この文書の目的
この文書は SCAPY をインストールして TCP 通信を試してみよう、と思った人向けのものです。
前提
以下のことを前提に書いています。
- TCP のことをまあまあ理解している
- socket のことをなんとなく把握している
なお、「その1:準備編」と「その2:はじめてのGET編」があります。
StreamSocket を用いた簡単な通信
「その2:はじめてのGET編」で、OS のカーネルを使わないで ACK フラグなどをSCAPYによるパケット操作で返すことにはかなり限界がありそうだと説明しました。
そこでここではACK処理はカーネルに任せて、アプリケーションレベルでTCPストリームの操作をすることを目指します。
SCAPYの公式ドキュメントの「TCP」のところを見ると、それを実現してくれる StreamSocket なるクラスが用意されていることがわかります。
小さなWebコンテンツの取得
以下はとても小さなコンテンツをWebサーバから取得する手続きを、StreamSocket を用いて書いたものです。例によって URL (ホスト名、パス)などは自分の状況に合わせて書き換えてください。
>>> sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
...: sck.connect(("example.com", 80))
...: ssck = StreamSocket(sck)
...: res = ssck.sr1(Raw("GET /a.html HTTP/1.0\r\nHost: example.com\r\n\r\n"))
...: ssck.close()
Begin emission:
Finished sending 1 packets.
*
Received 1 packets, got 1 answers, remaining 0 packets
>>>
コードはとても単純です。ポイントは以下のあたりでしょうか。
- 一度開いたソケットを用いて StreamSocket を作る
- そこに sr1() でGETリクエストを送信して返事を待つ
- HTTP 1.0 を用いている(サーバはコンテンツを送り終わるとコネクションを切る)
この状態で res 変数には受信したデータが入っています。
>>> res.load
b'HTTP/1.1 200 OK\r\nDate: Tue, 15 Dec 2020 07:21:07 GMT\r\nServer: Apache\r\nLast-Modified: Thu, 22 Oct 2020 09:34:49 GMT\r\nETag: "d7-5b23f2cde4040"\r\nAccept-Ranges: bytes\r\nContent-Length: 215\r\nMS-Author-Via: DAV\r\nContent-Type: text/html\r\nConnection: close\r\n\r\n<HTML>\n<HEAD>\n<META HTTP-EQUIV="Content-Type" CONTENT="text/html;CHARSET=UTF-8">\n<TITLE>Test Page</TITLE>\n</HEAD>\n<BODY bgcolor="#ffffff">\n\n<h2>\nTest Page for YLB.\n</h2>\n\n\xe3\x81\xa0\xe3\x82\x89\xe3\x81\xa0\xe3\x82\x89\xe3\x81\xa0\xe3\x82\x89\xe3\x81\xa0\xe3\x82\x89\xe3\x80\x82\n</BODY>\n</HTML>\n'
>>>
改行などがそれなりに見える形になるように、ペイロード部分(バイト型データ)を decode して表示させてみます。
>>> print(res.load.decode())
HTTP/1.1 200 OK
Date: Tue, 15 Dec 2020 07:21:07 GMT
Server: Apache
Last-Modified: Thu, 22 Oct 2020 09:34:49 GMT
ETag: "d7-5beef2cde4040"
Accept-Ranges: bytes
Content-Length: 215
MS-Author-Via: DAV
Content-Type: text/html
Connection: close
<HTML>
<HEAD>
<META HTTP-EQUIV="Content-Type" CONTENT="text/html;CHARSET=UTF-8">
<TITLE>Test Page</TITLE>
</HEAD>
<BODY bgcolor="#ffffff">
<h2>
Test Page for XXX.
</h2>
だらだらだらだら。
</BODY>
</HTML>
>>>
すこし大きなコンテンツの取得
先の例は sr1() をただ一度だけ呼び出していました。しかし一回の sr1() 呼び出しで大きめのコンテンツを取得させることはできません。試しに少し大きめのコンテンツを取得させると、途中でデータが切れていることがわかると思います。
つまり受信処理を一度でやめず、終わるまでループさせる必要があります。最も簡単な例は恐らく以下のようなものでしょう。
sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sck.connect(("example.com", 80))
ssck = StreamSocket(sck)
ssck.send("GET /aaa.html HTTP/1.0\r\nHost: example.com\r\n\r\n".encode())
resList = []
while True:
res = ssck.recv()
if res == None:
break
print("recv {0} bytes".format(len(res)))
resList.append(res)
print("{0} elements".format(len(resList)))
ssck.close()
上のコードのポイントは以下のあたりでしょうか。
- sr1() でなく send() を使って GET リクエストを送信した
- HTTP 1.0 を用いている(サーバはコンテンツを送り終わるとコネクションを切る)
- その後 recv() を繰り返し、受信したデータをリストに追加して保存
- recv() が None を返したら受信終了としてループを抜ける
- 実行が終わったら resList[0] などとして内容を確認する気分
ところでパケットモニタを見ていれば分かると思いますが、recv() が None を返しているのは、サーバ側がコネクションを切断したためです。これは GET リクエストが HTTP 1.0 によって行われたためで、1.1 だった場合にサーバはコンテンツの送信が終わってからもコネクションを切ることはありません。
timeout を使った強引な HTTP 1.1 対応
向こうが送信を停止したことを検出してコネクションを切る簡単な方法はタイムアウトです。そこでタイムアウトを利用して簡単に HTTP 1.1 で受信する方法を考えます。
ところが SCAPY は不思議なことに StreamSocket については sr1() に timeout オプションがあるくせに、recv() にはそれが実装されていません。
そこで上のコードを sr1() を無理矢理使うように書き換えてみます。
sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sck.connect(("example.com", 80))
ssck = StreamSocket(sck)
req = "GET /aaa.html HTTP/1.0\r\nHost: example.com\r\n\r\n")
resList = []
while True:
res = ssck.sr1(Raw(req), timeout=3, verbose=False)
if res == None:
break
print("recv {0} bytes".format(len(res)))
resList.append(res)
req = ""
print("{0} elements".format(len(resList)))
ssck.close()
実行すると先の例とは違って、受信終了とともにすぐプログラムが終了することはなく、sr1() の timeout パラメタに指定した 3 秒を待ってからループを抜けて終了処理に入ることがわかると思います。
sr1() で「何も送らない」指定をすると
それにしても sr1(Raw()) という書き方はいかにも気色が悪いです。一応ソースを当たってみました。scapy.sendrecv の、sndrcv() 関数のすぐ下にある __gen_send() 関数が実際のソケットに対する送信処理( send() コール)を行っているところと見えます。
その中には、与えられた引数 x に対して以下のような構造が見えます。
def __gen_send(s, x, inter=0, loop=0, count=None, verbose=None, realtime=None, return_packets=False, *args, **kargs):
# ....(すごく略)....
for p in x:
# ....(すごく略)....
s.send(p)
恐らく中身が無かった場合でも socket s の send() が呼び出されてしまうようです。これがどのような副作用をもつのか明確にするところまでは追い切れていません。
recv() で timeout させる
本当、どうして SCAPY は recv() にtimeout を付けないのでしょうね。やっぱり recv() 処理を普通に使いたかったので、私自身は SCAPY にこんな修正を加えて使っています。
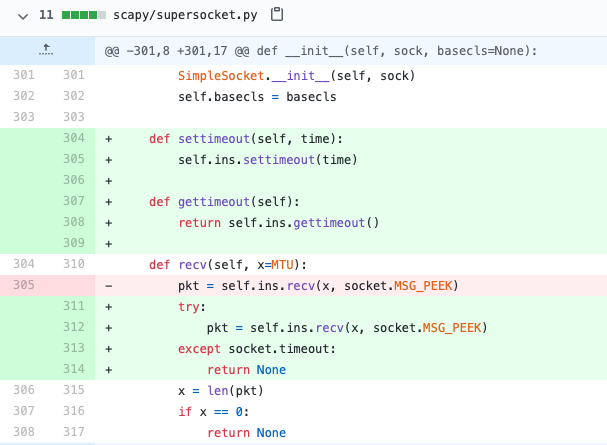
この修正によって、以下のような(私にとっては素直な)記述が可能になります。たった一行、settimeout() を追加するだけです。それ以降の recv() 処理はその秒数だけ待って返事がなければ、そこで帰ってきます。戻り値は sr1() での timeout 時同様、None になります。
sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sck.connect(("example.com", 80))
ssck = StreamSocket(sck)
ssck.send("GET /aaa.html HTTP/1.1\r\nHost: example.com\r\n\r\n".encode())
ssck.settimeout(3)
resList = []
while True:
res = ssck.recv()
if res == None:
break
print("recv {0} bytes".format(len(res)))
resList.append(res)
print("{0} elements".format(len(resList)))
ssck.close()
コンテンツ受信完了を調べるマトモな HTTP 1.1 対応
異常時の対応に StreamSocket に timeout が欲しいことは間違い無いのですが、とりあえず HTTP 1.1 ではコンテンツの受信は HTTP Response Header を見て、Content-Length: あるいは Transfer-Encoding: の指定に正しく反応する必要があります。
以下にそのどちらのヘッダにも対応するように書いてみたものを示します。
# ヘッダ行から : 区切りを頼りに key, value を取り出す
def chopHeader(line):
pos = line.find(": ")
key = line[:pos]
value = line[pos+2:]
return (key, value)
# CRLF で区切られた一行を取って来る
def getLine():
global buf
while True:
pos = buf.find(b"\r\n")
if pos < 0:
res = ssck.recv()
buf = buf + res["Raw"].load
else:
line = buf[0:pos]
buf = buf[pos+2:]
return line.decode()
# 指定されたバイト数まで取って来る
def getBytes(size):
global buf
while True:
if len(buf) < size:
res = ssck.recv()
buf = buf + res["Raw"].load
else:
line = buf[0:size]
buf = buf[size:]
return line
# コンテンツ取得
def getContent(host, path):
global buf
get = "GET {0} HTTP/1.1\r\nHost: {1}\r\n\r\n".format(path, host)
ssck.send(Raw(get))
# header part
isChunked = False
contentLength = 0
buf = b""
while True:
line = getLine()
if len(line) == 0: # header process done
break
(key, value) = chopHeader(line)
if key == "Transfer-Encoding" and value == "chunked":
isChunked = True
if key == "Content-Length":
isChunked = False
contentLength = int(value)
# body part
if isChunked:
print("Chunked mode\n")
data = b""
totalSize = 0
while True:
hexStr = getLine()
chunkSize = int(hexStr, 16)
print("chunk size = {0}".format(chunkSize))
totalSize = totalSize + chunkSize
if chunkSize == 0:
break
data = data + getBytes(chunkSize)
getLine() # remove following CRLF
print("total data = {0}".format(totalSize))
print("check last line, size = {0}".format(len(getLine())))
else:
print("Content-Length mode ({0} bytes)\n".format(contentLength))
data = getBytes(contentLength)
return data
##### main
sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sck.connect((host, 80))
ssck = StreamSocket(sck)
data = getContent("example.com", "/aaa.html")
print("size = {1} bytes".format(len(data)))
ssck.close()
サーバが Content-Length: ヘッダを付けて答える場合、実行結果は以下のようになるでしょう。
Content-Length mode (1569 bytes)
1569 bytes
サーバが Transfer-Encoding: chunk と答える場合、実行結果は以下のようになるでしょう。
Chunked mode
chunk size = 20374
chunk size = 351
chunk size = 29983
chunk size = 0
total data = 50708
check last line, size = 0
50708 bytes
ファイルに出力
もしファイルにデータを書き残したければ、変数 data に受信した結果が残っていますから以下のようにすると良いでしょう。画像ファイルなどでもこれで保存して、そのまま画像ビューア的なアプリメーションなどで開けると思います。
fp = open('/tmp/data', mode='wb')
bytes = fp.write(data)
print("total {0} bytes".format(bytes))
fp.close()
雑なところ
Transfer-Encoding: ヘッダは "chunked" だけでなく "gzip, chunked" のように複数の値を返す場合があります。が、コードは乱暴にも、以下のようにしています。
if key == "Transfer-Encoding" and value == "chunked":```
もちろん value を find() するなりして文字列 "chunked" が含まれるか否かで判定すればいいのですが、初学者向けにコードが易しくなるように、そのままにしておきます。
もう少し HTTP 1.1 らしい受信
せっかく HTTP 1.1 に対応させたのですから、もう少し HTTP 1.1 らしい実験をするとしたら、こんな感じでしょうか。あるサイトに接続して(コネクションを張って)、複数回の GET リクエストを繰り返して(コネクションを切ること無く)複数のコンテンツを受信するものです。
##### main
host = "example.com"
pathlist = ("/a.html", "/aa.html")
sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sck.connect((host, 80))
ssck = StreamSocket(sck, Raw)
for path in pathlist:
data = getContent(host, path)
print("path = {0}, size = {1} bytes".format(path, len(data)))
print("Done")
ssck.close()
追記 (2020/12/31):
連続してコンテンツを取得していると、そのうちに突然コネクションが切られてしまう現象が出ました。(上のコードだと recv() が NoneType を返してエラーになります。)
私の手元の Apache サーバでは 101 回目終了後に切れました。良く見ると最後に成功した GET に対するレスポンスには、Connection: close ヘッダがついていました。何故これが付くのか、なぜそれが101回上限なのかは追い切れていませんが、必要であればこのヘッダ指示に対応して StreamSocket をクローズし、再度オープン・connectするのが良いでしょう。
なお、この現象は curl の引数に 101 以上の URL を与えることで一つのTCP connection で連続受信させることで再現可能です。curl もその場合は再度コネクションを張り直します。
おわりに
ところで上に示したコードは単純に HTTP でコンテンツを取ってくるだけ、の処理です。SCAPYはそれについてはちゃんと実装があります。この HTTP のところに、以下のように使い方の例まで載せてくれてます。

HTTP 2 にも対応したようですし、使いやすそうですね。
当たり前ですが SCAPY はネットワーク実験をするためのツールですから、より短い記述で普通の処理が書ける(理解をスキップできる・処理を隠蔽してくれる)方が嬉しい、という人が使うものではありません。
今回、低レイヤーの実験、またその教材として SCAPY を使ってみました。適度にレイヤーの低いことが、適度な面倒臭さでできて、なかなか良い感じでした。
こういうことに興味の湧いた方はぜひ試して、Qiita に情報を出していってください。すると私がとても助かるので。。。。
例えば上に示した HTTP 処理のための拡張などを追いかけると、独自プロトコルに基づくアプリケーションを書くのが楽になりそうですよね。誰かチュートリアル的なのを書いてくれると嬉しいなあ。。。。