はじめに
本記事は自殺ツイート検出を試みるためセンシティブな内容を含みます。
ショッキングな内容もありますので何卒ご了承ください。
私は学生時代に友人を自殺で失ったことがあります。その時、なぜその友人の苦悩に気が付けなかったのだろうという後悔がいまもあります。その経緯から、人々の心の声をツイッターから検出し、相談できる場所を紹介したり、相談できる時間が限られる場合はAIがカウンセリングするといった打ち手が取れないかと考え、まずは自殺ツイートを検出できるのか試みました。

自殺ツイート検出の流れ
①データセット作成 ←今回はこちらを説明します。
②データのEDA、ルールベースでの検出
③ナイーブベイズでの検出
④BERTを用いたモデル作成
⑤アプリケーション作成
kaggleにて英語の自殺ツイートを集めたデータセットはありましたが、日本語は見当たらなかったため、自分でイチから作成することにしました。
▼kaggleでの類似データセット
https://www.kaggle.com/datasets/nikhileswarkomati/suicide-watch
データセット作成の流れは以下の通りです。

自殺ツイート収集
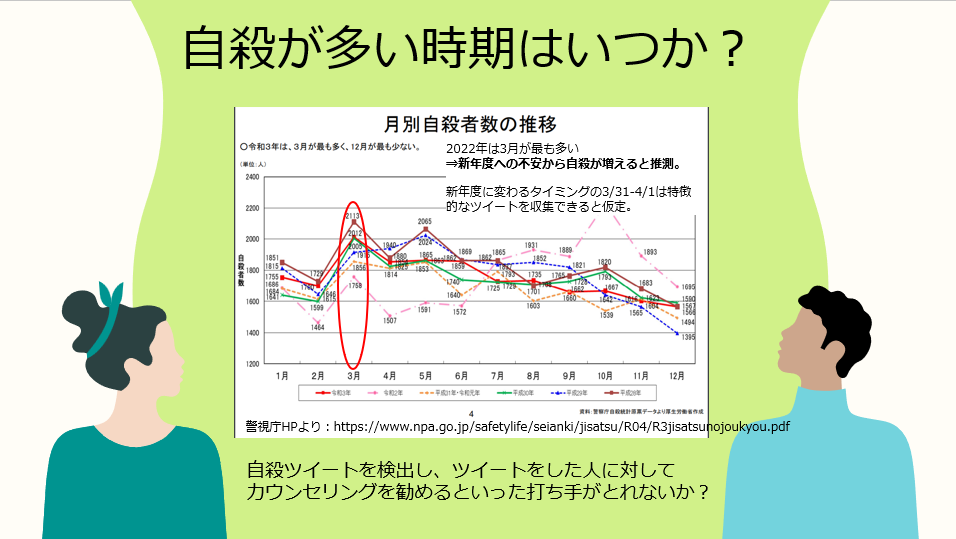
自殺ツイートを集めるにあたって、どの時期のものを集めればいいのかという問いがありました。
警視庁の資料によると、2022年は3月が最も多かったようです。これは4月から新年度が始まり、新しい生活・環境への不安からなのではないかと推測し、特徴的なツイートが集められると考え、3/31から4/1にかけて「死にたい」とつぶやかれたツイートを収集しました。
▼警視庁資料
https://www.npa.go.jp/safetylife/seianki/jisatsu/R04/R3jisatsunojoukyou.pdf
ツイートを集めるときはtweepyが有名ですが、twitter APIのkeyを取得したり大変なため、snsclapeを用いました。
#snscrapeでツイート収集
!pip install snscrape
import pandas as pd
import snscrape.modules.twitter as sntwitter
# ツイートの個数設定
maxTweets = 4000
# ツイート検索するキーワード
keyword = '死にたい'
df=[]
cols=pd.DataFrame([['id','date','tweet','likeCount']])
cols.to_csv('tweet.csv',index=False,header=False)
# 対象期間の「死にたい」を含むツイート
for i, tweet in enumerate(sntwitter.TwitterSearchScraper(keyword + ' since:2022-3-31 until:2022-4-1 lang:ja -filter:links -filter:replies').get_items()):
# いいね数0以上、文字数5以上のツイートを取得
if tweet.likeCount >= 0 and len(tweet.content) >= 5:
# 改行を削除
t = tweet.content
text = t.replace('\n', '')
df.append([tweet.id, tweet.date, text, tweet.likeCount])
df1=pd.DataFrame([[tweet.id, tweet.date, text, tweet.likeCount]])
# csvファイルとして保存
df1.to_csv('tweet.csv',index=False,mode='a+',header=False)
elif len(df) == maxTweets:
break
#csvに格納
import pandas as pd
tweet = pd.read_csv('tweet.csv')
このようなツイートが集められました。

「4月が始まってしまった死んでしまいたい」
「年度初日なのに頭痛が酷くて遅刻…死にたい」
「iPodのシャッフル再生で死にたくなる曲ばっかり再生されるから死にたい」
といった、深刻なツイートと軽い気持ちで死にたいといったツイートがあることが分かります。
4,000件をじっくり見ていくと「死にたい」ツイートは以下のように分類できました。
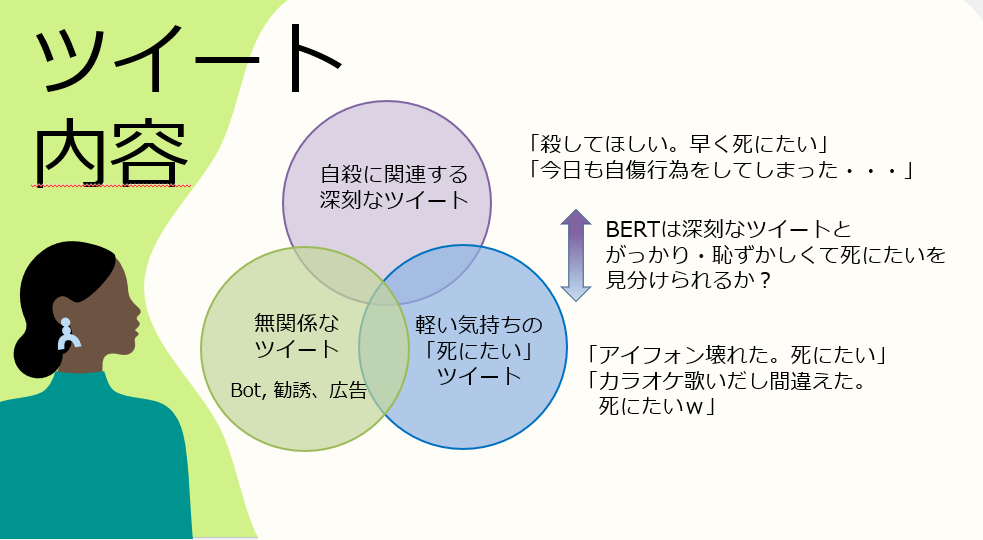
上に挙げた例のように、
①自殺に関連する深刻なツイート
②軽い気持ちの「死にたい」ツイート
③無関係なツイート の3つに大別されました。
ナイーブベイズなどでテキスト分類する際は「死にたい」ワードが入っていたら
②の軽いツイートも否応なく「自殺ツイート」と判別されてしまいますが、
文脈を読み取れるBERTなら①と②を見分けられるかがカギとなります。
「自殺ツイート:1」「自殺でない:0」のラベリング
さて、ここからは集めた4,000件のツイートを1つずつ、「自殺ツイート:1」か「自殺でない:0」を判別していきます。判断基準は以下の通りとしました。

ところが、判断基準を決めたものの、判断に迷うものが多数ありました。
・仕事ミスった。マジで終わった。死にたいいいいいいいいいい。
・ちょっと死にたいかも。
・はよ消えたいわ。
など、ヒトが判断に迷うものは削除することにしました。
↑実はこれが、のちのちのモデル精度に効いてきます。
というのも、ヒトのデータラベリングがぶれていると、AIはもっと判断に困ります。
ヒトが迷うものはAIには判断できません。
ちなみに、ぶれぶれのデータセットを使っていたときはF1スコアが0.27くらいしかありませんでした。判断に迷ったデータを取り除くだけでもF1スコアは0.47まで上がりました。
あと、ラベリング、めちゃ大変でした。5時間くらいかかりました。
日によって判断基準が変わると良くないと思い、ぶっ通しで行いました。
死にたいツイートばかり見ていると、ほんとに心が痛くなります。
train, testデータ作成
データは以下の通りとしました。
train: ラベル付けした自殺ツイート4,000件+無関係なツイート1,500件(天気、離婚のツイート)
test:自殺に関連する正解ツイート100件+無関係なツイート100件(猫のツイート)
ここで無関係なツイートを入れたことがポイントです。
snsclapeで収集した4,000件だけを学習させた場合、あまり精度が良くありませんでした。これは、①自殺に関連する深刻なツイートと②軽い気持ちの「死にたい」ツイートをあまり見分けられていなかったためだと考えます。無関係なツイートを増やしたことで①、②が見分けやすくなったのではと考えています。
データセットの構成で精度が変わるとは・・・知りませんでした。
まとめ
一連のデータセット作成を通して学んだことは、「データセット作成が後々のモデリングを左右する」ということです。そして、データのラベル付けは作成者の思想そのものを反映するものです。本来であれば、複数人でラベル付けをする方が望ましいと思いますが、個人の取り組みのため、モデルが安定してアプリケーションも仕上がったらクラウドソーシングに頼ってみようと思っています。
次回はBERTでのモデリングと苦労した点をまとめてみます。
データのEDAとルールベースでの検出編もまとめてみました。
よかったらご覧ください。