はじめに
セマンティックウェブやアウトラインの明示が重視されている現在、Webページの構造化に触れる機会は増えていることかと思います。
Webページの構造化マークアップを行うにあたって、基本的な情報をまとめているので
- そもそも構造化マークアップって何?
- なんで構造化するの?
- どうやって実装するの?
あたりの疑問を解消できれば幸いです。
そもそも構造化マークアップとは
当然ですが、人間はWebページに記述されている文字や画像から、必要な情報を読み取ります。
これに対してブラウザは、文章や写真の内容が何を表しているのか(HTMLタグからアウトラインは把握できるものの)基本的に理解できません。
しかし、正しく構造化マークアップを行うことでブラウザがWebページの内容を理解することができるようになります。
- 通常のマークアップ:
<h1>株式会社アンティー・ファクトリー</h1>
ブラウザのきもち:h1タグ使われてるから見出しですね、内容まではよくわからないです😐。
- 構造化マークアップ:
<h1 itemscope itemtype="http://schema.org/Corporation">
<span itemprop="name">株式会社アンティー・ファクトリー</span>
</h1>
ブラウザのきもち:h1タグ使われてるから見出しで、内容の「株式会社アンティー・ファクトリー」は会社名なんですね、とてもよくわかります😊。
構造化してあると何がうれしいのか
Googleなどの検索エンジンでは、通常はmetaデータのtitleやdescriptionのみが検索結果として反映されます。
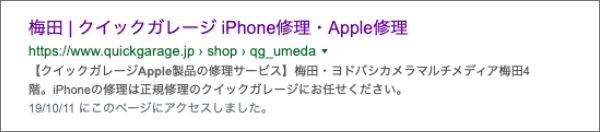
データが構造化されていると、構造化の内容に応じて検索結果をよりいい感じに表示(リッチリザルト)してくれます。
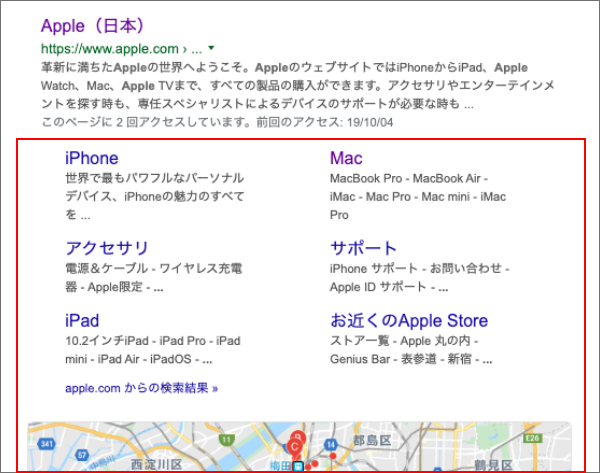
ただし、検索結果に必ずしもリッチリザルトが保証されるわけでは無いです。
構造化マークアップはあくまでブラウザにWebページの内容がどういうものかを伝えているだけで、それらをどう検索結果に反映させるかはブラウザ側に一任されています。
詳しくは公式をご参照ください。
Google Developers 構造化データに関するガイドラインに準拠する
実装方法
実装方法としては以下の三通りがサポートされています。
-
JSON-LD(Google推奨)
scriptタグ内にJSON-LD形式でページの構造や内容を書いていく方法です。
データが一箇所にまとまるのでソースレベルでも読みやすく、マークアップも複雑になりません。 -
Microdata
HTMLタグ内に属性を付与することでデータの構造化を行うことができます。
今回の記事で一番最初に出した会社名の例は、この方法でマークアップされています。 -
RDFa
Microdataと同じように、HTMLタグ内に属性を付与したマークアップを行うことで構造化を行うことができます。Microdataとは使用する属性が少し異なるようですが、この方法が使用されているのはあまり見かけません。
今回は、Google推奨のJSON-LDを使用した方法で構造化を行っていきます。
どういった内容を構造化するのか
基本的には
- どういった意味を持ったデータである、と伝えたいのか(ボキャブラリー)を選択
(例:パンくずリスト、記事データ、レビュー、FAQなどなど) - データの詳細を記述
という内容を明示するようにします。
上記の内容をブラウザが認知できるようにするには、schema.orgで定義されている構造化マークアップの規格に沿った形式で入力する必要があります。
構造化マークアップに使用するJSON-LDデータは、後述する二通りの方法で生成することができます。
例として以下のページを構造化したJSON-LDデータを生成することを考えていきます。
Qiita-スプレッドシートとSlackを連携させてタスク管理botを作る
方法1:構造化マークアップ支援ツールによるJSON-LDデータの生成
方法の一つとして、構造化データ マークアップ支援ツールを使用してJSON-LDデータを生成する方法があります。
WebページのソースやURLを貼り付け、「ここがタイトルでここが内容で、、」というのをブラウザ上で選択していきます。
自分でコードを書かずに簡単かつ素早くできる反面、自動生成できるデータが限られているので、これだけでは細かいカスタマイズはできません。
今回例として構造化するページはは記事ページなので、支援ツールで「記事」を選択し
- どこがタイトルで
- 誰が著者で
- 公開日がいつで
- セクションがどう分かれている
というような情報を選択していきます。
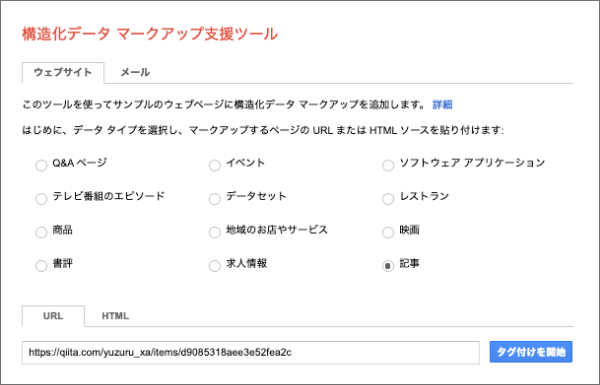
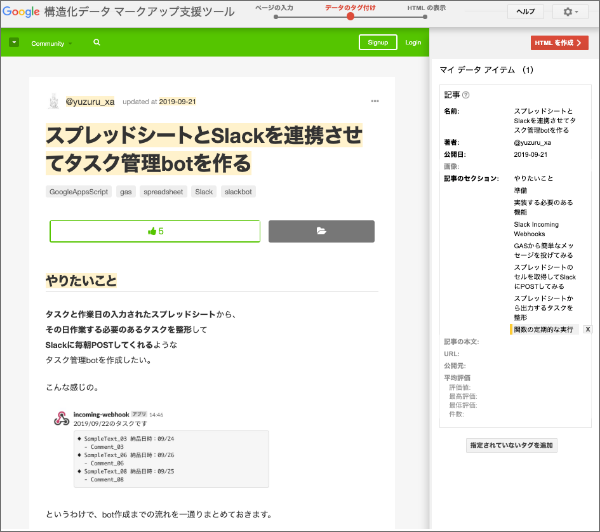
上記情報の選択後、HTMLを生成ボタンを押して生成されたJSON-LDデータが以下のものになります。
<!-- Google 構造化データ マークアップ支援ツールが生成した JSON-LD マークアップです。 -->
<script type="application/ld+json">
{
"@context" : "http://schema.org",
"@type" : "Article",
"name" : "スプレッドシートとSlackを連携させてタスク管理botを作る",
"author" : {
"@type" : "Person",
"name" : "@yuzuru_xa"
},
"datePublished" : "2019-09-21",
"articleSection" : [ "やりたいこと", "準備", "実装する必要のある機能", "Slack Incoming Webhooks", "GASから簡単なメッセージを投げてみる", "スプレッドシートのセルを取得してSlackにPOSTしてみる", "スプレッドシートから出力するタスクを整形", "関数の定期的な実行" ]
}
</script>
データ自体がかなり見やすいので、さっと眺めるだけでもなんとなく「schema.orgで定義されている記事の形式で、著者やセクションをまとめています」ということがわかるかと思います。
このデータを、構造化を行いたいページのHTMLファイルにペーストすれば構造化データマークアップは完了です。
方法2:JSON-LDによる実装
方法1の構造化支援ツールを使用する方法で最終的にやったことは、生成されたJSON-LDデータをHTMLにペーストすることでした。
当然、同じようなJSON-LDデータを自分で記述することで構造化マークアップを行うことも可能です。
構造化マークアップ支援ツールで生成できなくとも、規格に沿ってさえいればデータの構造化できるので、より正確で詳しい構造化を行うことができます。使用できるボキャブラリーの種類はschema.orgをご参照ください。
こちらの方法で構造化マークアップを行うにあたって、浮上した疑問点などはまた別記事にまとめようと思っています。
+α 構造化のチェック
「本当にデータの構造化できているのか」の確認は以下のツールで行うことができます。
構造化データ テストツール
まとめ
はじめにも書いているのですが、検索結果に必ずしもリッチリザルトが保証されるわけでは無いです。
構造化マークアップ自体必ず行う必要のあることでは無いですが、「何もしないよりはされている方が良い」と思っています。
手順はそれほどややこしくないので、興味のある方は一度やってみると良いのではないでしょうか。