言語モデリングにおけるRNN
The Unreasonable Effectiveness of Recurrent Neural Networks[1]の中でCharacter-Level Language Modelingを用いてRNN(LSTM,GRU)のハイパーパラメータ比較がされている。
Character-Level Language Modelingとは
原文
We’ll train RNN character-level language models. That is, we’ll give the RNN a huge chunk of text and ask it to model the probability distribution of the next character in the sequence given a sequence of previous characters. This will then allow us to generate new text one character at a time.
日本語訳(Google翻訳)
RNNの文字レベルの言語モデルを習得します。 つまり、RNNに大量のテキストを与え、シーケンス内の次の文字の確率分布を前の文字列でモデル化するよう依頼します。 これにより、一度に1文字ずつ新しいテキストを生成することができます。
比較結果
Leo Tolstoy’s War and Peace (WP) novelとthe source code of the Linux Kernel (LK)の2つのデータセットを用いて比較を行った結果が下図。
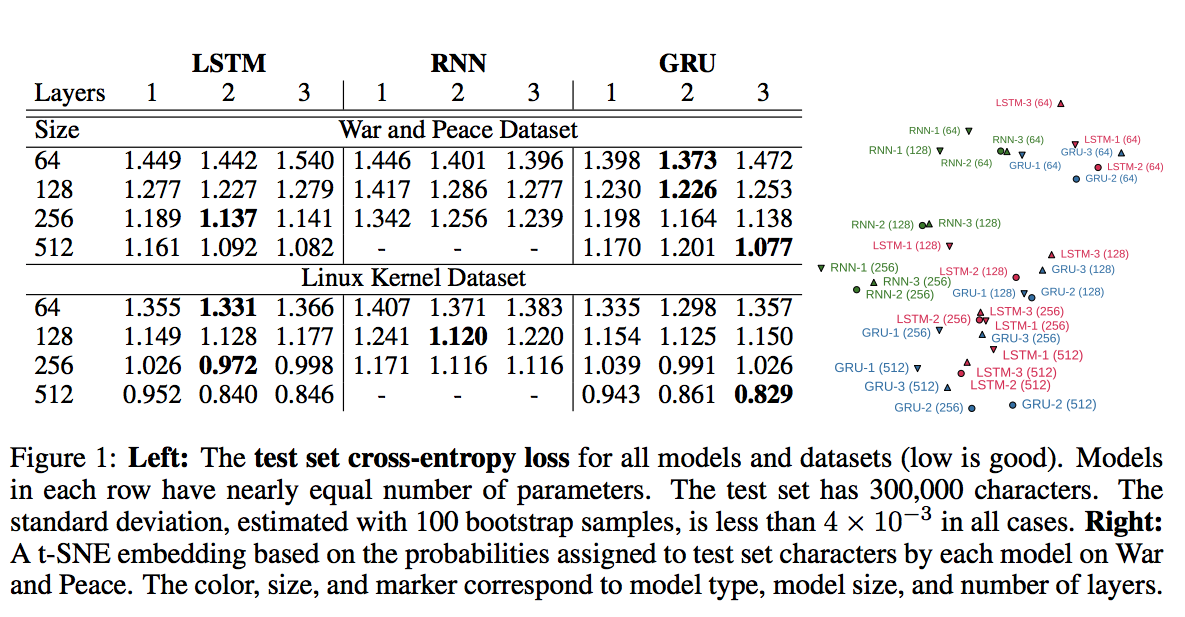
- 3層よりも2層のほうが優れた結果を出している
- LSTMとGRUがRNNよりも優れている
- 右図からLSTMとGRUが同様の予測をしていて、RNNは独自の予測をしているとわかる
- LSTMとGRUは、データセットによって結果が異なる
LSTMとGRUのどちらが優れているか一概にはいえないので、自分のデータセットで試してみることが大事と言える。
音声認識におけるRNN
Neural Speech Recognizer: Acoustic-to-Word LSTM Model for Large Vocabulary Speech Recognition[2]の中でNeural Speech RecognizerをテーマとしたのRNNハイパーパラメータが紹介されている。
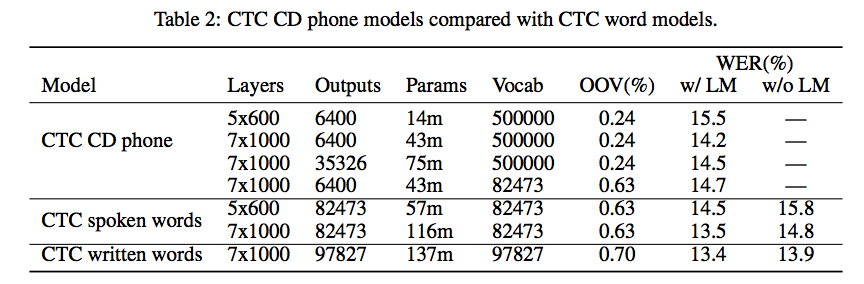
音声認識では5層または7層の結果がよかったよう。
まとめ
どのようなハイパーパラメータを用いてネットワークを構成したらよいかは一概には言えないので、自分の行うタスクに類似した先行研究の結果を参考にいろいろ試すべき。
参考文献
[1] Visualizing and Understanding Recurrent Networks by Andrej Karpathy, Justin Johnson, Li Fei-Fei
[2] Neural Speech Recognizer: Acoustic-to-Word LSTM Model for Large Vocabulary Speech Recognition by Hagen Soltau, Hank Liao, Hasim Sak