1. はじめに
- 前回Google Cloud AI Platform、What-if Toolを使ってみた①の続きです。
- What-if Toolで何が見れるかを記載します。
2. What-if Tool を使ってモデルを解釈する
Step 1: 個別データポイントの探索
デフォルトではDatapoint editorタブが表示されています。各データをクリックすると個別の特徴が見えます。複数データの特徴を見ることで各データがモデルにどのように影響を与えているかが確認できます。
1つデータを選んで、特徴量の値を変更して、Run Inferenceをクリックしてみます。
agency_code_Department of Housing and Urban Development (HUD)を試しに0から1に変更してみましょう。
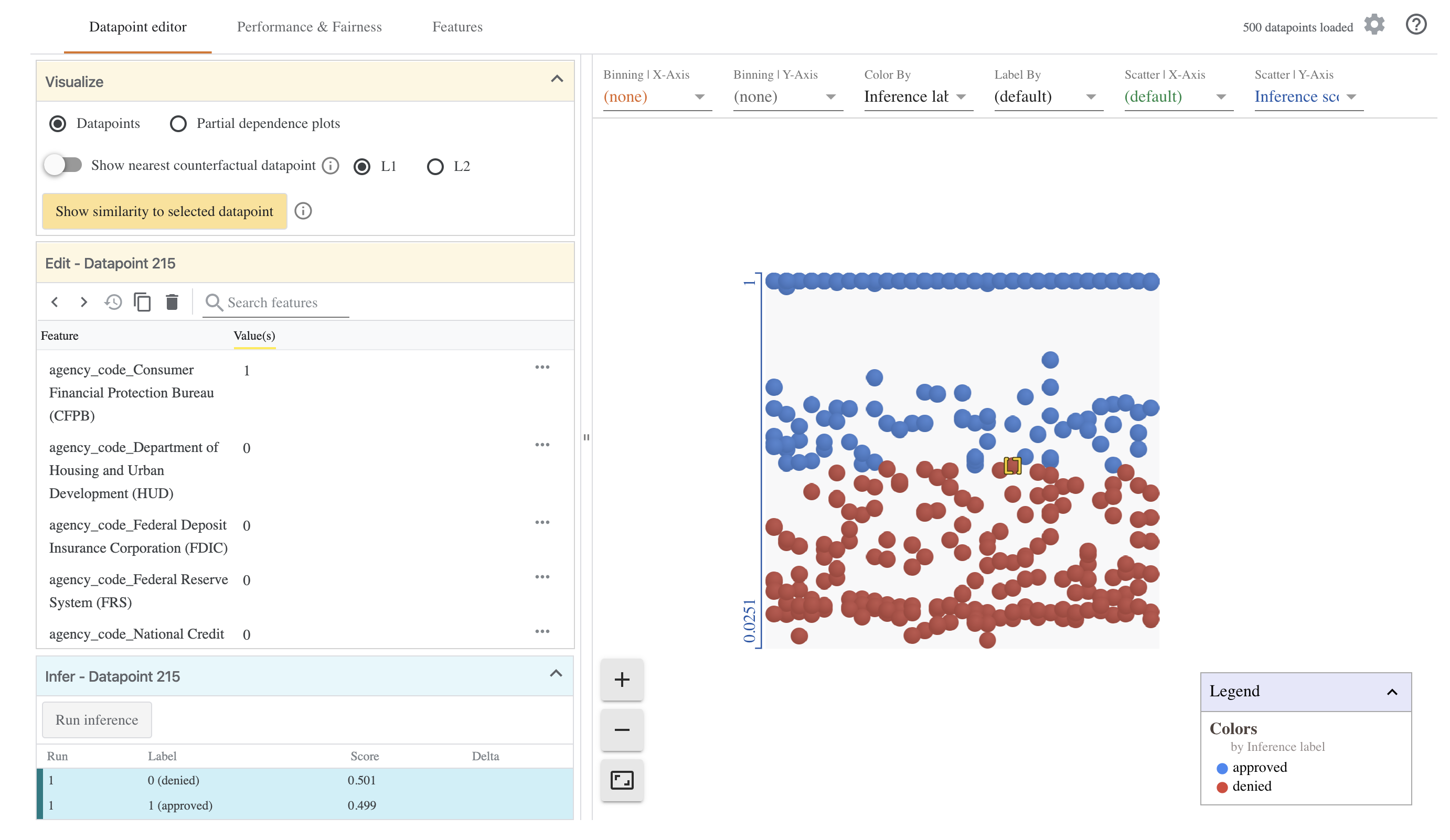
モデルの承認予測値が変化します。これで特徴量がどのくらい予測モデルに影響を与えているかがわかります。
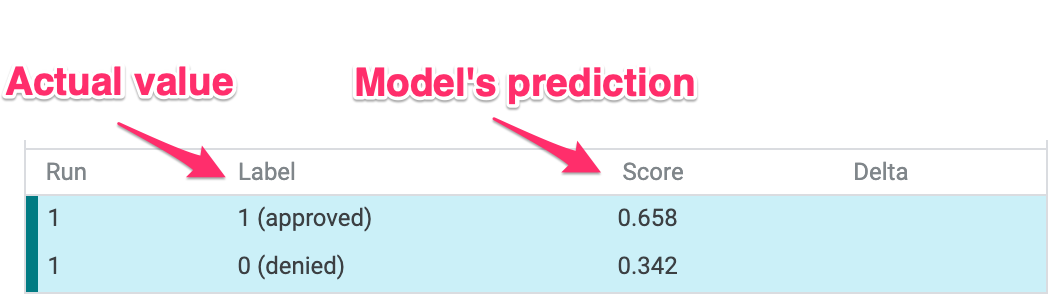
左下のUIからそれぞれの予測スコアを見ることができます。

Step 2: 反事実分析
データポイントを選択して、Show nearest counterfactual datapointスライダーを右にスライドさせましょう。
最も似ている特徴量を持ち、反対の予測値を示すデータポイントが表示されます。2つの差分を理解できます。
Step 3: 部分変数重要度
それぞれの特徴量が予測モデルにどのように影響するか見るために、Partial dependence plotsをチェックし、Global partial dependence plotsを選択します。

HUDからのローンは否認される確率がわずかに高いことがわかります。
application_income_thousandsは数値特徴量です。200kドルまでは収入が多いほど承認されやすいことがわかります。200kドルより高い場合は、モデルの予測に影響を与えていないことがわかります。
Step 4: 性能と公平性の探索
Performance & Fairnessタブを開きます。混同行列、PR曲線とROC曲線を含むモデルの性能統計結果をみられます。
mortgage_statusを選択し、混同行列を見ます。

混同行列はモデルの正解・不正解の予測を示します。
ローンのapprovedを予測する前に、閾値のスライダーを使って、分類スコアの変動を確認できます。この場合、閾値が0.55の時accuracyが最大になります。
loan_purpose_Home_purchaseを選択します。

"0" は住宅用のローン、"1"はそれ以外のローンであることを示します。false positiveとfalse negativeの値に差があることを確認できます。
画面を展開すると混同行列が表示されます。住宅ローンの場合は70%が承認されていると予測し、それ以外のローンでは46%が承認されていると予測しています。

Demographic parityを選択すると、2つの閾値が調整され、2つのスライスが同じくらいの割合でapprovedと予測されるようになります。
Step 5: 特徴量の分布
What-if ToolのFeatureタブでは特徴量それぞれの分布が見られます。

偏りをみましょう。