidedのembeddingを計算objectの埋め込み表現として利用します。

user modeling detail
論文中では各メタパスに対して、ユーザーのベクトル表現を個別にmodelingしています。

query modeling
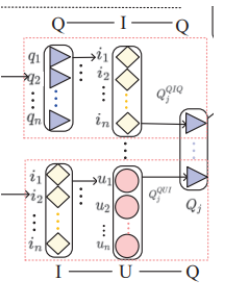
userのaggregationほぼ同じ、各query起点としてのメタパスに対して、queryのベクトル表現を個別にmodelingする。
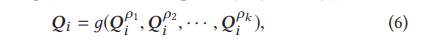
aggregation functionはCNN
目的最適化について
user embeddingとquery embeddingとstatic featuresを結合して、MLP層よりsimgmoid関数からuser具体的にクリックの確率を計算します。CE(クロスエントロピー損失)よりterm embeddingとパラメーターを最適化を行います。
本論文中static features(静的特徴)はqueryとuserの統計情報より設定します
- user featuresは42つ
- 性別、年齢、購買能力など
- query featuresは39
- 文字列の長さ、用語の数、クリック率など。
## データおよび評価について
Taobaoから10 日間のインタラクティブデータに基づいて異種情報ネットワークを構築しています。
- 1 億のquery、40 億のuser、40 億のitem
- user(search)query 40億
- user(click)item 200億
- item(guide by) query 40億
- データ特徴
- データ量がかなり多い
- 検証データにも新規ユーザー含まれています
比較手法について
- LR: 静的特徴(static features)を使用した線形モデル
- DNN: 入力は LR と同じ、3 層 MLP
- GBDT: 勾配ブースティング木のモデル、入力は静的特徴
- LR/DNN/GBDT+DW: 静的特徴と事前学習済みのDeepWalk によって取得されたembedding情報を含む
- LR/DNN/GBDT+MP: 上記と同じですが、異なる点はmetapath2vecのembeddingを使用
- NeuMF: Top-NレコメンドのSOTA、inputはuser|queryのインタラクティブデータ
- 今回の手法
## 結果
- 提案されたMEIRecの予測性能が最も優れており、このモデルが統計的特徴と相互関係を効果的に融合していることを示しています
- GBDT > DNN > LR > NeuMFの順になっています
- 検証データセットに多数の新しいユーザーと新しいクエリが含まれており、NeuMFはトレーニング過程でこれらのオブジェクトに対応した経験がなかったため、ランダムに初期化されたパラメータしか提供できず、その結果として最も低い性能を示しました。GBDTは、特徴情報を融合する優れた分類モデルであり、実験結果もGBDTの優位性を証明しています。そのため、実際のシナリオではGBDTが広く使用されています
- 静的特徴+異種ネットワーク投影 > 統計的特徴+同種ネットワーク投影 > 統計的特徴のみ、という結果が示されました。これは、より多くの情報を統合することでより良い結果が得られることを示しています。また、異種ネットワーク投影モデル(例えば、MetaPath2vec)は、同種ネットワーク投影モデル(例えば、Deepwalk)よりも優れています。これは、オブジェクトの異種性を考慮することで、モデルの性能を向上させることができることを示しています
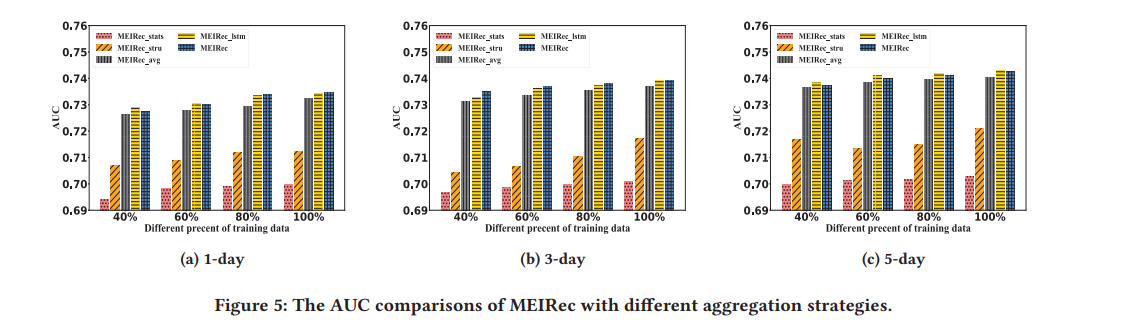
- このタスクにおいては、構造情報が統計的特徴よりも有効であり、論文で提案された静的特徴+Heterogeneous 情報を結合が非常に効果的であることが示されました
- 複数の情報を使用すると効果がよくなります
- 異なる種類の隣接ノードに対して、異なる種類の融合関数を使用することが非常に重要です。(avg,lstmの効果を示す)
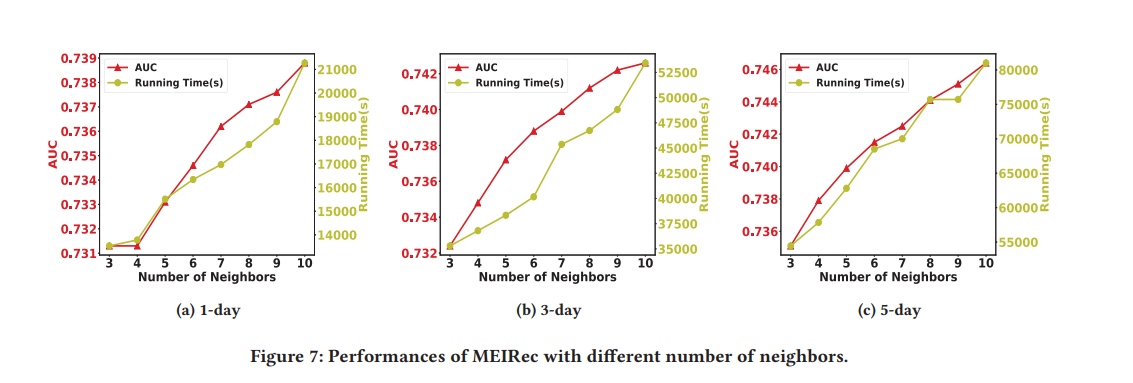
隣接ノードの情報は、ユーザーの表現を効果的に強化できます。
隣接ノードの情報が多ければ多いほど、$\color{red} {ユーザーの個別の意図} $をより表現できます。
しかし、隣接ノードの数が増えると、モデルの$\color{red} {実行時間も増加}$します。(レイテンシー問題につながり)
本論文では、コスパやレイテンシー観点では実験において隣接ノードの数を5を設定しました。
まとめ
本論文は電子商取引分野におけるIntent Recommendationに関する研究を行われ、その成果が実際にTaobaoアプリに運用され、ユーザーの検索意図を推測して検索バーに自動的に検索キーワード(クエリ)を生成するより、入力の手間を省くだけでなく、検索したい商品をどのように表現すればよいか迷っているユーザーにも利便性を提供します。
online A/Bテストの結果(2.66% up)より本論文のモデルが検索クエリに新規ユーザーを引き付ける上で有利であることを示しています。
モデルの構成も明確しています
まずUser | item | queryをノードとするHINを構築します。
次に、事前に定義されたメタパスに従って、ターゲットノードの多階層の隣接ノードを取得し、GNNの方式で逐次的に情報を集約し、ターゲットノードの埋め込み表現を生成します。
その後、異なるメタパスで得られたユーザーおよびクエリの埋め込み表現を統合し、ノードの静的特徴と共にMLPに入力して、ユーザーがそのクエリを検索する確率を予測します。
最後に、目的関数を最適化し、パラメータを調整することで、意図推薦の精度を向上させます。
個人的の懸念点や感想
term情報をembedding変換する方法について不明、恐らくone-hotやw2vのモデルもしくは何も処理せずにモデルで良しなに学習していると思います。
現在から見るとデータ前処理段階で意味理解強いなNLPモデルを利用すれば、精度や生成したqueryの質さらに向上できるかもしれません。ただ学習コストや維持費用も上がります。
検索は前後持ちのシーケンスデータなのでaggregation functionはLSTM利用には効果が良さそう。一方で、クエリの隣接ノードには順序性がないため、論文ではCNNを使用して集約する方が効果的であることを示されています。
他のinten recommendationに関する論文