きっかけ
現在、SEOライティングツールを開発する株式会社EXIDEAで、データ分析のインターンをしています。勤め始めて4ヶ月経ちましたが、コロナの影響で社内の方とまだ一度も面識がありません。が、定期的なオンライン飲み会やデイリーミーティングでどういった特徴を持った方が多いのか?ようやくわかってきました。また、最近の月次ミーティングで「採用」という言葉をよく耳にします。ベンチャー企業に限らず、Wantedlyを利用して採用活動に力を入れている企業は多いのではないでしょうか?この記事では、Wantedlyに投稿したストーリー記事を自然言語の可視化を手軽にできるようにしたパッケージnlplotを使用して、応募者に伝えたい企業特徴や想いを再認識しようというストーリーになります。
Githubにソースコードを公開していますので、よかったらどうぞ。
https://github.com/yuuuusuke1997/Article_analysis
環境
- macOS
- Python 3.7.6
- Jupyter Notebook
- zshシェル
ストーリーの流れ
1. データの収集(スクレイピング)
1-1.スクレイピングの流れ
今回のスクレイピングは、以下のようにwebページを遷移して自社の全記事のみを取得していきます。スクレイピングするにあたり、Wantedlyさんに事前に許可をいただいた上で実施させていただきます。予めご了承いただけますようお願いいたします。

1-2. 事前準備
Wantedlyのwebページはページ下部までスクロールすることで次の記事が読み込まれます。そのため、ブラウザ操作を自動化するSeleniumを必要最低限の箇所で使用し、データの取得を行います。ブラウザを操作するには、お使いのブラウザに対応したdriverの用意とSeleniumライブラリをインストールする必要があります。私は、Google Chromeを愛用しているのでこちらからChromeDriverをダウンロードし、下記のディレクトリに配置しました。なお、Users配下の*はご自身のユーザー名に適宜変更してください。
$ cd /Users/*/documents/nlplot
$ ls
article_analysis.ipynb
chromedriver
post_articles.csv
user_dic.csv
Seleniumライブラリはpipでインストールします。
$ pip install selenium
Seleniumの導入から操作方法まで詳しく知りたい方は、こちらの記事が参考になるかと思います。準備が整ったので、実際にスクレイピングしていきます。
1-3. ソースコード
import json
import re
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs4
from selenium import webdriver
base_url = 'https://www.wantedly.com'
def scrape_path(url):
"""
ストーリー一覧ページからスペース詳細ページのURLを取得する
Parameters
--------------
url: str
ストーリー一覧ページのURL
Returns
----------
path_list: list of str
スペース詳細ページのURLを格納したリスト
"""
path_list = []
response = requests.get(url)
soup = bs4(response.text, 'lxml')
time.sleep(3)
# <script data-placeholder-key="wtd-ssr-placeholder"> の中身を取得
# json文字で、先頭の'//'を除去するため.string[3:]
feeds = soup.find('script', {'data-placeholder-key': 'wtd-ssr-placeholder'}).string[3:]
feed = json.loads(feeds)
# {'body'}の'spaces'を取得
feed_spaces = feed['body'][list(feed['body'].keys())[0]]['spaces']
for i in feed_spaces:
space_path = base_url + i['post_space_path']
path_list.append(space_path)
return path_list
path_list = scrape_path('https://www.wantedly.com/companies/exidea/feed')
def scrape_url(path_list):
"""
スペース詳細ページからストーリー詳細ページのURLを取得する
Parameters
--------------
path_list: list of str
スペース詳細ページのURLを格納したリスト
Returns
----------
url_list: list of str
ストーリー詳細ページのURLを格納したリスト
"""
url_list = []
# chromeを起動(chromedriverはこのファイルと同じディレクトリに配置)
driver = webdriver.Chrome('chromedriver')
for feed_path in path_list:
driver.get(feed_path)
# ページ下部までスクロールして、これ以上スクロールできなくなったらプログラム終了
# スクロール前の高さ
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# ページ下部までスクロール
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
# Seleniumの処理が速すぎて、新たなページを読み込めないので強制待機
time.sleep(3)
# スクロール後の高さ
new_height = driver.execute_script("return document.body.scrollHeight")
# last_heightがnew_heightの高さと一致するまでスクロール
if new_height == last_height:
break
else:
last_height = new_height
continue
soup = bs4(driver.page_source, 'lxml')
time.sleep(3)
# <div class="post-space-item" >の要素を取得
post_space = soup.find_all('div', class_='post-content')
for post in post_space:
# <"post-space-item">の<a>要素を取得
url = base_url + post.a.get('href')
url_list.append(url)
url_list = list(set(url_list))
# webページを閉じる
driver.close()
return url_list
url_list = scrape_url(path_list)
def get_text(url_list, wrong_name, correct_name):
"""
ストーリー詳細ページからテキストを取得する
Parameters
--------------
url_list: list of str
ストーリー詳細ページのURLを格納したリスト
wrong_name: str
間違った社名
correct_name: str
正しい社名
Returns
----------
text_list: list of str
ストーリーを格納したリスト
"""
text_list = []
for url in url_list:
response = requests.get(url)
soup = bs4(response.text, 'lxml')
time.sleep(3)
# <section class="article-description" data-post-id="○○○○○○">の中の<p>要素を全取得
articles = soup.find('section', class_='article-description').find_all('p')
for article in articles:
# 区切り文字で分割
for text in re.split('[\n!?!?。]', article.text):
# 前処理
replaced_text = text.lower() # 小文字変換
replaced_text = re.sub(wrong_name, correct_name, replaced_text) # 社名を大文字に変換
replaced_text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', '', replaced_text) # URLを除去
replaced_text = re.sub('[0-9]', '', replaced_text) # 数字を除外
replaced_text = re.sub('[,:;-~%()]', '', replaced_text) # 記号を半角スペースに置き換え
replaced_text = re.sub('[、:;・〜%()※「」【】(笑)]', '', replaced_text) # 記号を半角スペースに置き換え
replaced_text = re.sub(' ', '', replaced_text) # \u3000を除去
text_list.append(replaced_text)
text_list = [x for x in text_list if x != '']
return text_list
text_list = get_text(url_list, 'exidea', 'EXIDEA')
取得したテキストはCSVファイルに保存します。
df_text = pd.DataFrame(text_list, columns=['text'])
df_text.to_csv('post_articles.csv', index=False)

2. 形態素解析(MeCab)
形態素解析までの流れ
- MeCab本体のインストールと環境設定
- IPA辞書の追加
- NEologd辞書の追加
- ユーザー辞書の作成
- ようやく解析
少しばかり休憩
ここからMeCabのインストールや諸々の準備に入るのですが、思った以上に上手くいかず心が折れるので、モチベーションアップに繋がれば幸いです。
そもそも、なんでこんなめんどくさい作業をするんだ。$ brew install mecabと叩けば一発で済むだろうと思う方も、もしかしたらいらっしゃるかもしれません。が、nlplotで形態素解析した結果を思い通りに出すためには、会社特有の事業部名や社内ワードを固有名詞として、文字コードをUTF-8でユーザー辞書に登録する必要があります。私は楽をしたくbrewでインストールした結果、文字コードがEUC-JPになってしまい、二度手間を踏むハメになりました。そのため、出力結果にこだわりたい方は、これから行う方法を是非試してみてください。
一旦、手軽に試してみたいという方は、下記を参考にbrewでインストールしてみてください。
MacにMeCabを利用できる環境を整える
*追記
brewで文字コードを指定する方法をご存知の方がいらっしゃいましたら、コメント欄にてご教授いただけますと幸甚です。
2-1. MeCab本体のインストールと環境設定
MeCab公式サイトから、curlコマンドでMeCab本体とIPA辞書をダウンロードします。なお、今回はローカル環境にインストールします。まずはMeCab本体のインストールです。
# ローカル環境にmecab本体のインストール先ディレクトリを作成
$ mkdir /Users/*/opt/mecab
$ cd /Users/*/opt/mecab
# カレントディレクトリに-oオプションでファイル名を指定してダウンロード
$ curl -Lo mecab-0.996.tar.gz 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE'
# ソースコードファイルを解凍
$ tar zxfv mecab-0.996.tar.gz
$ cd mecab-0.996
# 文字コードをUTF-8に指定してコンパイルできるかチェック
$ ./configure --prefix=/Users/*/opt/mecab --with-charset=utf-8
# configureで作成されたMakefileをコンパイル
$ make
# インストール前に正常に作動するかチェック
$ make check
# makeでコンパイルされたバイナリファイルを/Users/*/opt/mecabにインストール
$ make install
Done
configure, make, make installって何と疑問に思う方は、こちらが参考になるかと思います。
インストールできたので、mecabコマンドを実行できるようにpathを通していきます。
# シェルの種類を確認
$ echo $SHELL
/bin/zsh
# .zshrcにパスを追加
$ echo 'export PATH=/Users/*/opt/mecab/bin:$PATH' >> ~/.zshrc
"""
注意: ログインシェルによって、最後の(~/.zshrc)を変更
例) $ echo 'export PATH=/Users/*/opt/mecab/bin:$PATH' >> ~/.bash_profile
"""
# シェルの設定を反映
$ source ~/.zshrc
# パスが通ったか確認
$ which mecab
/Users/*/opt/mecab/bin/mecab
Done
参考記事: PATHを通すとは?
2-2. IPA辞書の追加
# 起点となるディレクトリに移動
$ cd /Users/*/opt/mecab
# カレントディレクトリに-oオプションでファイル名を指定してダウンロード
$ curl -Lo mecab-ipadic-2.7.0-20070801.tar.gz 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM'
# ソースコードファイルを解凍
$ tar zxfv mecab-ipadic-2.7.0-20070801.tar.gz
$ cd mecab-ipadic-2.7.0-20070801
# 文字コードをUTF-8に指定してコンパイルできるかチェック
$ ./configure --prefix=/Users/*/opt/mecab --with-charset=utf-8
# configureで作成されたMakefileをコンパイル
$ make
# makeでコンパイルされたバイナリファイルを/Users/*/opt/mecabにインストール
$ make install
Done
# 文字コードの確認
# 文字コードがEUC-JPの場合、UTF-8に変更
$ mecab -P | grep config-charset
config-charset: EUC-JP
# 設定ファイルを検索
$ find /Users -name dicrc
/Users/*/opt/mecab/mecab-ipadic-2.7.0-20070801/dicrc
$ vim /Users/*/opt/mecab/mecab-ipadic-2.7.0-20070801/dicrc
【変更前】config-charset = EUC-JP
【変更後】config-charset = UTF-8
$ mecab
おれは人間をやめるぞ!ジョジョーッ
おれ 名詞,代名詞,一般,*,*,*,おれ,オレ,オレ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
人間 名詞,一般,*,*,*,*,人間,ニンゲン,ニンゲン
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
やめる 動詞,自立,*,*,一段,基本形,やめる,ヤメル,ヤメル
ぞ 助詞,終助詞,*,*,*,*,ぞ,ゾ,ゾ
! 記号,一般,*,*,*,*,!,!,!
ジョジョーッ 名詞,固有名詞,組織,*,*,*,*
EOS
# IPA辞書のディレクトリ確認
$ find /Users -name ipadic
/Users/*/opt/mecab/lib/mecab/dic/ipadic
2-3. NEologd辞書の追加
# 起点となるディレクトリに移動
cd /Users/*/opt/mecab
# ソースコードをgithubからダウンロード
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ cd mecab-ipadic-neologd
# 実行して結果を確認する画面で「yes」と入力
$ ./bin/install-mecab-ipadic-neologd -n
Done
# 文字コードの確認
# 文字コードがEUC-JPの場合、UTF-8に変更
$ mecab -d /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd -P | grep config-charset
config-charset: EUC-JP
# 設定ファイルを検索
$ find /Users -name dicrc
/Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd/dicrc
$ vim /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd/dicrc
【変更前】config-charset = EUC-JP
【変更後】config-charset = UTF-8
# NEologd辞書のディレクトリ確認
$ find /Users -name mecab-ipadic-neologd
/Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd
$ echo “おれは人間をやめるぞ!ジョジョーッ | mecab -d /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd
“ 記号,括弧開,*,*,*,*,“,“,“
おれは人間をやめるぞ! 名詞,固有名詞,一般,*,*,*,おれは人間をやめるぞ!,オレハニンゲンヲヤメルゾ,オレワニンゲンオヤメルゾ
ジョジョーッ 名詞,一般,*,*,*,*,*
EOS
Github公式: mecab-ipadic-neologd
# 最後にpython3でmecabを使用できるようにpip
$ pip install mecab-python3
2-4. ユーザー辞書の作成
ユーザー辞書は、システム辞書で対応できなかった単語をユーザー自身が意味を与え作成します。
まずは、追加したい単語をフォーマットに従ってcsvファイルを作成します。一度可視化して、気になった単語があればcsvファイルに単語を追加してみてください。
"""
フォーマット
表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音
"""
# csvファイル作成
$ echo 'インターン生,-1,-1,1,名詞,一般,*,*,*,*,*,*,*,インターンセイ'"\n"'コアバリュー,-1,-1,1,名詞,一般,*,*,*,*,*,*,*,コアバリュー'"\n"'ミートアップ,-1,-1,1,名詞,一般,*,*,*,*,*,*,*,ミートアップ' > /Users/*/Documents/nlplot/user_dic.csv
# csvファイルの文字コードを確認
$ file /Users/*/Documents/nlplot/user_dic.csv
/users/*/documents/nlplot/user_dic.csv: UTF-8 Unicode text
次に、作成したcsvファイルをユーザ辞書にコンパイルします。
# ユーザー辞書の保存先ディレクトリを作成
$ mkdir /Users/*/opt/mecab/lib/mecab/dic/userdic
"""
-d システム辞書があるディレクトリ
-u ユーザ-辞書の保存先
-f CSVファイルの文字コード
-t ユーザ辞書の文字コード/csvファイルの保存先
"""
## ユーザー辞書を作成
/Users/*/opt/mecab/libexec/mecab/mecab-dict-index \
-d /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd \
-u /Users/*/opt/mecab/lib/mecab/dic/userdic/userdic.dic \
-f utf-8 -t utf-8 /Users/*/Documents/nlplot/user_dic.csv
# userdic.dicができていることを確認
$ find /Users -name userdic.dic
/Users/*/opt/mecab/lib/mecab/dic/userdic/userdic.dic
mecabのインストールからユーザー辞書の作成まで完了したので、形態素解析に移ります。
参考記事: 単語の追加方法
2-5. ようやく解析
まずは、スクレイピング時に作成したcsvファイルを読み込みます。
df = pd.read_csv('post_articles.csv')
df.head()

nlplotでは、文章を単語単位で出力したいので、名詞で形態素解析を行います。
import MeCab
def download_slothlib():
"""
SlothLibを読み込み、ストップワードを作成
Returns
----------
slothlib_stopwords: list of str
ストップワードを格納したリスト
"""
slothlib_path = 'http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt'
response = requests.get(slothlib_path)
soup = bs4(response.content, 'html.parser')
slothlib_stopwords = [line.strip() for line in soup]
slothlib_stopwords = slothlib_stopwords[0].split('\r\n')
slothlib_stopwords = [x for x in slothlib_stopwords if x != '']
return slothlib_stopwords
stopwords = download_slothlib()
def add_stopwords():
"""
stopwordsにストップワードを追加
Returns
----------
stopwords: list of str
ストップワードを格納したリスト
"""
add_words = ['ご覧', '社', '是非', 'ぜひ', 'お話', '弊社', '人間', 'いただき', '記事', '以外', 'ん', 'の', 'め', 'さ', 'こう']
stopwords.extend(add_words)
return stopwords
stopwords = add_stopwords()
def tokenize_text(text):
"""
形態素解析をして名詞のみを抽出
Parameters
--------------
text: str
dataframeに格納したテキスト
Returns
----------
nons_list: list of str
形態素解析して名詞のみを格納したリスト
"""
# ユーザー辞書とneologd辞書が保存されたディレクトリを指定
tagger = MeCab.Tagger(
'-d /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd -u /Users/*/opt/mecab/lib/mecab/dic/userdic/userdic.dic')
node = tagger.parseToNode(text)
nons_list = []
while node:
if node.feature.split(',')[0] in ['名詞'] and node.surface not in stopwords:
nons_list.append(node.surface)
node = node.next
return nons_list
df['words'] = df['text'].apply(tokenize_text)
df.head()

3. 可視化(nlplot)
3-1. 事前準備
$ pip install nlplot
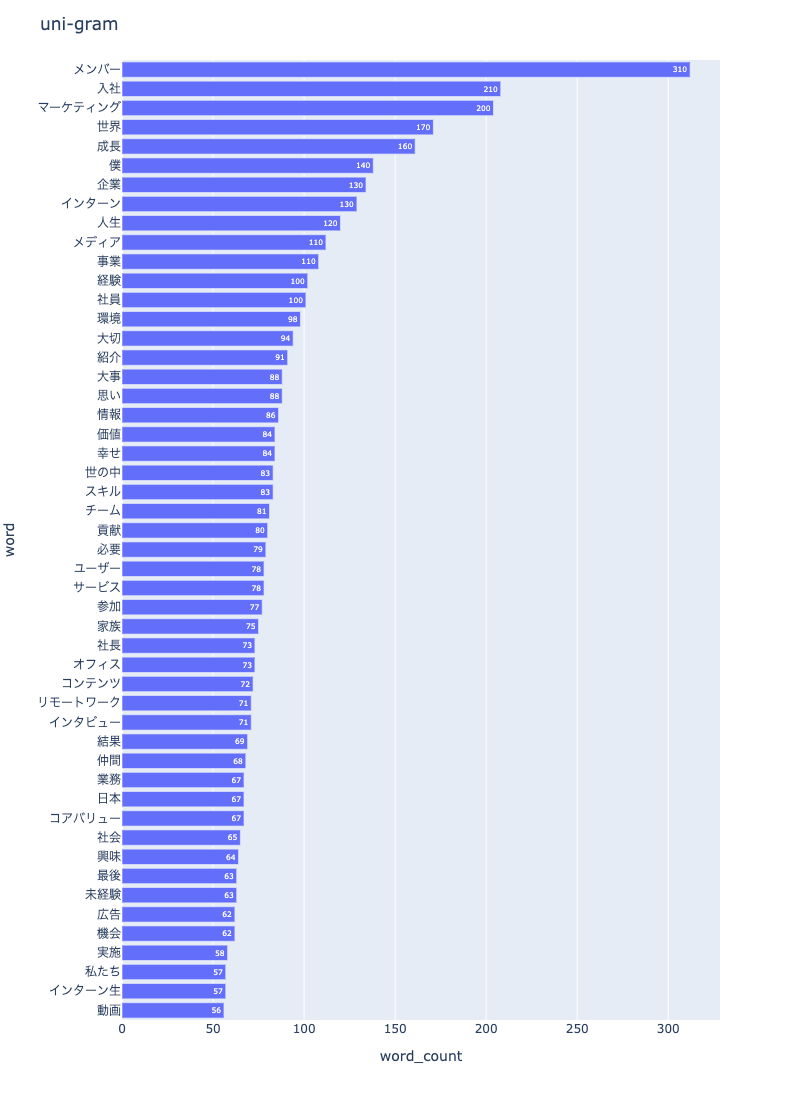
3-2. uni-gram
import nlplot
npt = nlplot.NLPlot(df, taget_col='words')
# top_nで頻出上位2単語, min_freqで頻出下位単語を指定
# 上位2単語: ['会社', '仕事']
stopwords = npt.get_stopword(top_n=2, min_freq=0)
npt.bar_ngram(
title='uni-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=1,
top_n=50,
stopwords=stopwords,
save=True
)
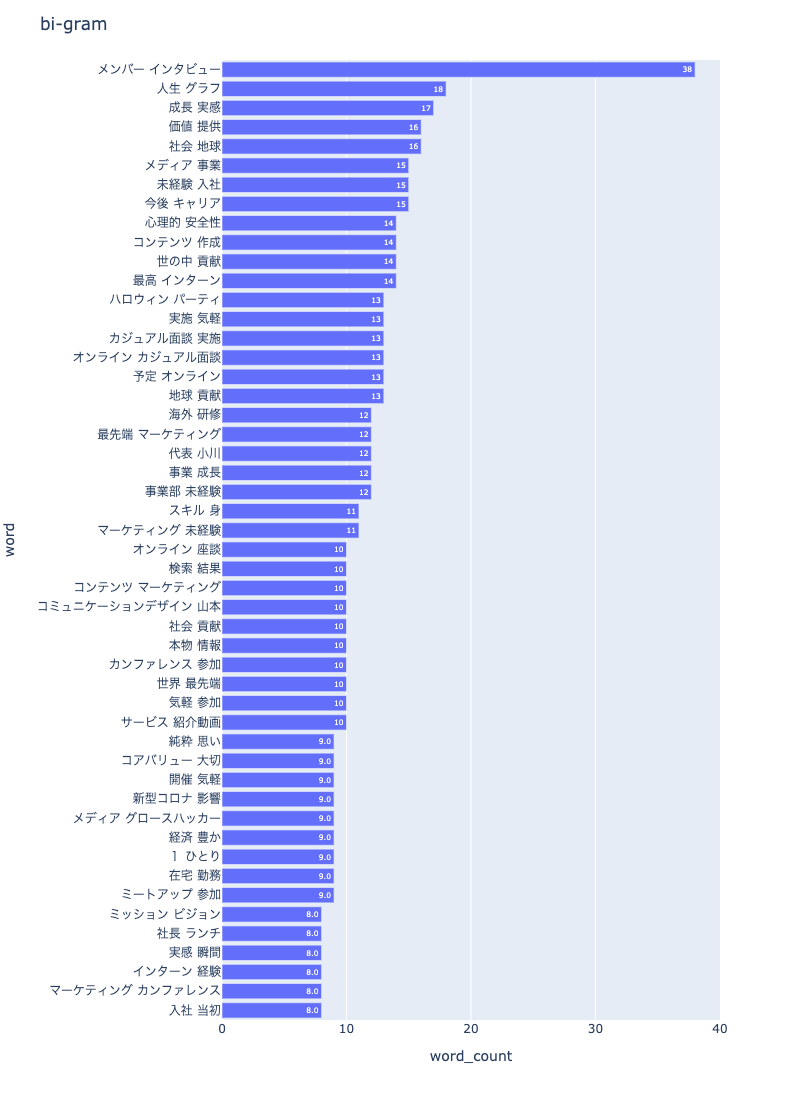
3-3. bi-gram
npt.bar_ngram(
title='bi-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=2,
top_n=50,
stopwords=stopwords,
save=True
)
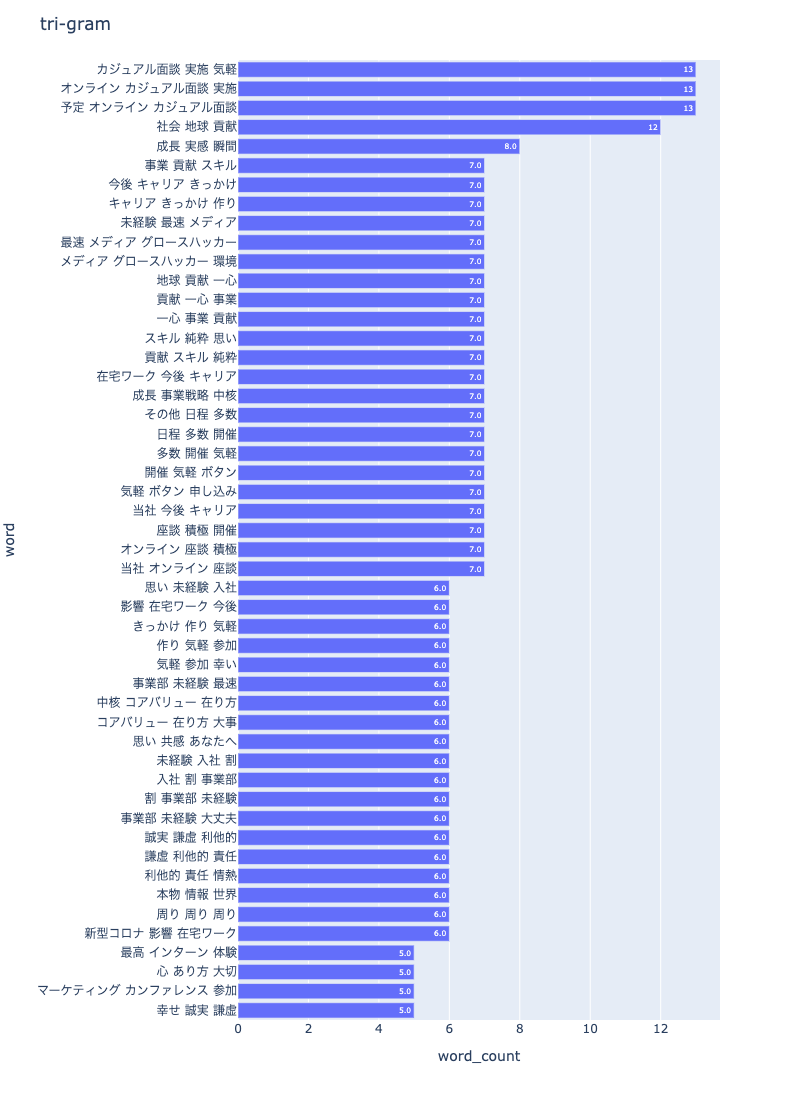
3-4. tri-gram
npt.bar_ngram(
title='tri-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=3,
top_n=50,
stopwords=stopwords,
save=True
)
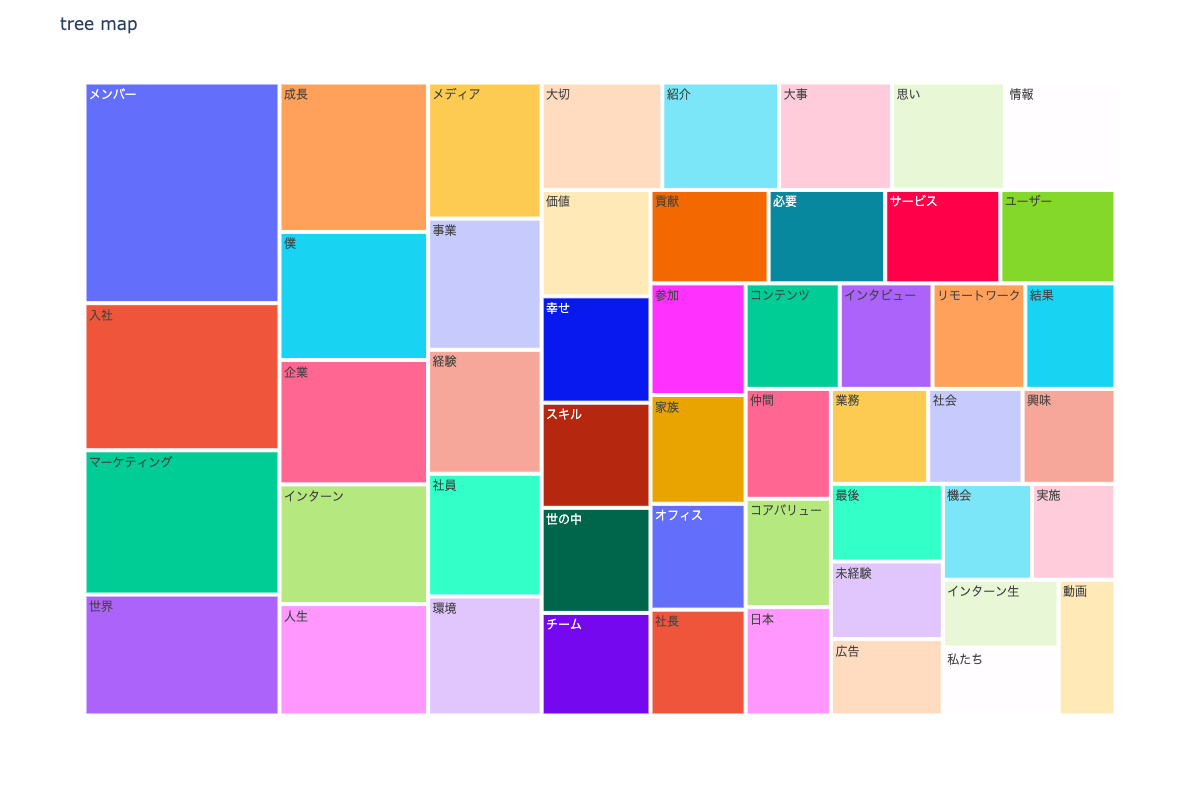
3-5. tree map
npt.treemap(
title='tree map',
ngram=1,
stopwords=stopwords,
width=1200,
height=800,
save=True
)
3-6. wordcloud
npt.wordcloud(
stopwords=stopwords,
max_words=100,
max_font_size=100,
colormap='tab20_r',
save=True
)

3-7. 共起ネットワーク
npt.build_graph(stopwords=stopwords, min_edge_frequency=13)
display(
npt.node_df, npt.node_df.shape,
npt.edge_df, npt.edge_df.shape
)
npt.co_network(
title='All sentiment Co-occurrence network',
color_palette='hls',
save=True
)
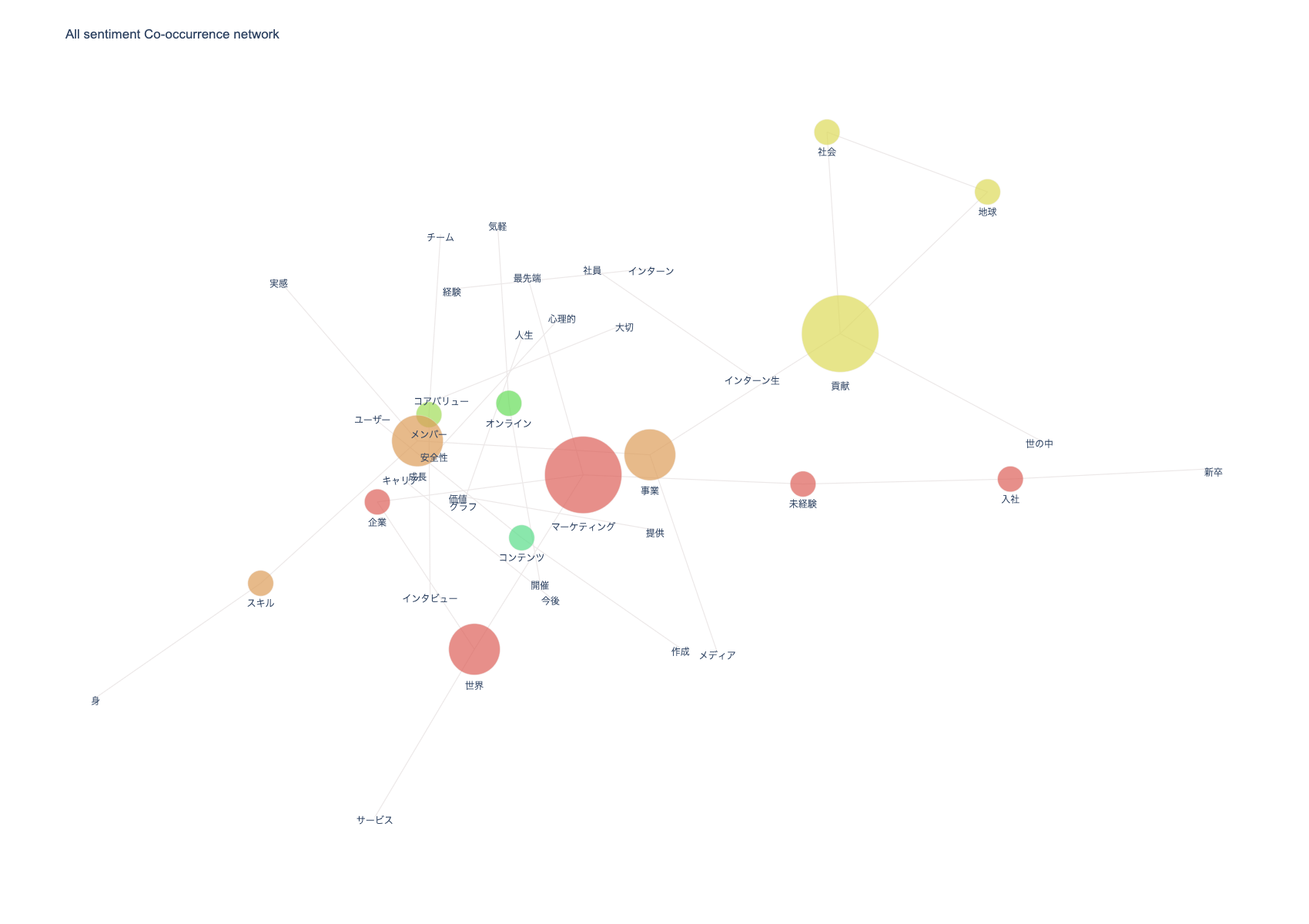
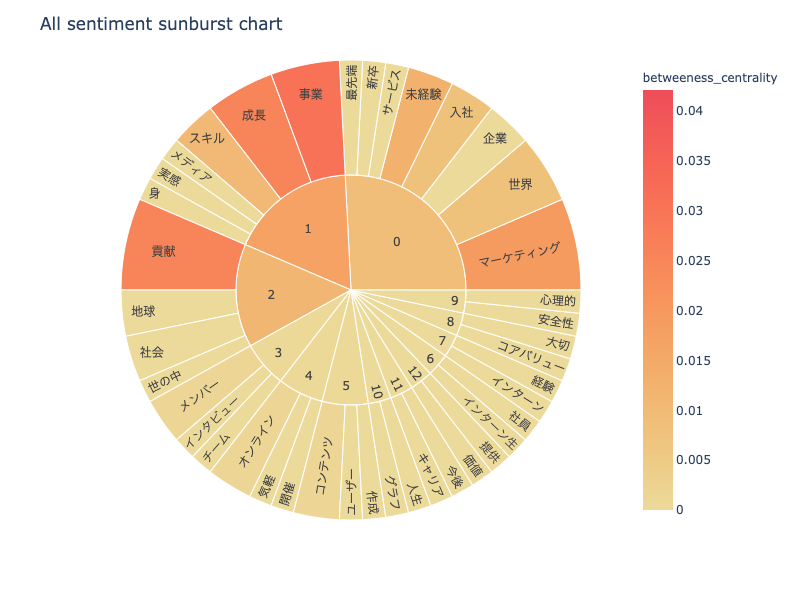
3-8. sunburst chart
npt.sunburst(
title='All sentiment sunburst chart',
colorscale=True,
color_continuous_scale='Oryel',
width=800,
height=600,
save=True
)
参考記事: 自然言語を簡単に可視化・分析できるライブラリ「nlplot」を公開しました
まとめ
可視化して、改めてEXIDEAが大事にしている行動指針「The share」を体現できていると感じました。特に、The shareの Happy(幸せ)とSincere(誠実)。そして、Altruistic(利他的)が記事から顕著に表れており、その結果、最高に働きやすい環境・実現したいことや悩みを相談できる仲間に出会うことができたんだと思います。日々の業務で会社に貢献できることはまだ少ないですが、目の前のタスクにフルコミットすることや外部に発信するなど、今の自分ができることを最大限に引き出せたらと思います。
おわりに
今回の記事で、前処理の重要性を再認識することができました。というのも、nlplotを試してみたいという気持ちで始めたのですが、前処理せずに可視化するとbi-gramやtri-gramで固有名詞が形態素で表示され、悲惨な結果になったからです。その甲斐あって、mecabインストール時やユーザー辞書の作成でLinux周辺の知識を学べたことが一番の収穫だったと思います。知識として身につけるより、実際に手を動かすという基本的なこと怠らないように今後の学習に活かしていきます。
長くなりましたが、ここまで読んでくださりありがとうございます。誤っている箇所がございましたら、コメントでご指摘頂けると大変嬉しいです。