AWSのアカウントを取得したので、初心者にも分かりやすそうだった「Amazon Comprehend」を使用してみました!
参考にさせていただいたQiita記事
・【初心者でも使える】AWSが提供する文書解析サービス「Amazon Comprehend」が日本語対応したので触ってみた!
@JJ33 さま
・【Python】🍜ラーメンガチ勢によるガチ勢のための食べログスクレイピング🍜
@toshiyuki_tsutsui さま
Amazon Comprehendとは
Amazon Comprehend は、機械学習を使用してテキスト内でインサイトや関係性を検出する自然言語処理 (NLP) サービスです。機械学習の経験は必要ありません。
Amazon Comprehend(テキストのインサイトや関係性を検出)| AWS より
はじめに
目的
食べログの評価が4.0以上である、超名店鰻屋さんの口コミを分析する。
なぜ鰻屋さんにしたかというと、鰻が好きだからです笑
名店とされる鰻屋さんってあこがれますよね…!
方法
口コミの取得
Python:Beautiful Soupライブラリ
口コミの分析
AWS:Amazon Comprehend
口コミの取得
手順
PythonのBeautiful Soupライブラリ(HTMLやXMLから指定したデータを抽出するためのWEBスクレイピング用ライブラリ)を使用し、食べログの口コミを取得します。
ソースコード
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
import time
class Tabelog:
def __init__(self, base_url, test_mode=False, p_ward='東京都内', begin_page=1, end_page=30):
# 変数宣言
self.store_id = ''
self.store_id_num = 0
self.store_name = ''
self.score = 0
self.ward = p_ward
self.review_cnt = 0
self.review = ''
self.columns = ['store_id', 'store_name', 'score', 'ward', 'review_cnt', 'review']
self.df = pd.DataFrame(columns=self.columns)
self.__regexcomp = re.compile(r'\n|\s') # \nは改行、\sは空白
page_num = begin_page # 店舗一覧ページ番号
if test_mode:
list_url = base_url + str(page_num) + '/?Srt=D&SrtT=rt&sort_mode=1' #食べログの点数ランキングでソートする際に必要な処理
self.scrape_list(list_url, mode=test_mode)
else:
while True:
list_url = base_url + str(page_num) + '/?Srt=D&SrtT=rt&sort_mode=1' #食べログの点数ランキングでソートする際に必要な処理
if self.scrape_list(list_url, mode=test_mode) != True:
break
# INパラメータまでのページ数データを取得する
if page_num >= end_page:
break
page_num += 1
return
def scrape_list(self, list_url, mode):
"""
店舗一覧ページのパーシング
"""
r = requests.get(list_url)
if r.status_code != requests.codes.ok:
return False
soup = BeautifulSoup(r.content, 'html.parser')
soup_a_list = soup.find_all('a', class_='list-rst__rst-name-target') # 店名一覧
if len(soup_a_list) == 0:
return False
if mode:
for soup_a in soup_a_list[:2]:
item_url = soup_a.get('href') # 店の個別ページURLを取得
self.store_id_num += 1
self.scrape_item(item_url, mode)
else:
for soup_a in soup_a_list:
item_url = soup_a.get('href') # 店の個別ページURLを取得
self.store_id_num += 1
self.scrape_item(item_url, mode)
return True
def scrape_item(self, item_url, mode):
"""
個別店舗情報ページのパーシング
"""
start = time.time()
r = requests.get(item_url)
if r.status_code != requests.codes.ok:
print(f'error:not found{ item_url }')
return
soup = BeautifulSoup(r.content, 'html.parser')
# 店舗名称取得
store_name_tag = soup.find('h2', class_='display-name')
store_name = store_name_tag.span.string
print('{}→店名:{}'.format(self.store_id_num, store_name.strip()), end='')
self.store_name = store_name.strip()
# うなぎ屋以外の店舗は除外
store_head = soup.find('div', class_='rdheader-subinfo') # 店舗情報のヘッダー枠データ取得
store_head_list = store_head.find_all('dl')
store_head_list = store_head_list[1].find_all('span')
#print('ターゲット:', store_head_list[0].text)
if store_head_list[0].text not in {'うなぎ','鰻'}:
print('うなぎのお店ではないので処理対象外')
self.store_id_num -= 1
return
# 評価点数取得
rating_score_tag = soup.find('b', class_='c-rating__val')
rating_score = rating_score_tag.span.string
print(' 評価点数:{}点'.format(rating_score), end='')
self.score = rating_score
# 評価点数が存在しない店舗は除外
if rating_score == '-':
print(' 評価がないため処理対象外')
self.store_id_num -= 1
return
# 評価が4.0未満店舗は除外
if float(rating_score) < 4.0:
print(' 食べログ評価が4.0未満のため処理対象外')
self.store_id_num -= 1
return
# レビュー一覧URL取得
#<a class="mainnavi" href="https://tabelog.com/tokyo/A1304/A130401/13143442/dtlrvwlst/"><span>口コミ</span><span class="rstdtl-navi__total-count"><em>60</em></span></a>
review_tag_id = soup.find('li', id="rdnavi-review")
review_tag = review_tag_id.a.get('href')
# レビュー件数取得
print(' レビュー件数:{}'.format(review_tag_id.find('span', class_='rstdtl-navi__total-count').em.string), end='')
self.review_cnt = review_tag_id.find('span', class_='rstdtl-navi__total-count').em.string
# レビュー一覧ページ番号
page_num = 1 #1ページ*20 = 20レビュー 。この数字を変えて取得するレビュー数を調整。
# レビュー一覧ページから個別レビューページを読み込み、パーシング
# 店舗の全レビューを取得すると、食べログの評価ごとにデータ件数の濃淡が発生してしまうため、
# 取得するレビュー数は1ページ分としている(件数としては1ページ*20=20レビュー)
while True:
review_url = review_tag + 'COND-0/smp1/?lc=0&rvw_part=all&PG=' + str(page_num)
#print('\t口コミ一覧リンク:{}'.format(review_url))
print(' . ' , end='') #LOG
if self.scrape_review(review_url) != True:
break
if page_num >= 1:
break
page_num += 1
process_time = time.time() - start
print(' 取得時間:{}'.format(process_time))
return
def scrape_review(self, review_url):
"""
レビュー一覧ページのパーシング
"""
r = requests.get(review_url)
if r.status_code != requests.codes.ok:
print(f'error:not found{ review_url }')
return False
# 各個人の口コミページ詳細へのリンクを取得する
#<div class="rvw-item js-rvw-item-clickable-area" data-detail-url="/tokyo/A1304/A130401/13141542/dtlrvwlst/B408082636/?use_type=0&smp=1">
#</div>
soup = BeautifulSoup(r.content, 'html.parser')
review_url_list = soup.find_all('div', class_='rvw-item') # 口コミ詳細ページURL一覧
if len(review_url_list) == 0:
return False
for url in review_url_list:
review_detail_url = 'https://tabelog.com' + url.get('data-detail-url')
#print('\t口コミURL:', review_detail_url)
# 口コミのテキストを取得
self.get_review_text(review_detail_url)
return True
def get_review_text(self, review_detail_url):
"""
口コミ詳細ページをパーシング
"""
r = requests.get(review_detail_url)
if r.status_code != requests.codes.ok:
print(f'error:not found{ review_detail_url }')
return
# 2回以上来訪してコメントしているユーザは最新の1件のみを採用
soup = BeautifulSoup(r.content, 'html.parser')
review = soup.find_all('div', class_='rvw-item__rvw-comment')#reviewが含まれているタグの中身をすべて取得
if len(review) == 0:
review = ''
else:
review = review[0].p.text.strip() # strip()は改行コードを除外する関数
#print('\t\t口コミテキスト:', review)
self.review = review
# データフレームの生成
self.make_df()
return
def make_df(self):
self.store_id = str(self.store_id_num).zfill(8) #0パディング
se = pd.Series([self.store_id, self.store_name, self.score, self.ward, self.review_cnt, self.review], self.columns) # 行を作成
self.df = self.df.append(se, self.columns) # データフレームに行を追加
return
unagi_review = Tabelog(base_url="https://tabelog.com/tokyo/rstLst/unagi/",test_mode=False, p_ward='東京都内')
# 出力結果をCSVに保存
unagi_review.df.to_csv("output/unagi_reveiw.csv")
口コミが取得された鰻屋さん
・うなぎ魚政
・かぶと
・活鰻の店 つぐみ庵
取得した口コミの一部(うなぎ魚政)

(文章以外の不要な情報は削除しました。)
口コミの分析(うなぎ魚政)
手順
①Amazon Comprehendサービスにアクセス
②サイドバーから「Real-time analysis」を選択
③「input text」に口コミを入力→「Analyze」を押下
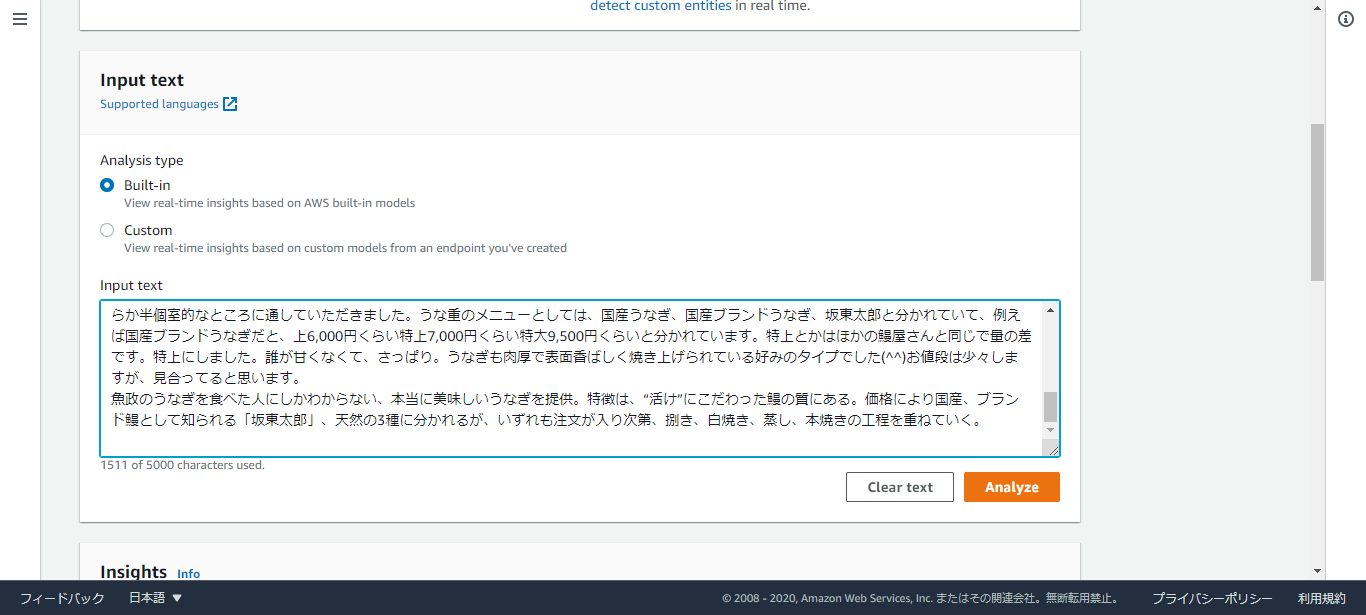
(「テキストデータは5000バイト未満」という制限があるため、オーバーする分は削除し、貼り付けました。)
④結果が表示される
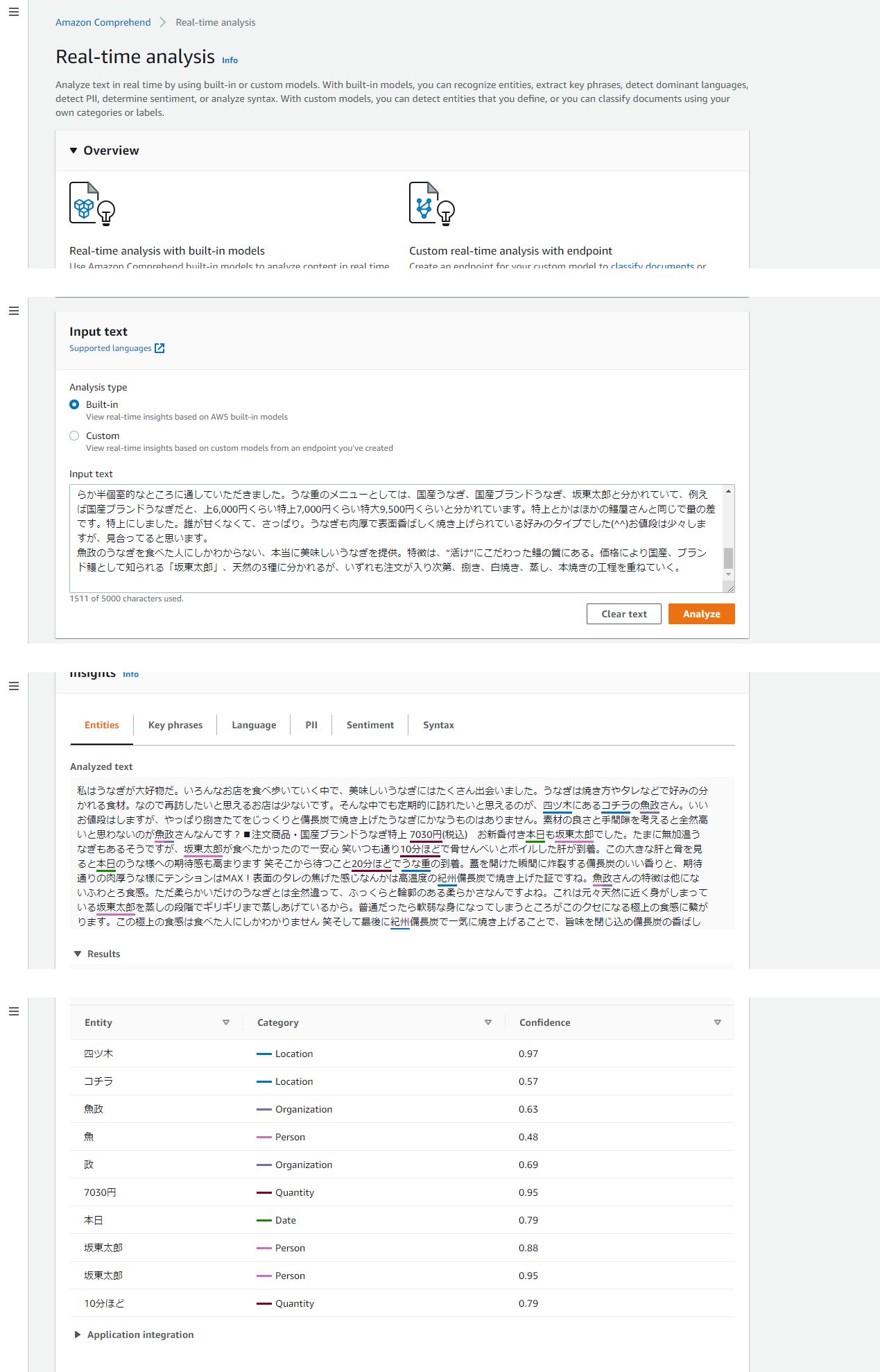
口コミの分析結果(うなぎ魚政)
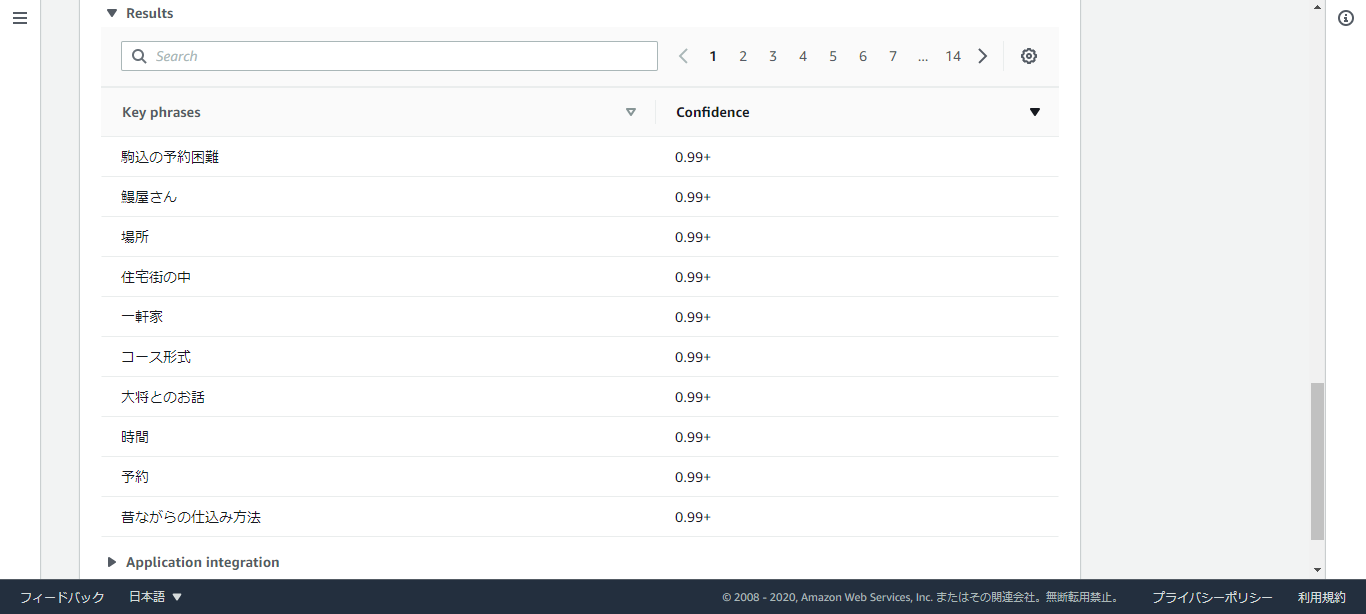
うなぎ魚政さんを例に、口コミの分析結果を紹介します。
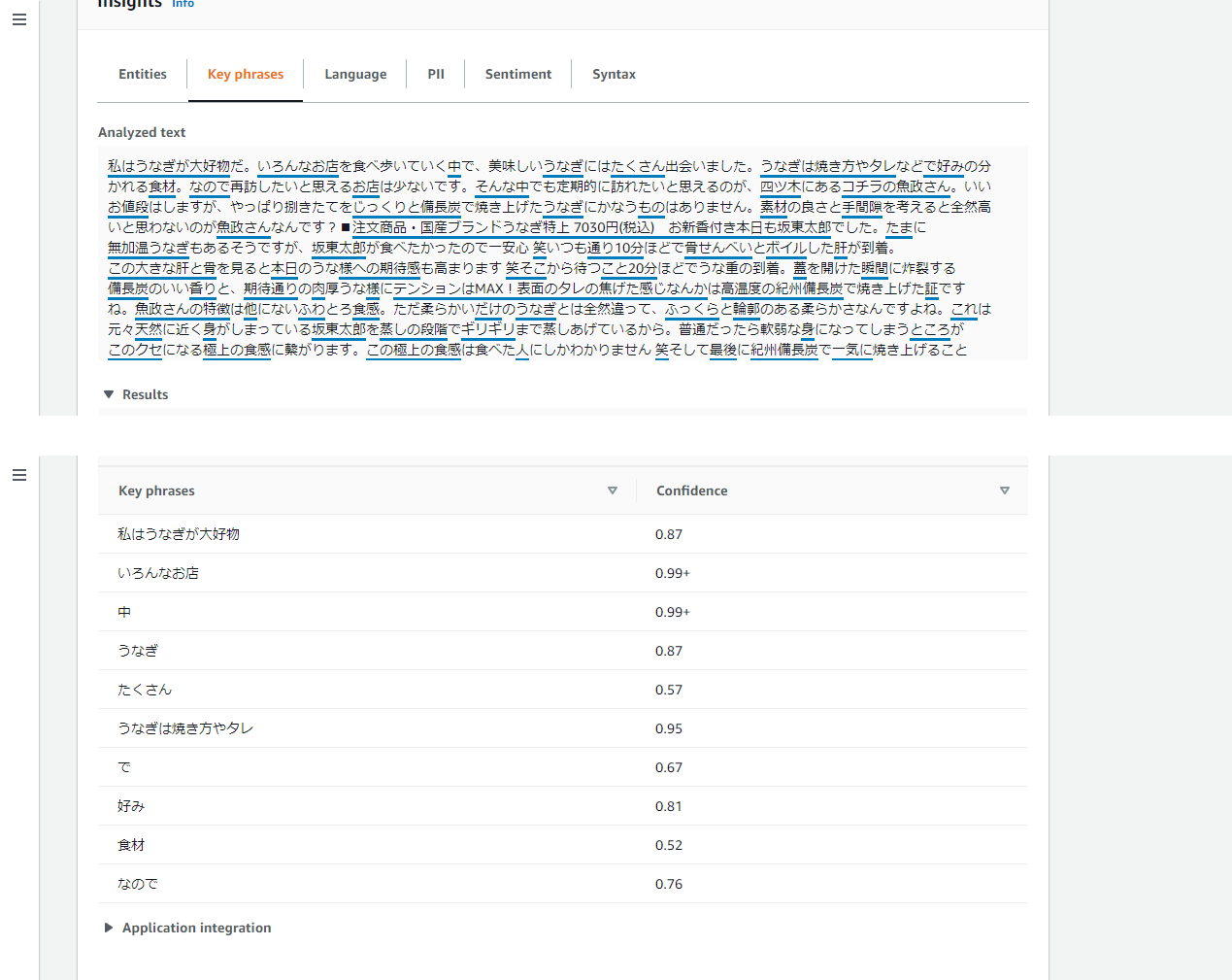
・Key phrases(キーフレーズ抽出)
キーフレーズ抽出 API は、キーフレーズまたは会話のポイント、およびそれがキーフレーズであることを裏付ける信頼性スコアを返します。
・Sentiment(感情分析)
感情分析 API は、テキストの全体的な感情 (肯定的、否定的、中立的、または混在) を返します。
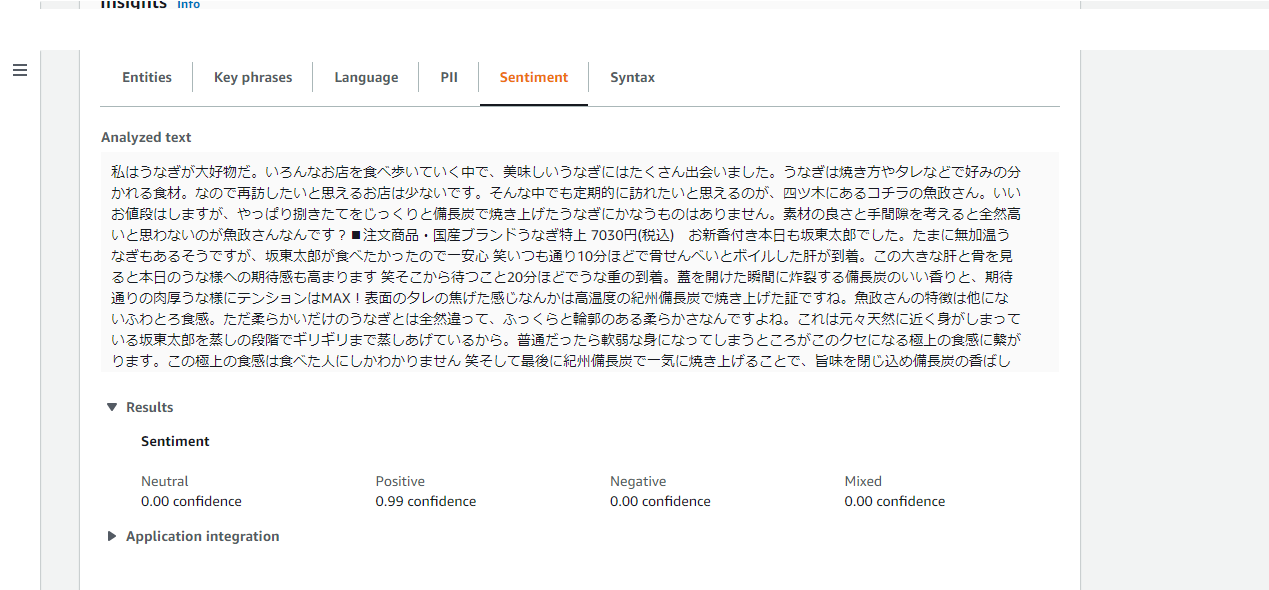
Neutral:中立的
Positive:肯定的
Negative:否定的
Mixed:混在
肯定的のスコアが0.99ってすごいですね!さすがです…。
・Entities(エンティティ認識)
エンティティ認識 API は、提供されたテキストに基づいて自動的に分類される、名前付きエンティティ (「人」、「場所」、「位置」など) を返します。
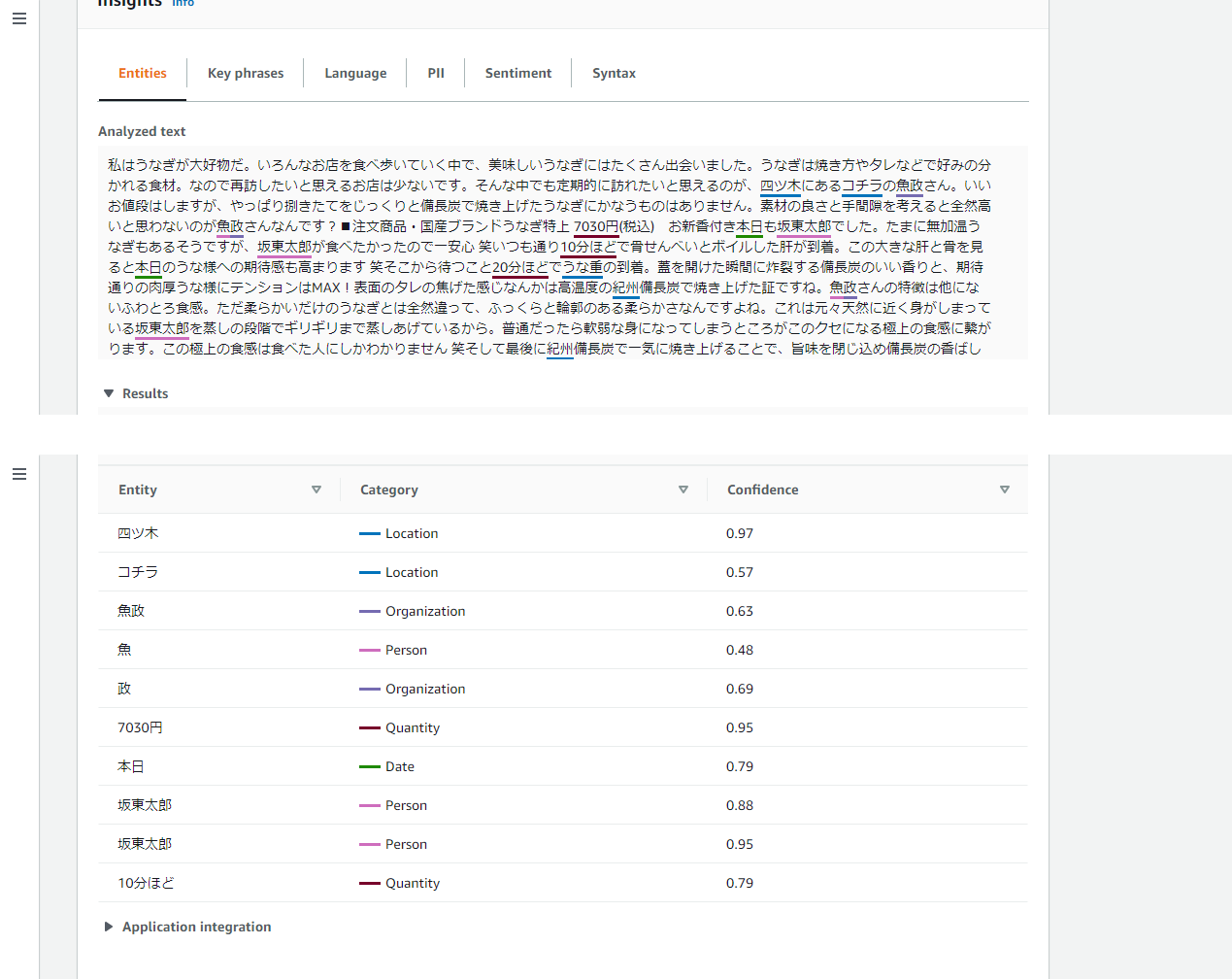
「坂東太郎」というのは、養殖うなぎのブランド名だそうです。
人の名前として認識されていますね笑
・Language(言語検出)
言語検出 API は、100 を超える言語で書かれたテキストを自動的に識別し、主要言語と、言語が主要であることを裏付ける信頼性スコアを返します。
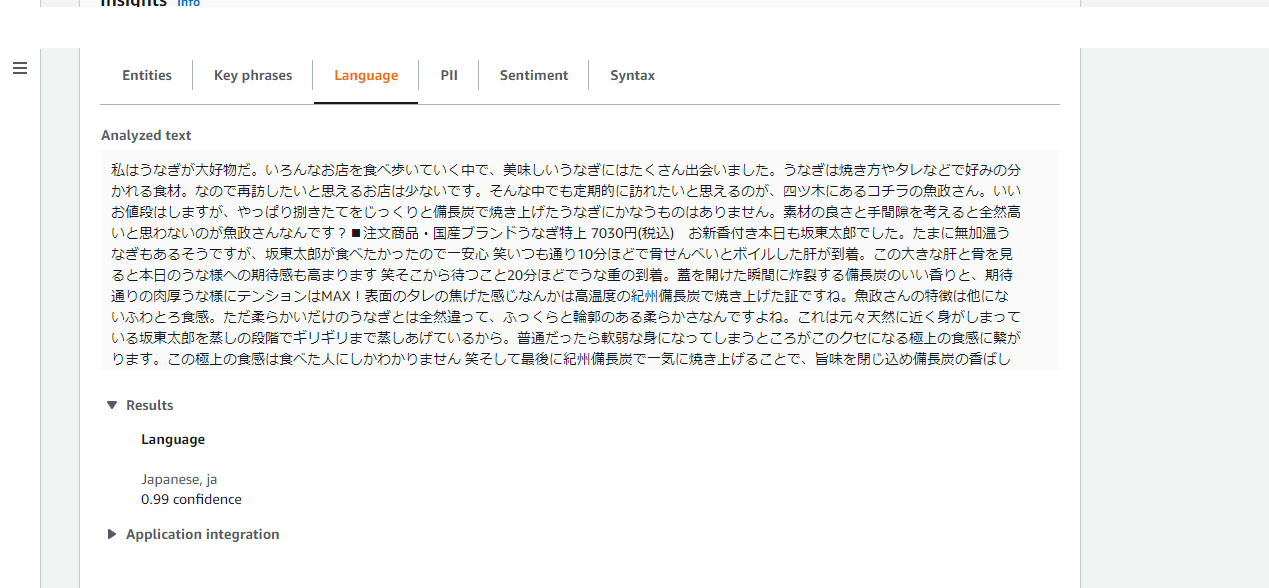
もちろんJapaneseですね。
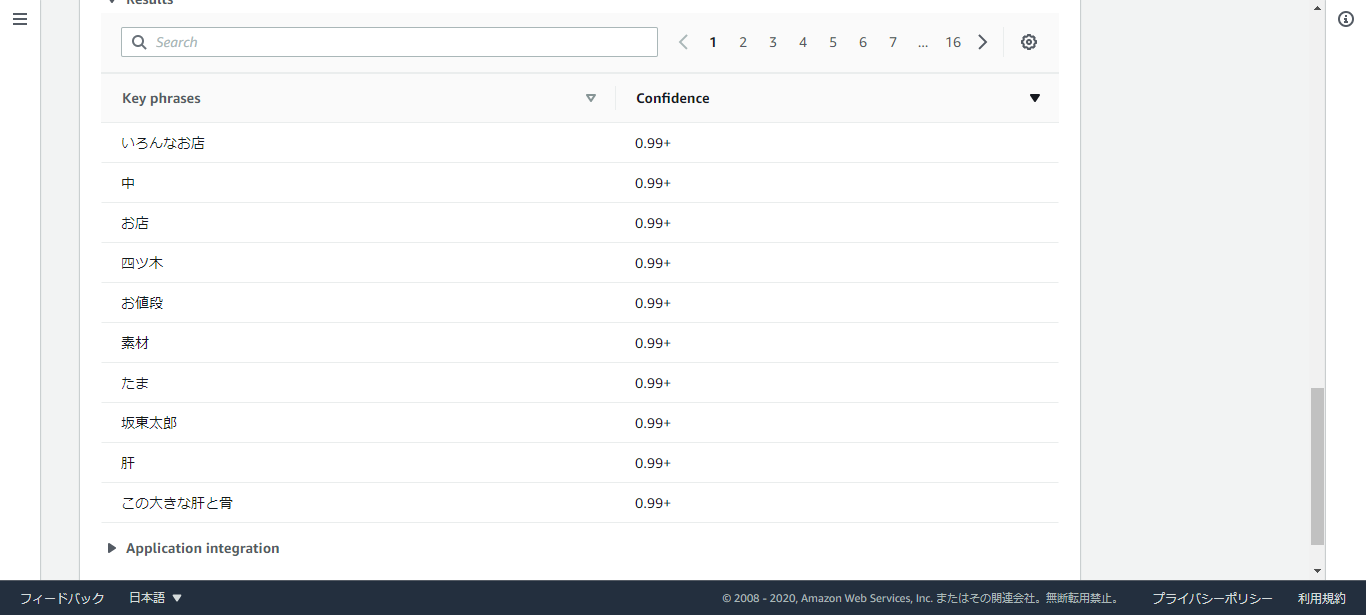
分析結果の比較(キーフレーズ抽出)
口コミ分析結果を、キーフレーズ抽出を例に比較します。
・うなぎ魚政
・かぶと
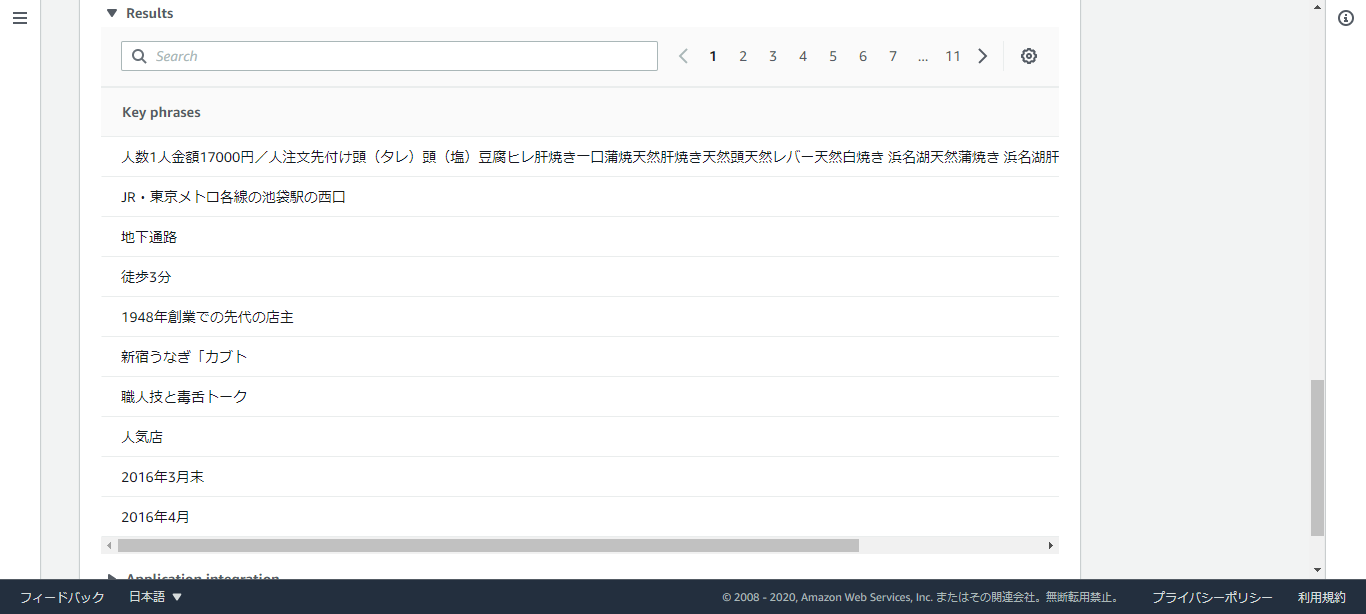
・活鰻の店 つぐみ庵
最後に
今回使用した「Real-time analysis」では、「テキストデータは5000バイト未満」という制限がありました。
次は、「Analysis jobs」(ファイルを指定して文章を分析できる)を使用し、長い文章の分析に挑戦してみます!
本当は今回も「Analysis jobs」でファイルを指定した分析を行いたかったのですが、
Amazon S3に取得したCSVファイルをアップロードし、Amazon Comprehendで参照→実行した結果のファイル内容がよく分からず、断念しました…。(恐らく失敗)
次は、(きちんと結果がでるように)「Analysis jobs」を使用し、長い文章の分析に挑戦してみます…!
また、不手際も多かったのですが、初心者ゆえご容赦いただけますと幸いです![]()