生配信されたプレゼンでひろゆきさんの真似をして、信じられないくらいすべりました。。。
はじめに
hackdayに初参加して一週間がたちました。
自分の学んだことの整理として、記事を描こうと思い立ち、いつもお世話になっているQiitaの記事を頑張って書いてみようと思いました。
初めて書くのでわかり辛い部分、不完全な部分あると思いますがお手柔らかによろしくお願いします。
目次
製作物の概要
発表当日が緊急事態宣言がされた日ということもあり、皮肉も込めて電車通勤体験キットを作りました。
具体的にはつり革を自宅に設置し、映像と連携しながら通勤を体験できるというものです。
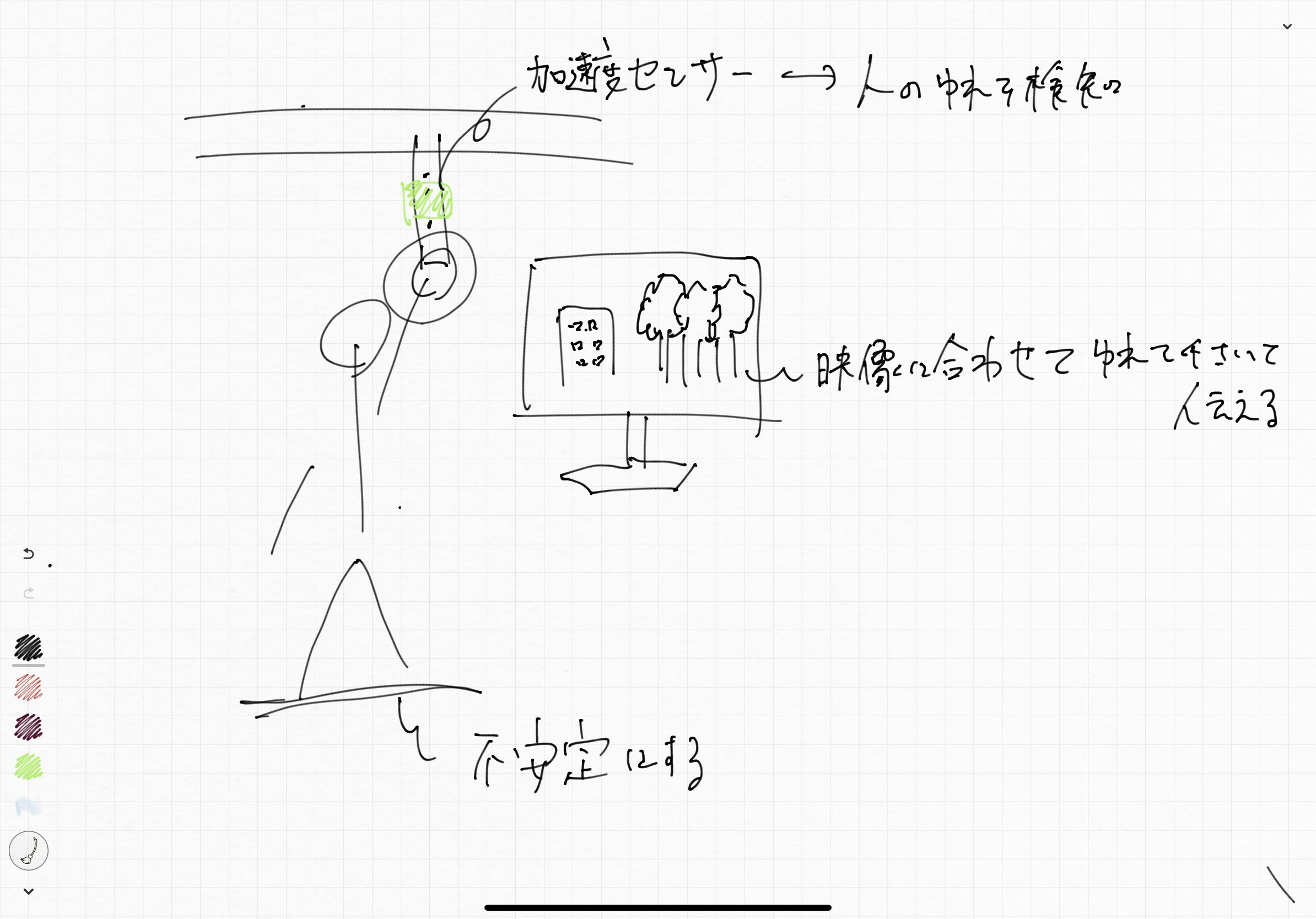
今回紹介する技術
実装のなかで映像(車窓の風景)からある程度の加速度を予測するということをしました。
今回はその紹介をさせていただきます。
アイデアとしては動画から一定時間ごとに静止画を抽出し、時間的に隣会う画像の類似度を求め、それを速度に見立てて加速度を推測するというものです。
類似度が高い→あまり移動がない→遅い
類似度が低い→結構移動している→早い
今回求めたいのは加速度なので、類似度がどのように変化しているかに注目して大まかな加速度を推測しました。
動画から静止画を抽出
extract_images.py
import cv2
import os
def save_all_frames(video_path, dir_path, basename, ext='jpg'):
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
return
os.makedirs(dir_path, exist_ok=True)
base_path = os.path.join(dir_path, basename)
digit = len(str(int(cap.get(cv2.CAP_PROP_FRAME_COUNT))))
n = 0
while True:
ret, frame = cap.read()
if ret:
cv2.imwrite('{}_{}.{}'.format(base_path, str(n).zfill(digit), ext), frame)
n += 1
print(n)
else:
return
save_all_frames('video_path', 'dir_path', 'sample_video_img')
save_all_frames('video_path', 'dir_path', 'sample_video_img', 'png')
video_path = 'video_path'
dir_path = 'output_path'
save_all_frames(video_path, dir_path, 'train')
記事を参考にしているので、中枢の部分は参考文献をご参照ください。
この後の都合のために保存するファイル名を変えるくらいの変更をしました。
類似度を推測
hist_matching.py
import cv2
import os
def add_zeros(path_number):
if (len(path_number) == 1):
return '000' + path_number
elif (len(path_number) == 2):
return '00' + path_number
elif (len(path_number) == 3):
return '0' + path_number
else:
return path_number
IMG_DIR = os.path.abspath(os.path.dirname(__file__)) + 'data_path'
IMG_SIZE = (200, 200)
temp = 0
for i in range(6901):
# print(i)
j = i + 1
i = str(i)
j = str(j)
i = add_zeros(i)
j = add_zeros(j)
target_img_path = IMG_DIR + 'train_' + i + '.jpg'
target_img = cv2.imread(target_img_path)
target_img = cv2.resize(target_img, IMG_SIZE)
target_hist = cv2.calcHist([target_img], [0], None, [256], [0, 256])
comparing_img_path = IMG_DIR + 'train_' + j + '.jpg'
# print('FILE: %s : %s' % ('train_' + i + '.jpg', 'train_' + j + '.jpg'))
comparing_img = cv2.imread(comparing_img_path)
comparing_img = cv2.resize(comparing_img, IMG_SIZE)
comparing_hist = cv2.calcHist([comparing_img], [0], None, [256], [0, 256])
ret = cv2.compareHist(target_hist, comparing_hist, 0)
# print(file, ret)
print(ret - temp)
temp = ret
記事を参考にしているので、中枢の部分は参考文献をご参照ください。
データのファイル名を変えるくらいの変更をしました。
いや、先頭のゼロ埋めしてくれる関数の存在は知ってたんですが、なんかうまくいかなくて自作しました、、、
類似度を推測
analysis.py
import matplotlib.pyplot as plt
import time
y = []
input_file = open('speed.txt', 'r', encoding = 'utf_8')
i = 0
while True:
line = input_file.readline()
if line:
i += 1
y.append(1 - float(line))
time.sleep(0.33)
print(1 - float(line))
else:
break
# RGBごとのヒストグラム計算とプロット
for i, channel in enumerate(colors):
histgram = cv2.calcHist([img_a], [i], None, [256], [0, 256])
plt.plot(histgram, color=channel)
plt.xlim([0, 256])
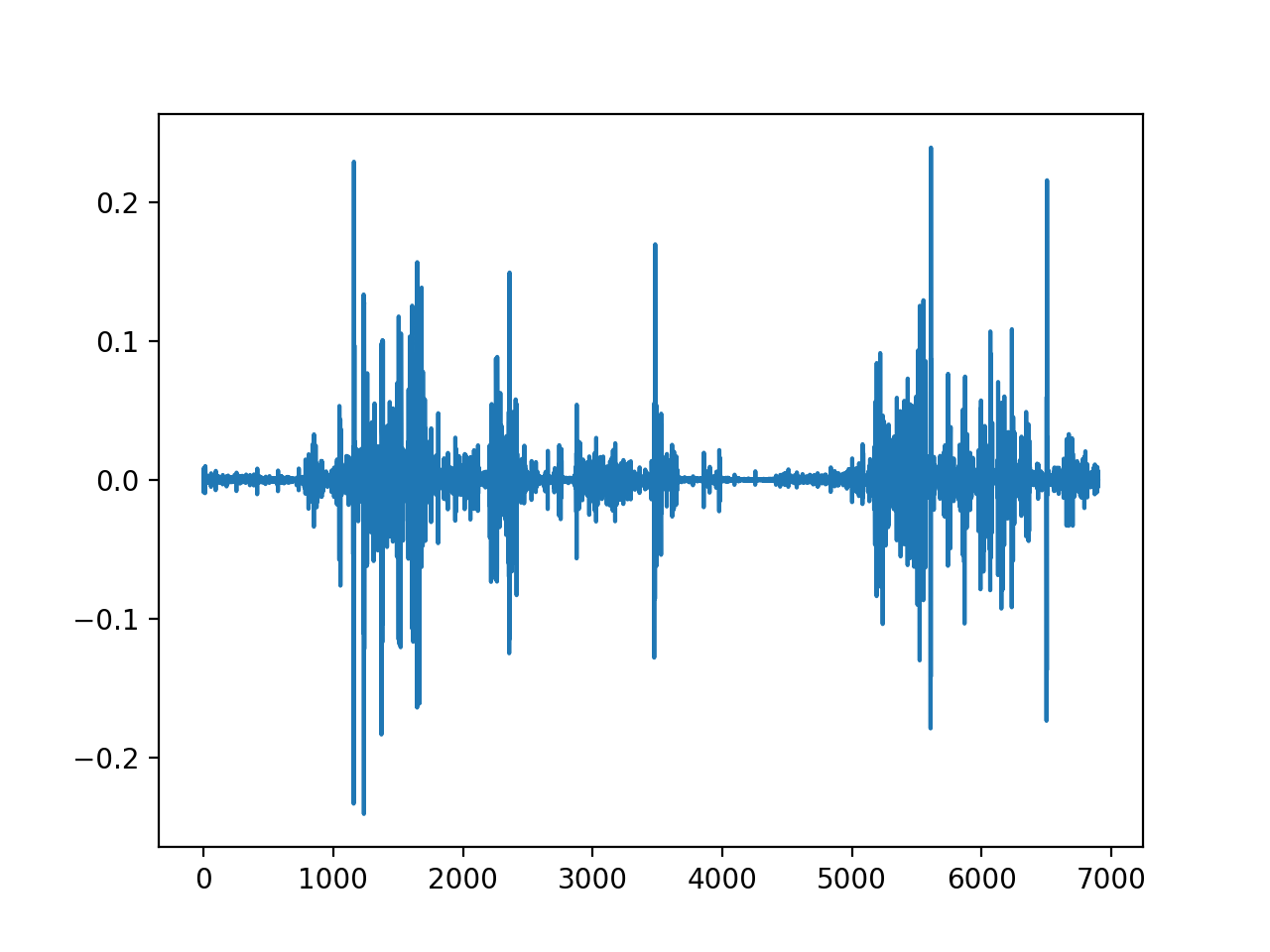
出てきたグラフと映像を見比べるといい感じで一番興奮した瞬間でした。
製作物(実際のプレゼン)
もう少し技術力があれば、、、(反省)
- 映像とグラフを比較すると実際には止まっているのに速度変化があると認識している部分があります。(動画2:30,グラフx:3500くらい)
原因は止まっている時に向かい側の電車が出発して類似度に変化があったことです。 - 加速度の向きも求めたかったなと思っています。
- プレゼンふざけすぎて一番大事な技術を伝えられなかった。