SQLにおける結合
結合 = 複数のテーブル間のデータを単一テーブルにまとめる
例
下記のようなテーブル関係があるとします。
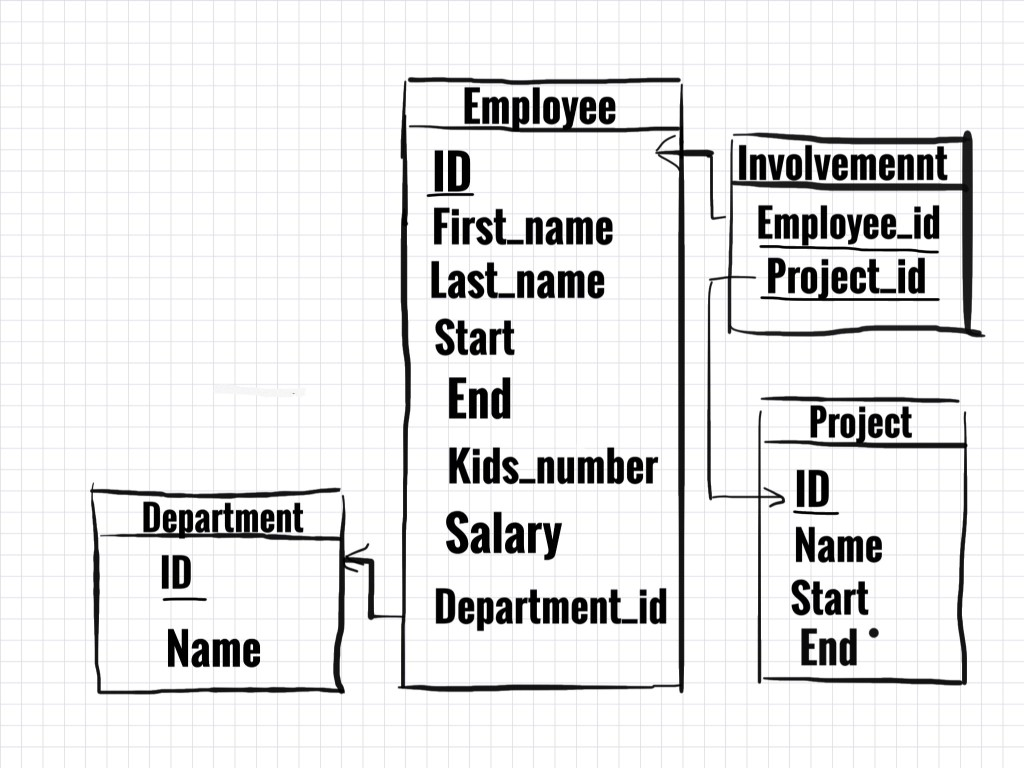
例1:単純結合
マーケティング部で働いている全ての従業員に関するデータが欲しいと仮定しましょう。各従業員の名前、苗字、部署のデータが取得したい。
SELECT emp.First_name AS First, emp.Last_name AS Last, dep.Name AS Department
FROM Employee AS emp, Department AS dep
WHERE emp.Department_id = dep.ID AND dep.Name = 'Marketing'
取得できるテーブルはこちらになります。
| First | Last | Department |
|---|---|---|
| Taro | Suzuki | Marketing |
今回の例では、
emp.Department_id = dep.ID
の記述によって、EmployeesテーブルのDepartment_idとDepartmentテーブルの主キーが一致する行を取得します。
さらに、dep.Name = 'Marketing'によって、DepartmentテーブルのNameカラムがMarketingの行に限定します。
それが上記のテーブルの結果となります。
例2:複数結合
複数結合は、AND節を用いることによって、単純結合と全く同じように機能します。
全ての会社のプロジェクトおよびそれぞれのプロジェクトに携わっている従業員の苗字と名前に関するデータが欲しいと仮定しましょう。この場合、Employee, Project, Involvementの名の付いた3つの表が該当しています。
-- 以降のカラムを取得します。Proj.Name(結果をProjectで表記)&emp.Last_name(結果をlastNameで表記)&emp.FirstName(結果をFirstNameで表記)
SELECT proj.Name AS Project, emp.Last_name AS lastName, emp.First_name AS firstName
-- どこから?? Employeesテーブル(SQL全体でempと省略して使用)、Involvementテーブル(inv)、Projectsテーブル(proj)の3つから取得する。
FROM Employee AS emp, Involvement AS inv, Project AS proj
-- 条件はある?? Involvementsテーブルのproject_idがProjectsテーブルの主キーと一致し、かつInvolvementsテーブルのemployee_idがEmployeeテーブルの主キーと一致すること。
WHERE inv.Project_id = proj.ID AND inv.Employee_id = emp.ID
すると、例えば下記のような経過をたどります。
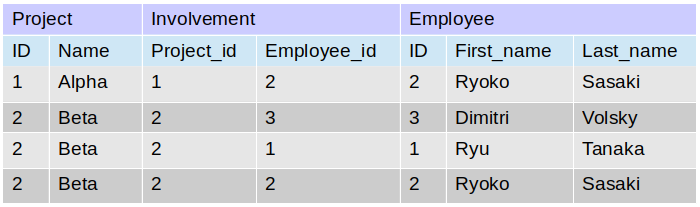
結果として下記のようなテーブルが取得できます。
| Project | lastName | firstName |
|---|---|---|
| Alpha | Sasaki | Ryoko |
| Beta | Tanaka | Ryu |
| Beta | Sasaki | Ryoko |
| Beta | Volsky | Dimitri |
Tips
データがたくさんの異なった表にある場合、結合[JOIN]が必要となり、SQLクエリではそれぞれの属性の前に表[テーブル]の名前の接頭が必要となります。(例:Project.ID)
実際に、異なった表が共通した属性名(例:ID)であることがあるかもしれない。この目的のために、上記の例では、より簡潔な表[テーブル]の名前にエイリアスを用いています。SQLにおいては、結合を行うための別のシンタックス(構文規則)が存在します。下記は、INNER JOIN(内部結合)構文を使用することによって、上記の1番目の例と同等の方法で書かれます。
SELECT emp.First_name AS firstName, emp.Last_name AS lastName, dep.Name AS Department
FROM Employee AS emp
INNER JOIN Department AS dep ON emp.Department_id = dep.ID
WHERE dep.Name = 'Marketing'
サブグループ(下位群)
GROUP BY
会社の全ての案件(プロジェクト)および、それらのプロジェクトに参加している従業員数に関するデータが欲しいと仮定しましょう。
テーブル結合を行った上で、プロジェクト単位でまとめた上で再カウントする必要がありそうですね。
SELECT pro.Name AS project, COUNT(*) AS nbOfEmployees
FROM Project AS pro, Involvement AS inv
WHERE inv.Project_id = pro.ID
GROUP BY pro.ID
どのようにサブグループ(下位群)が構成されるかもっと詳しく見てみましょう。
まず初めに、ProjectとInvolvementの表の間でそれらの両方のデータを統合しなくてはなりません。その後、共通のプロジェクトID(案件ID)のレコードは、以下の命令分によってグループ化されます:GROUP BY pro.ID
最後にCOUNT(*)を用いてそれぞれのサブグループ(下位群)に含まれる要素の数(レコード)がSELECT の中に表示されます。
| project | nbOfEmployees |
|---|---|
| Alpha | 1 |
| Beta | 3 |
サブグループ(下位群)内の条件付け:HAVING
次に、従業員2人または3人が参加しているプロジェクトを抽出したいとしましょう。
先程用いたGROUP BYで、サブグループが作成されましたが、そのグループに対してWHEREを用いることは出来ません。そのため、SQL文によってグループ化された新たなまとまりに対しては別の手段で条件を付与しなければいけません。それがHAVING句です。
SELECT pro.Name AS project, COUNT(*) AS nbOfEmployees
FROM Project AS pro, Involvement AS inv
WHERE inv.Project_id = pro.ID
GROUP BY pro.ID
HAVING COUNT(*) = 2 OR COUNT(*) = 3
結果は下記のようになります。
| project | nbOfEmployees |
|---|---|
| Beta | 3 |
Tips
ここまでで、共通する属性値を保持しているレコードのグループ化の方法を知ることが出来ましたね。HAVINGと関連付けされているGROUP BYは、1つまたはそれ以上の条件を満たすサブグループ(下位群)にフィルターをかける方法です。HAVINGは、全体としてサブグループの条件を設定するのに対して、WHEREはレコードのみに対してです。
SQLによって実行される操作の順番に留意することはとても重要です。初めに、表[テーブル]は、1つの総合表を形成することによって結合されます。その表[テーブル]の後段のレコードの部分にのみ合う条件が選択されます(WHERE)。それらの残りのレコードを基に、サブグループは作成されます (GROUP BY)。 最後に、それらのサブグループでの条件が確認されます(HAVING)。
サブクエリ
別のクエリの中で、SQLクエリを実行する必要が生じることもあります。このコンセプト(概念)は、サブクエリと呼ばれます。
1. 独立したサブクエリ
全ての従業員の平均給与よりも給与の高い全ての従業員に関するデータが欲しいとき。
-- 従業員の名前(姓・名)及び給与を取得する
SELECT emp.First_name AS firstName, emp.Last_name AS lastName, emp.Salary
-- Employeesテーブルを以下empと省略
FROM Employee AS emp
-- 条件:給与が以降の条件以上の従業員を抽出
WHERE emp.Salary >= (
-- 従業員の給与の平均を取得
SELECT AVG( e.salary )
-- Employeesテーブルを指定(eと省略)
FROM Employee AS e
)
| firstName | lastName | Salary |
|---|---|---|
| Dimitri | Volsky | 61400.5Ol |
| Oleg | Grichkin | 78000.8 |
2. 相関サブクエリ
それぞれの部署で一番初めに働き始めた従業員に関するデータが欲しいとき。
-- 部署名、従業員の名前(姓・名)、就業開始日時を取得
SELECT dep.Name AS Department, emp.First_name, emp.Last_name, emp.Start
-- Employeesテーブル(emp)及びDepartmentsテーブル(dep)を対象
FROM Employee AS emp, Department AS dep
-- 条件:従業員の部署IDと部署テーブルの主キーが一致し、就業開始日時が下記条件に一致する
WHERE emp.Department_ID = dep.ID AND emp.Start = (
-- 従業員の就業開始日時のうち、最も過去の日時を取得
SELECT MIN(e.Start)
-- 場所は、Employeesテーブルから取得し、eと省略
FROM Employee AS e
-- 取得条件は、従業員の部署IDが一致するもの
WHERE e.Department_ID = emp.Department_ID
)
| Department | First_name | Last_name | Start |
|---|---|---|---|
| Marketing | Dimitri | Volsky | 2007-05-01 |
| Finance | Ryu | Tanaka | 2010-02-01 |
| Sales | Oleg | Grichkin | 2008-07-01 |