#kaggleのタイタニックコンペで0.808
##1.はじめに
本格的にデータサイエンスの勉強を初めて1ヶ月経ったので、以前挑戦してちんぷんかんぷんだったタイタニックのコンペに再び取り組むことにした。0.8が一つの目安らしいので、それを超えるのを目標とする。タイタニックのコンペとは、タイタニックの沈没の際に乗っていた乗客の生死を予測するコンペのことで、初心者向けらしい。
##2. 特徴量エンジニアリング
まずは基本的なライブラリのインポートとデータの読み込み。
import pandas as pd
import numpy as np
import seaborn as sns
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
gender_submission = pd.read_csv("gender_submission.csv")
データの状態などを確認。
train.head()
train.info()
train.describe()
train.isnull().sum()
test.head()
test.info()
test.describe()
test.isnull().sum()
結果を見てみると、trainにはAge,Cabin,Embarkedにデータの欠損があり、testにはAge,Fare,Cabinにデータの欠損がある。特にAgeとCabinは欠損値が多すぎるので、最終的には特徴量から外すかも。
次に相関などについてみていく。
train_corr = train.corr()
sns.heatmap(train_corr)
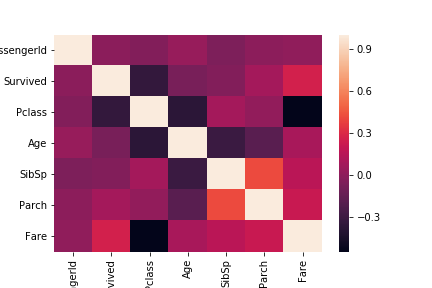
PclassとFareはSurvivedと関係が深そうなので、そこをみていく。
また、タイタニックの事故の際には女性を優先的に助けたそうなので、Sexも重要そうだ。
sns.countplot("Sex",data=train,hue="Survived")
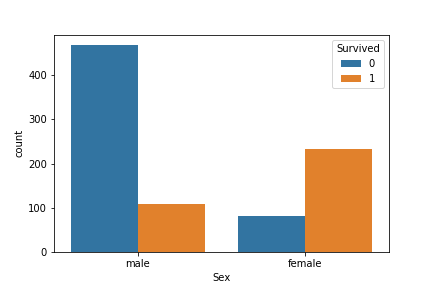
male,femaleの順に並んでいる。やはり女性を優先的に助けていたようだ。生き残った男性と亡くなった女性が気になるので、そこを調べる。
sns.factorplot(x="Pclass",y="Age",data=train,kind="violin",hue="Sex",col="Survived")
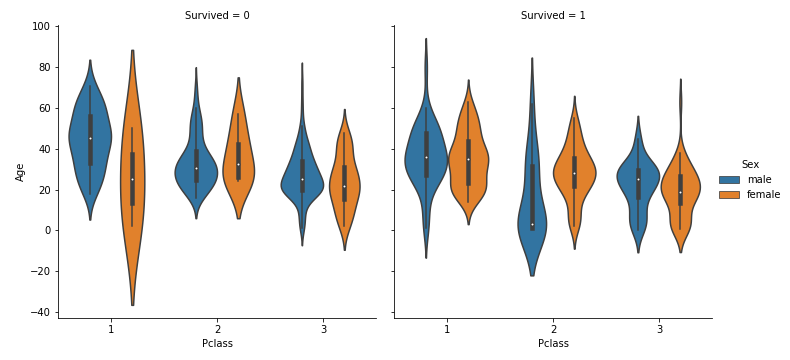
男性は若いほど生き残りやすいことがわかる。しかし、女性についてはよくわからない。
train_died_female = train[train["Survived"]==0]
sns.countplot("Pclass",data=train_died_female)
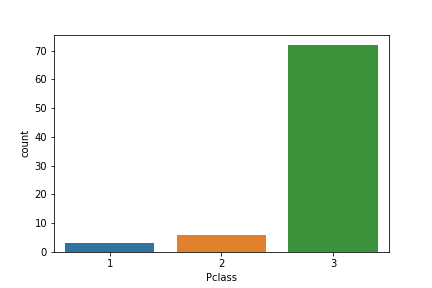
女性で亡くなっているのは、ほとんどPclassが3の人であったようだ。
ここまでのまとめとして、Age,Pclass,SexはSurvivedとかなり関連がある。
しかしAgeには欠損値が多すぎるため、何か方法を考えなければならない。これはカーネルから得た方法だが、Nameを利用する。Nameについて。1行目は、Braund, Mr. Owen Harris
さんだ。この人はMrであるから男性である。同様にみていくと、Mrs,Miss,Master等がある。これを利用すれば、Ageの欠損値問題は解決でき、性別もわかるためSexも特徴量から外すことができる。
for dataset in [train,test]:
dataset["title"] = dataset["Name"].str.split(",",expand=True)[1].str.split(".",expand=True)[0]
少し問題がある。
train["title"].value_counts()
test["title"].value_counts()
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Major 2
Mlle 2
Col 2
Mme 1
Lady 1
Ms 1
Capt 1
the Countess 1
Jonkheer 1
Sir 1
Don 1
Name: title, dtype: int64
Mr 240
Miss 78
Mrs 72
Master 21
Rev 2
Col 2
Ms 1
Dona 1
Dr 1
Name: title, dtype: int64
よくわからない名称がたくさん出てきた。
しょうがないので、少数の名称はすべてexeptionにしてしまう。
for miner_title in [" Dr"," Rev"," Mlle"," Major"," Col"," Ms"," Lady"," Mme"," Capt"," Jonkheer"," the Countess"," Sir"," Don"]:
train["title"] = train["title"].replace(miner_title,"exeption")
for miner_title in [" Dr"," Rev"," Col"," Ms"," Dona"]:
test["title"] = test["title"].replace(miner_title,"exeption")
一応titleについてみてみる。
sns.factorplot("title",data=train,hue="Survived",kind="count")
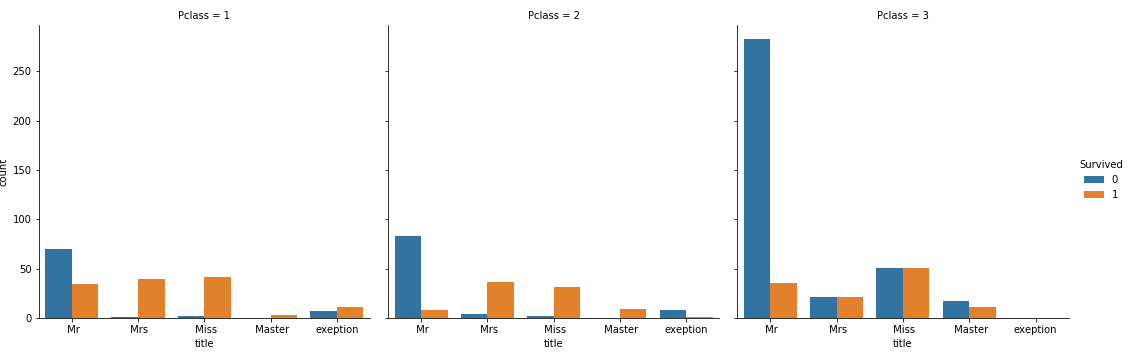
かなりわかりやすくなった。Mrは死者が多いが、Pclassが1のMrは比較的に助かった人も多い。女性でPclassが1か2であればほぼ死ぬことはなく、Pclassが3であると半々で助かる。特徴がよく現れているので、これは特徴量として使うこととする。
sns.jointplot(x="Fare",y="Age",data=train)
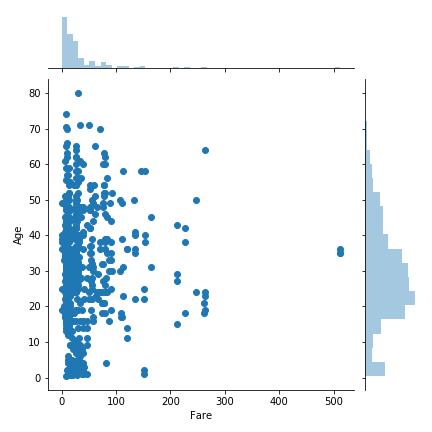
やたらFareの高いひとが3人いた。外れ値なので削除。
train[train["Fare"]>=400]
train = train.drop([258,679,737],axis=0)
testにはEmbarkedの欠損がないため、trainのEmbarkedの欠損値を含むデータを削除。
train[train["Embarked"].isnull()]
train = train.drop([61,829],axis=0)
trainX = train.drop(["Age","Name","Sex","Ticket","Cabin"],axis=1)
testX = test.drop(["Age","Name","Sex","Ticket","Cabin"],axis=1)
すでに使わないことにしたカラムを削除。
test[test["Fare"].isnull()]
testX["Fare"] = testX["Fare"].fillna(round(testX[testX["Pclass"]==3][testX["title"]==" Mr"]["Fare"].mean(),4))
testのFareに一つ欠損があったが、Pclassとtitleが同じ人の平均で補う。
sns.factorplot("SibSp",data=trainX,hue="Survived",kind="count")
sns.factorplot("Parch",data=trainX,hue="Survived",kind="count")
sns.factorplot("Embarked",data=trainX,hue="Survived",kind="count")
SibSp,Parch,Embarkedについてみたが、どれも特徴がでているため使うことにする。
trainX_dum = pd.get_dummies(trainX)
testX_dum = pd.get_dummies(testX)
trainX_dum = trainX_dum.drop(["Embarked_S","title_exeption"],axis=1)
testX_dum = testX_dum.drop(["Embarked_S","title_exeption"],axis=1)
データのダミー変数化とダブりの削除。
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
trainX_dum_std = trainX_dum
testX_dum_std = testX_dum
trainX_dum_std[["Fare","Pclass"]] = ss.fit_transform(trainX_dum[["Fare","Pclass"]])
testX_dum_std[["Fare","Pclass"]] = ss.transform(testX_dum[["Fare","Pclass"]])
trainY = trainX_dum["Survived"]
trainX_dum = trainX_dum.drop("Survived",axis=1)
特徴量をスケーリングし、目的関数を準備。
##3. モデリング
ロジスティック回帰や決定木、ランダムフォレストなど、いろいろ試したがサポートベクターマシンのスコアが最もよかったのでそれを載せておく。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100], 'gamma' : [0.001, 0.01, 0.1, 1, 10, 100]}
X_train, X_test, y_train, y_test = train_test_split(trainX_dum_std, trainY, random_state=0)
grid_search = GridSearchCV(SVC(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
グリッドサーチをして、
これを提出したところ、0.794だった。このときのパラメータは、C:100,gamma:0.01。
ここからは手作業だが、C:250,gamma:0.01 で0.8086をとれた。
##4. 結果
目標を達成することはできた。しかし、カーネルをみているとLightGBMなどのアンサンブル系を使っている人が多く、まだスコアを伸ばす余地はあると思う。SibSpとParchを合わせてfamily_sizeを作ることもできるようだが、今回はしていない。
##5. 参考文献
主にこのカーネルを参考にした。
https://www.kaggle.com/ldfreeman3/a-data-science-framework-to-achieve-99-accuracy