Microsoft MVPで、Azure Cosmos DBコミュニティチャンピオンのBlaize Stewartさんが「Cosmos DBアンチパターン」の記事を書いていたのでその紹介です。
- Antipattern 1: データに対して不適切なパーティションスキーマを選択している
- Antipattern 2: 整合性モデルについての無理解
- Antipattern 3: Bad query パターン
- Antipattern 4: Cosmos DBをOLAPで利用する
- Antipattern 5: SDKを正しく利用していない
Antipattern 1: データに対して不適切なパーティションスキーマを選択している
- Cosmos DBのデータはパーティション化されている
- データがパーティショニングされていると、複数のストレージやコンピュートノードに作業を分散させることができる
- ユーザがCosmos DBにデータの格納方法を指示しなければならない
駄目な例
- データが1部のパーティションに片寄って配置されている ※これが一番駄目
- データはバラけているがクエリには最適化されていない ※何も考えずにidを使っているとこうなる可能性がある

何を使ったらいいのか分からない場合(デフォルト挙動)
- 生成された「id」を使用し、その「id」をパーティション・キーとして割り当てる
- この場合、パーティションに均等に分散させることができる
- 実際の読み取りシナリオに最適化されているとは言えない
読み取りが多いシナリオの場合
- データを最も頻繁に読み取る方法でパーティショニングする
- 例えば、あるアプリケーションが地域ごとに顧客データを追跡し、データベースに対するアプリケーション・リクエストのほとんどが、地域ごと、あるいは地域内のデータをフィルタリングしていた場合、地域IDをパーティションキーとして使用するパーティショニングスキームがアプリケーションに適している
- データに対する各リクエストにはパーティションキーが含まれ、Cosmos DBはそのキーを使ってクエリを高速化できる
小規模なデータセットの場合
- 小規模なデータセットでは、すべてのデータを1つのパーティションで管理しても良い
- この場合すべてのクエリが同じパーティションにルーティングされる
- 参照データについては、ドキュメントに「type」プロパティを追加することを検討するとよい。この場合、1つのコンテナ上の1つのパーティションを複数の種類のデータに使用することができ、RUの数を減らすことができる
書き込みの多いワークロードの場合
- パーティション間でデータを分散させるキーを選択する
- このパーティション・キーに関連付けられる値が多ければ多いほど、分散させることができる
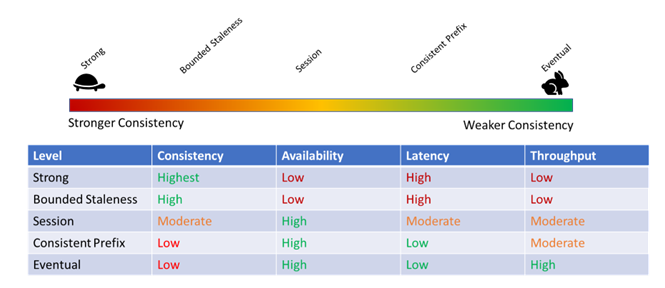
Antipattern 2: 整合性モデルについての無理解
- Cosmos DBは、5つの一貫性モデルを提供している
- 一貫性とは、書き込みがいつ読み込まれるかということである
- 強力な一貫性とは、書き込みが完了すると同時にデータが読めるようになることを意味する
- 一貫性が強いと、書き込みトランザクションに時間がかかるため、通常、データベースのスループットが低下する
- デフォルトの一貫性モデルのセッション一貫性はほとんどの場合に問題にならないが、重要なのは、一貫性モデルの意味合いと、それがアプリケーションにどのような影響を与えるかを理解することである
Antipattern 3: Bad query パターン
- デフォルトではすべてインデックス化されている
- インデックスを有効にしても、クエリのパターンが悪いと、パーティションをまたぐか、インデックスを利用しないか、あるいはその両方によって、パフォーマンスが低下することがある
BEST:単一のパーティションでクエリをインデックス化する。
- インデックスされたデータに対して単一のパーティションでクエリを実行できれば、クエリは高速に実行されるだけでなく、消費されるRUの量も少なくなる
- インデックス付きのデータが1つのパーティションにあったとしても、パーティションキーをクエリの一部として含めることで、Azure Cosmos DBがパーティションをまたぐクエリを想定していないことがわかる
OK:パーティションにまたがるインデックスクエリ
- すべてのクエリで有効なパーティションキーを思いつくのは不可能だが、例外になるようにするべきである
- パーティションをまたいだクエリが頻繁に発生する場合は、パーティションキーが異なる2つ目のコンテナにデータをコピーし、Changefeedで同期をとる方がパフォーマンス的にもコスト的にも有利な場合がある
- シングルパーティションのインデックスクエリを優先し、パーティションをまたいだクエリを行う必要がある場合は、データがインデックス化されていることを確認する
BAD:単一パーティションでのインデックスなしクエリ
- インデックスがないクエリとは、クエリエンジンがフィルタを適用する前に、まず何らかの方法でデータを変換しなければならないクエリのこと
-
SELECT * FROM c WHERE c.Id = 'ABC' AND pk = 'XYZ'は問題ない -
SELECT * FROM c WHERE UPPER(c.Id) = 'ABC' AND pk = 'XYZ'はインデックスが効かない
TERRIBLE:パーティション間のインデックスなしクエリ
絶対にやめるべき
Antipattern 4: Cosmos DBをOLAPで利用する
- 特にCore (SQL) API、API for MongoDB、Gremlin APIはトランザクション指向のデータベース
- エンジンはレコードレベルの操作(OLTP)に最適なパフォーマンスを発揮する
- データをサマリー(平均値、時系列データ、合計、集約など)に適した方法で表示する必要がある場合(OLAP)には向かない
- Cosmos DBはデータのサマリーやアグリゲートを行うことができますが、そのために最適化されているわけではない
- Azure Synapse Linkを通じて、Azure Synapseにデータを簡単にフィードできるようになった。これは、Azure Cosmos DBからデータを取得し、Synapseが分析に使用できるカラムストアのコピーを作成する
- データを集約した形で別のコンテナ(セカンダリコピー)に格納するだけでもよい
- セカンダリコピーは、データベースが重い計算を行う必要がないため、「スピードレイヤー」と呼ばれることもある
Antipattern 5: SDKを正しく利用していない
- データベース接続は再利用しなければならない
- Azure Cosmos DB SDK は、接続を維持し、再利用することを望んでいる
- 接続を再利用しないことはスレッドの枯渇、ポートの枯渇、メモリリーク、または検出が困難な多くの悪い動作につながる
感想
実務でCosmos DBを大規模に使ったことがなかったので私はとても参考になりました。
整合性モデルについての説明はこの記事の内容よりも、より深く知らないといけないなと思ったので、良い記事があればまた紹介したいと思います。